Test • AMD Radeon RX 6800 & RX 6800 XT |
————— 18 Novembre 2020



Test • AMD Radeon RX 6800 & RX 6800 XT |
————— 18 Novembre 2020
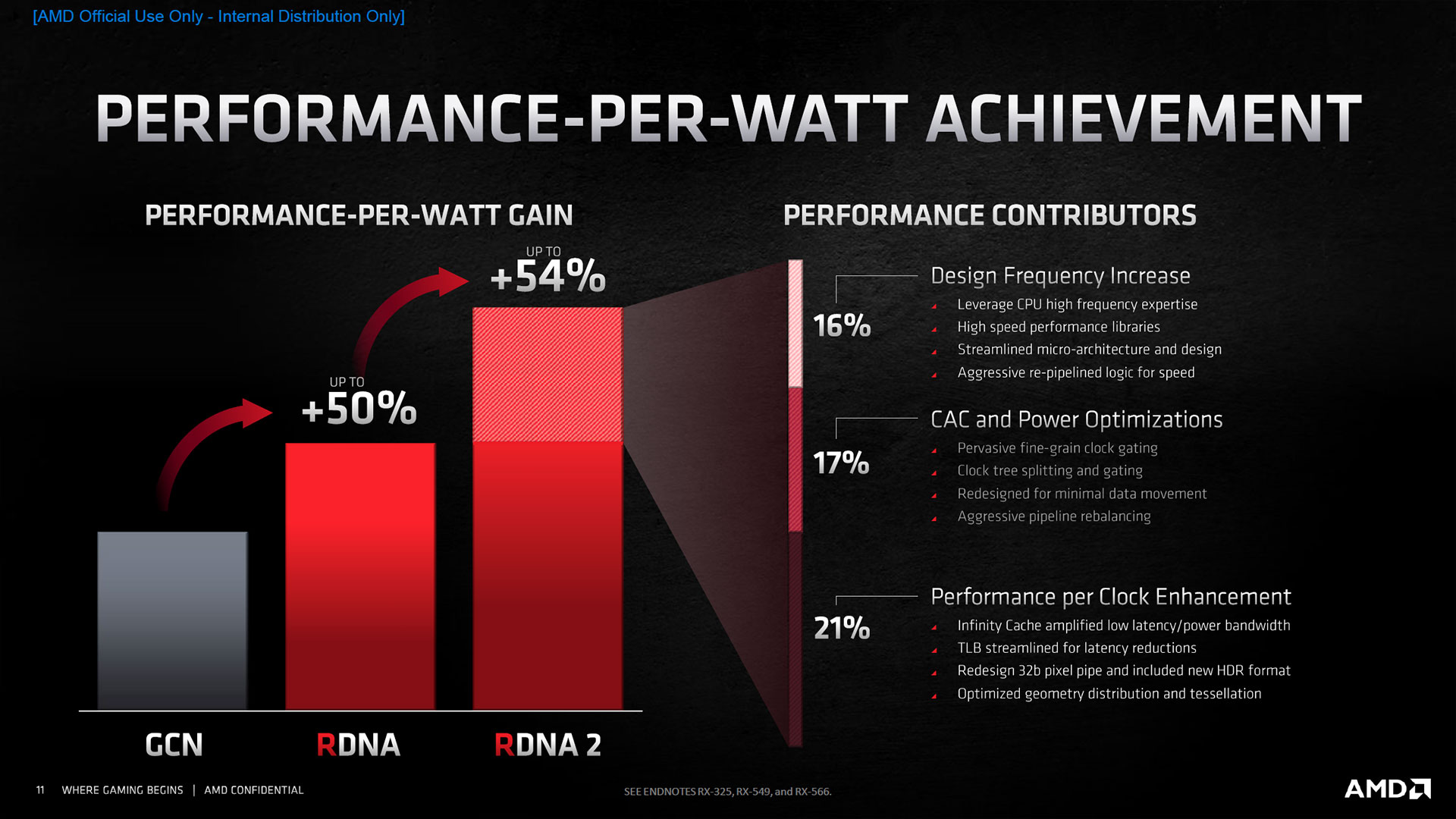
Pour vous aider dans la compréhension des pages à venir, nous vous invitons vivement à lire ou relire, si ce n'est pas déjà fait, celles que nous avions dédiées à RDNA au sein de ce dossier. Cette dernière architecture, est une refonte profonde de la précédente (GCN), avec pour objectif d'améliorer drastiquement les performances par watt. Pour ce faire, AMD a sérieusement revu l'organisation de ses unités de calculs, mais aussi le sous-système mémoire, en particulier la hiérarchie des caches. Pour la seconde itération de cette architecture, les rouges poursuivent dans ce sens avec 3 contributeurs principaux à l'amélioration. Le premier est l'augmentation significative de l'IPC, le second est la réduction de la puissance nécessaire pour atteindre une fréquence donnée ou exécuter certaines tâches, et enfin le dernier consiste à améliorer la capacité à monter en fréquence de l'architecture. Le tout combiné permettrait un gain de 54% au niveau du rapport performances par watt.
![rdna2 gains t [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/6800/rdna2_gains_t.jpg "Cliquédélique !")
Du côté des unités de calculs, ces dernières sont toujours à l'instar de celles en charge du texturing, organisées au sein de Compute Unit. Ces CU fonctionnent par paire au sein d'un Work Group Processor (WGP), partageant un seul et même accès à la mémoire. La nouveauté par rapport à RDNA première du nom, est l'adjonction d'une unité dédiée à accélérer le traitement du Ray Tracing au sein de chaque CU, et que nous détaillerons un peu plus bas. AMD a également réussi avec RDNA 2, le tour de force d'améliorer de 30% la fréquence de fonctionnement de ses unités de calcul, et ce pour une même puissance absorbée. Il y est parvenu par le biais d'un pipeline graphique optimisé, mais aussi en réduisant les déplacements de données au minimum via une nouvelle hiérarchie des caches que nous détaillerons un peu plus bas, et en adoptant un équilibrage agressif du pipeline graphique. Enfin, la granularité appliquée à l'arbre des fréquences est affinée, conduisant à économiser encore davantage de puissance, en visant des groupes de transistors non sollicités durant certaines opérations et qui conservaient leur fréquence maximale sur RDNA.
![rdna2 cu t [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/6800/rdna2_cu_t.jpg "La magie de la loupe, sans loupe")
Les CU progressent également au niveau du jeu d'instructions et fonctionnalités. En sus du Ray Tracing, les Sampler Feedback, Variable Rate Shading et Texture Space Shading font leur apparition (indispensable pour le support complet de DX12 Ultimate), rattrapant ainsi Nvidia qui les supporte depuis Turing. Nous détaillerons tout ceci page suivante. On notera également la prise en charge de précisions de calcul mixtes autorisant des opérations sur tenseurs, appréciées en inférence et donc potentiellement utiles pour un équivalent au DLSS par exemple. Toutefois, contrairement aux verts, AMD opte ici pour l'accroissement des capacités de calcul des unités traditionnelles. Si cette approche est plus économe en transistors, elle risque de se montrer moins performante à l'usage que des unités dédiées proposant des débits plus importants pour des formats particuliers, mais surtout utilisables de concert avec les unités traditionnelles.
![rdna2 cu capacity t [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/6800/rdna2_cu_capacity_t.jpg "Ultra bouzotron HD max def")
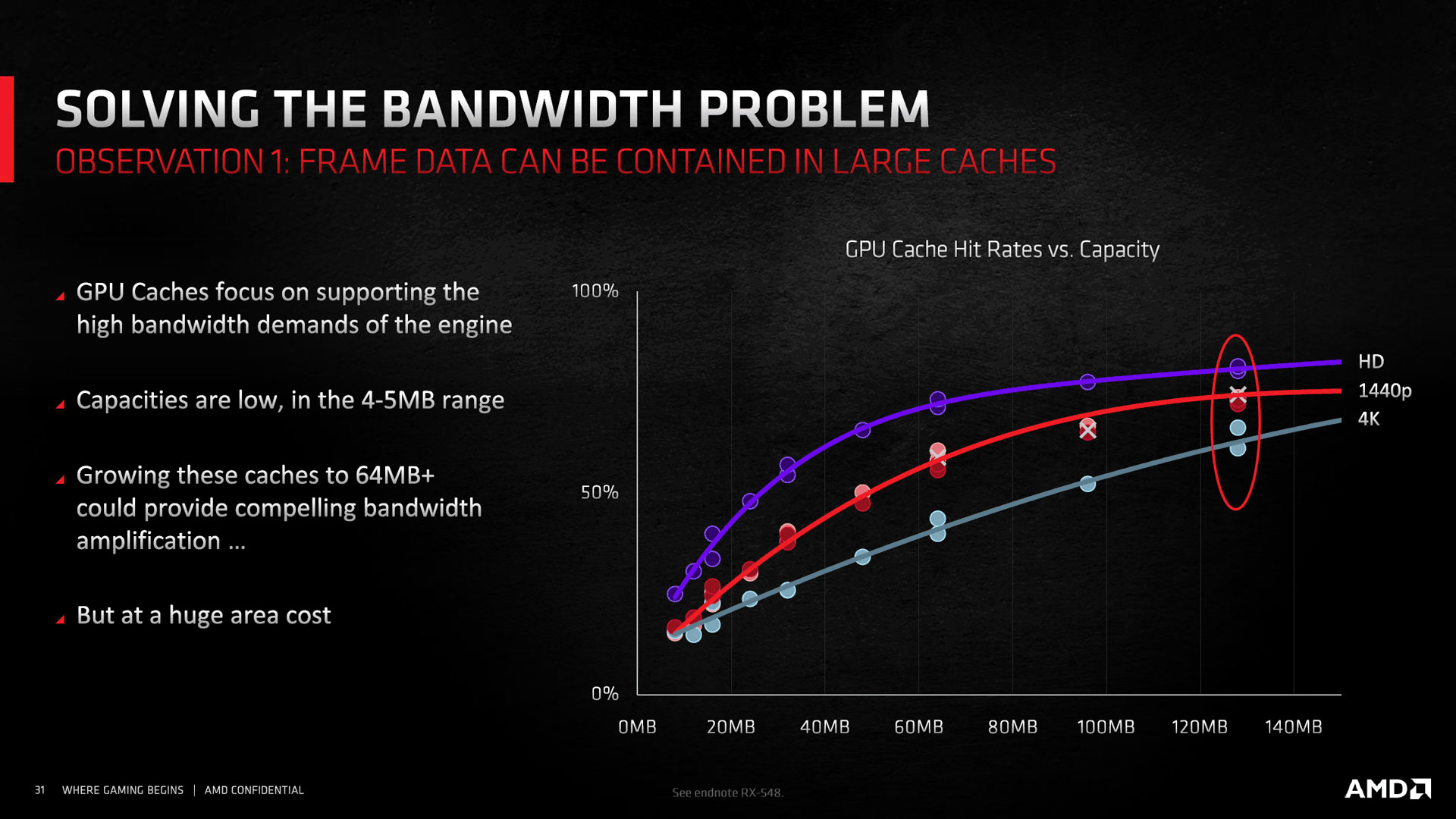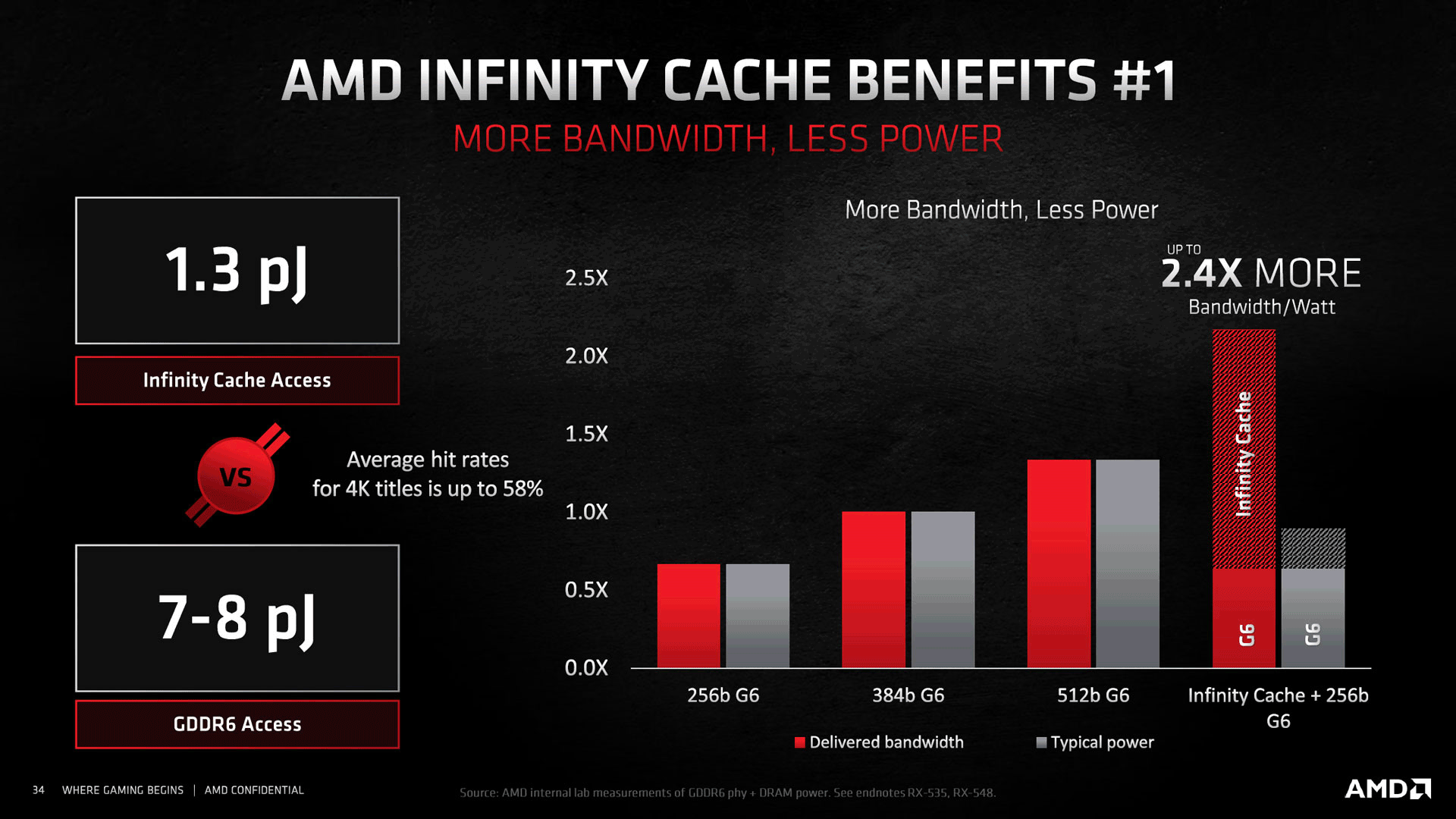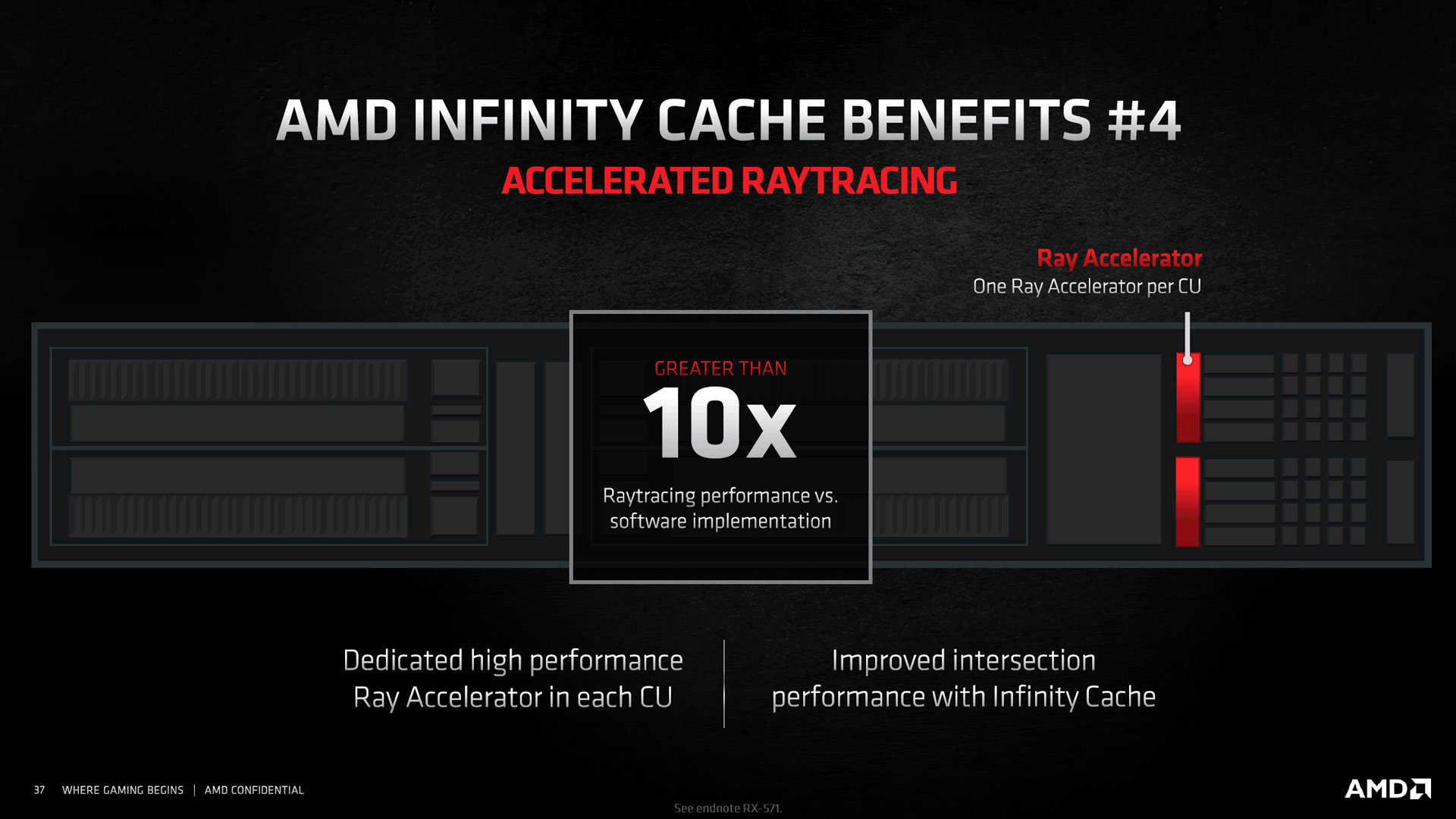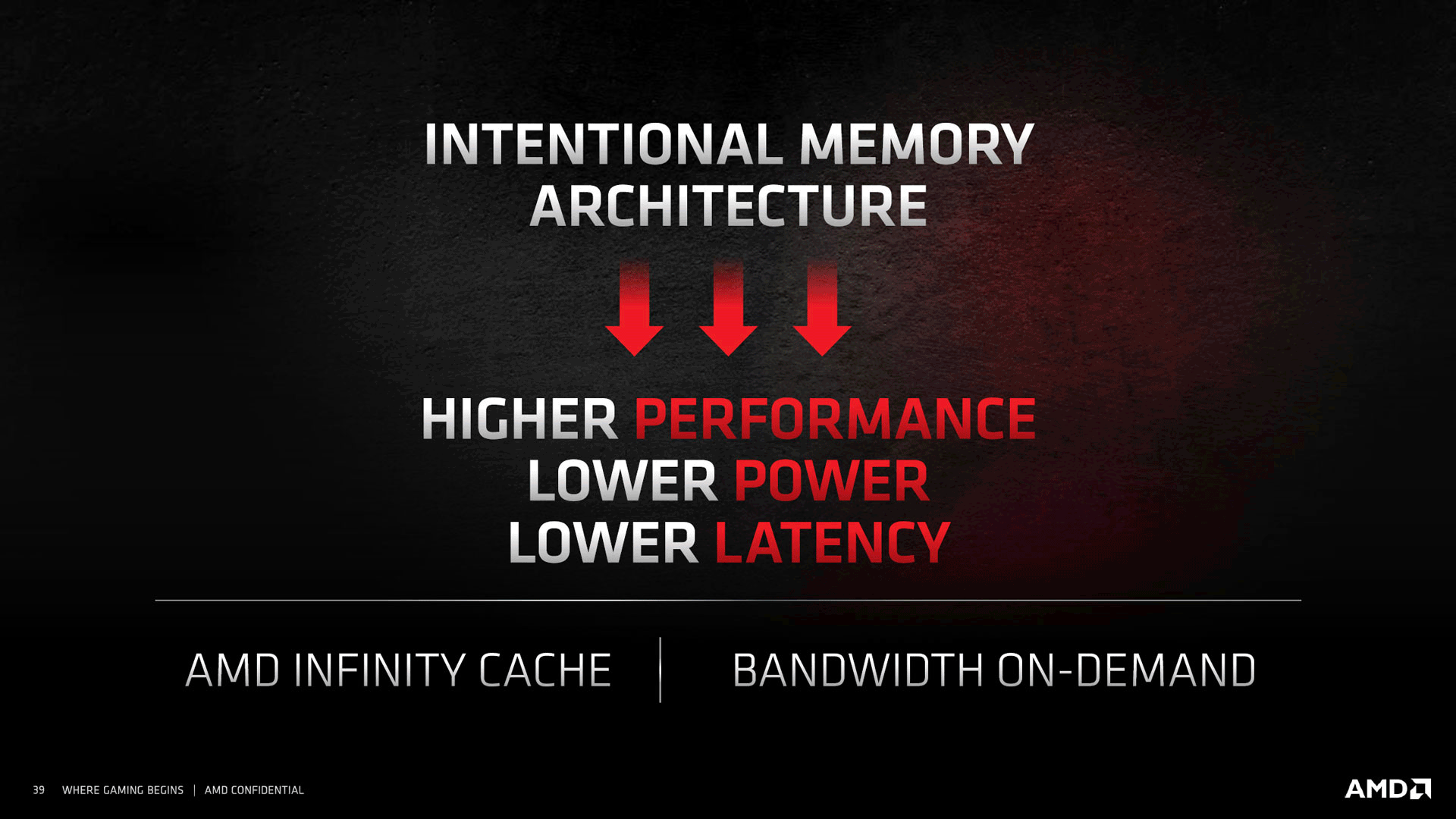
Les modifications précédentes remettent à niveau le côté fonctionnel, pour faire de même au niveau des performances, RDNA2 s'appuie en sus de l'augmentation de la fréquence de fonctionnement, sur l'adoption d'une nouvelle hiérarchie des caches, avec l'adjonction d'un troisième niveau, nommé commercialement Infinity Cache. Il dispose d'une capacité totale de 128 Mo et s'intercale logiquement entre le cache L2 et les contrôleurs mémoire. Cet espace supplémentaire très conséquent (32 fois plus que le précédent dernier niveau que constituait le L2 à 4 Mo sur RDNA), va permettre de conserver en mémoire bien plus de données, tant spatiales que temporelles, induisant les avantages que nous détaillerons un peu plus bas.
![rdna2 cache hierarchy t [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/6800/rdna2_cache_hierarchy_t.jpg "Ne pas appuyer ici")
![rdna2 infinitycache t [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/6800/rdna2_infinitycache_t.jpg "La magie de la loupe, sans loupe")
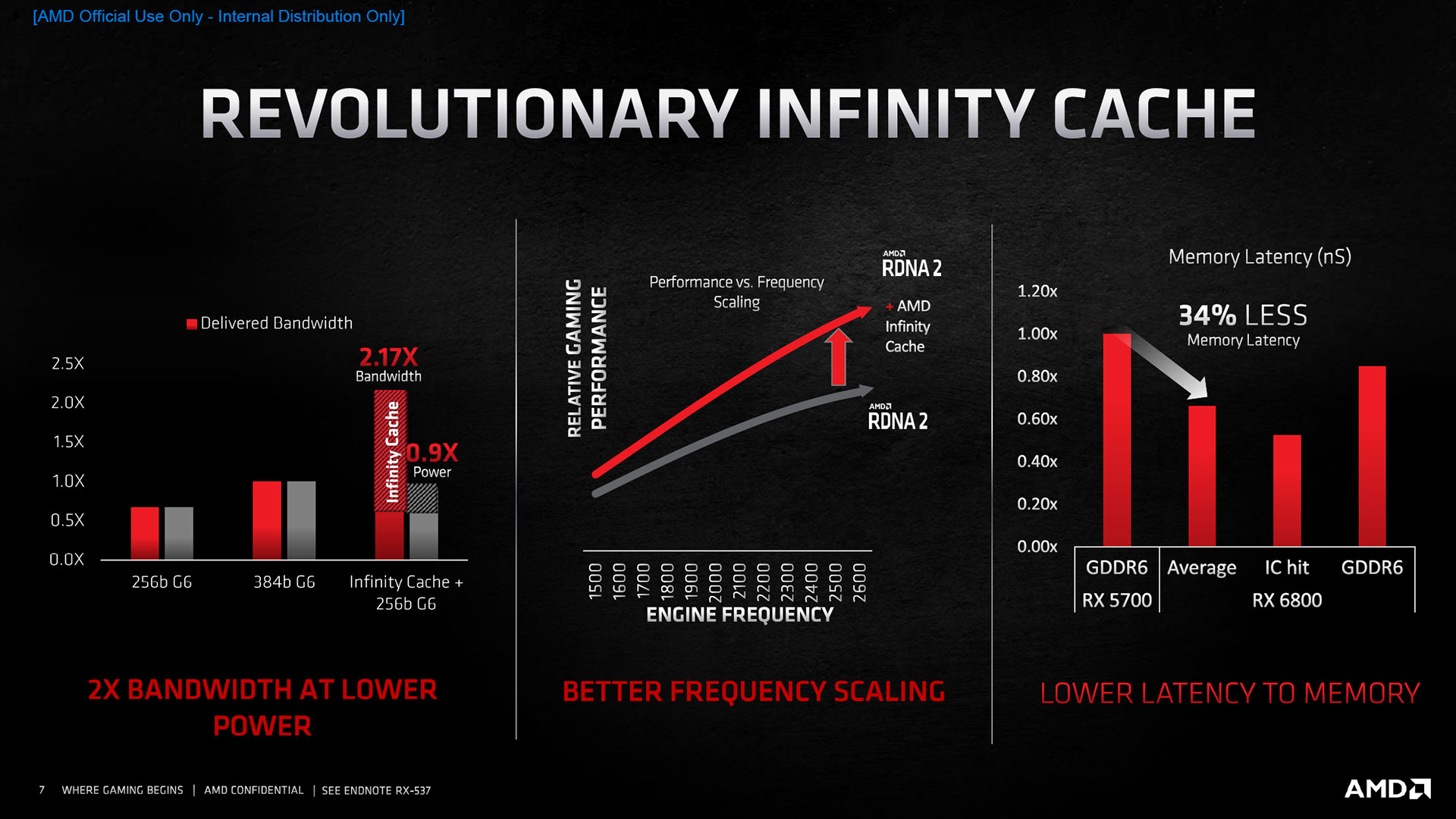
Mais les avantages de ce généreux cache ne se limitent pas à juste amplifier la bande passante mémoire, lorsque les données stockés sont présentes au sein de ce dernier. Les effets se font aussi sentir au niveau de la latence d'accès, significativement moindre. A cela s'ajoute le gain énergétique, puisqu'une requête au sein de l'Infinity Cache, permet de réduire drastiquement la consommation nécessaire par rapport à la même nécessitant un accès mémoire (rapport de 5 à 6). Qui plus est, la fréquence de l'IC est variable, permettant donc des économies d'énergie lorsque le besoin en bande passante est réduit. AMD indique enfin que son implémentation du Ray Tracing profiterait lui aussi de ce cache de dernier niveau. Quoi qu'il en soit, touts les gains annoncés dépendent grandement de la présence ou non des données requises en cache. AMD précise que d'après ses mesures sur de nombreux jeux en UHD, 58 % des requêtes obtiennent un résultat positif (l'information est présente) au sein de l'IC.
![hc t [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/hc_t.gif "Ne pas appuyer ici")
Donc pour exprimer plus clairement l'assertion précédente, dans 6 cas sur 10 lors d'un jeu en UHD (cette proportion est plus élevée avec les définitions moindres), RDNA 2 profitera des avantages de bande passante, latence et consommation correspondant aux accès à l'Infinity Cache. A contrario, dans 4 cas sur 10, il devra faire avec les caractéristiques d'un accès mémoire traditionnel (et probablement d'une petite pénalité en latence du fait d'un niveau de cache supplémentaire, les GPU arrivent cependant à relativement bien à masquer ces latences). Le calcul d'AMD est donc le suivant : utiliser un bus mémoire normalement dévolu pour les séries de cartes inférieures au haut de gamme, économisant ainsi au niveau des budgets transistors et puissance de ce dernier, pour les réaffecter à cet Infinity Cache et générer ainsi un bilan global positif, tant au niveau des performances que de la consommation. Cela permet aussi d'éviter l'association du GPU avec de la mémoire très rapide et donc onéreuse/énergivore, tout en ne bridant pas pour autant le GPU, du fait d'une bande passante insuffisante.
![rdna2 infinitycache2 t [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/6800/rdna2_infinitycache2_t.jpg "La magie de la loupe, sans loupe")
Voilà ce que nous pouvions détailler concernant les évolutions architecturales de RDNA 2, destinées à accroitre les performances. Voyons page suivante ce qu'il en est des fonctionnalités à présent.
|
|
| Un poil avant ?RX 6800 XT et boîtiers mini-ITX, l'impossible mariage ? | Un peu plus tard ...8 coeurs / 16 threads à 4 GHz, tout Ryzen vs Comet Lake | |