Test • AMD RX 5700 XT & RX 5700 |
————— 07 Juillet 2019



Test • AMD RX 5700 XT & RX 5700 |
————— 07 Juillet 2019
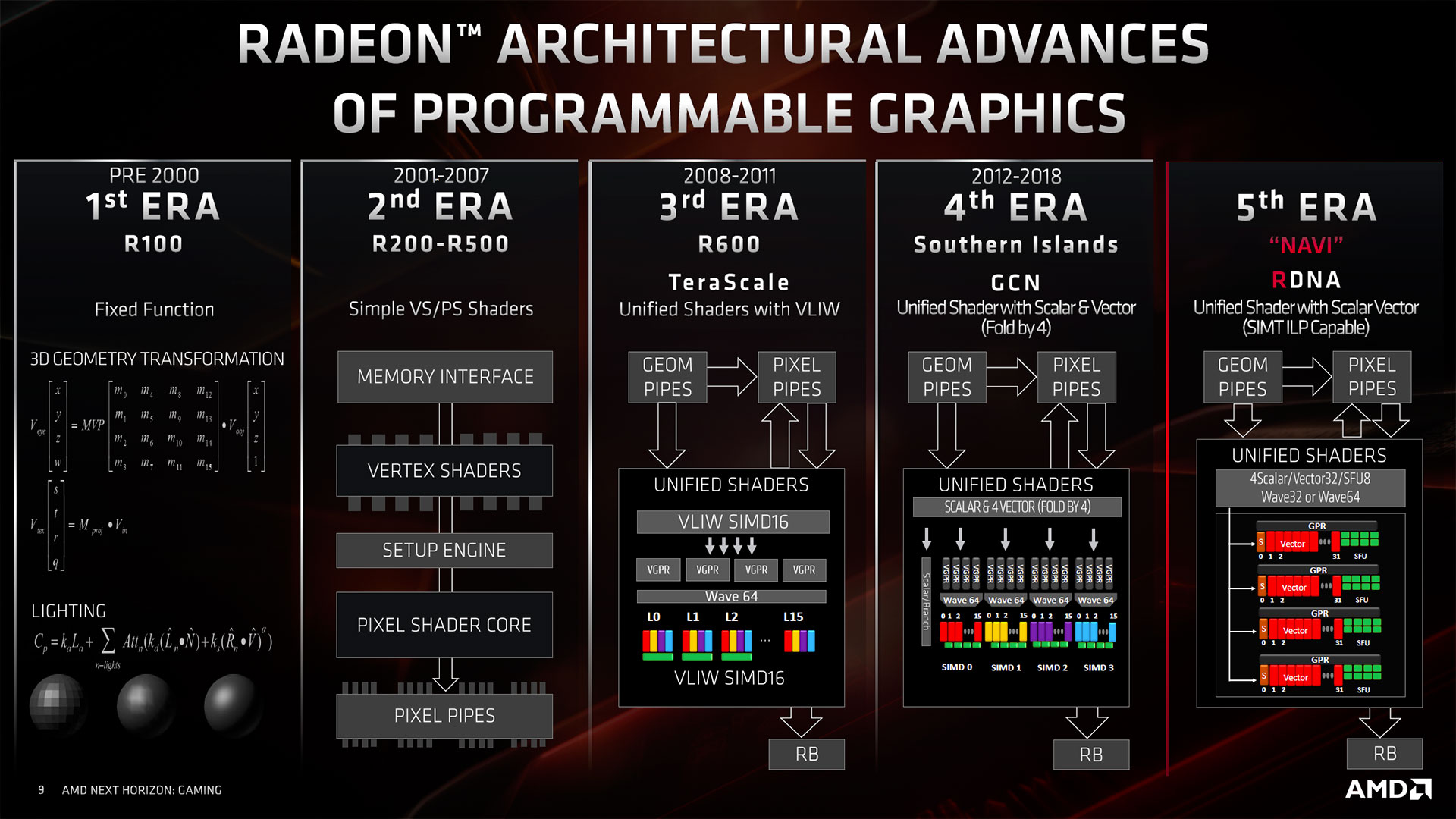
Afin d'être parfaitement clair dés le départ, cette nouvelle architecture n'est pas une énième resucée de GCN comme avait pu l'être Vega, et ce malgré les dénégations des rouges à l'époque, qui souhaitaient la présenter avec ce doux parfum qu'est la nouveauté. Pour autant, nouvelle architecture ne signifie pas systématiquement faire table rase du passé, c'est même très rarement le cas. NVIDIA ne procède pas autrement, pourtant que de chemin parcouru entre Fermi et Turing ! Mais revenons à RDNA comme la nomme AMD, à traduire par l'ADN Radeon, ça en jette pour sûr ! Qu'est-ce qui justifie cette fois l'adjectif "nouveau" pour cette architecture ? Le concepteur classe le fonctionnement interne de ses GPU en 5 grandes époques, la dernière débutant tout juste avec RDNA. Comme nous allons le voir, c'est principalement au niveau des unités d’exécution des Shaders que la différence fondamentale se situe entre les 3 dernières "ères".
![Les différentes ères du GPU pour AMD (ATi) [cliquer pour agrandir]](/images/stories/articles/gpu/navi/architecture/ere_gpu_amd_ati_t.jpg "Même pas cap' de cliquer")
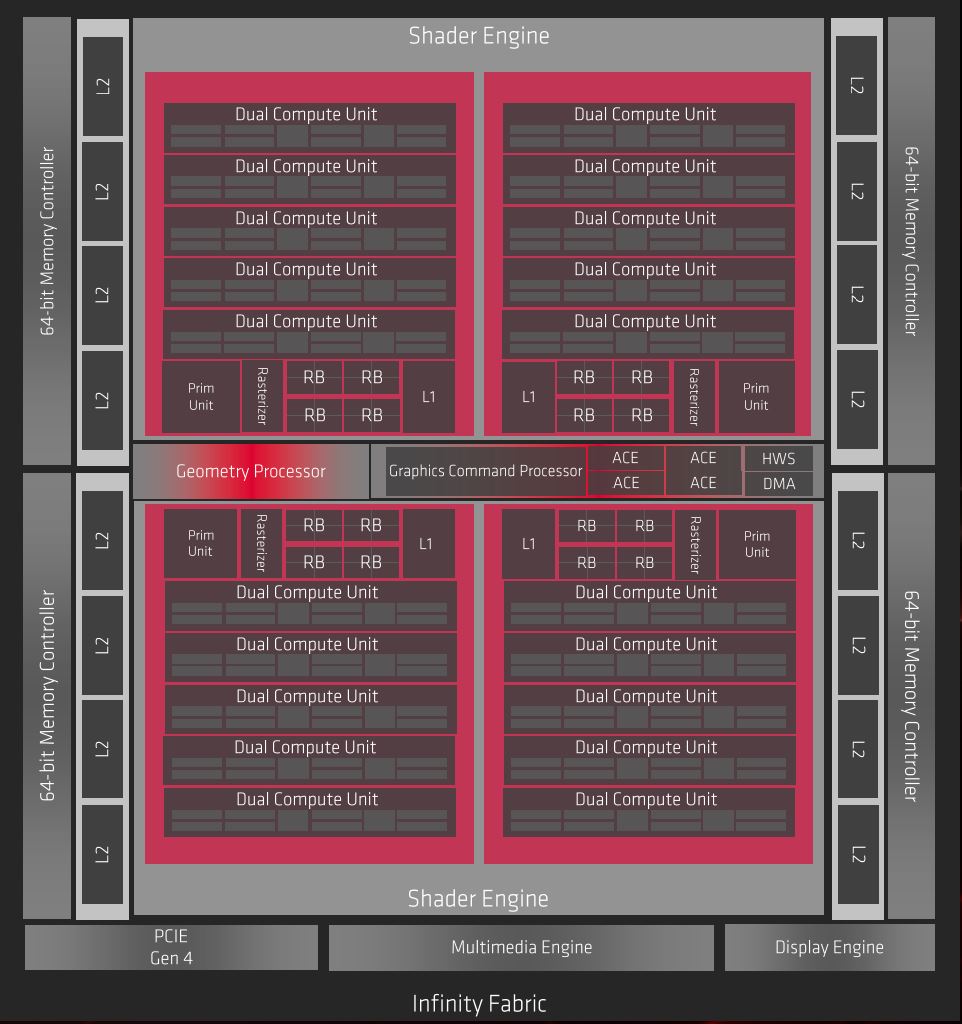
Pour rappel, les GPU modernes utilisent des unités multifonctions capables de réaliser les opérations de calcul et texturing : ce sont les SM (Streaming Multiprocessor) chez les verts et CU (Compute Unit) du côté rouge. Si elles ne sont pas totalement équivalentes, leur rôle est similaire et constitue le "cœur" du processeur graphique. NVIDIA a fait évoluer fortement ses SM au cours des dernières années, ce ne fut pas le cas d'AMD pour ses CU, tout du moins jusqu'à RDNA. Avant de détailler tout cela, voyons brièvement l'organisation "macro" de cette architecture, au sein du premier GPU l'employant aka Navi 10. Commençons par la vue d'ensemble du GPU fournie par AMD ci-dessous.
![Diagramme Navi 10 [cliquer pour agrandir]](/images/stories/articles/gpu/navi/rx_5700/diagram_navi10_t.jpg "Même pas cap' de cliquer")
Le processeur de commande central est chargé de planifier et ordonner les différents threads, à ses côtés se trouvent les ACE (organisation/gestion des tâches Compute), les contrôleurs mémoire interconnectés au cache L2 généralisé, ainsi qu'un processeur géométrique central. Tout ceci est complété par diverses interfaces et moteurs de gestion (vidéo, encodage/décodage). Enfin, l'exécution des programmes est réalisée au sein des Shaders Engine, ces derniers étant subdivisés en 2 Shader Arrays, chacune disposant de leurs propres cache L1, unité de rastérisation (découpe des triangles en pixels), Primitive Unit (génération et traitement des triangles), ainsi que 16 ROP (unité de rendu/sortie) et 5 Dual Compute Unit comprenant comme leur nom l'indique, 2 CU.
![Compute Unit RDNA [cliquer pour agrandir]](/images/stories/articles/gpu/navi/architecture/cu_rdna_t.jpg "Ne pas appuyer ici")
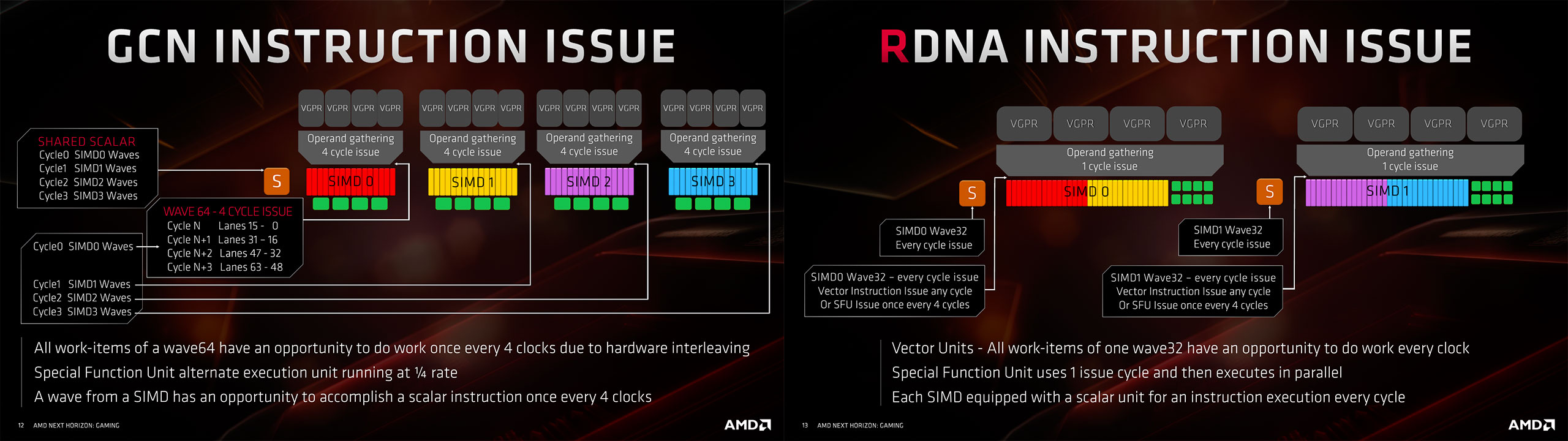
Commençons par un petit rappel sur le sujet concernant GCN : avec ce dernier, les unités de calcul "élémentaires" ou Stream Processors (SP), sont regroupées au sein d'unités vectorielles SIMD (Single Instruction Multiple Data) comprenant 16 SP. En tout, 4 unités de ce type prennent place au sein d'un CU (soit 64 SP), par contre l'unique ordonnanceur ne peut demander l'exécution d'une instruction qu'à une seule et unique SIMD16 par cycle. Ce choix avait été fait à l'époque pour simplifier le travail au niveau du compilateur et la gestion des éléments à traiter lorsque leur nombre croît fortement. A noter également que les tâches affectées à une SIMD16 sur GCN, ne peuvent solliciter l'unique unité scalaire partagée (pour le traitement d'instructions de ce type) que tous les 4 cycles. Autre limitation, les unités (SFU) réalisant les opérations spéciales (Cos, Sin, etc.), ne peuvent fonctionner qu'en alternance avec les SIMD16 (un ordre tous les 4 cycles, scalaire ou vectoriel).
![Unités d’exécution comparées RDNA vs GCN [cliquer pour agrandir]](/images/stories/articles/gpu/navi/architecture/rdna_vs_gcn_eu_t.jpg "Cliquédélique !")
Comment AMD s'y est-il donc pris pour améliorer les unités de calcul de ses Compute Units ? Eh bien en modifiant l'organisation interne de ces dernières et la manière dont elles sont alimentées, afin de faire disparaître certains "goulots" d'étranglement liés à la structure même de GCN. Avec RDNA, les rouges conservent 64 Stream Processors par CU, mais ils sont à présents répartis au sein de deux unités SIMD comprenant chacune 32 SP. Un second ordonnanceur a été ajouté, permettant dès lors de demander le traitement d'une instruction à chaque cycle d'horloge et ce par chacune des deux SIMD32. Autres progrès, RDNA permet à présent d’exécuter une instruction scalaire à chaque cycle (via une unité dédiée par SIMD soit 2 / CU), quant aux SFU, si elles ne peuvent toujours recevoir qu'un ordre tous les 4 cycles, elles peuvent à présent fonctionner en parallèle des SIMD32, une fois ce dernier reçu.
![GCN vs RDNA issue [cliquer pour agrandir]](/images/stories/articles/gpu/navi/architecture/gcn_vs_rdna_issue_t.jpg "Ultra bouzotron HD max def")
Ceci nous amène tout droit à la façon dont sont organisées les tâches à traiter : sur les Radeon modernes, elles sont regroupées au sein de ce qu'AMD appelle une Wavefront. Jusqu'à présent, ces dernières comprenaient systématiquement 64 éléments pour faciliter le travail des ordonnanceurs. Ces Wave64 sont conservées, mais les rouges introduisent à présent une Wave32 qui, comme son nom l'indique, comporte moitié moins de tâches à traiter, s'alignant ainsi sur ce que fait NVIDIA avec ses Warp.
![Wave32 et 64 [cliquer pour agrandir]](/images/stories/articles/gpu/navi/architecture/wave_execution_t.jpg "Même pas cap' de cliquer")
Chaque mode de fonctionnement implique ses propres avantages et inconvénients, il est donc possible selon la nature des Shaders à traiter, d'utiliser l'un ou l'autre afin d'optimiser l'exécution de tâches spécifiques ou éviter l'engorgement de certaines ressources, le code devant être compilé pour le type de Wavefront souhaité. Il faut surtout voir cela comme une rétrocompatibilité, permettant à RDNA de s'adapter au mieux aux spécificités du code prévu initialement pour GCN. Cette nouvelle architecture fonctionne en fait nativement en Wave32, l'usage des Wave64 nécessitant l'émission de 2 ordres pour les opérations de calcul et mémoire, en subdivisant les 64 tâches en 2 x 32.
![Exemple de traitement de Shaders [cliquer pour agrandir]](/images/stories/articles/gpu/navi/architecture/exemple_shader_t.jpg "Cliquédélique !")
La combinaison de la nouvelle structure des unités d'exécution et de leur alimentation via un nouveau type de Wavefront, permet un taux d'utilisation des ressources matérielles bien supérieur à ce dont GCN est capable. AMD avance ainsi un gain pouvant aller jusqu'à un facteur 4, pour l’exécution de certaines tâches faisant un appel intensif aux ALU. Bien entendu, il s'agit de cas très favorables qui sont loin de constituer la totalité de la charge dont doit s’acquitter le GPU lors du rendu d'une image en domaine ludique. Il n'en reste pas moins que le taux d'usage des unités d’exécution est effectivement en progression significative, du fait des changements opérés.
![Gains liés [cliquer pour agrandir]](/images/stories/articles/gpu/navi/architecture/perf_monothread_t.jpg "Si vous cliquez, vous cliquez.")
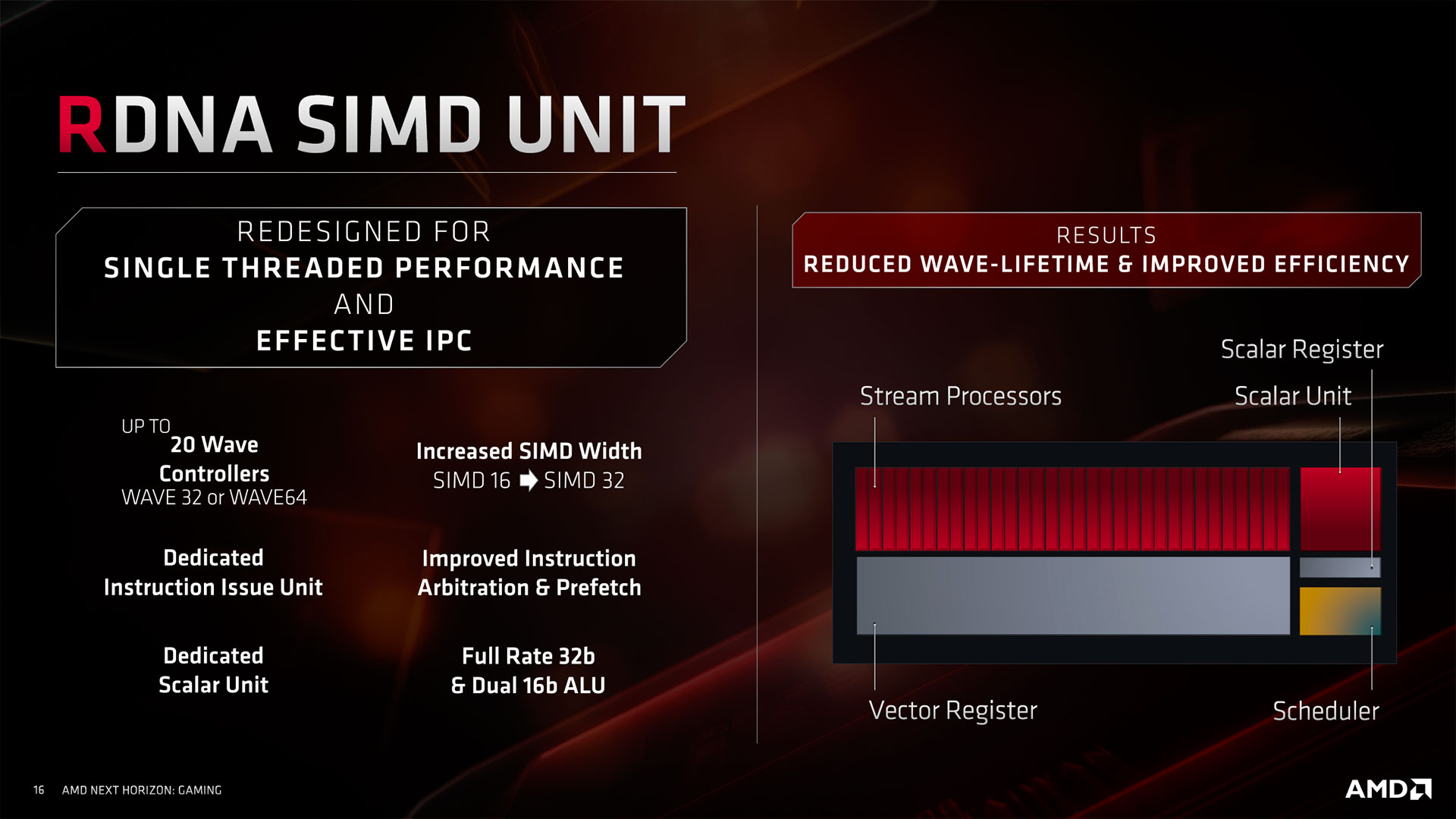
Pour ceux qui se poseraient la question, les unités de calcul conservent leur capacité à traiter à double vitesse la demi-précision (FP16), qu'AMD nomme Rapid Packed Math au sein de Vega. Voici résumées dans le slide suivant, les principales caractéristiques et évolutions des unités SIMD adoptées par RDNA...
![SMID RDNA [cliquer pour agrandir]](/images/stories/articles/gpu/navi/architecture/smid_rdna_t.jpg "La magie de la loupe, sans loupe")
... et les changements fondamentaux que l'évolution des caractéristiques a entraînés au niveau de l'usage des unités d'exécution. On peut donc voir RDNA comme un rééquilibrage entre les architectures Terascale et GCN, tentant le difficile équilibre entre l'efficience de l'une et la facilité d'usage et d'optimisation de l'autre.
![avantages respectifs architectures AMD [cliquer pour agrandir]](/images/stories/articles/gpu/navi/architecture/avantages_respectifs_architectures_t.jpg "Ultra bouzotron HD max def")
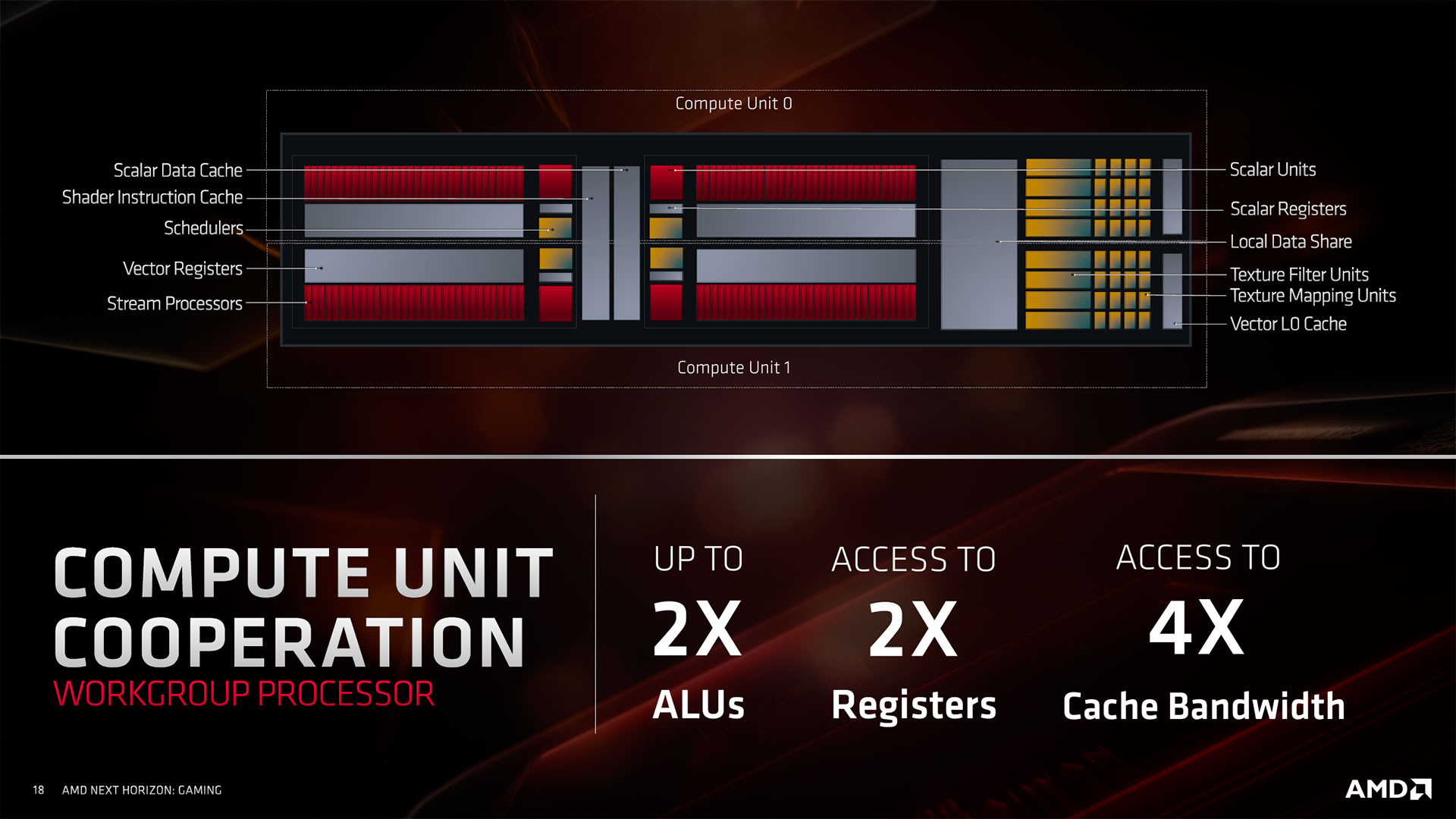
Intéressons-nous pour clore ce chapitre, aux autres éléments constitutifs d'un CU RDNA. Peu de changement à ce niveau, l'application des textures est toujours confiée à 4 TMU. Ces dernières sont toutefois plus performantes pour certaines tâches de chargement ou stockage. Le filtrage des textures en FP16 est également réalisé à présent à pleine vitesse. Chaque Compute Unit intègre également les registres destinés aux unités SIMD32 & scalaire, mais aussi divers caches et mémoire locale. Nous détaillerons cela page suivante. Des unités Load/store gérant les accès mémoire sont également présentes, mais ne sont pas affichées sur ces slides, probablement pour éviter de les surcharger. Un point intéressant à noter concerne la représentation visuelle d'un CU : il s'agit d'un couple de 2 Compute Unit, dont l'une des deux est grisée et ce n'est pas sans raison. En effet, la notion de WorkGroup Processor (WGP) apparaît avec RDNA : il s'agit de 2 CU "adjacents" partageant un même accès à la mémoire vidéo.
![CU RDNA vs GCN [cliquer pour agrandir]](/images/stories/articles/gpu/navi/architecture/rdna_vs_gcn_cu_t.jpg "Enlarge your pe...icture")
Ces CU coopèrent nativement en mutualisant leurs ressources au sein du WGP, de quoi obtenir une capacité de traitement doublée, tout comme le nombre de registres disponibles ou même une bande passante quadruplée pour le cache. Cette organisation en pool des ressources entre 2 CU interdépendants, vise à maximiser leur efficacité. Si les CU peuvent continuer à opérer individuellement si besoin, notons tout de même que dans sa documentation sur RDNA, AMD décrit un Compute Unit comme étant la moitié d'un WGP, ce dernier étant considéré à présent comme l'unité de base pour l'exécution des Shaders. Peut-être pour une simple raison marketing (40 > 20), ou tout simplement pour conserver une certaine continuité avec le passé, mais AMD continue à communiquer en termes de nombre de CU plutôt que de WGP.
![Coopération entre CU [cliquer pour agrandir]](/images/stories/articles/gpu/navi/architecture/cooperation_cu_rdna_t.jpg "Visionner en grand sur un magnifique pop-up")
C'est tout pour les unités d'exécution RDNA, poursuivons notre tour d'horizon de cette architecture page suivante.
|
|
| Un poil avant ?Gamotron • Et vous, quel sera votre rôle ? | Un peu plus tard ...Test • AMD Zen 2 : X570 & Ryzen 7 3700X / Ryzen 9 3900X | |