Test • AMD Radeon RX 6800 & RX 6800 XT |
————— 18 Novembre 2020



Test • AMD Radeon RX 6800 & RX 6800 XT |
————— 18 Novembre 2020
Cette révision de l'architecture RDNA n'est pas uniquement conçue pour revenir dans le jeu côté performance, elle l'est aussi pour rattraper le retard accumulé du côté fonctionnalités face à son concurrent. Ces dernières vont donc vous paraitre familières si vous nous lisez régulièrement, et pour cause, puisqu'il s'agit de la transposition au sein de la dernière architecture d'AMD, de celles introduites par Nvidia avec Turing. Ce niveau de fonctionnalités a été repris par Microsoft au sein de sa dernière API, DirectX 12 Ultimate.
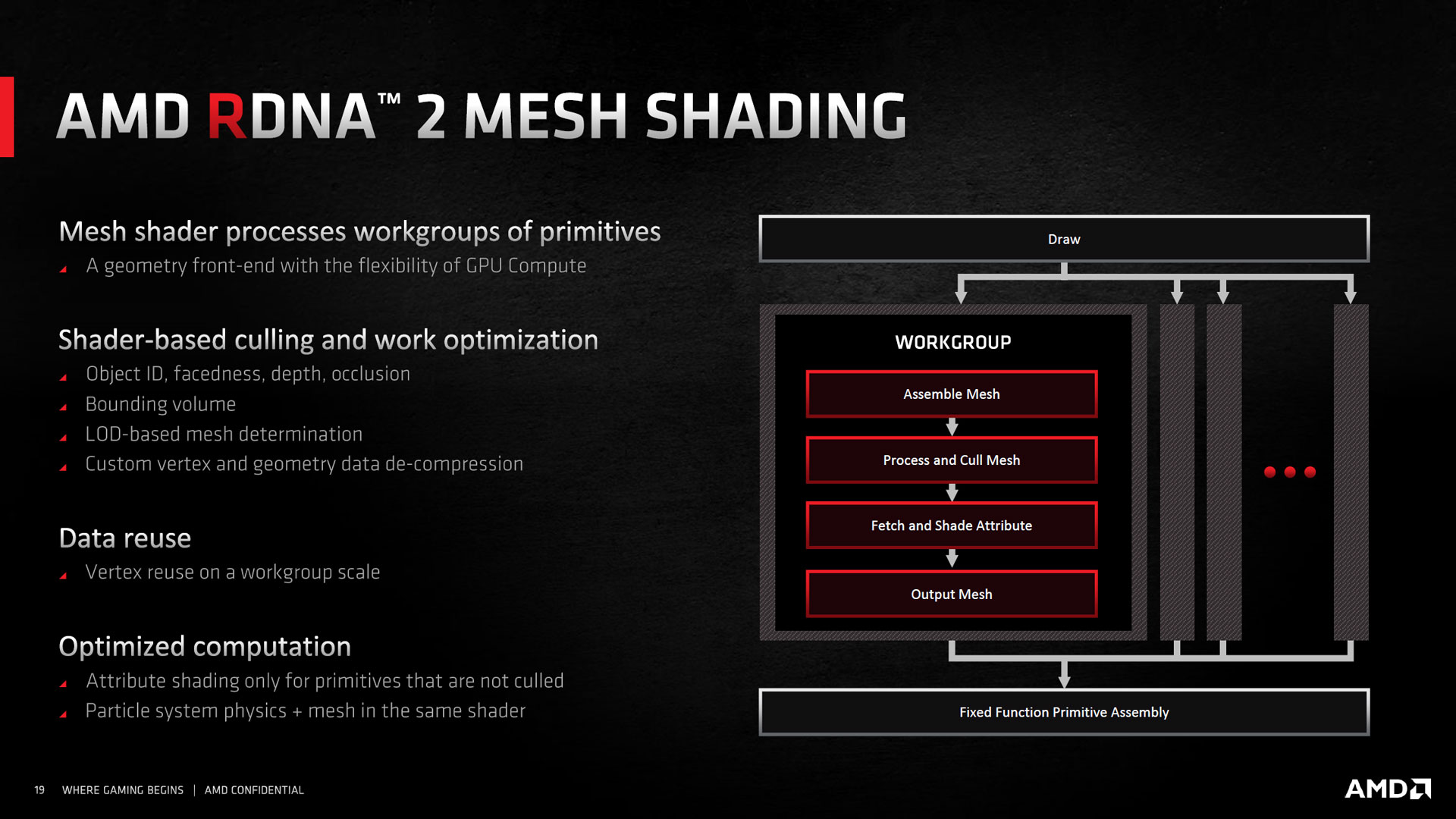
Les Mesh Shader constituent une refonte profonde du traitement de la géométrie, puisqu'au lieu de s'appuyer sur un exécution très peu parallélisée, nécessitant une sollicitation du CPU à chaque objet via une requête (Draw call), une scène complexe à ce niveau va pouvoir être traitée beaucoup plus efficacement. Ainsi, le développeur peut via les Mesh Shader, fournir une liste d'objets (avec le niveau de détails à appliquer à chacun) au travers d'un seul Draw call. Le GPU va ensuite ordonnancer cette liste afin de l'exécuter avec le maximum de parallélisme, et ainsi traiter ces opérations bien plus rapidement que ne le ferait le CPU, lorsque la scène est fortement chargée objets (au sein d'un champ d'astéroïdes par exemple, etc.).
![mesh t [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/mesh_t.jpg "Ne pas appuyer ici")
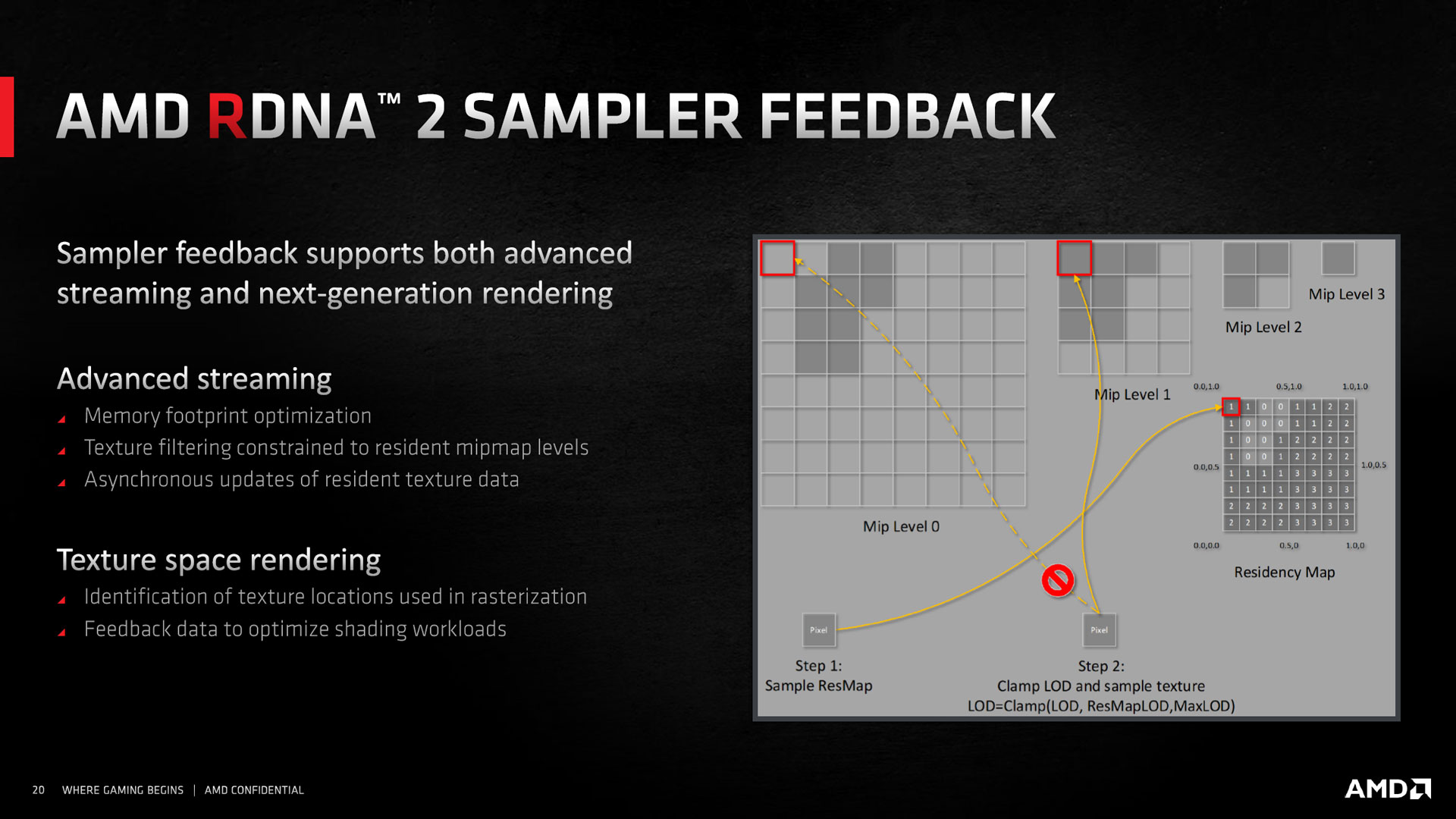
Passons à présent au Sampler Feedback. Cette fonctionnalité a pour objectif de simplifier la tâche des développeurs au niveau de la gestion de la mémoire vidéo. En effet, lors d'une scène en mouvement, le niveau de détail et filtrage des textures appliquées change constamment, obligeant à stocker en mémoire vidéo l'échantillonnage de ces dernières plus que réellement nécessaire. Le Sampler Feedback est une fonctionnalité permettant de répondre à la problématique suivante : quelle partie de la texture aurait du être échantillonnée et laquelle n'était pas nécessaire, en créant une "cartographie" basée sur l'historique. En l'intégrant ensuite dans le système de diffusion des éléments du moteur 3D, lorsque la question se posera à nouveau, les shaders en charge de ces opérations pourront déterminer si l'échantillonnage en mémoire est nécessaire ou non, et ce sans avoir à réaliser ladite opération.
Cela ouvre d'ailleurs la voie au Texture Space Shading, ce dernier permettant de découpler les opérations de rastérisation / Z-testing, de celles de shading. Ainsi, ces dernières peuvent à présent être réalisées à une vitesse ou à un moment différents. Un exemple illustrant cette possibilité consiste à réaliser via une opération compute pure (ne sollicitant pas le pipeline graphique), un éclairage complexe sur des matériaux et de stocker le résultat obtenu dans une texture. Lorsque la scène le requiert, cette dernière est utilisée par un simple échantillonnage lors de la rastérisation. Ce découplage permet de réduire la charge lors du rendu à un instant donné, et ce quelque soit la complexité de l'éclairage utilisé en amont, tout en limitant l'aliasing. L'astuce consistant donc à solliciter en amont les ressources inutilisées, afin d'économiser ces dernières lorsque la charge se fait plus critique.
![sampler feedback t [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/sampler_feedback_t.jpg "Cliquédélique !")
Le Variable Rate Shading est aussi une des fonctionnalités phares ajoutées à RDNA2, puisqu'il permet des gains de performances substantiels, en autorisant les développeurs à jouer sur la finesse de traitement des pixels au sein d'une scène. Le principe est de regrouper les pixels en une multitudes de zones réduites (Tiles), et d'appliquer un niveau de shading variable pour chacune d'entre elles. Ainsi, au sein d'uneTile, le développeur peut avec RDNA2, choisir d'utiliser le taux nominal (1x1 = shading de chaque pixel), ou minimum (2x2) = shading de 4 pixels à la fois) ou une valeur intermédiaire. Ainsi, le gain maximal peut aller jusqu'à un facteur 4, ce qui est moindre que sur Turing/Ampere (x16), tout en proposant moins de choix (4 contre 9), du fait d'une taille de Tile plus restreinte (8 x 8 pixels vs 16 x 16). AMD indique que des Tiles plus importantes (comprendre celle de Nvidia) complexifient le choix au niveau de débit, entraînant trop de compromis visuels ou de performances.
![vrs t [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/vrs_t.jpg "Enlarge your pe...icture")
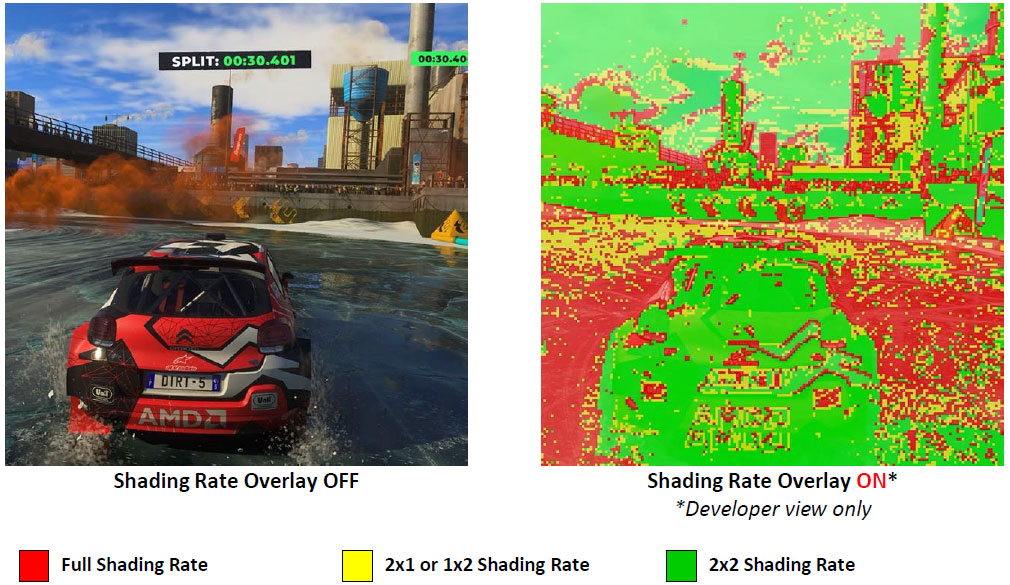
Bien entendu, il ne faut pas s'attendre à ce qu'AMD ou Nvidia explique autre chose que leur choix soit le plus pertinent, mais comme toujours ce seront les développeurs qui décideront en définitive de la meilleure approche, selon l'usage qu'ils en feront. Dans le test VRS de 3DMark, les RX 6000 proposent des gains supérieurs à leurs concurrentes vertes, étayant l'assertion des rouges, même s'il est difficile de généraliser sur un seul exemple. A ce titre, DiRT 5 en est un autre favorable, et AMD présente la mise en œuvre du VRS au sein de ce dernier. En vert, le moteur se contente de rendre une seule valeur pour un groupe de 4 pixels, en jaune pour un groupe de 2 et enfin vous l'aurez compris, en rouge pour chaque pixel. La carrosserie de la BX C3 étant constituée de larges zones identiques, il est facile d'unifier les groupes de pixels sans dégrader la qualité perçue. A contrario, les aspérités du revêtement routier et son déplacement rapide, imposent un taux de shading maximal.
![vrs2 t [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/vrs2_t.jpg "Visionner en grand sur un magnifique pop-up")
Intéressons-nous à la dernière nouveauté de RDNA2 en comparaison de son prédécesseur, l'accélération du Ray Tracing. Pour le dire très simplement, l'approche est très similaire à celle adoptée par Nvidia, c'est à dire une accélération du BVH (Bounding Volume Hierarchy). Nous vous renvoyons à ce dossier pour la description du principe de fonctionnement de ce dernier. Résumé en quelques lignes, il s'agit de simplifier le calcul des intersections entre les rayons lancés et les triangles (composant les objets) frappés par ces derniers. Pour ce faire, l'algorithme crée des formes (boites) simples (pour faciliter le calcul des intersections) au sein de la scène, et teste si le rayon touche ou non la forme. Si le résultat est négatif, alors une autre boite est testée et ainsi de suite jusqu'à obtenir un résultat positif. Une fois ce dernier obtenu, l'intérieur de ladite boite est à nouveau divisé en de multiples boites plus petites et l'opération recommence ainsi jusqu'à être en mesure d'identifier le triangle frappé par le rayon. Pour accélérer ces opérations, AMD a développé ses Ray Accelerator, à raison d'un par CU. Là où l'approche entre les 2 concepteurs diverge, c'est dans les capacités des unités respectives.
Le BVH se subdivise donc en 3 opérations distinctes : le calcul des intersections entre les boites et rayons, la traversée de l'arbre du BVH (passage d'une boite touchée à des boites plus petites en son sein) et enfin le calcul de l'intersection entre triangle et rayon. Là où ces 3 opérations sont gérées par les RT Cores sur Turing/Ampere, les Ray Accelerators de RDNA 2, ne réalisent que la première et la dernière d'après notre compréhension du sujet (AMD restant flou à ce niveau). La traversée du BVH serait donc effectuée par un shader (programme) s'exécutant sur les unités de calculs traditionnelles, ce qui ne serait pas sans conséquence. En effet, ces dernières sont organisées en unités SIMD (Single Instruction on Multiple Data), appréciant très modérément les sauts d'une zone mémoire à une autre sans ordre logique dans un programme (Pointer chasing). Or, ces opérations sont très fréquentes lors de la traversée du BVH, d'où l'organisation MIMD (Multiple Instructions on Multiple Data) des RT Cores concurrents. AMD explique que l'Infinity Cache améliore considérablement la latence de calcul des intersections, reste à voir dans quelle proportion cela permettrait de compenser la perte probable, au niveau des opérations de traversée du BVH.
![ray accelerator2 t [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/ray_accelerator2_t.jpg "Ultra bouzotron HD max def")
Ajoutons aussi que le Ray Tracing tel qu'appliqué à l'heure actuelle, est une solution hybride destinée à cumuler les avantage de vitesse (rastérisation) et qualité (RT), en mixant les tâches selon les points fort de chaque rendu. Les performances finales ne dépendent donc pas uniquement de la capacité d'accélération du BVH et ce y compris au niveau du seul RT. En effet, des compromis sont nécessaires aussi à ce niveau vis-à-vis du nombres de rayons lancés, sous peine de ne parvenir qu'à un slide show. AMD utilise donc à l'image de son concurrent, des filtres de débruitage permettant d'obtenir un rendu visuel "propre", malgré cette restriction. Ces filtres sollicitent les unités de calcul traditionnelles (FP32), diluant encore davantage le seul apport des accélérateurs du BVH.

Si vous vous êtes déjà intéressés au sujet Ray Tracing, un point qui ne vous aura pas échappé, est l'extrême gourmandise de ce dernier. Des compromis sont donc indispensables pour le mettre en œuvre au sein des jeux vidéo, nécessitant un rendu en temps réel. Comme nous l'évoquions précédemment, le rendu n'est pour commencer par intégralement réalisé en RT. Ce dernier est généralement cantonnée à la gestion de l'éclairage de manière plus ou moins complète selon les jeux, le reste étant assuré par rastérisation. A cela s'ajoute un usage parcimonieux du nombre de rayons lancés, l'appoint visuel étant réalisé par des filtres de débruitage. Malgré cela, la charge reste énorme pour les GPU contemporains, c'est pourquoi Nvidia s'est tourné vers un upscaling assisté d'IA (DLSS), afin de fournir des performances décentes en très haute définition.
Après une première itération perfectible du fait d'un flou important impactant la plupart des jeux, la version 2.0 procure cette fois un résultat visuel tout à fait satisfaisant et un gain de performance impressionnant. Le souci actuel côté rouge, est donc l'absence de proposition équivalente, rendant l'usage du RT quasi impossible en UHD. Si les unités de calcul traditionnelles de RDNA2, disposent de ce qu'il faut pour une inférence rapide (au prix de la mobilisation d'une partie de ces dernières, comme expliqué précédemment), il reste encore à développer le réseau de neurones artificiels capable de réaliser l'apprentissage profond, préalable à toute inférence, et un écosystème apte à en tirer parti. Ce n'est pas une mince affaire, AMD indique toutefois y travailler en collaboration avec les développeurs de jeux, sans fournir pour autant plus de précision ou de délai quant à sa mise à disposition. Wait & see donc.
![superresolution t [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/superresolution_t.jpg "Enlarge your pe...icture")
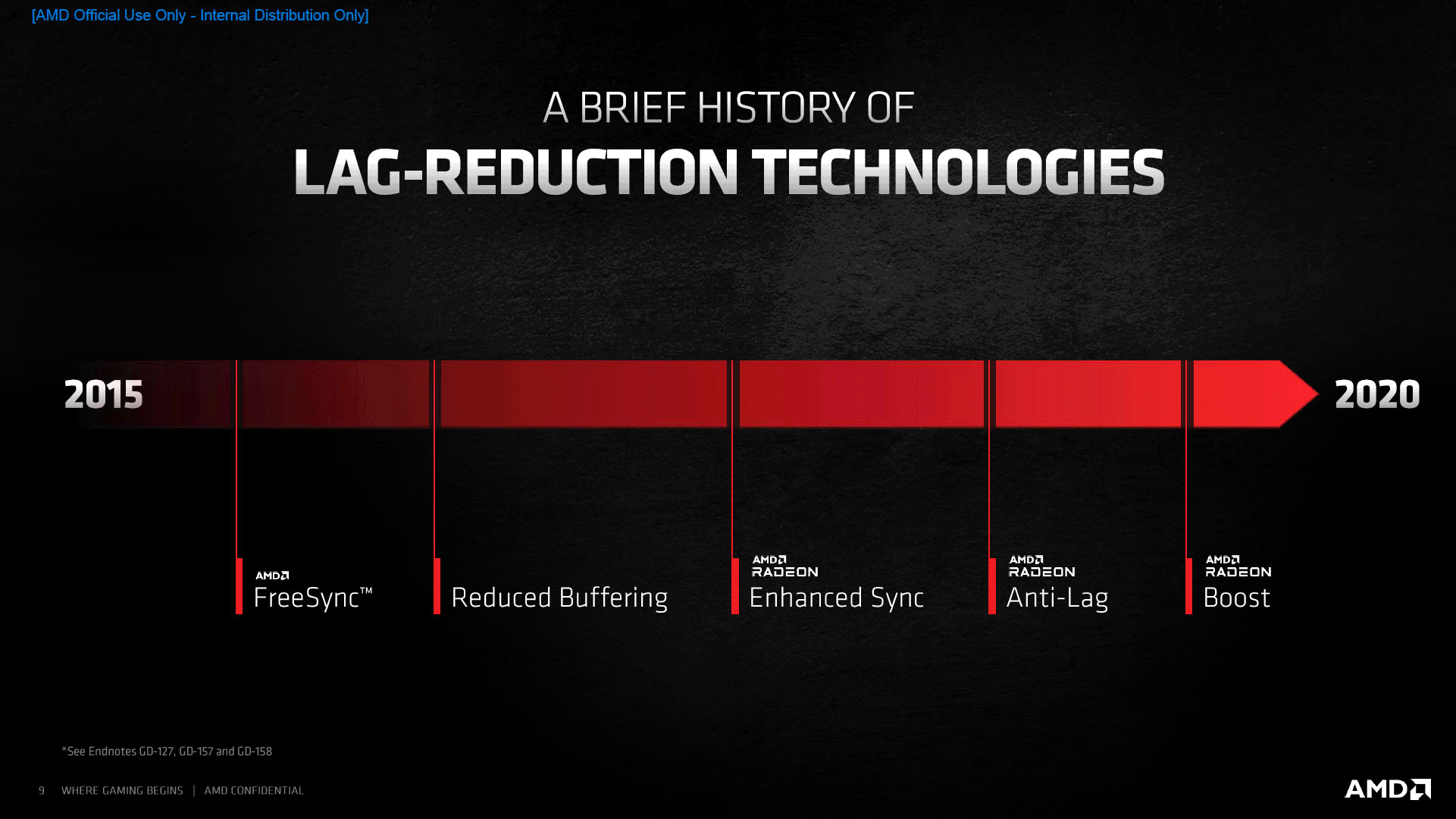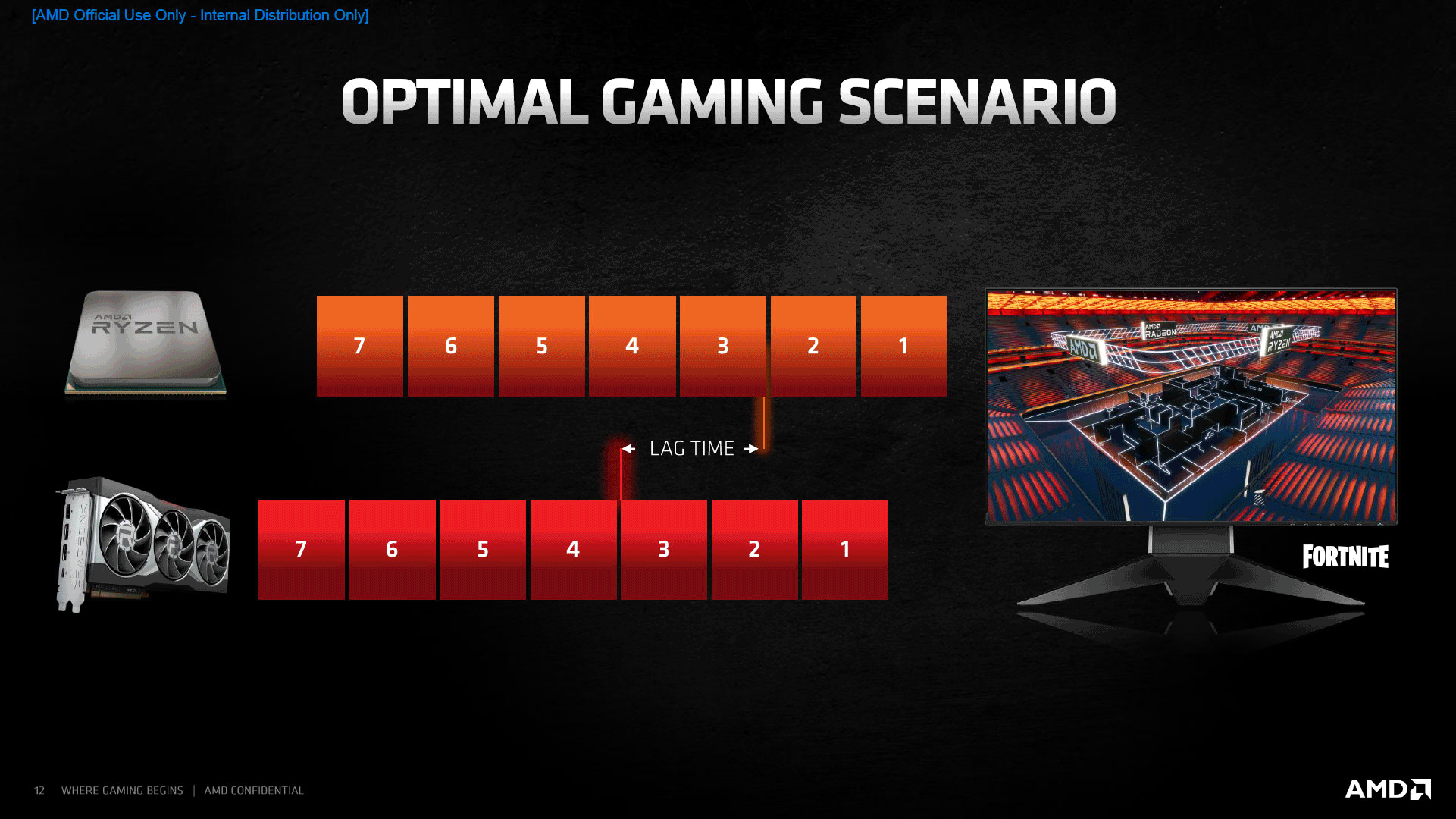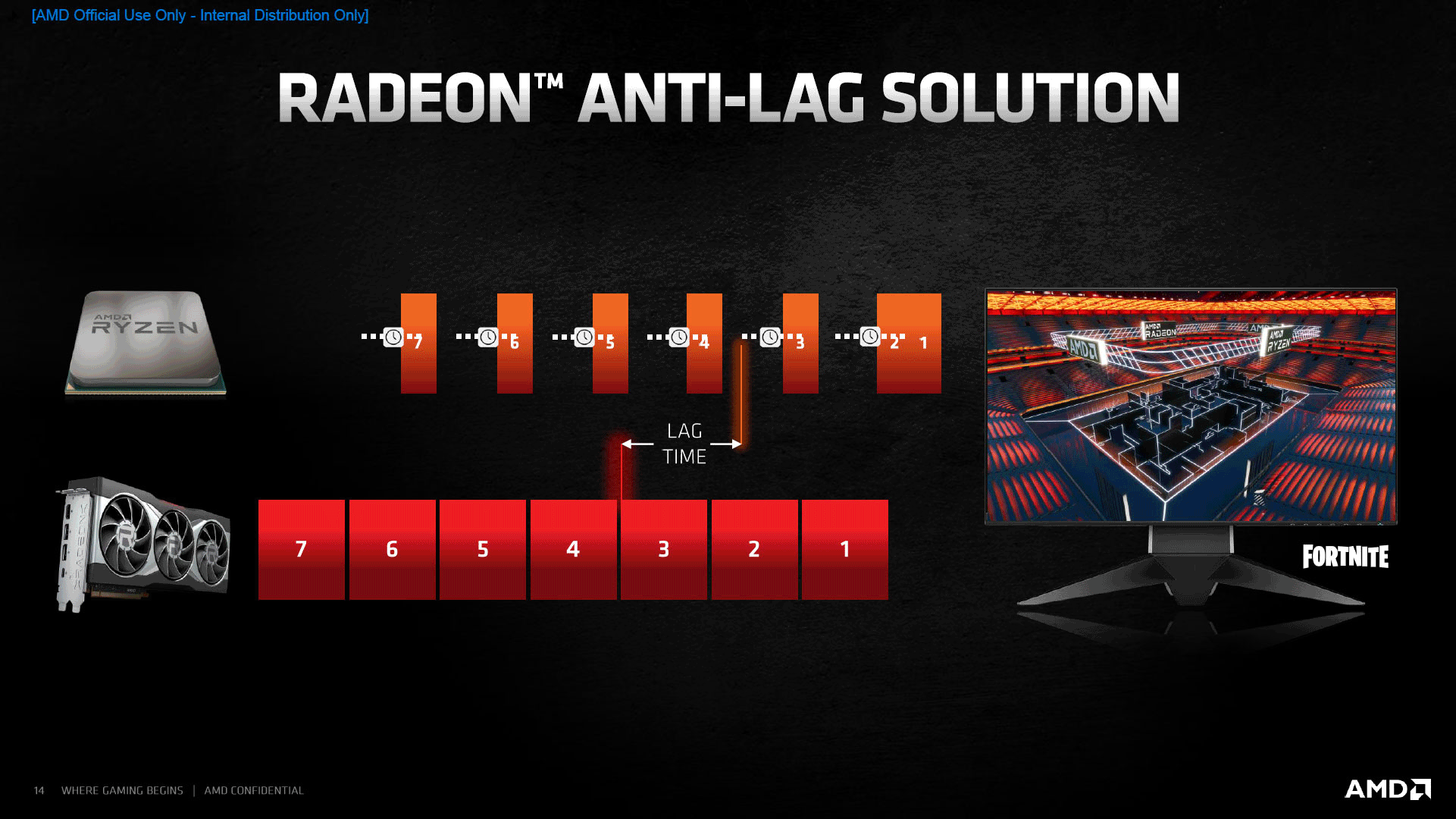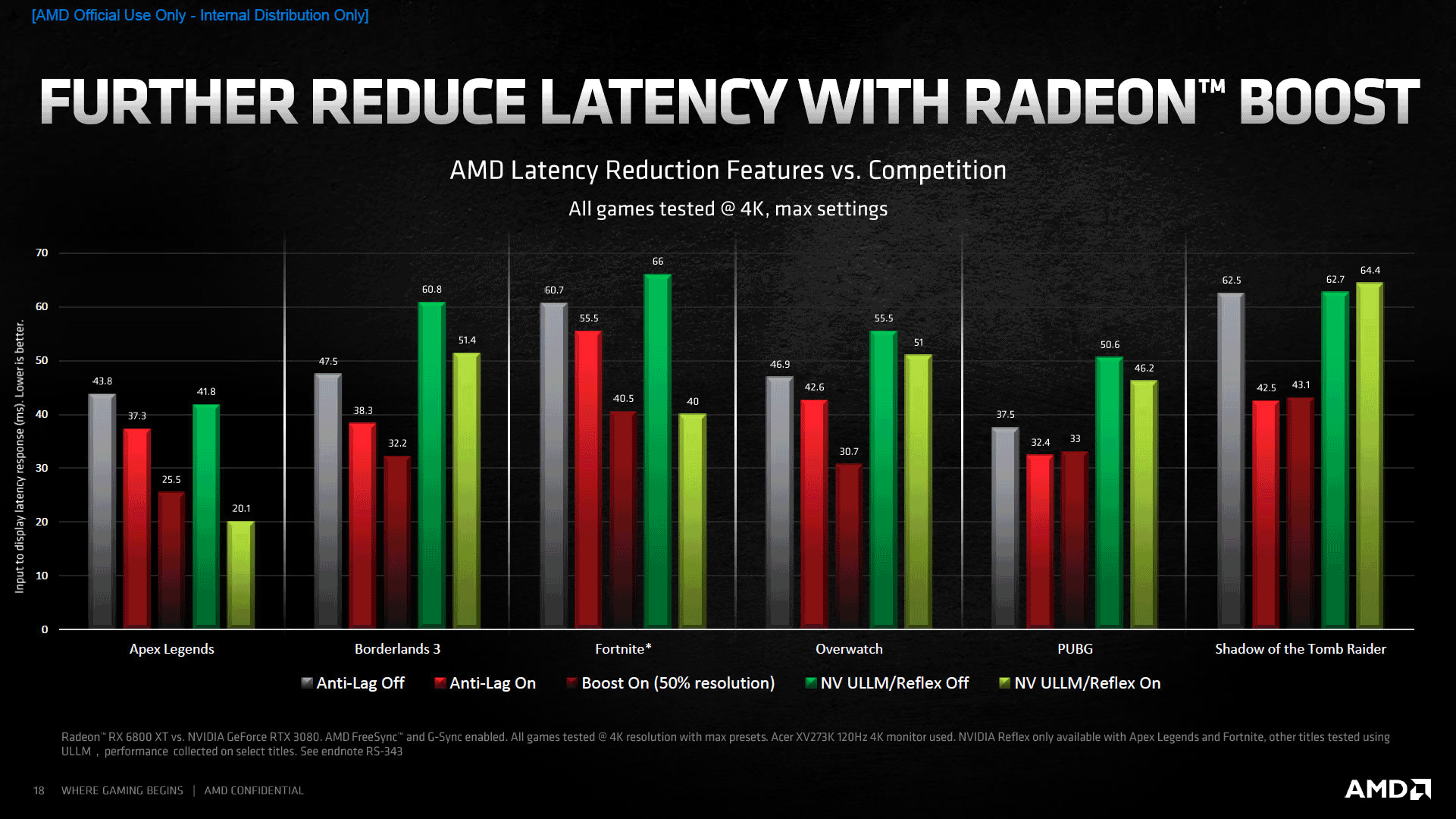
Poursuivons par un sujet poussé par les rouges depuis le lancement de Navi en juillet 2019, la latence en jeu. Après avoir introduit Anti Lag lors de cet évènement, AMD a lancé quelques mois plus tard Radeon Boost. Ce dernier correspond en fait à un système de définition dynamique, permettant donc d'augmenter le nombre d'images par secondes et réduisant ainsi la latence lors des mouvements rapides. C'est bien-sûr au prix d'une dégradation de la qualité visuelle, mais compte-tenu du flou de mouvement, l'impact est peu sensible selon les rouges (les joueurs compétitifs s'attachent de toute façon rarement à ce point). Cette fonctionnalité tout comme Anti-Lag, sont bien entendu fonctionnels avec RDNA2. AMD indique que ses propres solutions permettent de devancer la concurrence, nous tâcherons à l'avenir de vérifier à l'avenir cette assertion en utilisant LDAT.
![Technologie d'amélioration de la latence par AMD [cliquer pour agrandir]](/images/stories/articles/gpu/rdna2/latence_t.gif "Ultra bouzotron HD max def")
Voilà ce que nous pouvions vous dire sur l'architecture RDNA2, voyons sa mise en œuvre au travers du premier GPU l'employant page suivante.
|
|
| Un poil avant ?RX 6800 XT et boîtiers mini-ITX, l'impossible mariage ? | Un peu plus tard ...8 coeurs / 16 threads à 4 GHz, tout Ryzen vs Comet Lake | |