Test • NVIDIA GeFORCE RTX 3080 |
————— 16 Septembre 2020



Test • NVIDIA GeFORCE RTX 3080 |
————— 16 Septembre 2020
Si vous n'êtes pas ou peu familiers avec les architectures modernes du caméléon, nous vous invitons donc à relire les pages que nous avions dédiées à ces dernières, en particulier celles dévolues à Maxwell, Pascal et bien sûr Turing, pour vous aider dans la compréhension du présent article. La dernière citée marquait une réelle rupture par rapport aux précédentes (hormis Volta mais qui n'a jamais été déclinée en version Gaming), du fait d'une réorganisation interne et de l'intégration de nouvelles unités liées au Ray Tracing et à l'IA. On peut par analogie, considérer Ampere davantage comme une évolution de Turing, même si les changements sont significatifs selon certains aspects .
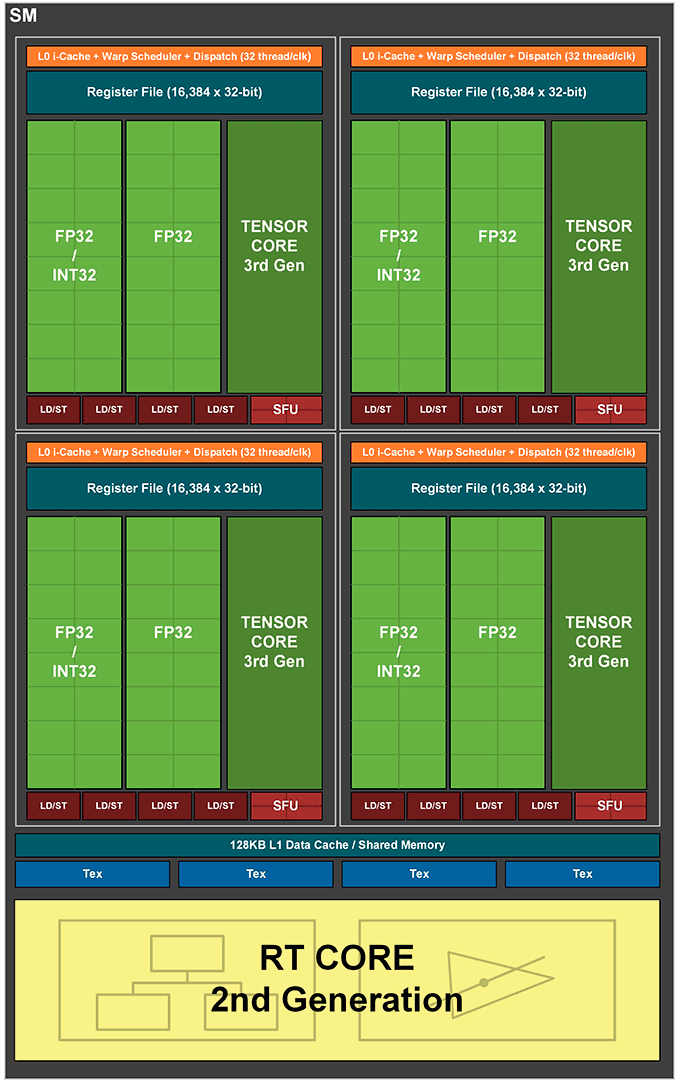
Précisons avant de détailler cela, que la version destinée aux activités professionnelles telles le Machine Learning, diffère sensiblement. Nous vous renvoyons vers cette brève, si vous êtes intéressés par le sujet. Comme souvent, c'est au sein des SM (Streaming Multiprocessor) que la plupart des modifications ont lieu. Pas de rupture significative ici, mais un renforcement de certains points là où c'était nécessaire, en particulier la puissance de calcul. Pour ce faire, Nvidia a tout simplement doublé le nombre d'unités FP32 par SM, portant leur nombre total à 128. Toutefois, ce doublement ne conduira pas forcément à des performances par cycle multipliées par 2 dans ce domaine, comme nous allons le voir. Pour cela, jetons un coup d’œil au schéma de principe d'un SM Ampere. On voit effectivement 2 blocs FP32 par partition (le SM est toujours subdivisé en 4), par contre un des deux blocs voit sa dénomination associée à INT32. Qu'est-ce que cela peut donc bien signifier ?
![SM Ampere [cliquer pour agrandir]](/images/stories/articles/gpu/ampere/architecture/sm_ampere_t.png "La magie de la loupe, sans loupe")
Un SM Ampere
Petit retour en arrière : avec Turing (Volta plus précisément), Nvidia indiquait avoir créé un second chemin de données (data path) pour permettre l'exécution concomitante d'une opération sur entier et d'une autre en virgule flottante. Cette possibilité permet d'après les études de différents shaders (à l'époque) menées par le caméléon, d'augmenter de 36% l'utilisation des unités FP32. En effet, ces dernières ne doivent plus "laisser la place" aux INT32 lorsqu'il y a besoin de calculer un entier, chacun disposant à présent de son propre chemin de données. Cette modification est très coûteuse à mettre en place en termes de bande passante mémoire, c'est pourquoi le caméléon s'est penché sur la possibilité de maximiser les gains liés à cette dernière. Puisque le chemin de données dédié aux INT32 est loin d'être saturé lors de l’exécution de shaders, comment mettre à profit cette ressource potentielle ? La réponse a donc été d'ajouter sur Ampere, 64 unités FP32 au sein du SM, mais qui vont cette fois devoir partager le même chemin de données que les INT32 (façon CUDA Cores pré-Volta donc).
C'est le sens de la représentation graphique du SM, puisqu'il ne s'agit en rien d'une fusion d'unités, juste de la représentation simplifiée d'INT32 et FP32 distinctes, mais partageant le même data path (le second bloc de FP32 disposant lui de son propre chemin de données dédié). Mécaniquement, le taux d'utilisation de ces FP32 sera directement corrélé à celui des INT32, et comme les premières ont vu leur nombre total doublé par SM, alors la probabilité de sollicitation des secondes, grandit en conséquence durant l'exécution de shaders. Tout dépendra donc des usages : si un programme donné n'a pas besoin de calculer d'entiers, alors le débit réel en flottants sera bel et bien doublé par cycle. Si par contre le besoin en entiers est significatif, alors le bloc de FP32 partageant le même chemin de données que les INT32, sera impacté en conséquence. Vous noterez qu'à aucun moment nous n'avons utilisé le terme Cuda Core. En suivant le lien précédent, vous retrouverez la définition qu'en donnait Nvidia, lors du lancement de Fermi en 2010. Ainsi, difficile de parler de réel doublement ici, même si ce terme Cuda Core n'est en réalité qu'une simple appellation marketing.
Parce qu'en définitive, rien n'empêche de voir GA102 avec non pas 10752 CC comme l'indique Nvidia, mais seulement la moitié, c'est à dire 5376, dotées toutefois de possibilités supplémentaires : traitement de 2 FP32 en parallèle ou 1 FP32 + 1 INT32 à chaque cycle, alors que seule la seconde option est valable pour Turing. Toutefois, en comptant ainsi, l'écart en nombre de CC séparant TU102 de GA102, n'est plus que de 16,7%. Bien moins impressionnant, n'est-ce pas ? Il est certainement plus pratique de communiquer sur un nombre (plus que) doublé, que d'expliquer un gain certes plus modeste en nombre, mais s'accompagnant d'une puissance accrue pouvant être bien plus importante, suivant l'usage fait, desdits Cuda Cores. Mais laissons là ces considérations marketing, ce qu'il est important de retenir de cette histoire de chiffres et dénominations, vous l'aurez compris, c'est une augmentation très variable de la puissance de calculs en virgule flottante. Nvidia précise que les algorithmes de dé-bruitage utilisés en Ray Tracing, en sont particulièrement friands. Pour ce genre de tâches, Ampere devrait donc exceller, en mettant à profit ses unités FP32 additionnelles.
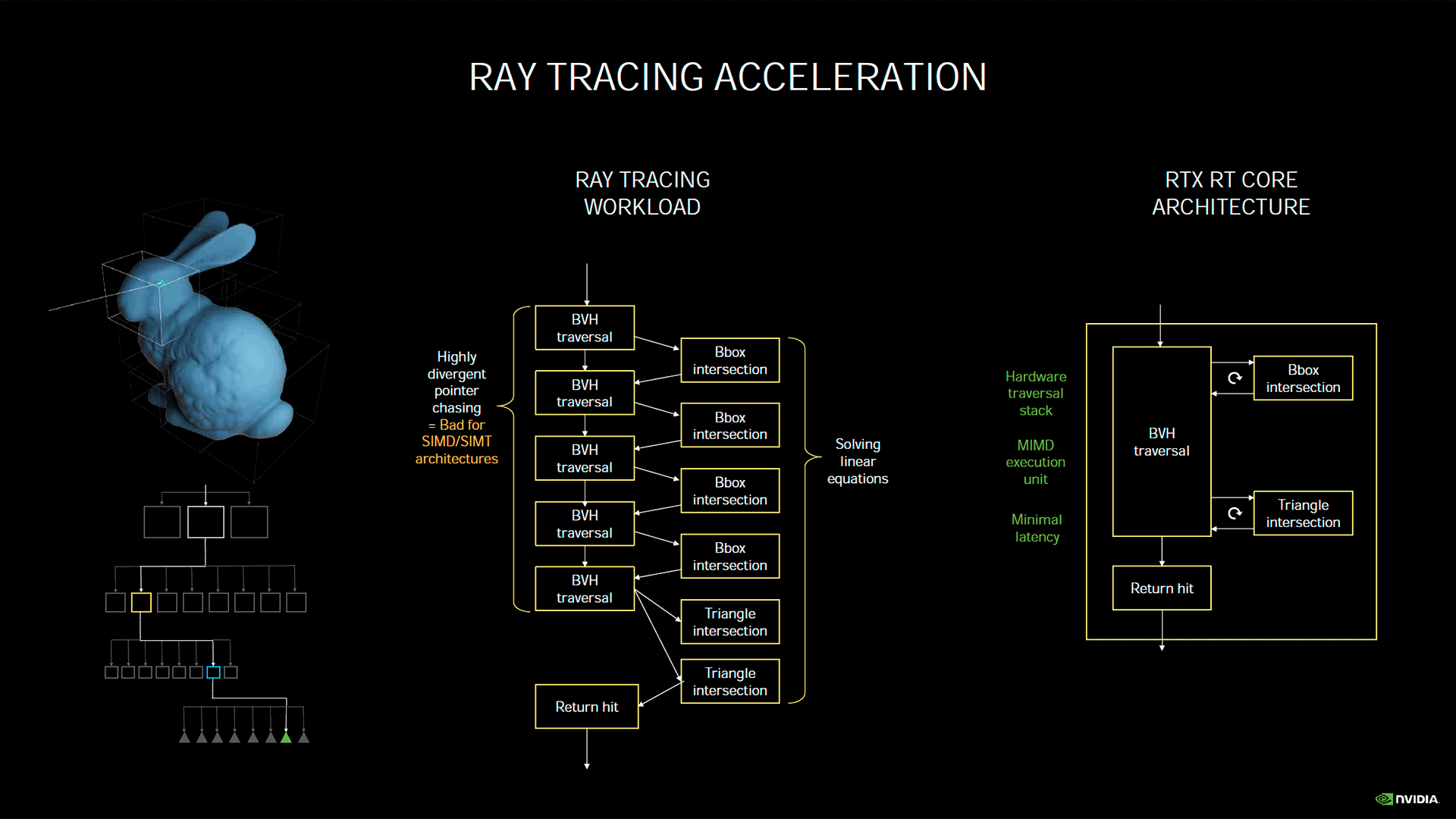
Turing avait marqué une rupture en étant la première architecture à inclure des unités dédiées à l'accélération matérielle du Ray Tracing. Plus précisément de l’algorithme BVH (Bounding Volume Hierachy), vous retrouverez tous les détails le concernant au sein de cette page. Ampère utilise de son côté, des RT cores de seconde génération. Mais avant de détailler les nouveautés, voyons d'abord comment sont organisés ces RT Cores, puisque les verts ont (enfin !) été davantage loquaces quant à leur organisation interne. Le principal souci du BVH réside dans le pointer chasing, c’est-à-dire l’obligation du programme de sauter d’une zone mémoire à une autre sans ordre logique, ce que détestent particulièrement les organisations SIMD/SIMT (Single Instruction on Multiple Data / Single Instruction Multiple Threads) des GPU modernes. C'est pourquoi, plutôt que d'exécuter un algorithme fonctionnant sur les unités de calcul traditionnelles du GPU, Nvidia a préféré opter pour une unité spécialisée utilisant une organisation MIMD (Multiple Instructions on Multiple data), qui était, fait amusant, celle des "vieux" GPU. Ainsi, les RT Cores intègrent trois composants logiques : le premier effectue la traversée de l’arbre contenant la hiérarchie des volumes (les boites) possiblement frappés par le rayon, le second se charge de trouver si une telle intersection a lieu dans le volume, et le dernier calcule le triangle touché au sein dudit volume.
![Fonctionnement RT Core [cliquer pour agrandir]](/images/stories/articles/gpu/ampere/architecture/rt_core_t.png "Si vous cliquez, vous cliquez.")
Le fonctionnement d'un RT Core
Évoquons à présent de la deuxième version de ces RT Cores, que l'on retrouve cette fois sur Ampere. Le premier point notable, est l'augmentation substantielle du débit de ces derniers. En analysant le fonctionnement de ses RT Cores au sein de divers jeux, Nvidia a constaté qu'en pratique le composant calculant les intersections des rayons avec les triangles, était le maillon faible de la précédente implémentation. Celui-ci a donc été sérieusement renforcé, si bien que le caméléon indique un doublement du débit de ce dernier au sein des nouveaux RT Core, par rapport à la première itération. Bien sûr, le Ray Tracing ne se limite pas à ce composant ni au seul BVH, toutefois avec les modifications apportées aux autres points du GPU, les performances avec ce rendu progresseraient jusqu'à 70%, selon les conditions. C'est tout sauf négligeable, et plus que bienvenu vu la gourmandise de ce dernier. Second point mis en avant, l’accélération matérielle du flou cinétique lors d'un rendu RT. Késako ?
![motionblur t [cliquer pour agrandir]](/images/stories/articles/gpu/ampere/architecture/motionblur_t.gif "Enlarge your pe...icture")
Principe de fonctionnement du motion blur en RT et sa prise en charge par Ampere
Le flou cinétique ou motion blur consiste à générer un effet de stries ou traînées pour les objets en déplacement rapide. Il a pour origine le temps d'exposition nécessaire pour imprimer l'image sur une pellicule. C'était particulièrement important dans l'industrie du cinéma, car cela permettait d'apporter un visionnage fluide malgré un débit pourtant faible (24 i/s). C'est aussi pour cela qu'en jeu vidéo, une cadence plus élevée est nécessaire pour obtenir cette sensation de fluidité en l'absence de motion blur. Pour un GPU, l'astuce consiste donc ici à créer artificiellement cet effet. Il existe plusieurs techniques permettant cela, la plus répandue étant d'échantillonner la position d'un même objet à des instants différents et "mélanger" le tout. Il faut généralement ajouter un post-traitement pour supprimer le bruit et autres artefacts visuels (images fantômes, etc.) résultants. Le résultat n'est malgré cela pas toujours convaincant, la faute à des images souvent maculées, la présence d'artefacts persistants (images fantômes), voire l'absence de flou sur les matériaux translucides.
Le Ray Tracing est capable de proposer un rendu bien plus propre de cet effet, malheureusement, il est beaucoup plus long, comme souvent. En effet, lors d'un rendu de type lancer de rayons, tous les triangles composant la scène sont définis au sein du BVH. Lorsqu'un rayon est lancé, ce dernier effectue ses tests pour déterminer si un triangle est touché, et si c'est le cas, les informations de l'intersection sont échantillonnées et renvoyées. Si on ajoute maintenant à cela le flou cinétique, alors plus aucun triangle n'a de position fixe au sein du BVH. Il est donc nécessaire de fournir à ce dernier, la position de chaque triangle suivant une ligne temporelle, car chaque rayon va exister à un moment différent pour générer le flou cinétique. C'est le rôle de la nouvelle unité incluse dans les RT Cores d'Ampere, ce qui permet selon Nvidia, de multiplier par 8 la réalisation de cet effet par rapport à Turing. Cela reste malgré tout fortement complexe, l'usage sera donc limité à du rendu de postproduction, via la prise en charge au sein de logiciels dédiés (Blender, V-Ray, Arnold, etc.).
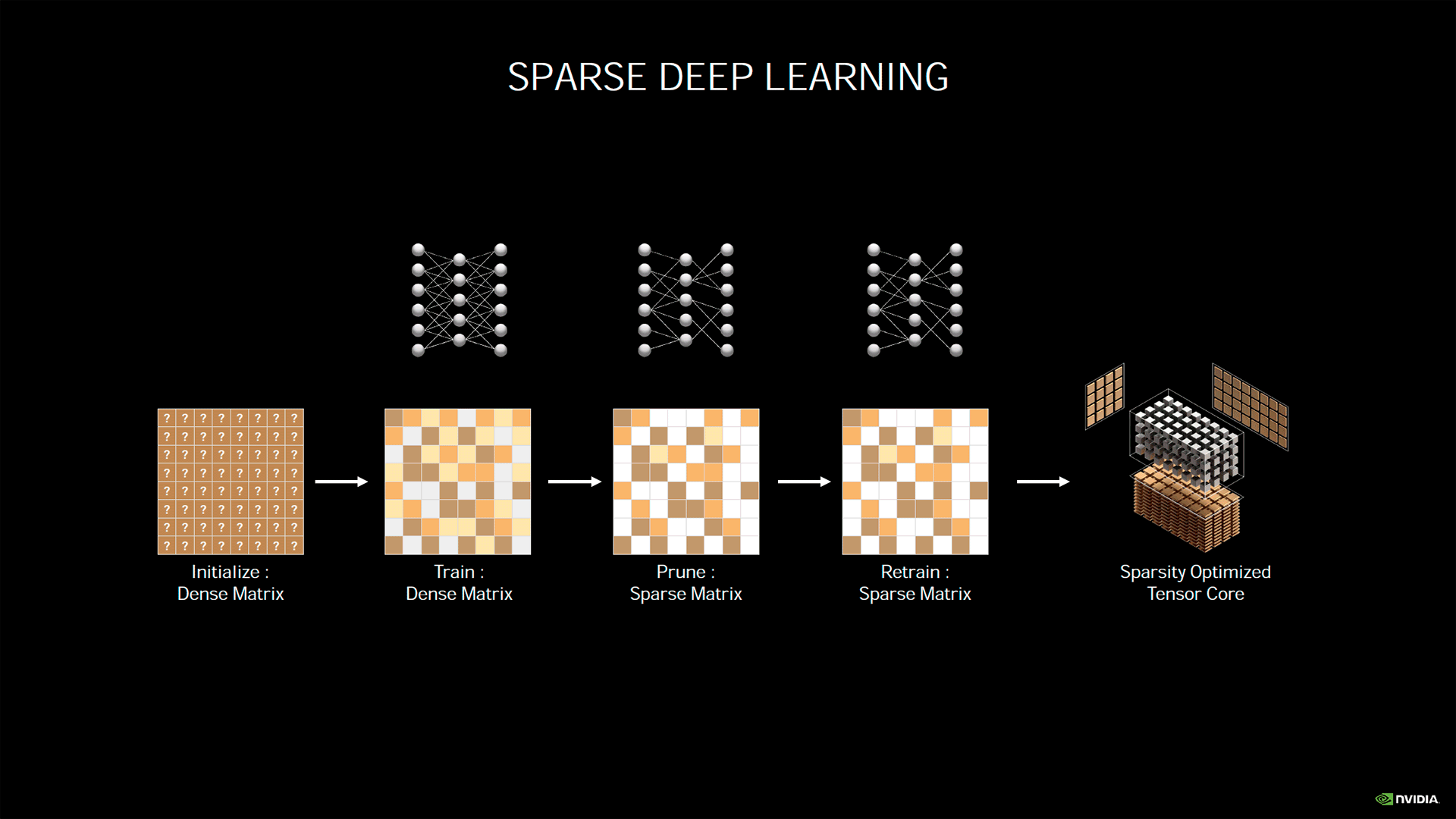
Au sein des SM Ampere, on remarque principalement la division par 2 du nombre de Tensor Cores par rapport à Turing (de 8 à 4 par SM). Toutefois, ces derniers sont largement retouchés, de quoi compenser plus que largement cette réduction. Ainsi, ils intègrent le calcul dit sparse, qui consiste à effectuer les opérations matricielles courantes sur des matrices dites creuses, c’est-à-dire contenant une majorité de zéros. Représentables de manière plus compacte en mémoire, les matrices creuses ont une application toute particulière dans le domaine du Machine Learning, dans lequel de nombreux réseaux de neurones réalisent, en interne, des opérations sur ces matrices creuses. Dans le but de communiquer des chiffres toujours plus imposants, NVIDIA ajoute donc aux opérations réellement effectuées, celles qui le seraient et donneraient zéro, dans le cas d’une multiplication ne prenant pas en compte la sparsite.
![Calcul Sparse [cliquer pour agrandir]](/images/stories/articles/gpu/ampere/architecture/sparse_t.png "Si vous cliquez, vous cliquez.")
Le calcul sparse via les Tensor Cores d'Ampere
Fort de ces changements, les verts annoncent pouvoir appliquer la technologie DLSS de manière toujours plus performante. Qu’est-ce que cela signifie ? Eh bien, pour pouvoir jouer en 8K, le DLSS serait (une nouvelle fois) appelé à la rescousse, dans des proportions toujours plus impressionnantes. Voyez donc:
| Définition d'affichage | Définition de rendu |
|---|---|
| FullHD (1920x1080 px) | HD (1280x720 px) |
| QHD (2560x1440 px) | Jensen's Favorite (1706x960 px) |
| UHD (3840x2160 px) | FullHD (1920x1080 px) |
| 8K (7680x4320 px) | quasi-QHD (2560x1400 px) |
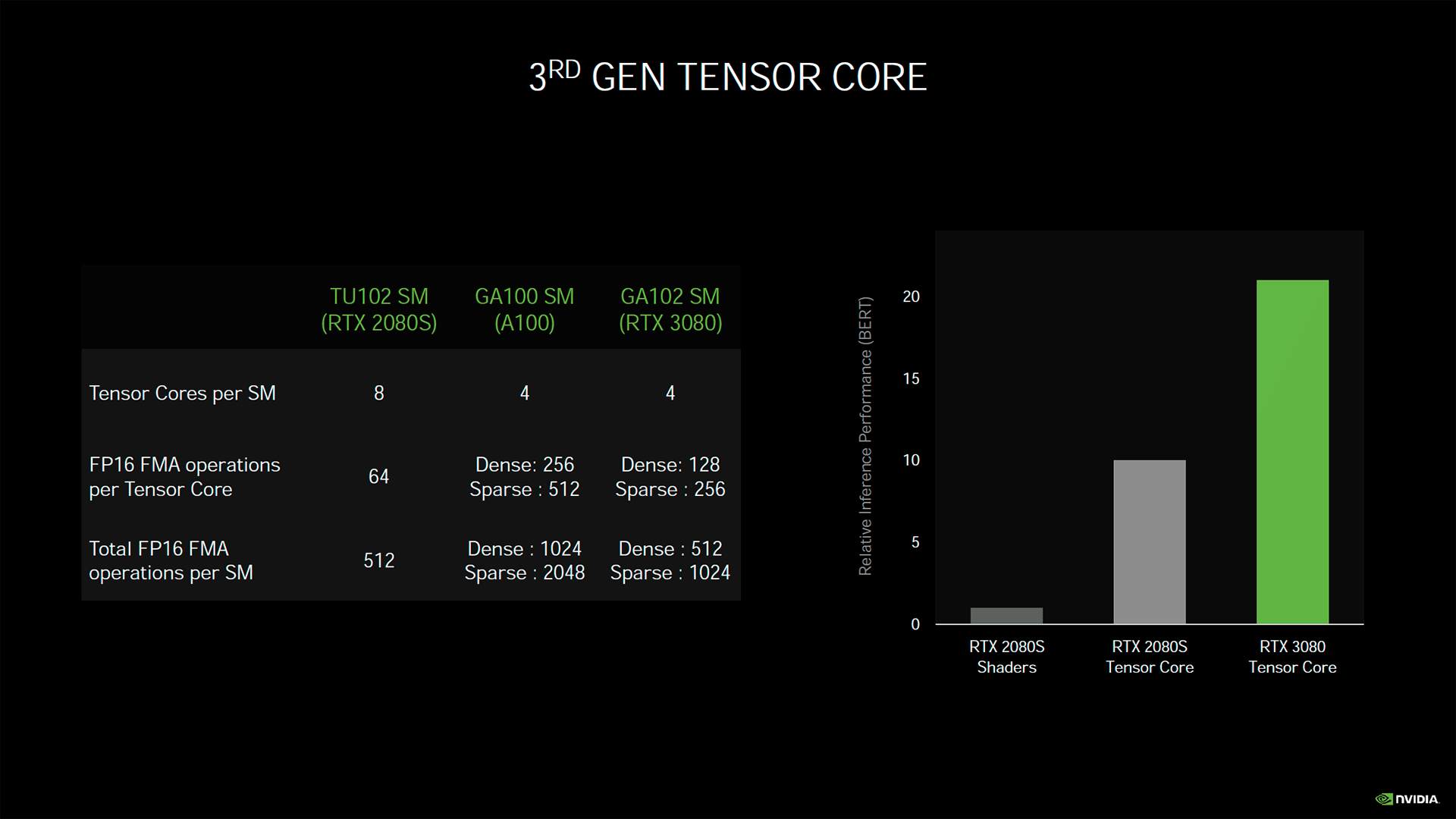
Oui, vous avez bien lu : l’IA devrait permettre de multiplier par 9 le nombre total de pixels affiché tout en évitant le classique flou de la mise à l’échelle habituelle. Techniquement, rien n’est impossible au vu du matériel embarqué, avec une capacité en inférence progressant très nettement du fait de cette nouvelle version. On notera également que ces Tensors Cores ont été revus en interne pour offrir un débit 2x plus rapide en 1/2 précision (non sparse) que la génération précédente. Ils prennent également en charge de nouveaux formats, là aussi nous vous renvoyons à cette brève pour de plus amples détails. Ainsi, malgré la division par deux du nombre de Tensor Cores par SM par rapport à Turing, ils sont capables de fournir les mêmes performances en calcul classique. Pour être plus précis sur le sujet, le caméléon semble d'ailleurs les brider à la moitié de leur débit nominal (cf. résultat GA100) sur cartes grand public, à voir si les futures cartes professionnelles qui utiliseront GA102, retrouveront effectivement le même niveau de performances des Tensor Cores, que ceux équipant GA100.
![inference ampere t [cliquer pour agrandir]](/images/stories/articles/gpu/ampere/architecture/inference_ampere_t.png "Même pas cap' de cliquer")
Les performances des Tensor Cores d'Ampere
Le caméléon ne s'est pas limité aux seules unités de calcul, car doubler leur débit ou nombre est bien beau, encore faut-il pouvoir les alimenter correctement. Pour cela, il a repris la hiérarchie existante en améliorant certains points. Ainsi, un SM Ampere est toujours organisé en 4 partitions, chacune étant pilotée par un couple ordonnanceur / dispatcheur (32 threads/cycle). Ils incluent en sus des 16 INT32 et 32 FP32, 4 unités de texturing, 4 unités load/store pour les accès mémoire, un cache L0 dédié aux instructions, 64 Ko pour les registres 32-bit, 4 SFU traitant des fonctions complexes (Cos, Sin, etc.) en simple précision, un Tensor Core de troisième génération et un RT Core de seconde génération. Le cache L1 est tout comme Turing, unifié avec la mémoire partagée et le cache de textures. Pour prendre en compte l'augmentation du nombre de FP32, son débit est par contre doublé et sa capacité augmente de 33% à 128 Ko par SM. Précisons que le partage de ces 128 Ko entre L1 & Share MEM est largement plus varié qu'il ne pouvait l'être à l'époque de Turing (uniquement 2 répartitions possibles), en utilisation Compute :
| L1 | Mémoire Partagée |
|---|---|
| 128 Ko | 0 Ko |
| 120 Ko | 8 Ko |
| 112 Ko | 16 Ko |
| 96 Ko | 32 Ko |
| 64 Ko | 64 Ko |
| 28 Ko | 100 Ko |
Dans un contexte de charge graphique par contre, la répartition est la suivante : 64 Ko L1 + Texture cache (x2 / Turing), 48 Ko de mémoire partagée et 16 Ko réservés pour diverses opérations au niveau du pipeline graphique. Au total, GA102 complet inclut pas moins de 10 752 Ko de L1, à comparer aux 6912 Ko de Turing, disposant toutefois de moins de SM et de moins d'unités au sein de ces derniers. Quid du cache L2 à présent ? Eh bien pas de changement indiqué par Nvidia, il se compose donc toujours de 512 Ko associés à chaque contrôleur mémoire 32-bit, soit 6 Mo en tout à l'instar de TU102. On est donc bien loin des 48 Mo d'un GA100, ce dernier est toutefois orienté Compute pur, avec la capacité de subdiviser chaque GPC en instance de GPU autonome, ceci expliquant cela. Passons à présent à une vue plus macroscopique du GPU.
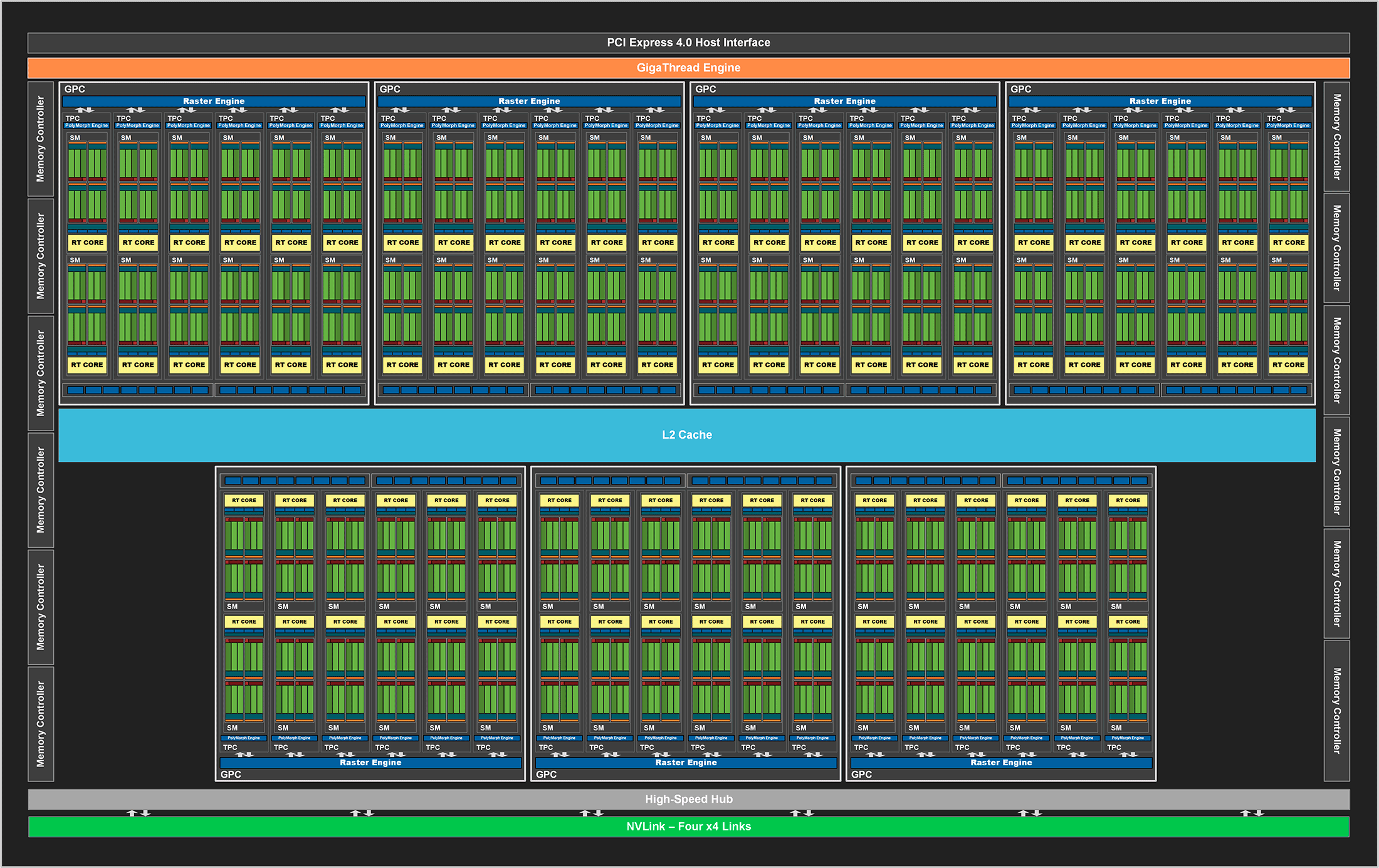
![Diagramme GA102 [cliquer pour agrandir]](/images/stories/articles/gpu/ampere/architecture/ga102_full_diagram_t.png "Même pas cap' de cliquer") Le diagramme d'un GA102 complet
Le diagramme d'un GA102 complet
Si vous êtes familiers des architectures vertes, vous ne serez pas désorientés par ce diagramme. Ainsi, les SM sont à l'instar de Turing, inclus par paire au sein de structures nommées TPC (Texture Processor Cluster), support du Polymorph Engine, c'est-à-dire les unités dédiées à la géométrie (vertice, tesselation). Si le nombre d'unités de calculs explose avec Ampere du fait de leur doublement par SM, ce n'est pas le cas des autres unités (TMU, géométriques, etc.) qui elles ne progresseront qu'à hauteur de l'inflation du nombre SM/TPC, entre TU102 et GA102 (+16,7 %). Les TPC prennent de leur côté place par groupe de six au sein des GPC (Graphics Processing Cluster), disposant d'une unité de rastérisation capable de traiter un triangle par cycle. Au total, GA102 comprend 7 GPC, soit une unité de plus que les GM200, GP102 et TU102, tout du moins dans leurs versions complètes respectives.
Autre changement notable, les ROP (Render Output Unit) ne sont plus associées aux contrôleurs mémoire / cache L2, mais directement au GPC cette fois, et ce par paire de partitions (8 ROP soit 16 en tout). Ainsi, la désactivation d'un contrôleur mémoire (qui reste lié au cache L2), ne conduira plus à la désactivation de ROP. Il est donc temps de faire les comptes : 7 GPC x 2 partitions x 8 ROP = 112 ROP en tout. C'est la première fois que la barre des 96 est franchie sur une GeForce, cette valeur maximale étant inchangée depuis Maxwell 2. Le fillrate va donc progresser en conséquence. Seule la Titan V CEO Edition en propose davantage avec 128, mais ce n'est pas une carte grand public.
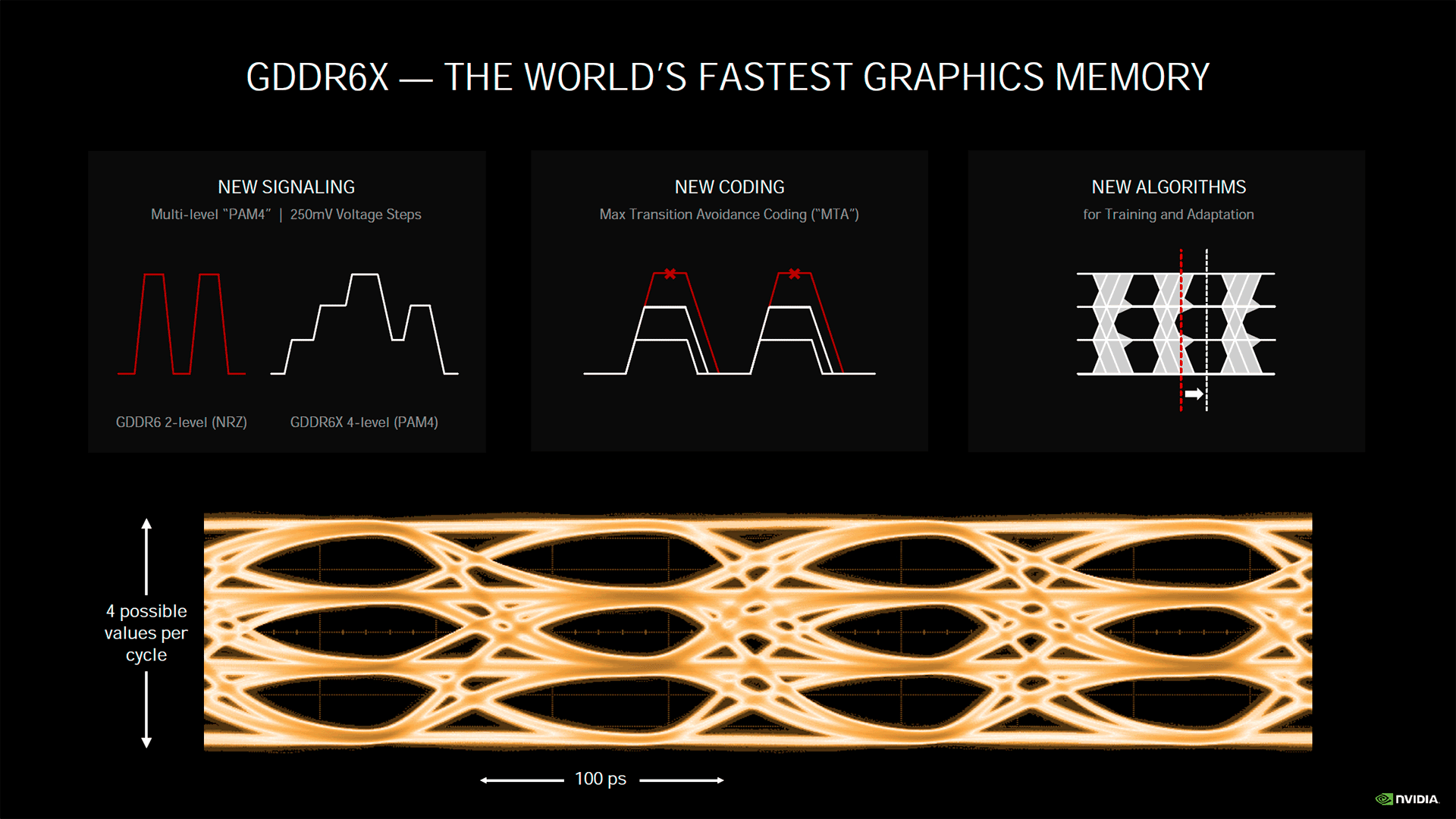
La gestion mémoire évolue elle aussi : si le caméléon conserve des contrôleurs 32-bit, NVIDIA a jeté son dévolu sur un nouveau type de mémoire, la GDDR6X. Après la GDDR5X sur Pascal, la GDDR6 avec Turing, voici donc la troisième fois consécutive que les verts inaugurent un nouveau type de mémoire avec une nouvelle architecture. Cela montre évidemment que le besoin en bande passante mémoire croît logiquement avec la puissance de calcul, mais plutôt que d'élargir le bus ou opter pour la HBM, le caméléon trouve préférable de choisir des puces plus rapides. La GDDR6 sera tout de même utilisée sur les versions moins huppées des GeForce Ampere, mais le haut de gamme s'appuiera donc sur la GDDR6X. Mais qu'est-ce qui différencie ces deux versions hormis le X ? Tout est question de codage de données.
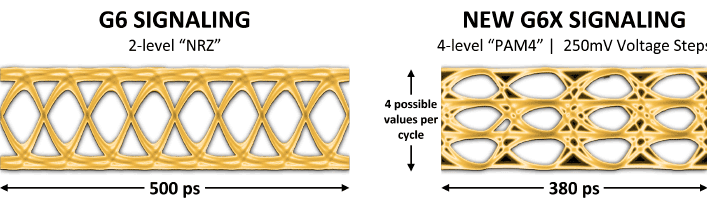
La GDDR6 transfère ses données au travers d'un signal de type PAM2/NRZ (que l'on pourrait traduire en modulation d'amplitude d'impulsion à 2 niveaux), un bit étant transmis via le front montant du signal et le second via le front descendant, fonctionnement classique de la DDR. La GDDR6X adopte quant à elle un codage PAM4, ce qui veut dire que cette fois, 4 bits de données sont transférés (2 par front) au lieu de 2. En d'autres termes, à fréquence équivalente, l'utilisation de PAM4 permet de doubler la bande passante. En pratique, les bits sont encodés à l'aide de 4 tensions différentes (par pas de 250 mV). Si cela peut paraître simple dans le principe, la mise en œuvre est autrement plus ardue. En effet, il faut pouvoir distinguer une valeur (0 ou 1) malgré le bruit (et des entrecroisements de signaux), et ce sur une amplitude moindre, puisque cette dernière est utilisée pour encoder les bits supplémentaires. Pour cela, un nouveau schéma de codage intitulé MTA (Maximum Transition Avoidance), a été développé pour répondre à cette problématique du rapport signal sur bruit.
![Les signaux de la GDDR6X [cliquer pour agrandir]](/images/stories/articles/gpu/ampere/architecture/gddr6x_t.png "Ultra bouzotron HD max def")
Les yeux bien nets des signaux de la GDDR6X
L'objectif est d'éviter que l'amplitude maximale d'un signal puisse franchir tous les paliers de tension et ainsi perturber la lecture des autres signaux. Les signaux pourront donc évoluer soit au sein du seul pas de 250 mV, soit en franchir un second, mais pas plus. En empêchant de telles superpositions, on obtient des "yeux bien propres", propices à une lecture fiable du signal. Enfin, des algorithmes ont été développés pour positionner correctement l’échantillonnage, les courbes des signaux étant amenées à se déplacer légèrement sur la base temporelle, du fait de l'échauffement des composants, ce qui nuirait là aussi à la lecture.
C'est donc un travail en coopération entre Micron (qui livre les modules mémoires) et Nvidia qui a développé les contrôleurs Ad Hoc, qui a permis l’émergence de ce nouveau type de mémoire, avec pour l'heure des modules capables de fournir jusqu'à 21 Gbps par pin. Comme il faut moitié moins de fréquence pour atteindre ce débit par rapport à la GDDR6, on peut donc imaginer une consommation inférieure à débit équivalent. Voilà, c'est tout pour la partie architecture d'Ampere, nous vous proposons page suivante, de découvrir la mise en œuvre de cette dernière et le descriptif d'autres fonctionnalités.
|
|
| Un poil avant ?Live Twitch • Tell Me Why, du narratif posé | Un peu plus tard ...NVIDIA donne ses ambitions pour ARM et son architecture | |