NVIDIA A100 : le nouveau GPU monstre à 54 milliards de transistors |
————— 14 Mai 2020 à 18h50 —— 42091 vues



NVIDIA A100 : le nouveau GPU monstre à 54 milliards de transistors |
————— 14 Mai 2020 à 18h50 —— 42091 vues
Ironie de l’emploi du temps: à peine communiquions-nous à propos des caractéristiques de la supposée RTX 3080 Ti, tout droit sorties des antres de YouTube, que NVIDIA décide de lever le voile sur son architecture Ampère et la première « carte » (un module type mezzanine utilisant une interface NVLink propriétaire, au format SMX) l’intégrant : la A100, reposant sur la puce... roulement de tambours... GA100.
![La A100 : un beau bébé ! [cliquer pour agrandir]](/images/stories/_cg/ampere/nvidia-a100-smx_t.jpg "La magie de la loupe, sans loupe")
Pour ceux qui attendaient des chiplets, chou blanc ! Néanmoins, NVIDIA a tout de même réussi l’exploit d’intégrer 54,2 milliards de transistors dans 826mm², aidé par une gravure en 7nm de chez TSMC. À titre de comparaison, la V100 précédente, d’architecture Volta, en utilisait « seulement » 21,1 dans 815mm², sans compter les piles d’HBM. Car cette A100 est accompagnée de pas moins de 5 stacks de mémoire haute vitesse, pour un total de 40 Go de VRAM et un débit de 1,6 To/sec, soit 73 % de plus que la V100. Au niveau des connexions, ce GPU supporte les technologies de la firme Magnum IO et Mellanox sur les solutions Ethernet et InfiniBand. Pas assez clair ? Voici un petit récapitulatif:
| Caractéristique | Tesla V100 | Tesla A100 | GA100 complet |
|---|---|---|---|
| Architecture | Volta | Ampère | |
| Coeurs CUDA | 5 120 | 6 912 | 8 192 |
|
Streaming Multiprocessor / GPU Processing Clusters |
84/6 | 108/7 | 128/8 |
| Tensor Cores | 640 | 432 (4 par SM) | 512 (4 par SM) |
| Fréquence Boost | 1 530 MHz | 1 410 MHz | Il faudrait une carte pour ça, té ! |
| Cache L2 | 6 Mo | 40 Mo | 48 Mo |
| Contrôleurs mémoires | x8 512-bit | x10 512-bit | x12 512-bits |
| VRAM |
32 Go HBM2 (900 Go/s maximum) |
40 Go HBM2 (5 Stacks) (1,6 To/s maximum) |
48 Go HBM2 (6 Stacks) (1,83 To/s maximum) |
| TDP | 300 W | 400 W | Pas de carte, pas de conso ! |
| PCIe | Gen 3.0 | Gen 4.0 | |
| NVLINK |
2ème génération 300 Go/sec au total |
3ème génération 600 Go/sec au total |
|
| Taille du die | 815 mm² | 826 mm² | |
| Processus de gravure | 12 nm FFN TSMC | 7 nm TSMC (N7) | |
| Performances (FP32/FP64) | 15,7 TFLOPS/7,4 TFLOPS | 19,5 TFLOPS/9,7 TFLOPS | Des TFLOPS sans fréquences ne sont que ruines de l'âme |
| Performances (F16 - Tensor Cores) | 125 TFLOPS | 312 TFLOPS (624 TFLOPS maximum sur des matrices creuses) | |
| Performance (FP64 - Tensor Cores) | Non compatible | 19,5 TFLOPS (sparsitude non supportée) | |
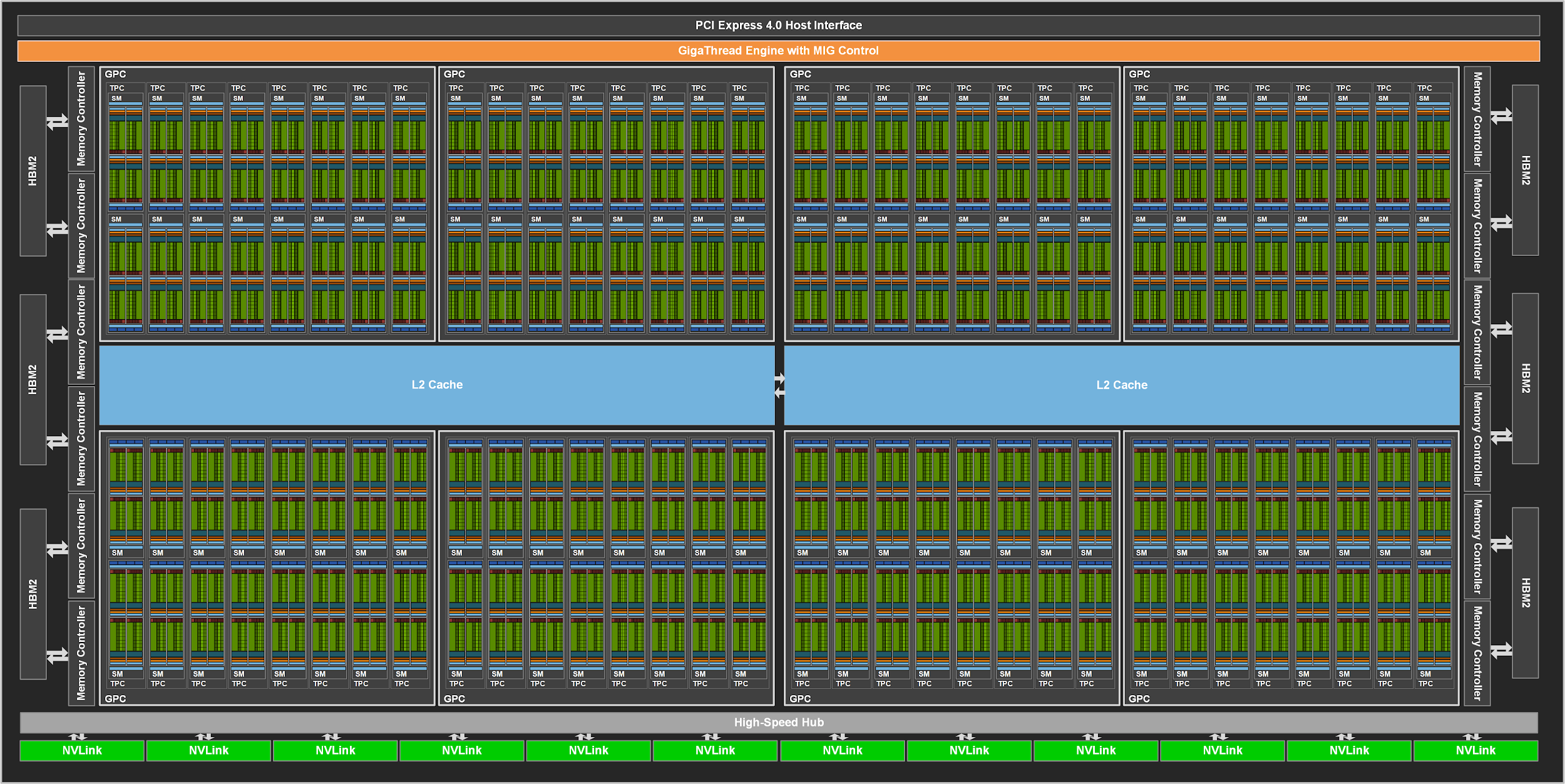
Comme vous pouvez le constater, la A100 utilise une version castrée de la puce GA100, très probablement pour rentabiliser le procédé de gravure coûteux et au rendement encore faible de TSMC, une caractéristique démultipliée par la taille des dies. Ainsi, la A100 n’utilise « que » sept huitièmes des unités présentes matériellement... ce qui est amplement suffisant pour dépasser Volta en matière de nombre de cœurs.
![Une puce de taille ! [cliquer pour agrandir]](/images/stories/_cg/ampere/ga100-full-gpu-128-sms_t.png "Ultra bouzotron HD max def")
Le GA100 dans sa version complète
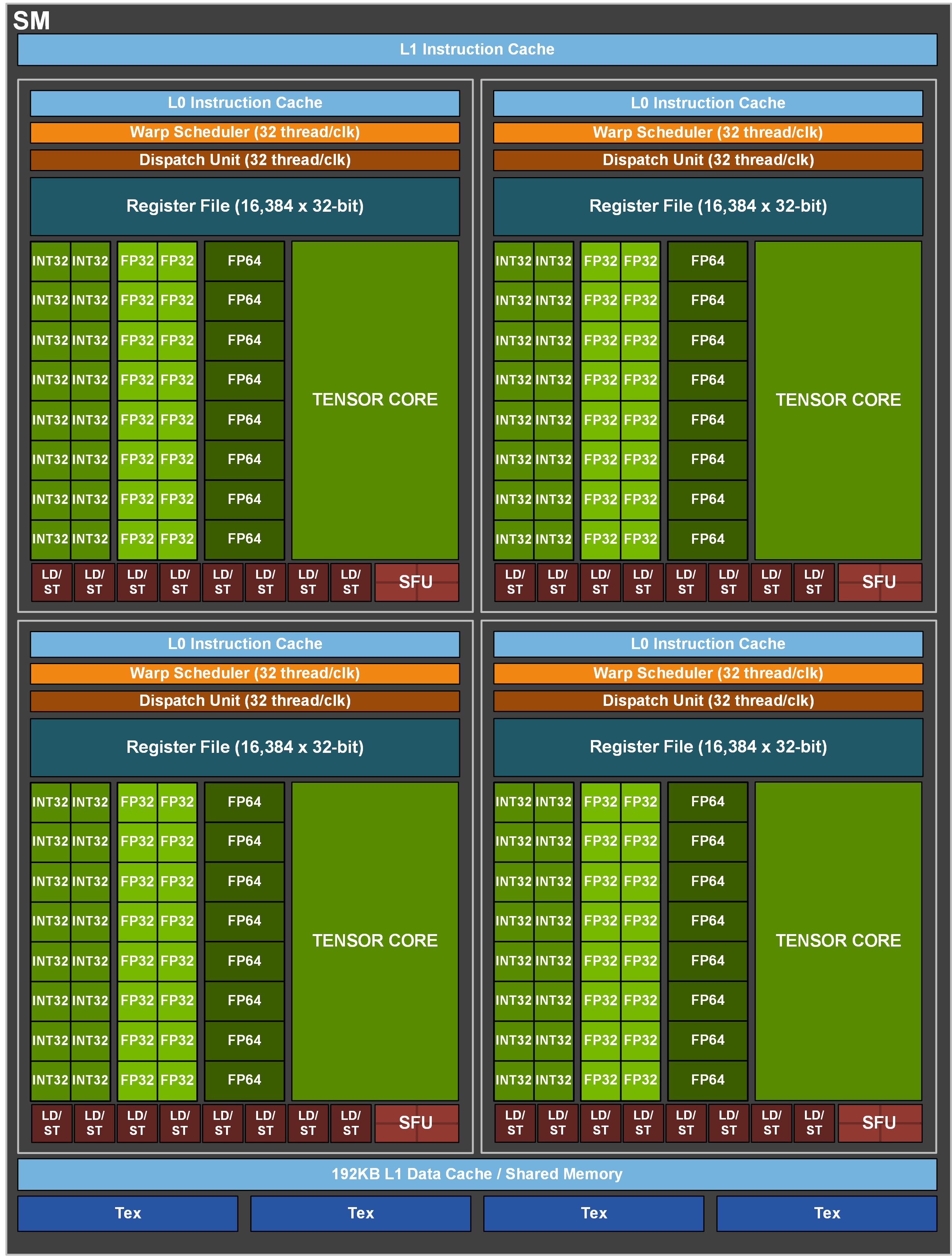
Architecturalement, le GA100 est un assemblage de 8 GPC (GPU Processing Clusters), eux-mêmes composés de 8 TPC (Thread Processus Clusters), qui regroupent 2 SM (Streaming Multiprocessors), lesquels contiennent 4 Tensor Cores. Vous l’aurez remarqué à la lecture des spécifications, le cache L2 a fait un bond d’un facteur 6,7, et est divisé en deux partitions indépendantes (mais synchronisées), permettant d’offrir une bande passante maximale 2,3 fois supérieure à celle de son prédécesseur.
![Un SM version Ampère [cliquer pour agrandir]](/images/stories/_cg/ampere/ga100-sm_t.png "Enlarge your pe...icture")
Vous l’aurez remarqué, mais le nombre total de Tensor Cores est en baisse par rapport à Volta. Cela s’explique par leur passage en version 3 : cette nouvelle mouture permet en effet de traiter des calculs matriciels quelle que soit l’encodage des nombres: FP16, FP32, FP64, binaire, INT8, INT4, mais aussi BFLOAT16, un format popularisé par Intel pour le machine learning, et le TF32. Si vous ne connaissiez pas ce format, hé bien, nous non plus ! Cette nouveauté combine le BFLOAT16 et le FLOAT16 pour ne garder que le meilleur des deux sur... 19 bits (1 bit de signe, 8 d’exposant et 10 de mantisse). Ne cherchez donc plus de lien entre ce TF32 et les 19 bits qu’il utilise, il n’y en a point — contrairement au FP32, qui correspond aux nombres flottants sur 32 bits, ou au INT8, les entiers 8 bits ! Ces Tensors Cores supportent également le calcul sparse sur le TF32, l'INT8, le BF16 et la FP16 (sautez au paragraphe suivant pour une explication plus en détail), ce qui permet d’accélérer grandement les calculs matriciels dans certains cas spécifiques. De plus, ces Tensors Cores ont été revus en interne pour offrir un débit 2 x plus rapide (en simple et double précision non sparse) que la génération précédente, ce qui clôt totalement l’étrangeté de la « diminution » de ces unités de calcul.
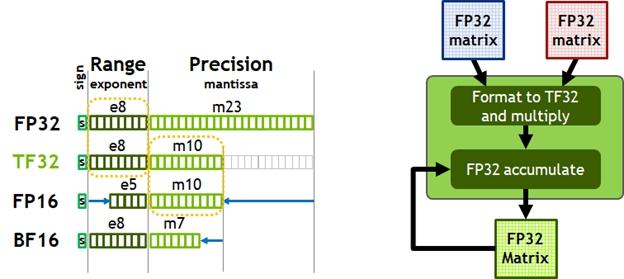
Le TensorFloat, en schéma
Petite parenthèse: le calcul sparse consiste à effectuer les opérations matricielles courantes sur des matrices dites creuses, c’est-à-dire contenant une majorité de zéros. Représentable de manière plus compacte en mémoire, les matrices creuses ont une application toute particulière dans le domaine du machine learning, dans lequel de nombreux réseaux de neurones réalisent, en interne, des opérations sur les matrices creuses. Pour les TFLOPS, NVIDIA ajoute donc aux opérations réellement effectuées celle qui seraient effectuées et donnant zéro dans le cas d’une multiplication ne prenant pas en compte la sparcité, d’où les 624 TFLOPS maximaux de la puce. Vous vous doutez donc que le DLSS, qui repose justement sur du machine learning de cet acabit, devrait en bénéficier — une fois ces cœurs disponibles sur une version grand public — tout comme de l’ajoute du BFLOAT16
Pour ce qui est du calcul général, ce A100 se voit enrichi de deux nouvelles fonctionnalités: la copie asynchrone, permettant d’éviter l’utilisation du register file et du L1 lors de la copie de donnée depuis la VRAM vers la mémoire locale des SM, ainsi que les barrières asynchrones, un mécanisme supplémentaire de synchronisation des cœurs CUDA permettant, d’une part, une utilisation intelligente des copies asynchrone, mais offre également plus de flexibilité dans la gestion de la répartition des tâches, pour les programmes où la parallélisation n’est pas triviale. D’autres améliorations au niveau de l’ordonnanceur, des systèmes de débugage et de gestion des erreurs ont été effectués, ce qui devrait être grandement apprécié par les programmeurs CUDA. Notez également que la quantité de L1 (fusionnée avec l'espace de stockage local) embarqué par SM passe à 192 Ko, soit 50 % de plus que sur Volta. Entre cette augmentation, celle du L2 et la prise en charge matérielle du calcul sparse, les verts ont dû avoir de sacrés retours à propos de goulot d’étranglement mémoire .
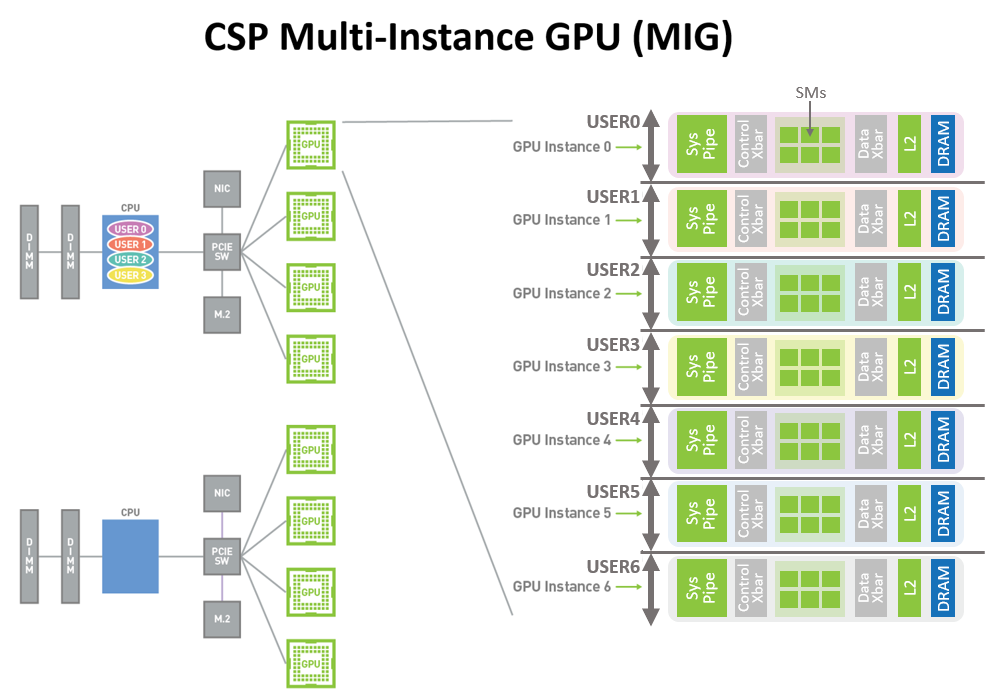
Enfin, NVIDIA a également dans la manche un outil pour les amateurs de machines virtuelles, nommé MIG (Multi-Instance GPU). En effet, alors que les techniques habituelles, à base de PCIe passthrough, géraient le partage des ressources GPU à la granularité... du GPU, c’est-à-dire en associant ou pas une carte à une VM, la A100 permet de scinder virtuellement son GPU selon les GPC, c’est-à-dire en allouant des blocs de 1024 cœurs CUDA aux machines le requérant. À l’ère du cloud gaming, certaines entreprises doivent lorgner juteusement sur cette fonctionnalité !
![Partager son GPU sans ciseaux, c'est enfin possible ! [cliquer pour agrandir]](/images/stories/_cg/ampere/csp-multiuser-mig_t.png "Si vous cliquez, vous cliquez.")
Il faut comprendre Cloud Service Provider pour ce « CSP », soit « fournisseurs de services dans le cloud »
Avec cet A100, NVIDIA enfonce son clou comme leader incontesté des accélérateurs de calcul haute performance pour serveurs. Allié d’un écosystème puissant, le support matériel ajouté devrait sérieusement roxer du poney (et même des licornes, à ce stade). Clairement orienté machine learning — l’offre suivant logiquement la demande — l’A100 se réservera néanmoins aux nouveaux centres de calculs assez dotés financièrement pour s’en procurer. Néanmoins, l’intégration des Tensors Cores issue de Volta dans les RTX grand public a déjà prouvé que bon nombre des améliorations architecturales de la série serveur se retrouvaient, quelques années après, dans les cartes grand public. Doit-on donc s’attendre à des Tensors Cores surboostés sur les RTX3000, du 7nm et un DLSS exaltant ? Impossible de répondre avec exactitude (la HBM étant, par exemple, réservée au monde professionnel chez les verts !), mais nous attendons de pied ferme la prochaine déclinaison, plus accessible !
| Un poil avant ?RTX 3080 Ti : un paquet de rumeurs, beaucoup d'attentes ! | Un peu plus tard ...APU AMD Ryzen 4000G(E) desktop, c'est bon, on les a tous ? | |