Preview • Turing : la révolution Ray Tracing & IA ? |
————— 14 Septembre 2018



Preview • Turing : la révolution Ray Tracing & IA ? |
————— 14 Septembre 2018
Si Pascal (dans sa version Gaming) peut être vu comme une très légère évolution de l'architecture Maxwell 2, ce n'est pas le cas de Turing qui marque des changements notables vis-à-vis de ses devanciers, même s'il en garde les fondements, initiés par Fermi en 2010. Si vous n'êtes pas familiers avec les architectures modernes du caméléon, nous vous invitons donc à relire la page dédiée à ce dernier, mais aussi celles dévolues à Maxwell ainsi que Pascal, pour vous aider dans la compréhension du présent article.
On notera d'ailleurs en passant, que Volta n'a jamais été décliné en version gaming, puisque l'on passe directement du mathématicien français à l'anglais, en ignorant le physicien italien. Il y a toutefois de nombreuses similitudes entre les 2 dernières architectures, comme nous le verrons au cours de cette page. Turing s'articule une fois encore autour des SM (Streaming Multiprocessor), ces entités polyvalentes réalisant les opérations de calcul et texturing. Ils évoluent toutefois et s'apparentent davantage à ceux utilisés sur les puces GP100 et surtout GV100, avec quelques spécificités.
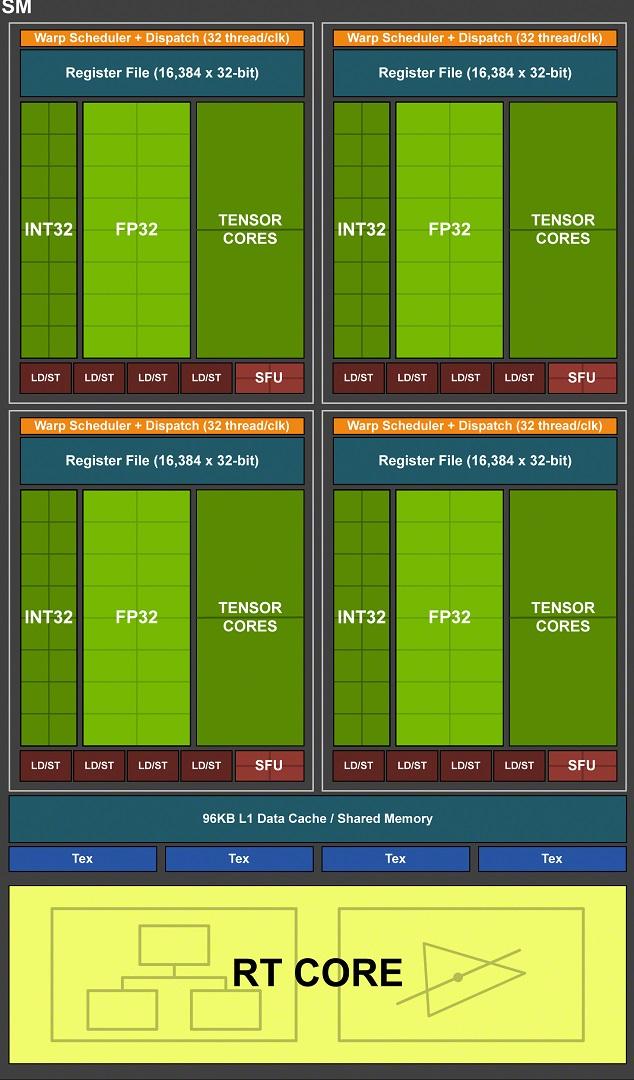
![SM Turing [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/sm_turing_t.jpg "Cliquédélique !")
Un SM Turing
Ainsi, les Tensor Cores (8 par SM) et RT Core (1 / SM) font leur apparition. Si les premiers (des unités vectorielles destinées à accélérer les tâches liées à l'IA) ont déjà été étrennés par Volta (ils évoluent toutefois légèrement), le dernier cité est par contre une nouveauté consécutive à l'adoption sur ces nouveaux GPU, d'un rendu hybride Rastérisation / Lancer de rayons. NVIDIA est plutôt avare en détails sur leur constitution, mais il s'agirait d'unités dédiées à l'accélération de certaines tâches utilisées pour le Ray Tracing. Nous détaillerons ces 2 unités spécifiques page suivante. En attendant, concentrons-nous sur les parties plus "classiques" des Streaming Multiprocessor, puisqu'elles évoluent aussi, du moins par rapport à Pascal, comme nous allons le voir à présent.
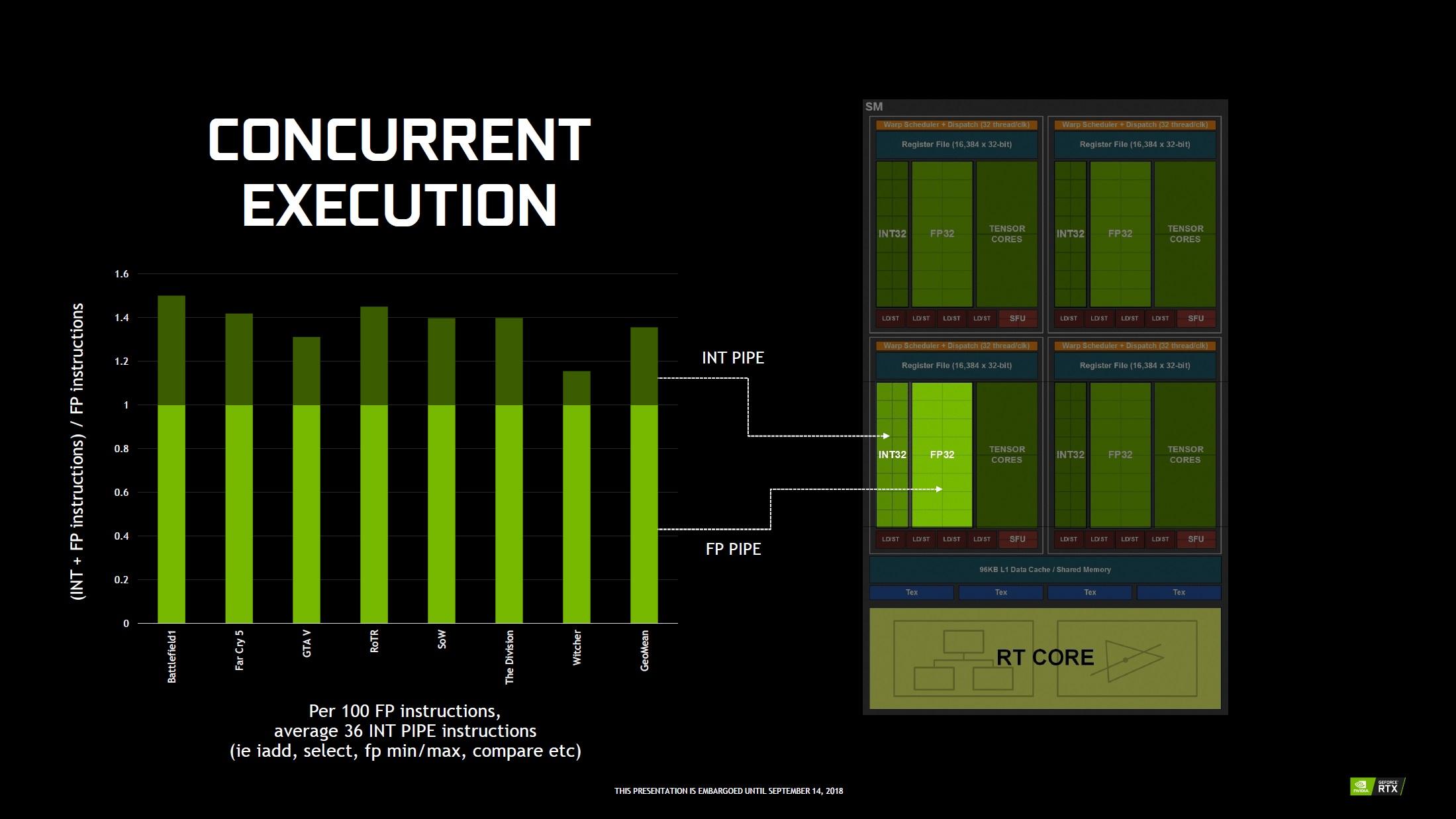
En sus de ces nouveautés, l’œil averti est attiré par la représentation graphique séparée des unités de calcul sur entiers (INT32), de celles dédiées aux opérations en virgule flottante (FP32). Ce duo forme ce que le caméléon nomme depuis des années, les CUDA Cores. Pourquoi diable les dissocier aujourd'hui dans leur représentation ? Jusqu'à présent, il n'était possible de traiter les opérations sur entiers ou réels que de manière séquentielle. Ce n'est plus le cas avec Turing (depuis Volta plus exactement), qui peut donc réaliser ces calculs de manière concomitante. NVIDIA indique qu'en moyenne, pour 100 opérations exécutées sur flottants, 36 opérations sur entier doivent également être traitées. Autrement dit, le traitement concomitant de ces opérations permettrait d’accroître dans un même laps de temps, la performance de calcul moyenne en virgule flottante de 36%.
![Décomposition des instructions moyennes traitées par le SM [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/int32_t.jpg "Enlarge your pe...icture")
Une exécution concomitante des calcul entiers et flottants
Autre point notable, les unités FP32 sont capables, à l'instar de Vega 10 ou des GP100/GV100, de traiter la demi-précision (FP16) à double vitesse. Puisque l'on parle de ces 2 GPU, les SM Turing adoptent une configuration similaire avec "seulement" 64 CUDA Cores. C'est la moitié de ce que l'on trouve sur les précédents GPU Gaming du caméléon. Les unités de calcul sont organisées au sein du SM en 4 partitions ou "blocs de traitement", chacun étant piloté par un couple ordonnanceur / dispatcheur (32 threads/cycle). Ils incluent en sus des 16 INT32/FP32, 4 unités load/store pour les accès mémoire, un cache L0 dédié aux instructions, 64 Ko pour les registres 32-bit, 4 SFU traitant des fonctions complexes (Cos, Sin, etc.) en simple précision et 2 Tensor Cores.
Le ratio entre ces unités n'évolue pas, conduisant là aussi à leur réduction par 2 en comparaison des SM Maxwell ou Pascal (dans sa déclinaison GeForce/TITAN). Chaque bloc de traitement partage également avec les 3 autres, un cache L1 et une mémoire partagée de 96 Ko au total, que nous détaillerons plus bas. Notez pour être exhaustif sur le sujet, que n'apparaissent pas sur le schéma les unités de calcul à double précision (FP64). NVIDIA précise que pour des raisons de compatibilité, 2 unités de ce type sont bien présentes par SM, soit 1/32 de la puissance en SP. 4 TMU (Texture Mapping Unit) complètent le SM, soit le même ratio calcul/texturing adopté depuis Maxwell.
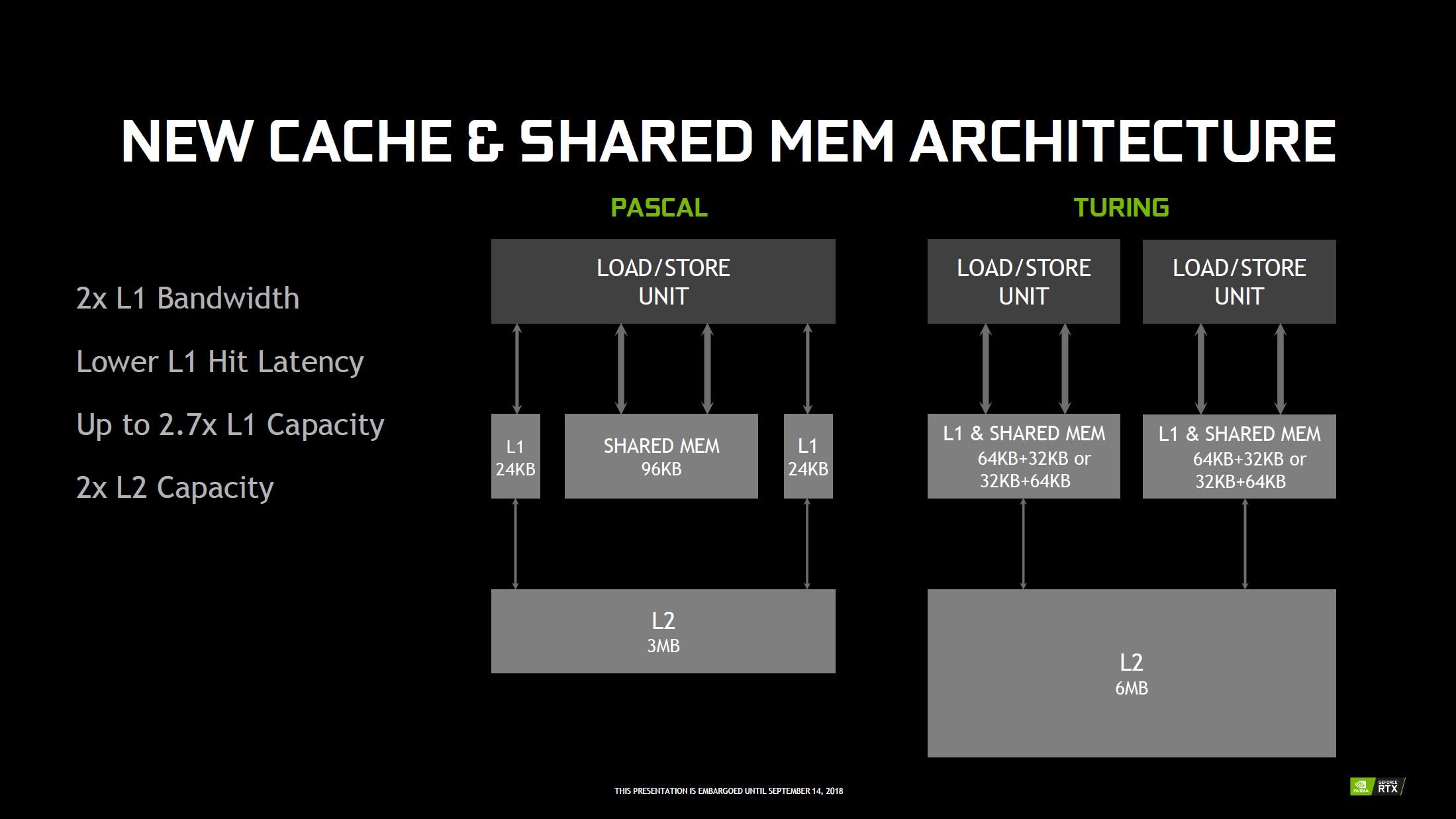
Le caméléon ne s'est toutefois pas arrêté en si bon chemin, puisqu'il a également décidé de s'attaquer aux différents caches, afin d'améliorer encore l'efficacité de son GPU. Pour cela, à l'instar de Volta, la quantité de L2 est doublée par rapport à Pascal. Ce cache généralisé est toujours agencé par "partition", chacune étant associée aux ROP et contrôleurs mémoire (512 Ko par contrôleur 32-bit). La quantité totale de cache L2 disponible, dépendra donc du nombre actif/présent de ces derniers par GPU (6 Mo par exemple pour un TU102 avec son bus 384-bit intégral).
![Les caches L1 et L2 sur Turing [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/caches_t.jpg "Ne pas appuyer ici") Des caches améliorés
Des caches améliorés
Comme nous l'évoquions précédemment, le cache L1 évolue lui aussi, à l'instar de ce qui a été fait sur GV100, puisque NVIDIA a décidé de fusionner ce dernier avec la mémoire partagée, pour un total de 96 Ko. On revient donc au mode de fonctionnement adopté par Kepler (mais avec un texture cache dissocié dans le cas de ce dernier), puis abandonné à partir de Maxwell... Cette approche semble plus efficace dans une optique Compute, notons toutefois que le partage de ces 96 Ko entre L1 & Share MEM est ajustable, puisqu'il est possible de configurer 32 Ko + 64 Ko ou l'inverse si la mémoire partagée réellement utilisée ne dépasse pas la première valeur.
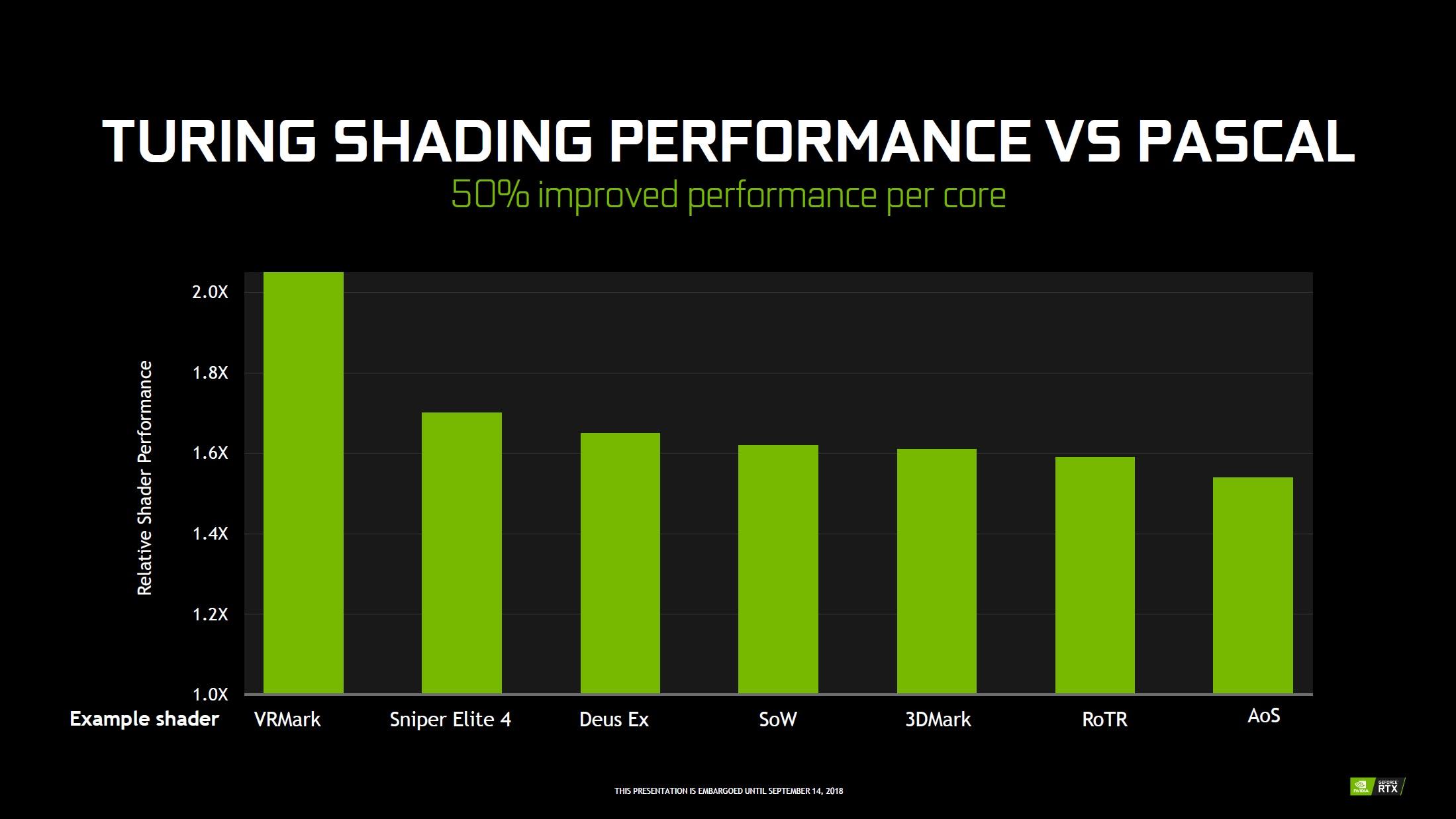
Les SM comprenant 2 fois moins d'unités que celles des précédents GPU Gaming, la quantité de L1 disponible pour ces dernières progresse jusqu'à 2,7 fois plus (si 64 Ko affectés au cache de premier niveau). Cette unification permet également de doubler le débit et réduire notablement la latence (82 cycles pour Pascal contre 32 sur Turing par exemple, un score proche de Volta (28), vu la similitude des 2 architectures). Toutes ces modifications ont un impact positif sur les performances intrinsèques de Turing, d'après le caméléon. Ainsi, les gains moyens en exécution de shaders, seraient de l'ordre de 50% pour ces nouveaux CUDA Cores, face à ceux de Pascal.
![Gains liés aux évolutions de l'architecture [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/gain_archi_t.jpg "Si vous cliquez, vous cliquez.") Gains liés aux évolutions architecturales selon NVIDIA
Gains liés aux évolutions architecturales selon NVIDIA
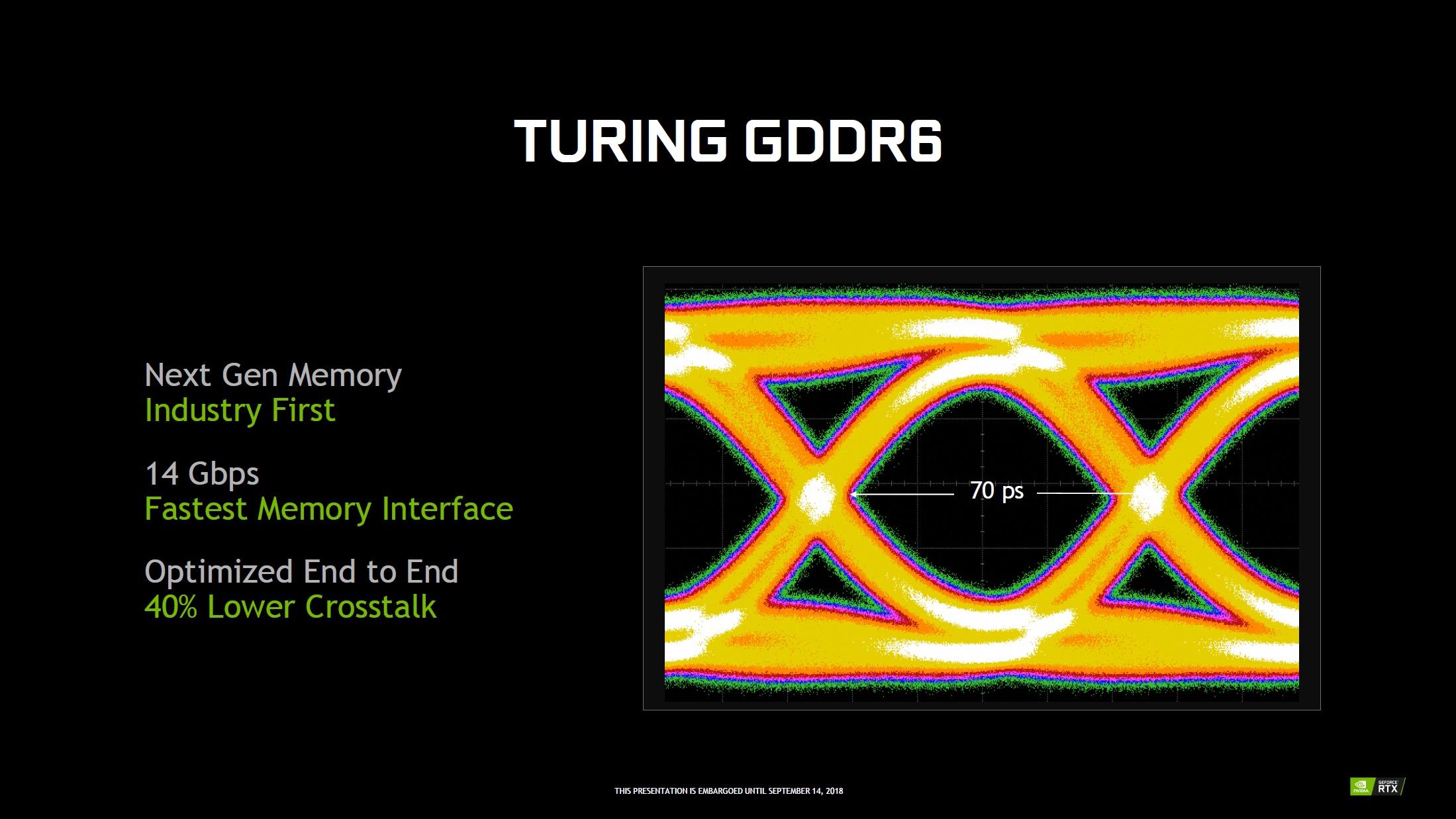
La gestion mémoire évolue elle aussi : si le caméléon conserve des contrôleurs 32-bit, chacun étant associé à une partition de 8 ROP (Render OutPut unit) chargés d'écrire en mémoire, ceux-ci (les contrôleurs) ont tout de même été retravaillés pour réduire le bruit au niveau du signal, et supporter des fréquences plus élevées, tout en limitant la consommation. À ce sujet, les périodes de moindre activité, profitent à présent d'une plage de fréquences étendue, permettant de réduire encore davantage la consommation dans ces conditions. Pour ses nouvelles cartes graphiques, NVIDIA a jeté son dévolu sur un nouveau type de mémoire, la GDDR6.
Exit donc la GDDR5X des Pascal haut de gamme, qui utilisait pour rappel un mode de fonctionnement QDR (Quad Data rate), afin d’atteindre au mieux 12 Gbps (commercialement), au prix d'un prefetch doublé (16n) en comparaison de la GDDR5. La nouvelle venue utilise de son côté 2 canaux en parallèle, pour atteindre jusqu'à 18 Gbps pour le moment. NVIDIA utilise des puces plus conservatrices à 14 Gbps, ces dernières nécessitant une tension de 1,35 V, soit la même que celle utilisée par la GDDR5X. Les différentes optimisations et la bande passante plus élevée, conduirait à une efficacité énergétique en hausse de 20%, par rapport à celle-ci.
![Le signal de la GDDR6 [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/gddr6_t.jpg "Ultra bouzotron HD max def")
L’œil bien propre de Sauron du signal de la GDDR6
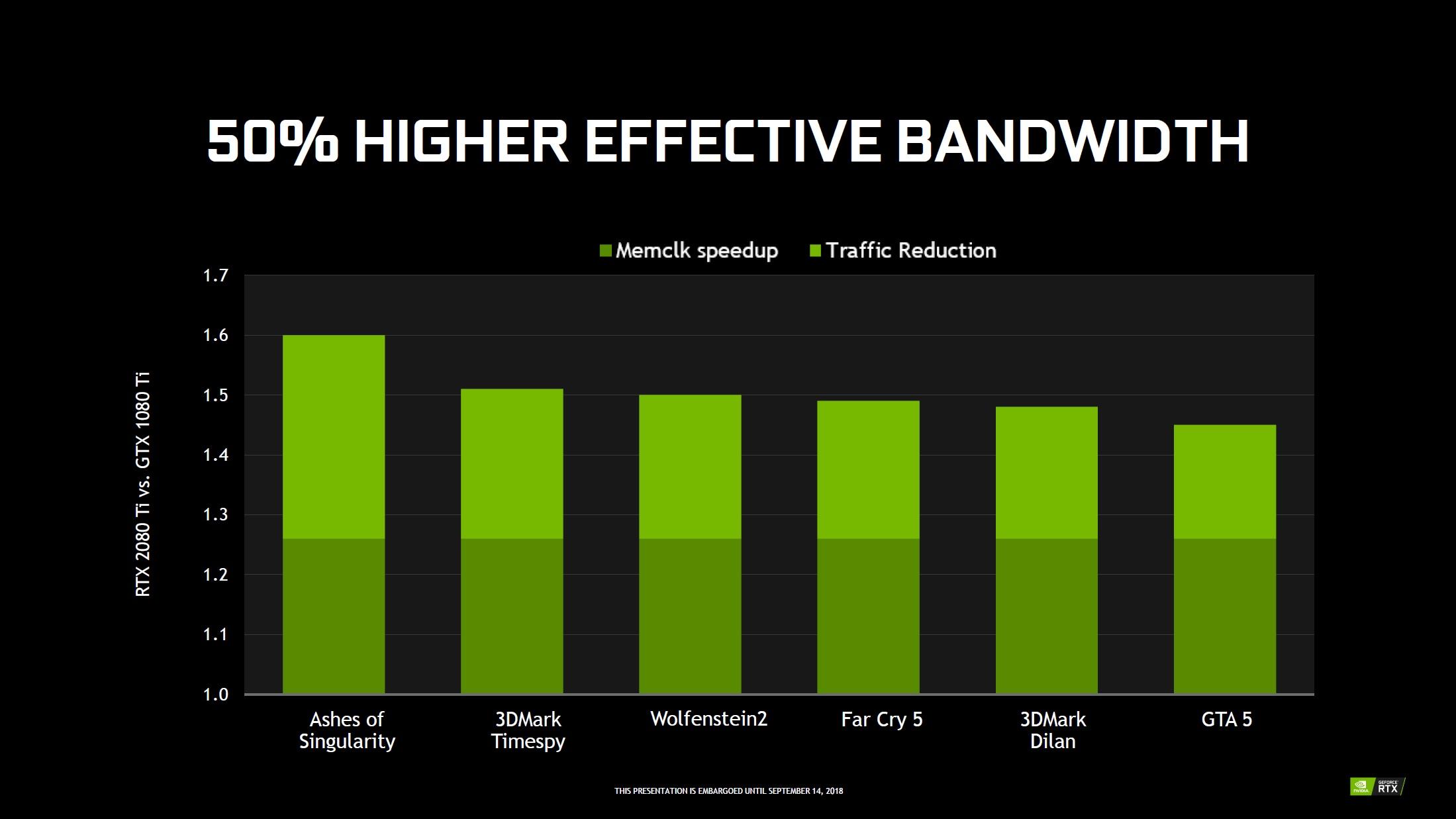
Nous venons de le voir, la progression en terme de bande passante mémoire est notable, mais pas exceptionnelle pour autant, puisque l'on passe par exemple de 11 Gbps sur la 1080 Ti, à 14 Gbps sur la 2080 Ti pour un bus identique. Un rapide calcul indique un gain brut de 27%, toutefois, le caméléon précise que la réduction du trafic permettrait d'amplifier l'avantage de la nouvelle venue à ce niveau. C'est là qu'interviennent différents algorithmes de compression de données (dont le delta color), déjà présents sur les précédents GPU du caméléon et qui réduisent la taille des données à transférer. Ils progressent avec Turing par rapport à Pascal, conduisant à une bande passante effective, qui serait en hausse de 50%.
![Gain de bande passante avec Turing [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/bande_passante_t.jpg "3N C11QU4N7 C357 P1U5 6r4ND")
Les gains en termes de bande passante effective
Remontons à présent à une vue plus macro du GPU (pour notre exemple TU102) : la représentation visuelle de son organisation est plutôt familière, même si là aussi elle ressemble davantage à celles des GP100/GV100 que GP102. Ainsi, les SM sont toujours inclus au sein des structures nommées TPC (Texture Processor Cluster), support du Polymorph Engine, c'est-à-dire les unités dédiées à la géométrie (vertice, tesselation). Par contre, on trouve cette fois 2 SM par TPC et non plus un seul, ce qui conduit au même nombre d'unités de calcul et texturing sur Turing que Pascal (Gaming) au sein d'un TPC, mais via une organisation différente (en tout cas telle que représentée schématiquement par NVIDIA).
![Diagramme TU102 [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/diagram_tu102_t.jpg "Cliquédélique !")
Le diagramme fonctionnel de Turing dans sa déclinaison TU102
Les TPC prennent de leur côté place par groupe de six (5 sur Pascal, 4 pour Maxwell) au sein des GPC (Graphics Processing Cluster), disposant d'une unité de rastérisation capable d'afficher un triangle par cycle. Au total, TU102 comprend 6 GPC, soit une valeur inchangée par rapport aux GM200 et GP102. À cela s'ajoute bien sûr le cache généralisé L2 à 6 Mo et les ROP associés par partition de 8, à chacun des 12 contrôleurs mémoire 32-bit. Apparaissent également 2 liens NVLink 8x (l'interface haute vitesse développée par le caméléon pour le domaine HPC) de seconde génération (introduite sur Volta).
En faisant les comptes, on obtient un TU102 (complet) comprenant 4608 CUDA Cores, au sein de 72 SM et 36 TPC. En découle donc 288 TMU, 72 RT Cores et 576 Tensors Cores. Enfin, 96 ROP et le bus mémoire 384-bit complètent le tout pour une puce intégrale. D'un point de vue calculs (flottants) en simple précision (FP32), un TU102 complet, tel qu'intégré sur les Quadro RTX 6000/8000, permet d'atteindre un peu plus de 16 TFlops contre un peu plus de 12 pour le GP102 (complet lui-aussi) de la Titan Xp.
Ce gain brut de 33% n'a rien de bien impressionnant non plus au premier abord pour une nouvelle génération, mais l'efficacité en hausse du fait de l'évolution de l'architecture, permet d'espérer des écarts plus importants en pratique, puisque par exemple, l'exécution concomitante des opérations sur entiers et flottants, ne se retrouve pas dans les chiffres bruts de ces derniers. Côté demi-précision (FP16), les valeurs s'envolent du fait de la présence des Tensors Core (le débit est nettement moindre, mais reste conséquent (32 TFlops sur RTX 6000) en usage plus classique via les CUDA Cores). C'est également le cas des précisions encore plus réduites, ces dernières pouvant trouver une utilité en inférence (mise en œuvre d'un modèle issu du Deep Learning).
![Turing en chiffres [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/turing_t.jpg "Même pas cap' de cliquer")
Turing en chiffres dans la déclinaison dédiée à la RTX 2080 Ti
Mais toutes ces évolutions ont un coût qui est loin d'être négligeable, à savoir une inflation considérable du nombre de transistors nécessaires. GP102 en intègre près de 12 Milliards, cette valeur passe à pas moins de 18,6 Milliards pour TU102, soit une augmentation de 55%. Dans le même temps, le procédé de fabrication n'évolue pas dans les mêmes proportions, puisque au lieu du 16 nm FinFET, les nouvelles puces font appel au 12 nm FFN (toujours chez TSMC). Derrière ces appellations commerciales, il ne s'agit pas réellement d'un nouveau Node, mais plutôt d'une optimisation du premier cité. Qui plus est, nous avons affaire ici à une version personnalisée pour NVIDIA (à l'occasion du lancement de GV100), qui privilégie la performance des transistors aux gains de densité. Cela permet de contrôler la consommation, malgré l'explosion du nombre de transistors.

En conséquence, la taille de ce nouveau GPU (TU102) est tout simplement énorme, à 754 mm². Seul GV100 et ses 824 mm² pour 21,1 Milliards de transistors, le dépasse à ce niveau. La densité est légèrement moindre sur TU102 que GP102, mais compte-tenu de la différence constitutive marquée (Tensor Cores, RT Cores, NVLink) entre ces 2 GPU (les interfaces sont généralement moins denses en transistors), il est difficile d'estimer les éventuelles évolutions à ce niveau du "nouveau" procédé de gravure. Toujours est-il qu'avec une telle taille de die, le nombre produit par Wafer (disque de silicium sur lequel sont gravés les puces) chute considérablement et conduit inéluctablement à un coût de production en forte hausse. En effet, le fondeur vend les Wafers gravés à ses clients, peut importe le nombre de puces présentes sur ces derniers. C'est également sans compter le taux de puces fonctionnelles (Yield), qui peut encore dégrader le coût de production, surtout dans le cas de GPU très complexes, multipliant d'autant les risques d'anomalie. Afin de compenser ce point, il est toutefois possible de recycler les puces partiellement défectueuses, et créer ainsi un effet de gamme, selon les unités réellement activées.
Voilà pour la partie "classique" de Turing, nous vous proposons page suivante, une plongée plus profonde au sein des "grosses" nouveautés de ce dernier, à savoir les RT et Tensor Cores, dédiés au Ray Tracing et intelligence artificielle.
|
|
| Un poil avant ?Live Twitch • Démo de Forza Horizon 4 sur PC | Un peu plus tard ...Lara benchée par tous les... GPU bien sûr ! | |
| 1 • Préambule |
| 2 • |
| 3 • RT Cores / Tensor Cores / Rendu hybride |
| 4 • 3 cartes = 3 GPU |
| 5 • Les nouvelles fonctionnalités |
| 6 • VR, Vidéo & Encodage / NV Scanner / SLi |
| 7 • Conclusion |