Test • NVIDIA GeFORCE RTX 3080 |
————— 16 Septembre 2020



Test • NVIDIA GeFORCE RTX 3080 |
————— 16 Septembre 2020
Comme nous l'indiquions en page précédente, NVIDIA a conçu à partir de son architecture Ampere (dans sa déclinaison gaming), un premier GPU portant la dénomination GA102. Dans la nomenclature verte, 102 désigne la puce la plus haut de gamme destinée au grand public. Alors que le GA100 est gravé en 7 nm par TSMC, le caméléon a décidé d'accorder sa confiance à Samsung pour GA102. Le procédé est décrit comme un 8 nm personnalisé pour Nvidia. À quoi avons-nous affaire ici ? Ce node 8 nm Samsung est une optimisation du procédé de gravure 10 nm du fondeur, un nœud intermédiaire entre les 14 nm et 7 nm. Il est donc d'une "génération technologique" antérieure au 7 nm qu'utilise déjà AMD pour ses puces Navi 1x. Ce palier intermédiaire n'avait pas été utilisé précédemment par les concepteurs de GPU (évolution directe du 28 nm au 14/16 nm sans passer par la case 20 nm), mais exclusivement par les concepteurs de puces à destination de la mobilité.

Pourquoi diable Nvidia le fait-il cette fois, alors que son concurrent profite déjà depuis une bonne année, d'un procédé plus avancé ? Une histoire de coût et de rendements se cache probablement derrière tout cela. Toujours est-il que ces informations étant savamment gardées, toute analyse plus poussée ne serait que pure conjecture de notre part. Mais à quel point le 7 nm de TSMC est-il meilleur que le 8 nm de Samsung ? Là-aussi, difficile d'émettre le moindre avis sans base de comparaison. Il est toutefois utile et important de préciser qu'il n'y a pas un, mais des 7 nm disponibles chez TSMC. Après l'introduction initiale de ce nœud de gravure, une version Performance est apparue (augmentant densité et efficacité énergétique), puis une version + a été lancée utilisant l'EUV, pour là-aussi améliorer ces deux points, ainsi que le rendement de production. Si concernant l'efficacité énergétique, on ne peut que se baser sur les dires du fondeur, pour la densité, les informations d'AMD et Nvidia permettent de réaliser des ratios entre GPU.
| Gravure | GPU | Nombre de transistors | Superficie Die |
Densité (Millions de transistors / mm²) |
|---|---|---|---|---|
| 7 nm TSMC | GA100 | 54.2 Milliards | 826 mm² | 65,6 |
| 8 nm Samsung | GA102 | 28,3 | 628 mm² | 45 |
| 8 nm Samsung | GA104 | 17,4 | 392 mm² | 44,3 |
| 7 nm TSMC | Navi 10 | 10,3 Milliards | 251 mm² | 41 |
| 7 nm TSMC | Vega 20 | 13.2 Milliards | 331 mm² | 39.9 |
| 16 nm TSMC | GP102 | 12 Milliards | 471 mm² | 25,5 |
| 14 nm GF | Vega 10 | 12.5 Milliards | 495 mm² | 25,3 |
| 16 nm TSMC | GP100 | 15,3 Milliards | 610 mm² | 25.1 |
| 12 nm TSMC | TU102 | 18,6 Milliards | 754 mm² | 24,7 |
| 12 nm TSMC | TU100 | 21,1 Milliards | 815 mm² | 24,3 |
D'après les chiffres fournis par Nvidia, GA100 disposerait d'un avantage de 46% pour la densité par rapport à GA102. Attention toutefois, ces GPU ne visant pas du tout les mêmes usages, cela a pour conséquence des designs bien différents (cache L2 bien plus important sur GA100, probablement pas de moteur d'affichage intégré, etc.) qui peuvent impacter significativement la densité. Toutefois, vu l'ampleur de l'écart, il ne fait pas de doute que le procédé de TSMC est bien plus dense, reste à savoir duquel il s'agit... La comparaison avec les 2 puces d'AMD utilisant elles aussi un 7 nm de TSMC, est édifiante à ce sujet. Toujours est-il que 628,4 mm², est une taille conséquente pour un GPU, même si moindre que les 754 mm² de son prédécesseur. La densité progressant de 82% entre les 2 puces, cela a permis d'intégrer plus de 28 milliards de transistors au sein du nouveau venu. Deux cartes graphiques seront déclinées depuis ce GPU, selon le niveau d'activation des unités.
| GA102 | RTX 3080 | RTX 3090 | Complet |
|---|---|---|---|
| GPC | 6 | 7 | 7 |
| TPC / SM | 34 / 68 | 41 / 82 | 42 / 84 |
| FP32 | 8704 | 10496 | 10752 |
| TMU | 272 | 328 | 336 |
| Tensor Cores | 272 | 328 | 336 |
| RT Cores | 68 | 82 | 84 |
| ROP | 96 | 112 | 112 |
| L2 (Mo) | 5 | 6 | 6 |
| Bus mémoire (bits) | 320 | 384 | 384 |
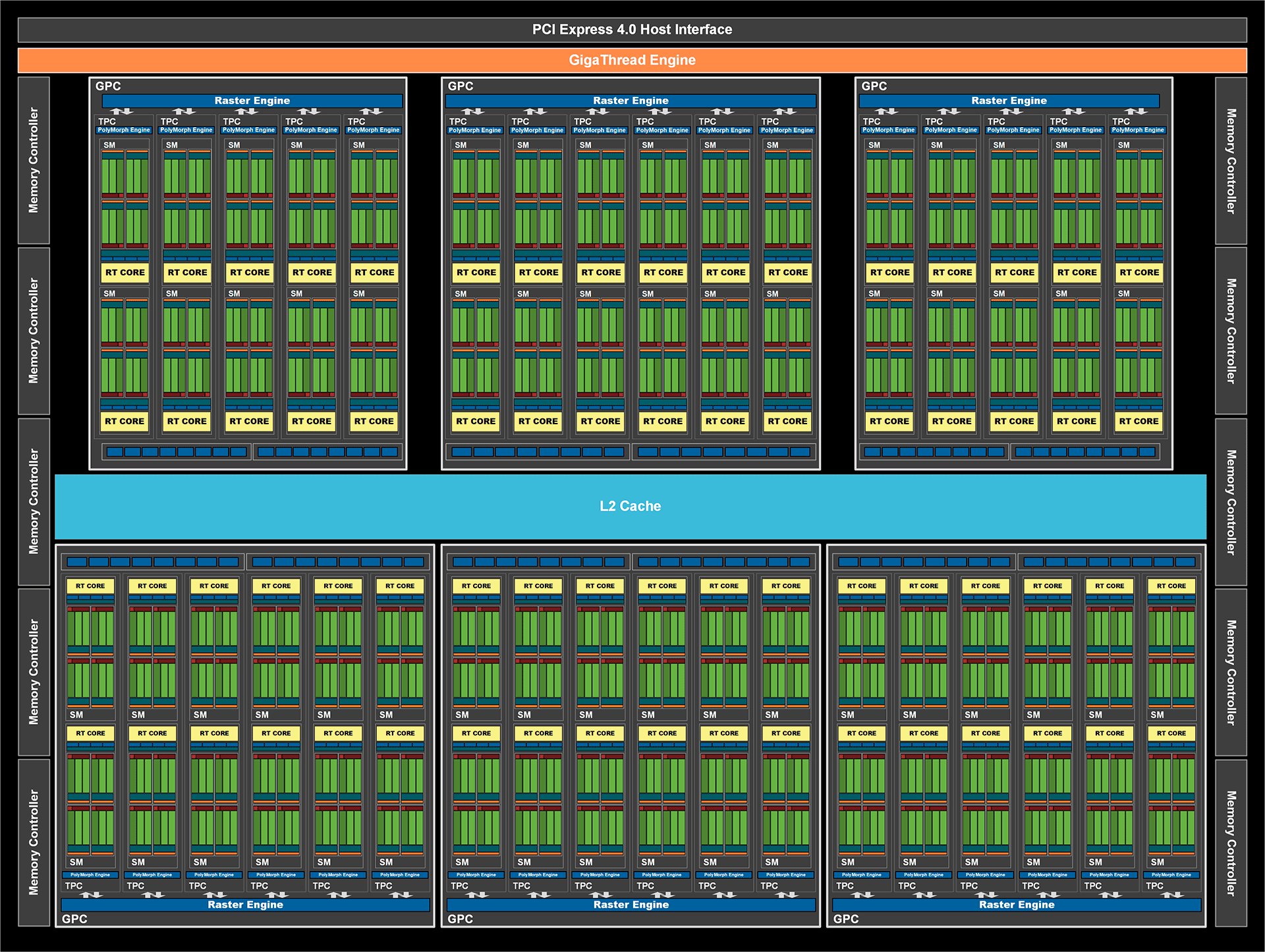
Comme on pouvait s'en douter, la "castration" est beaucoup plus violente pour la RTX 3080, qui se retrouve au final avec un peu moins de 81% des unités actives. Côté mémoire, c'est du même ordre avec 83% du bus total conservés. A contrario, la RTX 3090 dispose de son côté de pratiquement 98% des unités présentes dans le die, activées, et d'un bus mémoire 100% opérationnel, couplé à des puces légèrement plus rapides. Nous détaillerons la RTX 3090 lorsque nous serons en possession de ladite carte, en attendant, voici ci-dessous le diagramme logique du GA102, dans sa version RTX 3080.
![Diagramme GA102 version RTX 3080 [cliquer pour agrandir]](/images/stories/articles/gpu/ampere/architecture/ga102_3080_diagram_t.png "Cliquédélique !") GA102 tel que configuré pour la RTX 3080
GA102 tel que configuré pour la RTX 3080
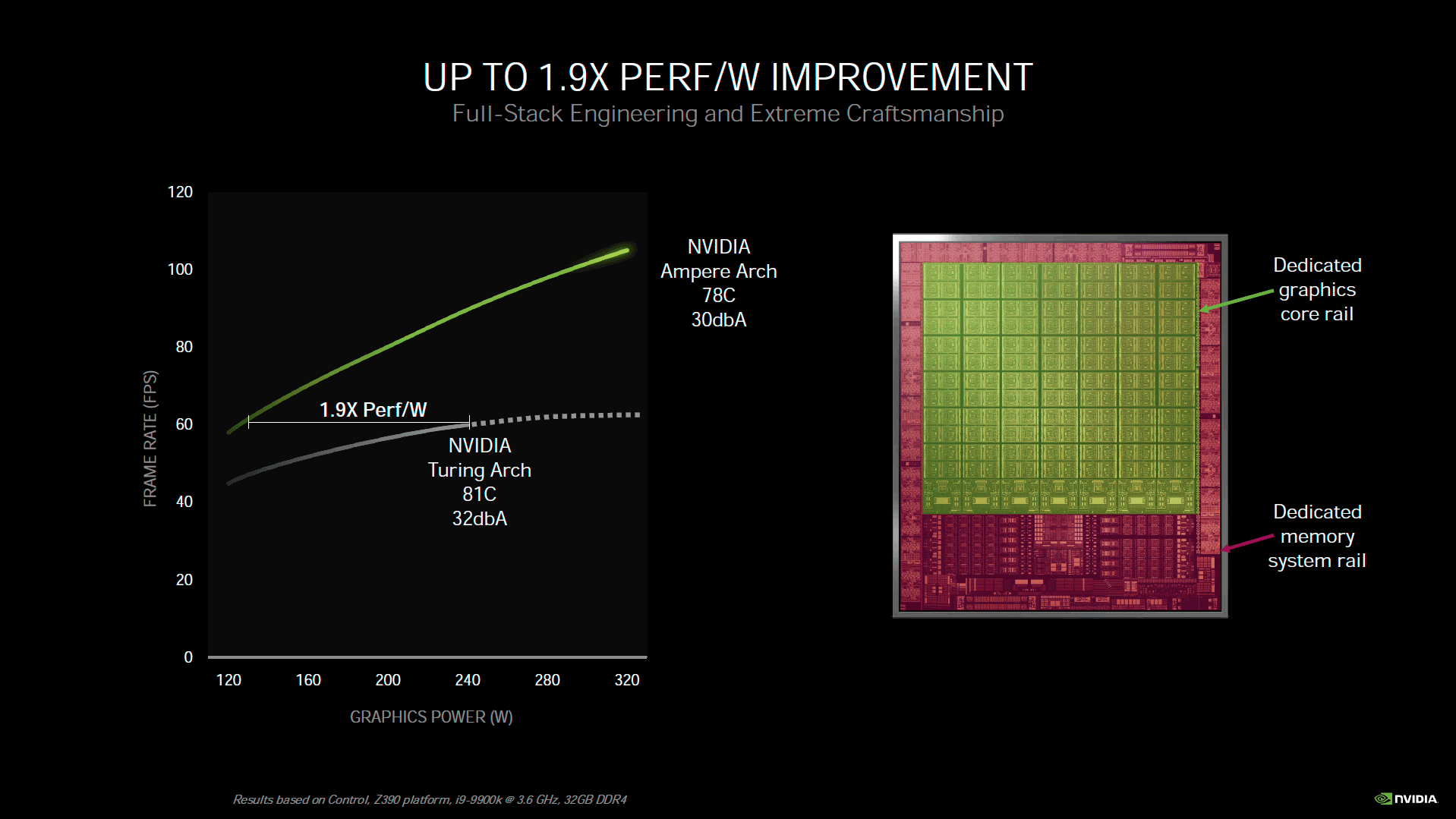
Nvidia précise que cette carte graphique dispose d'un TGP de 320 W, du jamais vu à ce niveau. Si ce n'est pas sans poser de soucis d'ordre environnemental, on peut toutefois accepter une telle consommation, si tant est que les nuisances sonores et températures de fonctionnement soient sous contrôle (ce que nous vérifierons bien entendu au niveau des pages dédiées), et surtout que les performances suivent. En effet, le rapport performance/watts a toute son importance pour jauger de l'efficacité d'un GPU. Les verts nous présentent d'ailleurs un magnifique ratio performances par watt pour la RTX 3080, à 1,9x celui de la RTX 2080. Toutefois, pour obtenir ce résultat, les performances sont bloquées à 60 i/s pour les 2 cartes. Cette méthode de mesure est exagérément favorable à la plus performante des deux, puisqu'une partie de son GPU va pouvoir se tourner les pouces pour atteindre ce niveau, ce qui ne sera pas le cas de la moins rapide. Alors ce n'est pas un mensonge pour autant, nous arrivons bien grosso modo à ce résultat dans ces conditions, mais sont-elles réellement celles qui seront appliquées ?
![Ratio performances par watt [cliquer pour agrandir]](/images/stories/articles/gpu/ampere/architecture/ratio_perf_w_t.png "Si vous cliquez, vous cliquez.")
Le ratio performances par watt de la RTX 3080 à iso performance
En effet, certains joueurs pourront opter par exemple pour une synchronisation verticale activée sur un écran à 60 Hz et se retrouver exactement dans les mêmes conditions, ou opter pour un bridage volontaire dans le but de limiter la consommation, soit. Mais en pratique, l'acquéreur de RTX 3080 est à la recherche de performances, il va donc plus probablement lâcher la bride de sa carte pour qu'elle donne son maximum. Parce que si on va dans cette direction, pourquoi diable proposer une enveloppe de puissance allant jusqu'à 320 W, si ce n'est pour l'utiliser ? On ne peut pas d'un côté afficher des graphiques de performances carte débridée et de l'autre représenter l'efficacité énergétique en les bridant.
Soyons clairs, nous ne reprochons pas à Nvidia d'être allé chercher plus de performance avec plus de consommation. Compte tenu du procédé de fabrication retenu pour une maîtrise des prix, c'était probablement la moins mauvaise option. C'est donc un choix tout à fait respectable et qui conviendra à beaucoup, mais il faut l'assumer. Nous ne sommes pas dans le monde des Bisounours, il est donc nécessaire de prendre du recul vis-à-vis de certains arguments marketing. Bref, vous l'aurez compris, nous ne partageons pas cette façon de mesurer l'efficacité énergétique, et vous retrouverez dans la page dédiée nos propres résultats, forcément beaucoup moins clinquants. Pour finir sur ce sujet, Nvidia précise que l'alimentation du GPU est à présent assurée par 2 rails distincts, alimentant respectivement la partie mémoire et la partie calcul. Cela évite des intensités par trop importantes, si usage d'un seul et unique rail.
Turing était une architecture très polyvalente, capable de réaliser de nombreuses tâches de front. Toutefois, Ampere serait encore plus efficace à ce niveau d'après son concepteur. Une des limitations de Turing était l’impossibilité de réaliser simultanément des tâches utilisant RT Cores et Tensor Core. Cette limitation est à présent levée, ce qui ouvre la porte à de nouveaux gains potentiels. Afin de mettre ces derniers en évidence, Nvidia présente l'exemple d'un rendu en Ray Tracing et ce avec ses trois dernières architectures.
![Async Compute [cliquer pour agrandir]](/images/stories/articles/gpu/ampere/architecture/async_t.gif "Si vous cliquez, vous cliquez.")
Une image de Youngblood en Ray Tracing rendu par les 3 dernières générations vertes
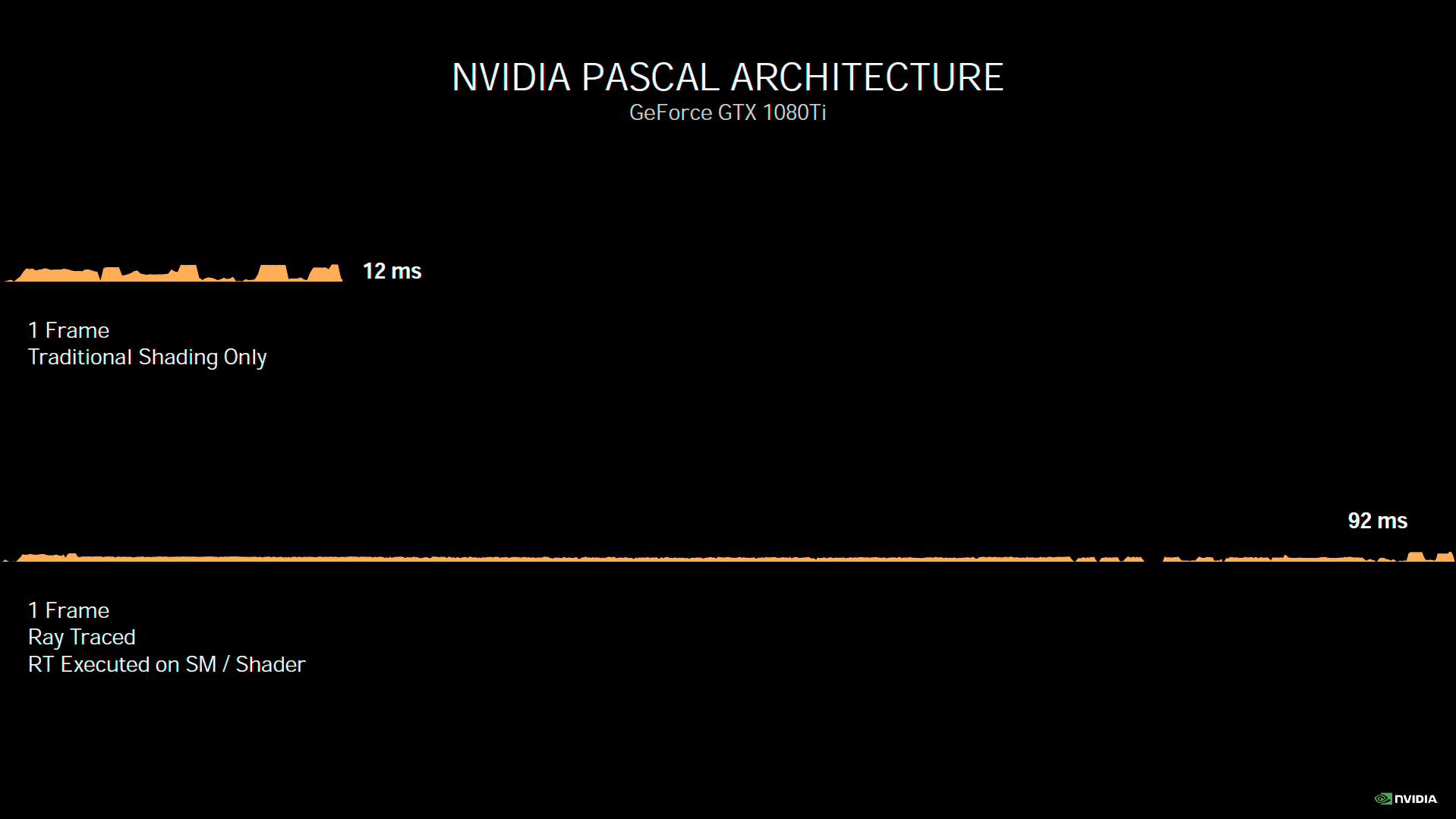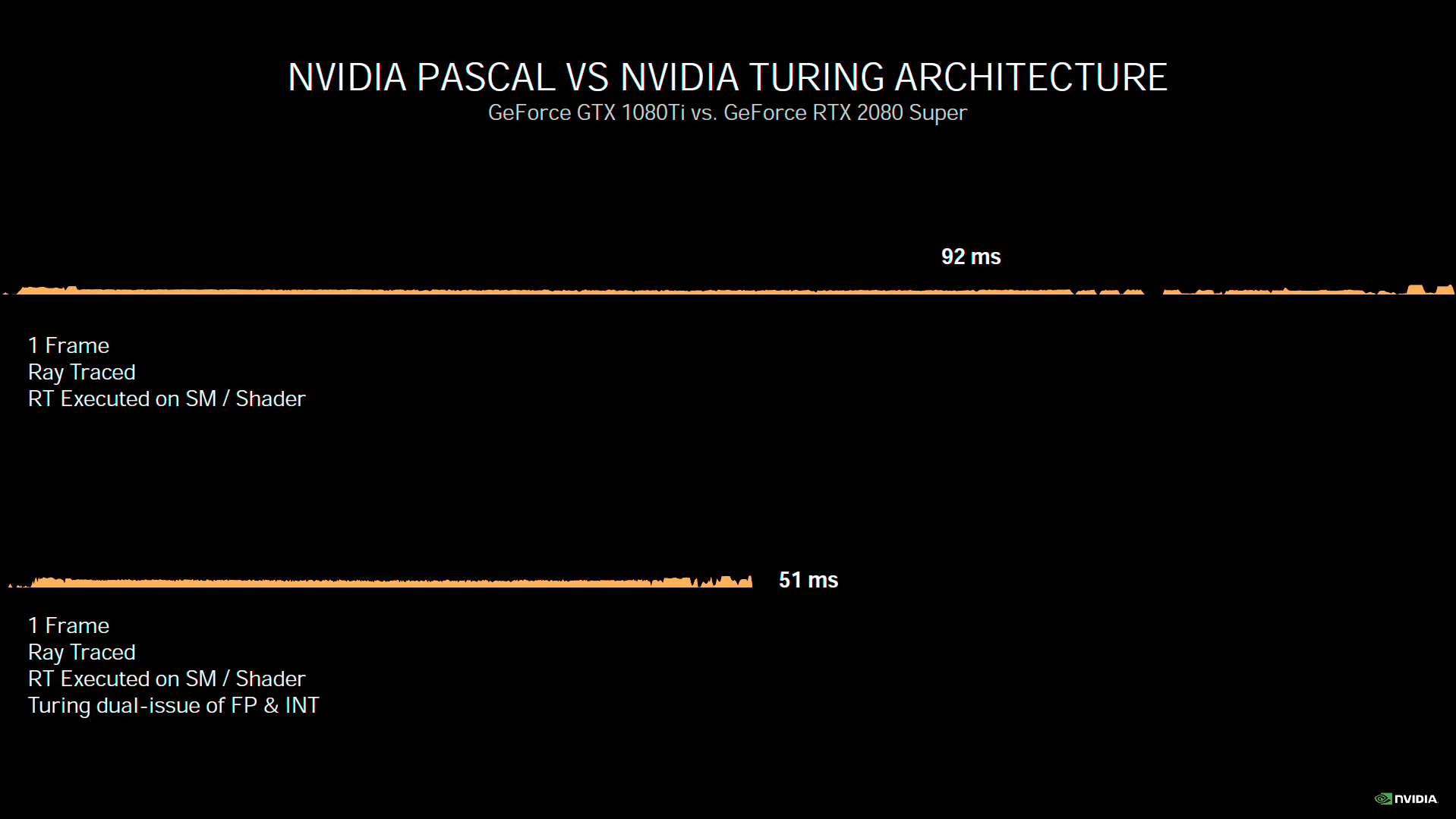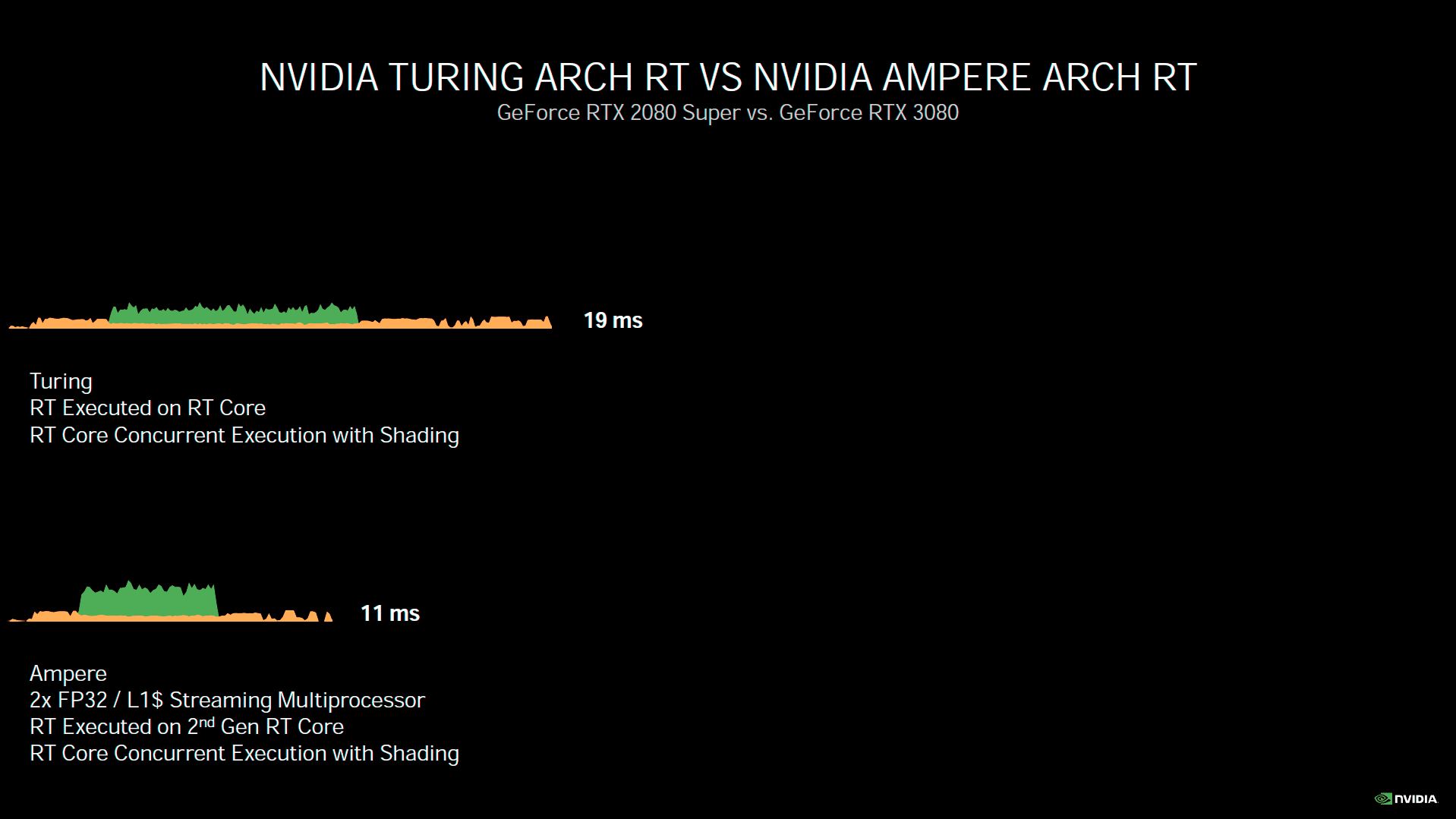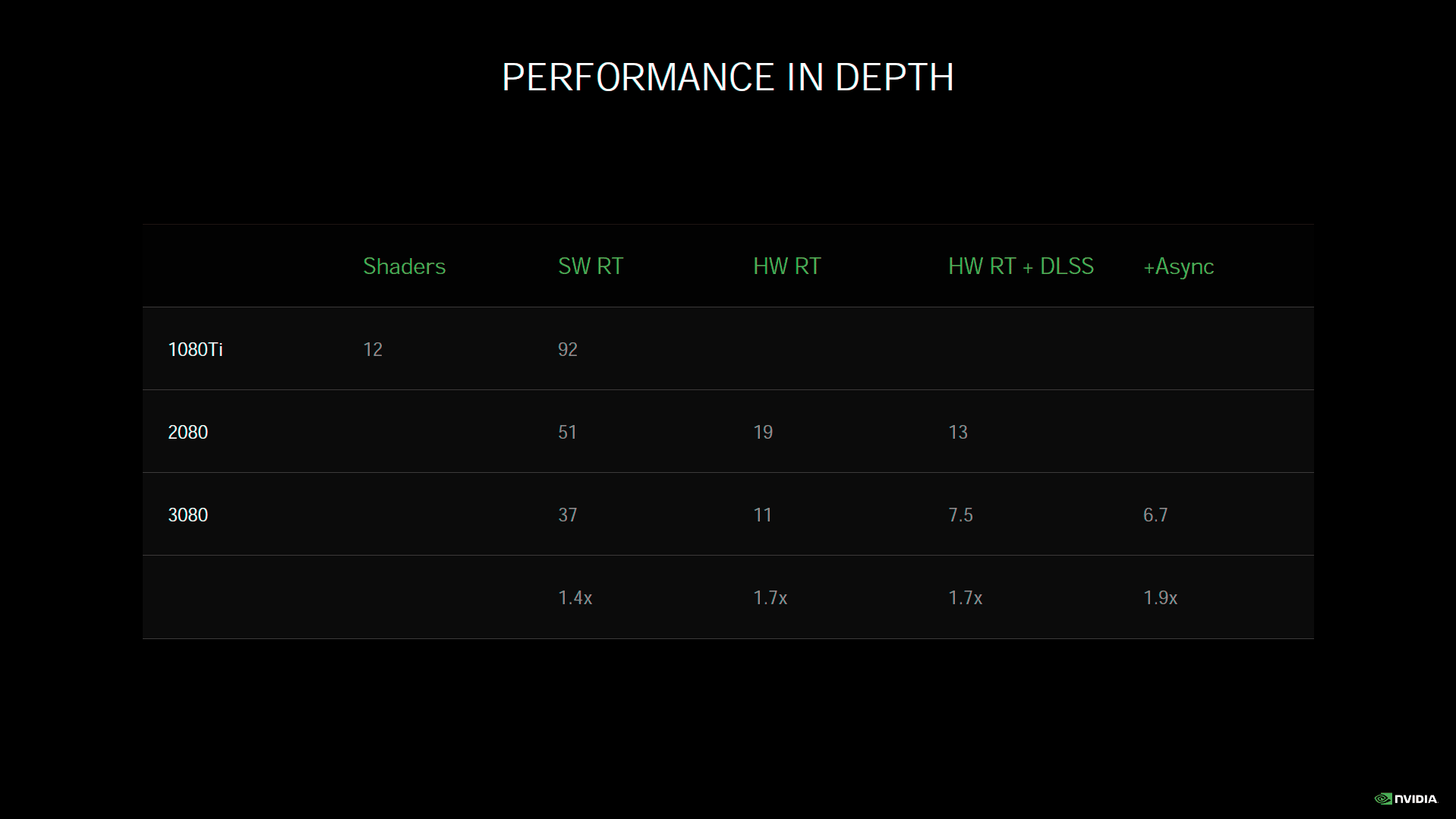
Pascal n'étant pas doté de RT Core, le rendu doit être réalisé intégralement via des Shader, ce qui prend 51 ms à la GTX 1080 Ti (~20 i/s). Turing permet de raccourcir très nettement ce temps de rendu, via ses RT Cores. Il est même possible de réduire notablement cette valeur, en utilisant le DLSS, afin de calculer l'image dans une définition moindre puis en inférant celle souhaitée via les Tensor Core, une fois la partie RT terminée. Ampere est capable de réaliser la même opération, mais bien plus vite du fait de ses progrès architecturaux. Cerise sur le gâteau, il peut aussi solliciter ses Tensor Cores, sans avoir à attendre la fin de l’utilisation des RT Cores, pour inférer la définition d'affichage, maximisant ainsi les gains. Il faut toutefois que les développeurs tirent parti de cette possibilité, nul doute que les équipes du caméléon en support des développeurs, seront attentives à ce sujet. Nous avons eu l'opportunité de tester la version bêta de Wolfenstein Youngblood, intégrant ce traitement concomitant des 3 composantes de son rendu. Vous retrouverez les résultats obtenus en page 17.
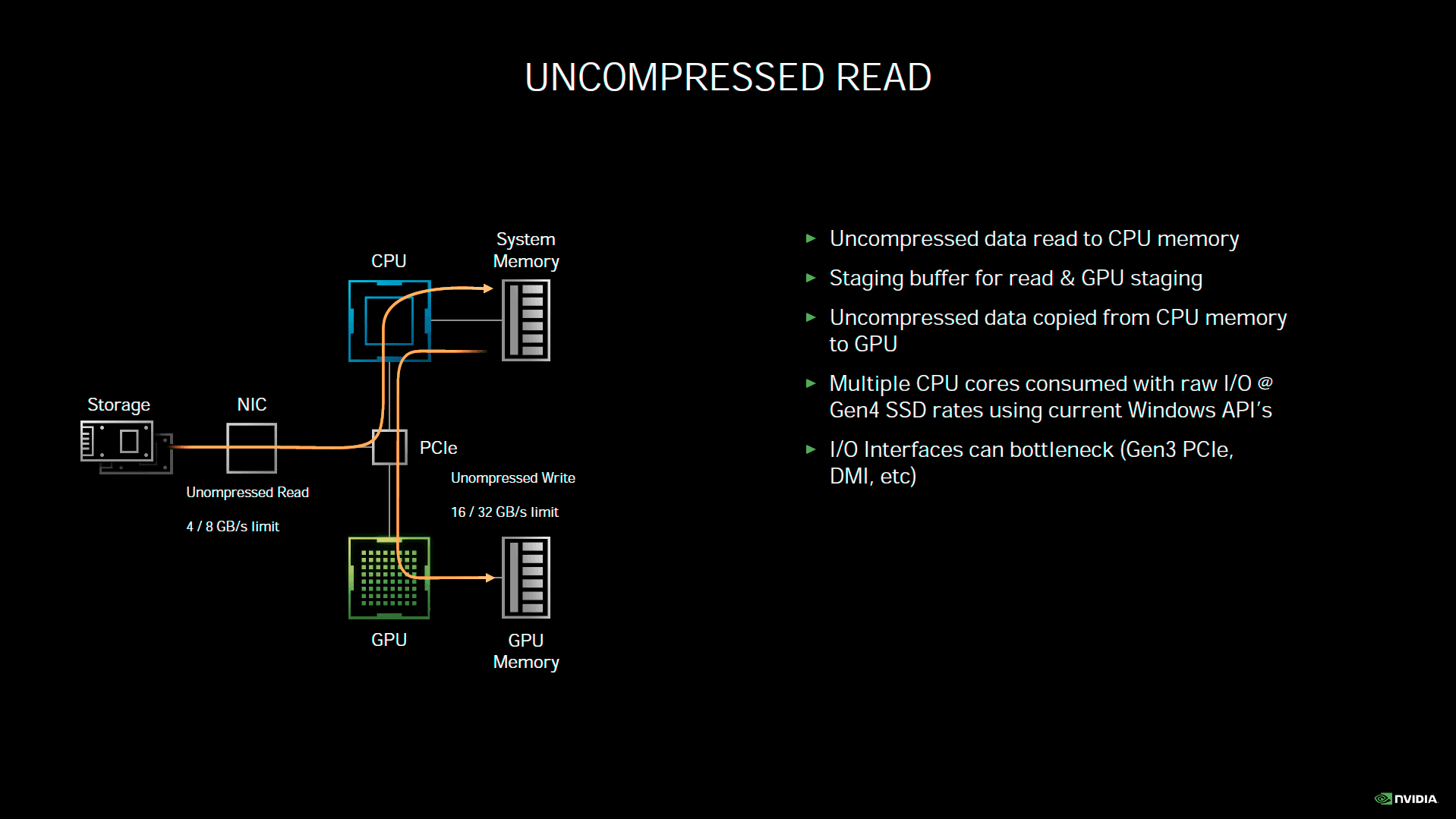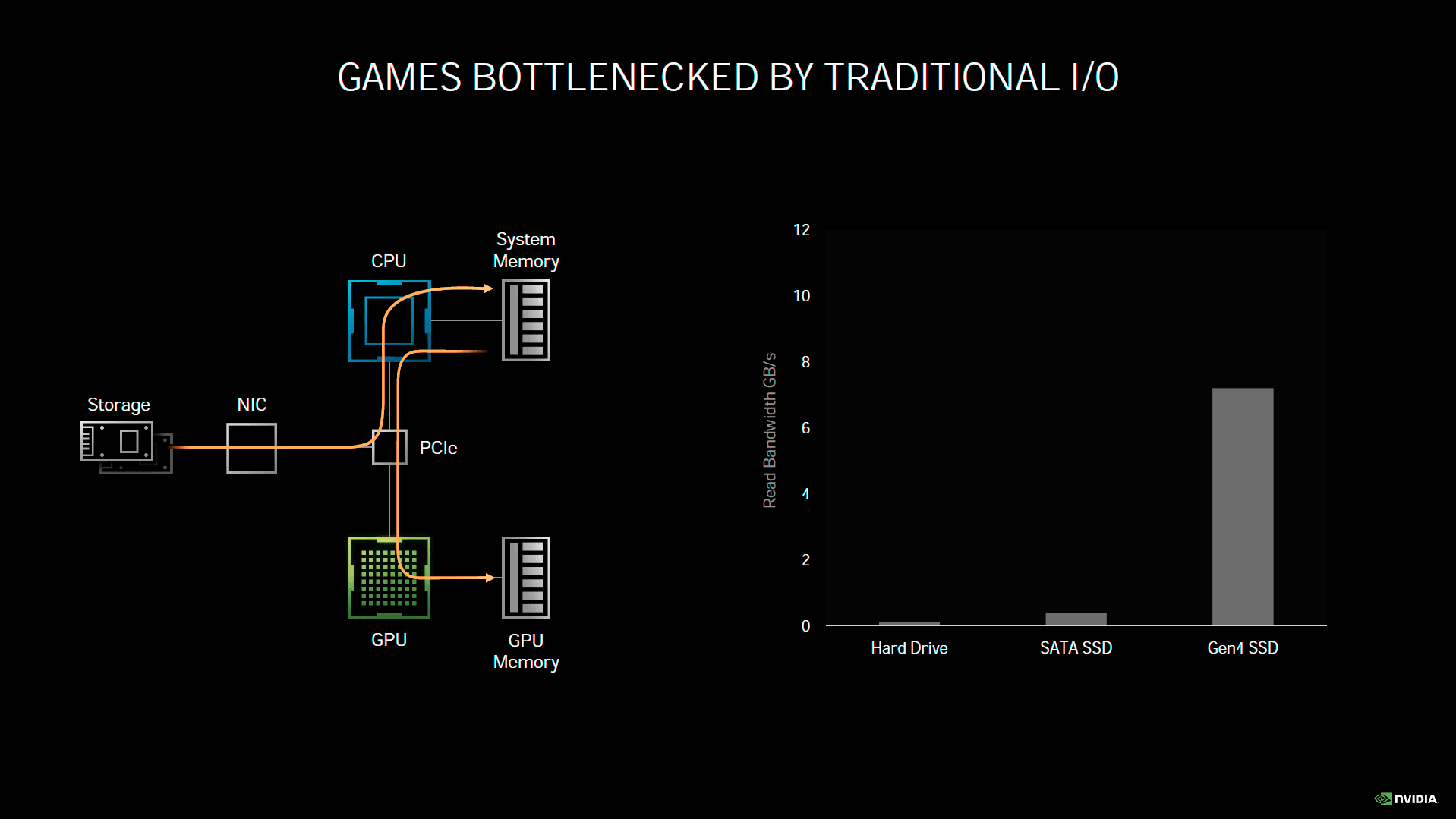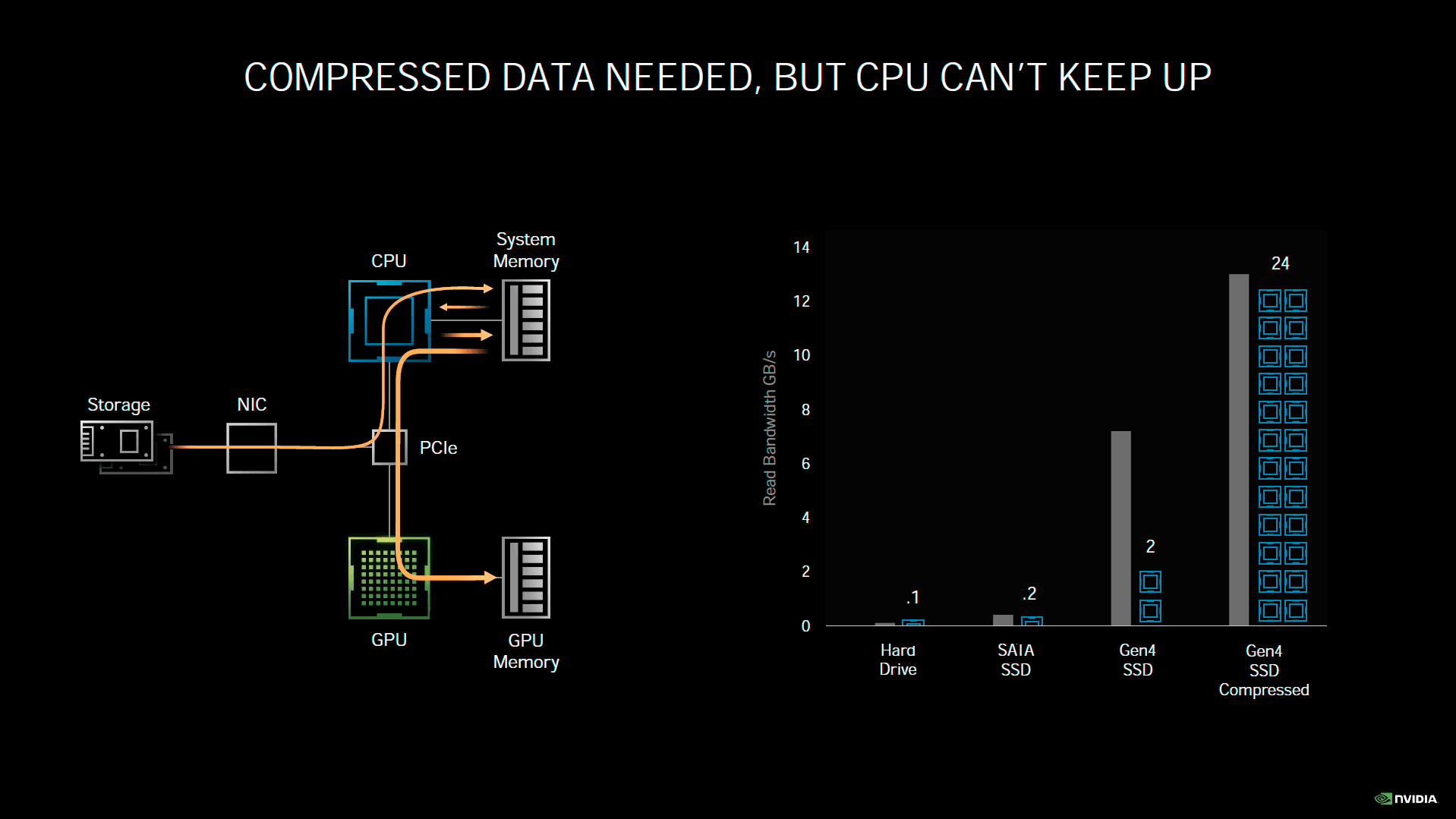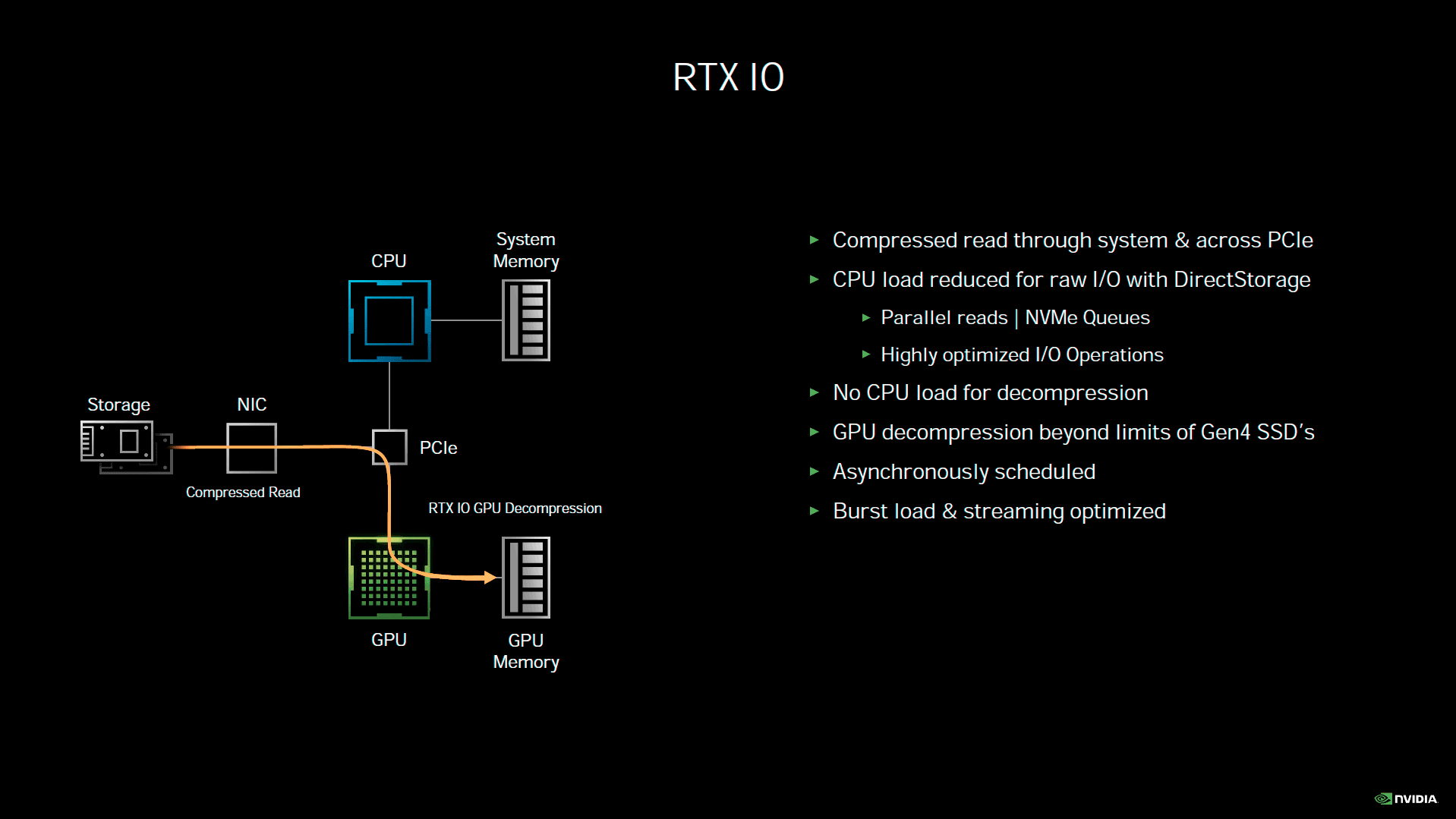
Probablement une des annonces les plus inattendues de Nvidia concernant Ampere, RTX IO est un mécanisme destiné à réduire considérablement les temps de chargement des données, depuis le périphérique de stockage, à destination de la mémoire vidéo. Actuellement, les données doivent d'abord transiter par le CPU pour une mise en tampon et organisation dans la mémoire centrale, en attendant que le GPU soit en condition d'accepter les données. Une fois prêt, l'opération de transfert a finalement lieu. Les données vont donc transiter deux fois par les interfaces, avant d'être enfin stockées au sein de la mémoire vidéo. Il est également possible de compresser les données au niveau du stockage, afin d'économiser en bande passante. En contrepartie, le CPU sera fortement sollicité par la décompression des données, avant de pouvoir les transférer à la carte graphique. En sus de l'encombrement des bus, la charge sur le CPU peut donc elle aussi, être considérable. Partant de cet état des lieux, Nvidia propose donc d'apporter sa pierre à l'édifice, sa solution étant prévue pour fonctionner de concert, avec Microsoft DirectStorage pour Windows.
![RTX IO [cliquer pour agrandir]](/images/stories/articles/gpu/ampere/architecture/rtxio_t.gif "Visionner en grand sur un magnifique pop-up")
Le principe de fonctionnement de RTX IO
Pour l'heure, il manque donc de nombreuses briques logicielles, avant que RTX IO puisse être fonctionnel. La première est bien évidemment la prise en charge par l'OS. Microsoft estime pouvoir fournir une version preview de DirectStorage l'année prochaine. Une fois ce point levé, RTX IO devrait être en mesure, au travers de l'API de Microsoft, de charger directement les données depuis le périphérique de stockage, vers la mémoire vidéo, si et seulement si, la fonction est utilisée par les développeurs du jeu. Mieux, les données peuvent-être stockées de manière compressée, et la puissance du GPU pourra sans souci les décompresser à la volée, sans ralentir un SSD PCIe 4.0. Une puce Turing ou Ampere sera nécessaire, reste tout de même une question épineuse. Lors d'un écran fixe de chargement d'un niveau par exemple, le GPU sera alors peu sollicité et pourra donc sans difficulté réaliser cette tâche. Quid de l'usage en plein jeu par contre ? Durant une phase de rendu, le GPU est souvent sollicité au maximum de ses possibilités, or, RTX IO repose sur les mêmes SM, qui devront traiter cela. Les capacités d'Async Compute de Turing et Ampere, pourront s'avérer utiles dans ce cas, mais encore faut-il que des ressources soient disponibles. Bref, nous attendons de voir la chose en pratique.
Commençons par la disparition du port VirtualLink. Ce dernier permettait de regrouper au sein d'un connecteur USB Type C, le flux d'affichage, de données et l'alimentation destinée aux casques VR. De nombreux acteurs de la VR étaient partie prenante de ce projet, pourtant aucun casque n'a vu le jour utilisant ce format. C'est une déception, une de plus dans l'univers de l'informatique, impitoyable pour certaines technologies. Aux rayons des bonnes nouvelles, voici enfin une série de GPU qui va proposer nativement l'HDMI 2.1 avec compression DSC 1.2a. De quoi fournir une bande passante totale de 48 Gbps, via 4 canaux. Nvidia nous a par ailleurs confirmé que les TV intégrant un port HDMI 2.1, telles les LG OLED CX, supportent bien la VRR, un bon point pour les joueurs sur TV. Le DisplayPort 2.0 n'est pas de la fête, probablement trop récent, la version 1.4 couplée là aussi au DSC 1.2a, permet toutefois de répondre à la plupart des besoins actuels (jusqu'à 8K en 60 Hz + HDR via DSC). Résumons les différentes normes contemporaines dans le tableau suivant.
| norme | Bande passante maximale | bande passante par ligne / canal |
Définition maximale supportée |
|---|---|---|---|
| DisplayPort 1.2 | 21,6 Gbps | 5,4 Gbps | 4K @60 Hz |
| DisplayPort 1.3 | 32.4 Gbps | 8,1 Gbps |
8K @ 60 Hz 4K @ 120 Hz |
| DisplayPort 1.4a | 32.4 Gbps | 8,1 Gbps |
8K @ 60 Hz + HDR* 4K @ 240 Hz + HDR* |
| DisplayPort 2.0 | 80 Gbps | 20 Gbps |
16K @ 60 Hz + HDR* 10K @60 Hz + HDR* |
| HDMI 1.4 | 10,2 Gbps | 3,4 Gbps | 4K @ 30 Hz |
| HDMI 2.0b | 18 Gbps | 6 Gbps |
4K @ 60 Hz 8K @ 30 Hz* |
| HDMI 2.1 | 48 Gbps | 12 Gbps |
4K @ 240 Hz + HDR* 8K @ 60 Hz + HDR* |
| * nécessite DSC 1.2a ou format de couleur 6-bit (4:2:0) | |||

Vous pouvez aussi vous rendre sur notre recap de référence avec plein de chiffres
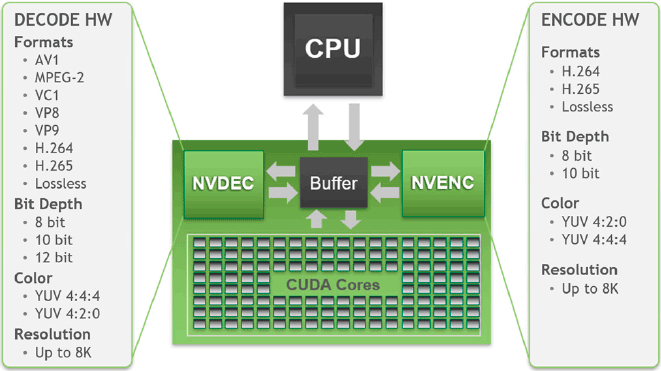
Passons à présent au moteur vidéo. Sur le front de l'encodage, rien à signaler depuis Turing, puisqu'Ampere réutilise la version 7 de l'encodeur maison, aka NVENC, qui est parmi, si ce n'est le plus performant, à l'heure actuelle. Côté décodage par contre, une nouvelle version (la cinquième) est à l'oeuvre ici, avec le support plus que bienvenu de l'AV1. Ce codec ouvert sans royalties à payer, permet de meilleurs taux de compression ou de qualité d'image que le H.264 et HEVC / VP9. La contrepartie est une décompression très gourmande, pouvant mettre à genoux de nombreux processeurs en haute définition. Le décodage par le GPU permet de réduire à minima le taux d'usage du processeur central, il faudra tout de même vérifier la consommation du GPU dans ces conditions. A priori, même les cartes moins rapides devraient intégrer ce nouveau moteur vidéo de décodage. Puisqu'un dessin vaut mieux qu'un long discours, voici un petit rappel de tout cela.
Ampere est compatible avec la Gen 4 du PCI Express, revenant ainsi au niveau de Vega 20 (bridé en 3.0 sur la Radeon VII toutefois) et de Navi 1x. Pour rappel, cette révision double la bande passante par rapport à la génération précédente, permettant dans le cas du traditionnel port x16 utilisé par les cartes graphiques, d'atteindre jusqu'à 64 Go par seconde. Pour le moment, les seules plateformes compatibles PCIe Gen4, sont celles d'AMD (chipset série 500 ou TRX40) équipées d'un CPU Zen 2. Par acquit de conscience, nous avons également testé notre RTX 3080 sur une telle plateforme, sans souci notable, le PCie 4.0 est bien actif. Par contre, comme on pouvait s'y attendre, aucun gain significatif de performance, n'est à noter.
GA102 gère également 4 liens NVLink de 3e génération, pour une bande passante totale de 112,5 Go/s entre deux cartes. Seule la RTX 3090 les verra activés, permettant un SLi sur 2 cartes maximum. Vu l'épaisseur de cette dernière en version FE, il faudra déjà trouver une carte mère compatible. Ça sent donc vraiment le sapin pour le multi-GPU. Clôturons cette partie par une évidence, mais qu'il est toujours bon de rappeler. Turing supportait déjà tous les niveaux de fonctionnalités adéquats pour DirectX 12 Ultimate, c'est également le cas d'Ampere. Nvidia n'annonce pas d'ajouts, mais est-ce par absence ou non-communication pour l'heure ? L'avenir nous le dira, puisque nous ne sommes plus à une surprise près. Voyons d'autres fonctionnalités annoncées par le caméléon lors de ce lancement, page suivante.
|
|
| Un poil avant ?Live Twitch • Tell Me Why, du narratif posé | Un peu plus tard ...NVIDIA donne ses ambitions pour ARM et son architecture | |