Test • Intel Core i9-11900K / i7-11700K / i5-11600K & Z590 |
————— 30 Mars 2021



Test • Intel Core i9-11900K / i7-11700K / i5-11600K & Z590 |
————— 30 Mars 2021
À trop vouloir en faire, les bleus se sont retrouvés pris au dépourvu au moment du lancement final de Rocket Lake. En effet, si ce Cypress Cove rompt avec les six ans de Skylake réchauffé optimisé, cette microarchitecture n’est pas nouvelle, puisque directement issue de la génération mobile : Tiger Lake, basé sur des cœurs Willow Cove. Cependant, cette révision n’est elle-même qu’une mise à jour mineure de Sunny Cove (intronisé avec Ice Lake et détaillée à l’Architectural Day 2018), bénéficiant principalement d’une réorganisation des caches et l’ajout de quelques extensions x86 nommées Control-Flow Enhancing Technology. Le rapport avec le schmilblick ? Hé bien, ce Cypress Cove n’incorpore ni l’un ni l’autre, autant dire que ce patronyme barbare n’est, finalement, "qu’une" adaptation 14 nm du lac glacé. De quoi apporter, sur le papier, un désavantage en ce qui concerne l’efficacité énergétique par rapport à la concurrence en 7 nm, mais un potentiel certain à monter dans les tours ; et c’est bien ce qui nous intéresse sur plateforme mainstream.
![Un die bien meublé ! [cliquer pour agrandir]](/images/stories/articles/cpu/rocket_lake/rocket-lake-organisation_t.jpg "Visionner en grand sur un magnifique pop-up")
À droite, le die tout nu, à gauche, son diagramme logique
Du fait de cette architecture déjà dévoilée en grande pompe maintes fois, le fondeur de Santa Clara s’est probablement retrouvé coincé au moment de résumer les principales évolutions d’une manière graphique, nous avons donc dû vérifier ça et là les informations concernant le nouveau venu... Il faut dire qu’une slide récapitulant le sur-place face à Ice Lake n’était probablement pas du goût du département marketing, même si les +18 % d’IPC promis (par rapport à Comet Lake) devraient bel et bien être présents.
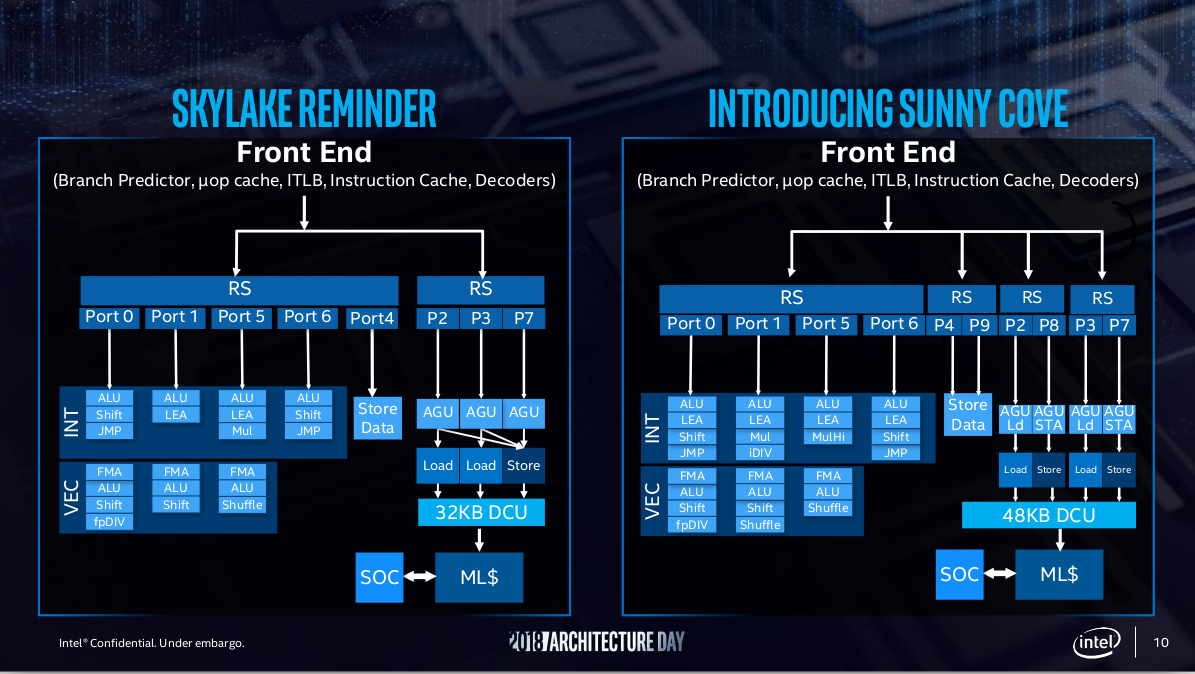
Trêve de plaisanteries, plongeons dans le vif du sujet. Du point de vue du back-end, Cypress Cove est un bon en avant spectaculaire avec le passage de 8 à 10 ports d’exécutions, qui comble l’asymétrie entre chargement mémoire et rangement mémoire introduite sur Skylake. Ainsi, les ports 8 et 9 viennent respectivement s’occuper de la génération d’adresse et du stockage en tant que tel, assurant ainsi la possibilité d’effectuer deux chargements et deux enregistrements par cycle (de 64 octets chacun), tout du moins lorsque le sous-système mémoire suit. Les mémoires tampons concernées sont, du coup, légèrement gonflées, avec un passage à 128 opérations dans la queue des chargements mémoires (contre 72 sur Skylake), et 72 pour celle des rangements (contre 56 précédemment). Côté puissance brute, Intel a également été resserrer les boulons en rajoutant des possibilités de calculs aux ports déjà en place, principalement sur les ports 0 et 5 qui peuvent désormais effectuer des LEA, une instruction x86 permettant de stocker dans un registre une adresse mémoire complexe, typiquement lors d'un accès indirect à une donnée nécessitant plusieurs indirection — par exemple, un nombre placé dans un tableau, lui-même attribut d'une structure de donnée accédée via un pointeur.
![Skylake contre Sunny Cove [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architectural-day-2018/skl-vs-sunnycove_t.png "3N C11QU4N7 C357 P1U5 6r4ND")
Un pipeline plus large pour exprimer davantage de parallélisme au niveau des instructions : la meilleure solution technique pour augmenter uniformément les performances
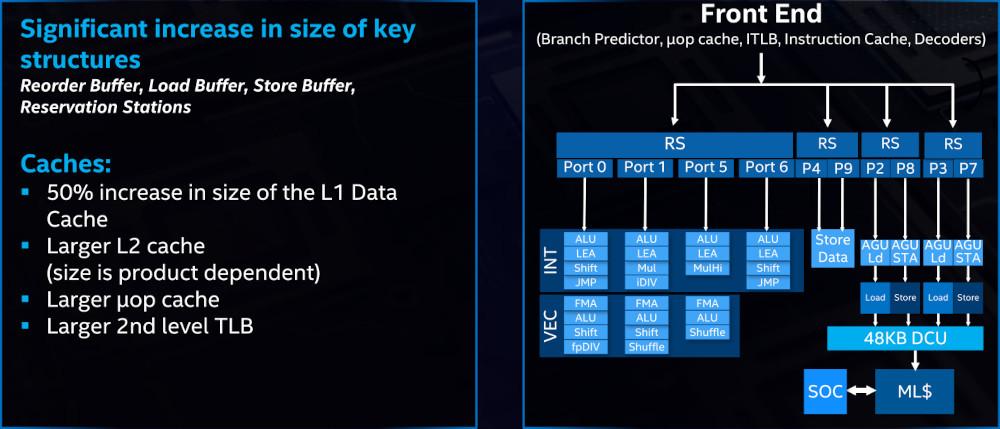
Ainsi, les deux principaux concepteurs de CPU ont opté pour des solutions techniques somme toute similaires afin d’augmenter l’IPC, puisque les rouges ont également été modifier avec Zen 3, leur pipeline d’exécution en grossissant le Reorder Buffer (ou ROB, une mémoire contenant l’ensemble des instructions sélectionnées pour être potentiellement exécutées/en cours d’exécution/en cours de terminaison, qui passe, chez les bleus, de 224 micro-ops à 352), le retire buffer et en travaillant du côté du front-end (cf paragraphe suivant). Similairement, l'ordonnanceur (constitué des éléments exécutables pour sûr) explose en passant de 97 à 160 entrées, offrant désormais la possibilité d’allouer les micro-ops sur 10 chemins différents, contre 8 sur la microarchitecture précédente... pour 10 ports, c’est mieux !
Cependant, de chaque côté, le décodeur reste inchangé avec un débit maximal de 16 octets par cycle, probablement le plus gros goulot d’étranglement des deux architectures, sachant que l’avantage reste côté rouge pour l’IPC, avec une limitation au niveau du dispatch de 6 instructions par cycle, contre 5 pour Cypress Cove / Ice Lake, qui reste un progrès significatif par rapport aux 4 des Sky-/Kaby-/Coffee/Comet Lake précédent.
![sunny cove buffers improvement t [cliquer pour agrandir]](/images/stories/articles/cpu/rocket_lake/sunny-cove-buffers-improvement_t.jpg "Ultra bouzotron HD max def")
Avec un tel goulot d'étranglement au niveau du décodage de l’assembleur, les autres composants du front-end doivent fortement évoluer afin de pouvoir tout de même fournir une quantité suffisante de micro-instructions, pour alimenter efficacement le back-end plus large. Ainsi, le cache contenant les micro-ops déjà décodées passe de 1 500 à 2 250 entrées, et la prédiction de branchement est également gonflée avec la possibilité de se souvenir jusqu'à 70 micro-ops formant une boucle (contre 64 auparavant), et une allocation queue (mémoire précédant le ROB) de 70 entrées par threads (contre 64 également auparavant). Enfin, notez que la mémoire cache de table des pages côté instructions (pour les hugepages de 2 Mio) est doublée, passant de 8 à 16 entrées. Précisons que le prefetching est également revu, sans que nous ayons de données officielles à son sujet.
À cela, Intel rajoute l’AVX-512 (ainsi que les extensions VNNI / DL Boost), soit la possibilité de doubler le débit d’exécution de calculs par rapport à l’AVX-2 précédent (comprenez que, pour un même nombre d’instructions, la version AVX-512 ira deux fois plus vite), un progrès qui n’est donc pas reflété par l’IPC. Néanmoins, seuls les codes à dominance scientifique tirent pleinement parti de ce progrès : machine learning, simulations physiques ou rendus 3D complexes... mais pas pour une utilisation vidéoludique. Tant qu’à causer des extensions x86, Intel rajoute également les Galois Field New Instructions, utilisés principalement pour le chiffrement AES. Une fois encore, pas vraiment de quoi bouleverser l’ordre établi des performances, mais l’occasion de gagner de précieuses parts de marché chez les professionnels. Or, pour les joueurs, ce n’est pas tant l’ajout d’extensions qui peut être utile que leur retrait : l’AVX entraîne en effet des instabilités de tension, fatales aux hautes fréquences, c’est pourquoi les bleus permettent désormais un contrôle plus fin des fréquences des extensions vectorielles, allant jusqu’à la possibilité de les désactiver totalement afin de monter toujours plus haut sur la cadence principale.
![Des caches, plus de caches ! [cliquer pour agrandir]](/images/stories/articles/cpu/rocket_lake/sunny-cove-cache-improvement_t.jpg "Ultra bouzotron HD max def")
Côté mémoire, la principale amélioration de Rocket Lake se situe sur le L1-D, qui prend un sympathique bonus de +50 %, passant à 48 Kio. Notez que l’instruction cache n’augmente pas, et reste tranquillement à 32 Kio. Le reste de la hiérarchie mémoire évolue un peu : 512 Kio de L2 privés par cœur (contre 256 Kio pour Skylake), et 2 Mio de L3 par cœur, partagé cette fois-ci. Si nous regrettons les avancées de Willow Cove (1,25 Mio de L2 / 3 Mio de L3), Intel communique sur un die "trop gros" pour y rajouter quoi que ce soit — cache ou cœurs supplémentaires, d’ailleurs. Si l’on se doute que l’argument ne découle pas uniquement d’une contrainte technique — NVIDIA gravant via TSMC / Samsung des dies bien plus gros depuis longtemps —, il n’est pas dit que le dégagement thermique n’en devienne pas insurmontable ; sans compter les obligations liées à la place disponible sur le socket et les considérations internes (taille de masques, rentabilité). Notez que les tables des pages évoluent également : l’adressage passe de 48 bits physiques à 57 (l’OS ne voyant toujours que 64 bits) : de quoi adresser 128 Pio de RAM, contre 256 Tio sur Skylake, et les caches associés évoluent également : le STLB passe de 16 à 1024 entrées pour les pages de 1 Gio, celles de 4 Kio passent de 1536 à 2048 entrées, et deux nouveaux caches sont créés pour les pages de 2 Mio et 4 Mio, tous deux de 1024 entrées.
Enfin, une puce en 2021 n’est plus seulement définie par sa puissance de calcul généraliste, mais également par ses contrôleurs embarqués et son iGPU (on préférera d’ailleurs les termes d’APU — issu d’AMD — ou de SoC - plutôt hérité du monde mobile). Ici, Rocket Lake marque deux points, et de taille. Côté contrôleur, Intel se met (enfin ?) au PCIe 4.0 avec 20 lignes proposées (16 pour le/s GPUs et, nouveauté, 4 pour un ou deux SSD [attention donc si vous mettez un Comet Lake sur chipset 500]) sortant directement du CPU ; un gonflement des entrées/sorties que partage le chipset, désormais lié par 8 lignes DMI 3.0 — l’impasse étant faite sur le 4.0 faute de design (IP) disponible en 14 nm côté chipset — dont la répartition dépendra de votre carte maman. Nous reviendrons plus en détail sur ce sujet dans quelques pages.
![Apports de la plateforme [cliquer pour agrandir]](/images/stories/articles/cpu/rocket_lake/key_t.png "Enlarge your pe...icture")
Les points clés de la plateforme
Côté GPU, c’est bien entendu Xe aux manettes ; un choix objectivement discutable — la complexification du GPU est réalisée au détriment de la partie CPU —, d’autant plus que les références les moins bien dotées de ce côté et donc potentiellement destinées aux machines d’entrée de gamme à prix plancher, n'intégrant donc pas de carte graphique dédiée, ne sont pas particulièrement bien loties. Ainsi, avec 32 unités d’exécution (EU), Rocket Lake est moins bien pourvu que le plus petit des i3 Tiger Lake (48 EU), autant dire que ce n’est pas avec cette génération de puces qu’Intel s’embarquera dans une course effrénée à la puissance des APU... Pourquoi pas au vu du frein qu’est la DDR4 par rapport aux GDDR actuelles, au débit bien plus élevé. Pourquoi pas, mais alors pourquoi ne pas réduire au maximum la complexité du GPU interne, en le limitant aux seules fonctions d'affichage ? Du fait d’un futur dossier entièrement réservé à cet iGPU, son organisation technique ne sera pas davantage explicitée ici ; mais vous pouvez trouver de quoi satisfaire votre curiosité à l’Architecture Day ainsi que sur notre billet dédié à la Gen11.
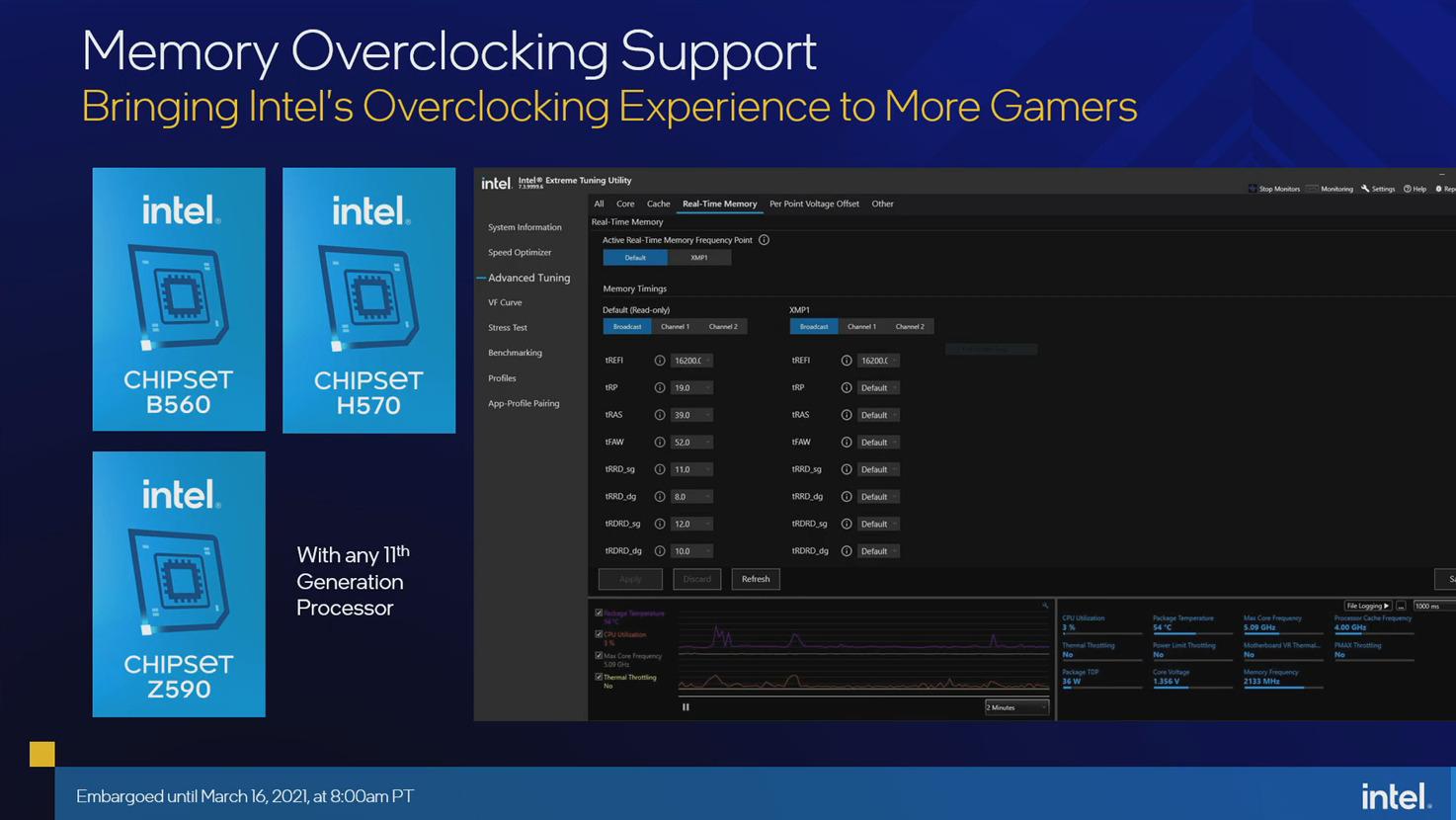
![Chipsets série 500 : de l'OC mémoire pour tous !! [cliquer pour agrandir]](/images/stories/_cpu/14nm_intel/500-series-chipset-memory-oc_t.jpg "La magie de la loupe, sans loupe")
Puisque nous parlons RAM, sa liaison avec le processeur semble également évoluer, mais rien n’est clair sur le papier : Intel communique sur un support complet (comprenez, en ratio 1:1) de la DDR4 2933 MHz sur toute sa gamme, et 3200 MHz pour les i9, les autres modèles passant en ratio 2:1 pour atteindre ce premier chiffre. Pour autant cela ne se retrouve pas sur les tests bas niveau des i5 et i7 testés qui conservent sur notre carte mère le ratio 1:1. A noter que le déblocage de l’overclocking mémoire sur une partie des chipsets non-Z (H570 et B560, mais pas H510) devrait permettre à tous les joueurs de chercher par eux-mêmes leur réglage optimal.
|
|