Test • Nvidia GeForce RTX 4090 |
————— 11 Octobre 2022



Test • Nvidia GeForce RTX 4090 |
————— 11 Octobre 2022
Si vous n'êtes pas ou peu familiers avec les architectures modernes du caméléon, nous vous invitons donc à relire les pages que nous avions dédiées à ces dernières, en particulier celles dévolues à Maxwell, Pascal, Turing, et bien sûr Ampere pour vous aider dans la compréhension du présent article. En pratique, Ada Lovelace ressemble à s'y méprendre à ce dernier pour la partie calcul "traditionnel", c'est pourquoi vous retrouverez une bonne partie de notre analyse de l'époque ci-dessous. À contrario d'autres unités, dont celles liées au ray tracing, évoluent significativement.
L'entité à tout faire chez Nvidia, se nomme toujours SM pour Streaming Multiprocessor. Pas de changement au niveau de la structure de base, avec 128 unités FP32 par SM, par contre la moitié d'entre elles doit toujours partager un chemin de données commun avec les unités en charge des entiers (INT32).
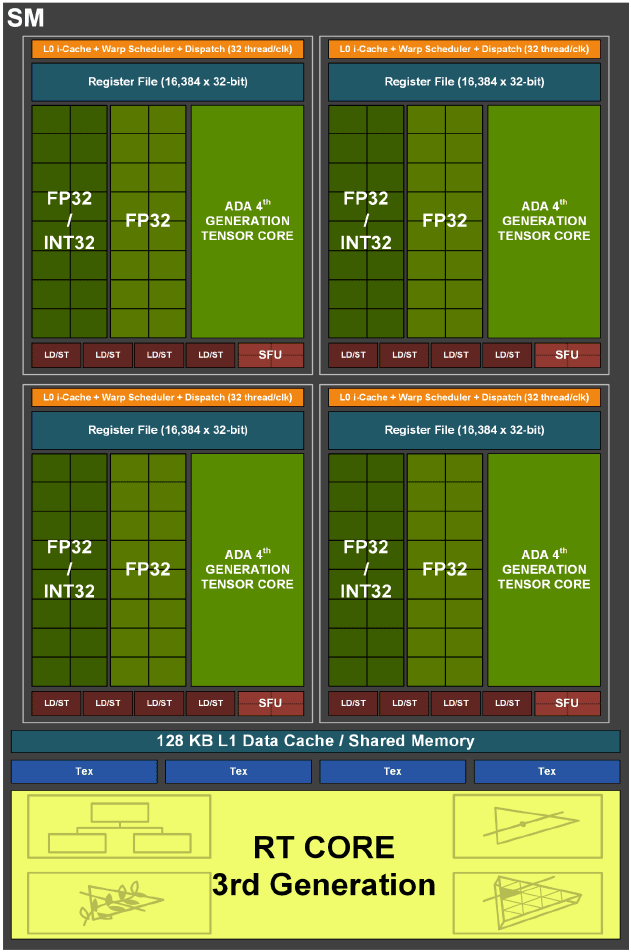
Un SM Ada Lovelace
Petit retour en arrière : avec Turing (Volta plus précisément, mais pas de déclinaison grand public de cette microarchitecture), Nvidia indiquait avoir créé un second chemin de données (data path) pour permettre l'exécution concomitante d'une opération sur entier et d'une autre en virgule flottante. Cette possibilité permet d'après les études de différents shaders (à l'époque) menées par le caméléon, d'augmenter de 36% l'utilisation des unités FP32. En effet, ces dernières ne doivent plus "laisser la place" aux INT32 lorsqu'il y a besoin de calculer un entier, chacun disposant à présent de son propre chemin de données.
Cette modification est très coûteuse à mettre en place en termes de bande passante mémoire, c'est pourquoi le caméléon s'est penché sur la possibilité de maximiser les gains liés à cette dernière. Puisque le chemin de données dédié aux INT32 est loin d'être saturé lors de l’exécution de shaders, comment mettre à profit cette ressource potentielle ? La réponse a donc été d'ajouter sur Ampere, 64 unités FP32 au sein du SM, mais qui vont cette fois devoir partager le même chemin de données que les INT32 (façon CUDA Cores pré-Volta donc). Ada Lovelace reprend cette structure.
C'est le sens de la représentation graphique du SM, puisqu'il ne s'agit en rien d'une fusion d'unités, juste de la représentation simplifiée d'INT32 et FP32 distinctes, mais partageant le même data path (le second bloc de FP32 disposant lui de son propre chemin de données dédié). Mécaniquement, le taux d'utilisation de ces 64 FP32 supplémentaires par SM, sera directement corrélé à celui des INT32, et comme les premières ont vu leur nombre total doublé par SM, alors la probabilité de sollicitation des secondes, grandit en conséquence durant l'exécution de shaders. Tout dépendra donc des usages : si un programme donné n'a pas besoin de calculer d'entiers, alors le débit réel en flottants sera bel et bien doublé par cycle. Si par contre le besoin en entiers est significatif, alors le bloc de FP32 partageant le même chemin de données que les INT32, sera impacté en conséquence.
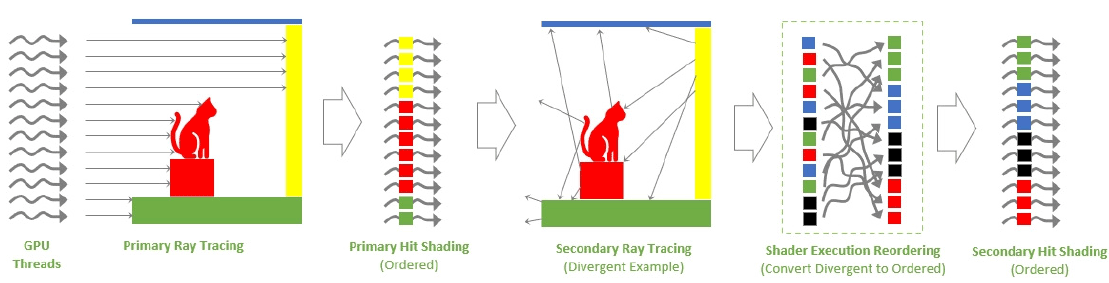
Avant de s'attaquer aux nouveautés apportés aux RT Cores de 3ème génération page suivante, intéressons nous d'abord à l'autre nouveauté qu'introduit Nvidia au sein de ses SM pour améliorer les performances en Ray Tracing, à savoir le Shader Execution Reodering ou SER. En effet, le caméléon (mais aussi Intel via l'implémentation de ses Thread Sorting Unit au sein de ses Xe-Core, le pendant bleu des SM) est bien conscient qu'augmenter la puissance brute de ses RT Cores, n'est pas suffisant pour garantir des performances optimales avec du contenu faisant appel au Ray Tracing. En effet, les tâches liées au lancer de rayons peuvent être entravées par un certain nombre de facteurs.
Ainsi, les shaders liés au RT dit divergents, sont de plus en plus limitants, à mesure que les chemins empruntés par les rayons, deviennent de plus en plus aléatoires, lors des multiples rebonds ou lors de l'évaluation de matériaux complexes, affectant ces derniers. La divergence peut prendre deux formes : celle d'exécution, où les threads exécutent différents shaders (ou chemins de code au sein d'un même shader), et la divergence de données, où les threads accèdent à des ressources mémoire difficiles à fusionner ou à mettre en cache. Les deux types de divergence se produisent naturellement dans de nombreux scénarios de lancer de rayons et cela impacte fortement les performances, puisque les GPU fonctionnent plus efficacement lorsque le travail à réaliser est uniforme pour le paralléliser au maximum. C'est là qu'entre en jeu le SER.
![Principe du Shader Execution Reodering [cliquer pour agrandir]](/images/stories/articles/gpu/ada_lovelace/ser_t.png "La magie de la loupe, sans loupe")
Le schéma ci-dessus montre un exemple simple de lancer de rayons. En partant de la gauche, un certain nombre de threads GPU projettent des rayons primaires dans une scène. Les rayons primaires frappant les objets suivent la même trajectoire : ils sont donc exécutés au sein du même shader, correspondant tout à fait au modèle d’exécution d’un GPU SIMT (une instruction, une multitude de threads). Les difficultés commencent lorsque des rayons secondaires sont générés à chaque point d’impact d’un rayon primaire.
En effet, à partir des surfaces d’impact, les trajectoires divergent et cela va s’accroître au fur et à mesure des rebonds et de la complexité des surfaces touchées. Nous nous retrouvons alors avec un paradigme différent : plusieurs instructions pour plusieurs threads ! De ce fait, les shaders se multiplient, rendant leur exécution parallèle bien moins efficace par le GPU, calibré pour quelques shaders seulement, aux chemins de code homogènes. Le SER ajoute donc une nouvelle étape dans le pipeline de lancer de rayons, en réorganisant et regroupant le shading des rebonds secondaires, pour retrouver cette homogénéité si chère aux performances GPU. De quoi obtenir une efficacité globale beaucoup plus élevée.
Si Intel indique qu'il a ajouté une unité dédiée à ces opérations en sortie des unités de lancer de rayons, Nvidia est bien mois loquace à ce sujet. Tout juste se borne-t-il a préciser que :
l'architecture matérielle Ada a été conçue avec SER à l'esprit et inclut des optimisations du SM et du système de mémoire spécifiquement ciblées pour une réorganisation efficace des threads.
Ok, on est bien avancé avec ça, les verts utilisent peut-être une unité spécifique chargée de ces tâches à l'instar d'Intel, ou - plus vraisemblable au vu des communications de la GTC - inclut de nouvelles capacités aux ordonnanceurs déjà présents dans le SM, allez savoir. Un point intéressant et divergeant (au moins officiellement) entre bleus et verts, se situe au niveau du fonctionnement du SER. En effet, sur Xe-HPG, l'unité dédiée semble autonome d'après Intel, c'est à dire quelle va réorganiser toute seule comme une grande les tâches, alors que du côté ADA, Nvidia évoque un processus bien différent :
SER est entièrement contrôlé par l'application via une petite API, permettant aux développeurs d'appliquer facilement la réorganisation là où leur charge de travail en profite le plus. L'API introduit en outre plus de flexibilité autour de l'appel des shaders liés au RT, permettant de mieux structurer les implémentations du moteur de rendu, tout en tirant parti de la réorganisation. De plus, nous ajoutons de nouvelles fonctionnalités au profileur de shader NSight Graphics, afin d'aider les développeurs à optimiser leurs applications pour SER. Les développeurs peuvent ainsi utiliser les extensions NVAPI spécifiques à NVIDIA pour implémenter SER dans leur code. Nous travaillons également avec Microsoft et d'autres pour étendre les API graphiques standard avec SER.
L'approche des verts semble donc (là encore si on se base sur les annonces de part et d'autre) faire appel aux différents développeurs pour tirer parti au mieux de la fonctionnalité au sein des moteurs 3D. C'est indéniablement une grande force du caméléon, sa capacité à proposer aux différents développeurs un environnement logiciel leur facilitant la tâche, pour tirer le meilleur de son hardware spécifique, encore faut-il que ce boulot d'optimisation soit réalisé en pratique !
Comment le caméléon s'y prend-t-il pour alimenter correctement ses différentes unités de calculs ? Comme nous l'avons indiqué précédemment, il n'y a pas beaucoup de différence entre Ampere et Ada à ce niveau, à une (grosse) exception près. Ainsi, un SM Ada est toujours organisé en 4 partitions, chacune étant pilotée par un couple ordonnanceur / dispatcheur (32 threads/cycle). Ils incluent en sus des 16 INT32 et 32 FP32, 4 unités de texturing, 4 unités load/store pour les accès mémoire, un cache L0 dédié aux instructions, 64 Ko pour les registres 32-bit, 4 SFU traitant des fonctions complexes (Cos, Sin, etc.) en simple précision, un Tensor Core de troisième génération et un RT Core de seconde génération. Des unités FP64 sont également présentes pour assurer la compatibilité avec les applications en faisant usage, mais avec un débit réduit au 1/64ème de celui en FP32. Le cache L1 est unifié avec la mémoire partagée et le cache de textures. Nvidia n'indique pas les valeurs de ce partage en utilisation Compute, elles étaient les suivantes sur Ampere et probablement inchangées donc :
| L1 | Mémoire Partagée |
|---|---|
| 128 Ko | 0 Ko |
| 120 Ko | 8 Ko |
| 112 Ko | 16 Ko |
| 96 Ko | 32 Ko |
| 64 Ko | 64 Ko |
| 28 Ko | 100 Ko |
Dans un contexte de charge graphique par contre, la répartition était la suivante pour Ampere (là aussi nous supposons que ces valeurs sont inchangées avec Ada) : 64 Ko L1 + Texture cache (x2 / Turing), 48 Ko de mémoire partagée et 16 Ko réservés pour diverses opérations au niveau du pipeline graphique. Au total, AD102 complet inclut pas moins de 18 432 Ko de L1, à comparer aux 10 752 Ko d'Ampere, la différence venant de l'augmentation du nombre de SM au sein du GPU. Quid du cache L2 à présent ? Eh bien on oublie les 6 Mo des TU102/GA102 pour passer à 96 Mo, soit le double des 48 Mo d'un GA100.
Le cache L2 est toujours rattaché par partition à chaque contrôleur mémoire 32-bit, mais du fait de l'augmentation considérable de sa capacité, Ada permet à présent la désactivation d'une fraction de ce L2 connecté à chacun des contrôleurs, ce qui n'était pas le cas des microarchitectures précédentes. Mais au fait, pourquoi une telle inflation ? Probablement en raison de la stagnation de la mémoire vidéo. Certes, la GDDR6X gagne un peu en fréquence par rapport à celle intronisée sur Ampere, mais les puces les plus rapides sur RTX 40 se limitent pour l'heure à 22,4 Gbps (4080 16 Go), contre 21 Gbps pour la série 30 (3090 Ti). Un gain de 6,7 %, loin d'être comparable à celui qui intervient du côté de la puissance de calcul.
Augmenter ainsi considérablement le cache, va permettre d'amplifier la bande passante à destination des unités de calcul. Si les données nécessaires sont présentes en cache (et plus il est grand, plus il y a de chances que cela se produise), alors le débit ne sera plus celui de la mémoire, mais bel et bien celui du cache L2, infiniment plus rapide (et moins couteux en énergie qu'un accès mémoire). A noter qu'AMD a visé le même objectif avec RDNA2, mais avec une approche légèrement différente. Au lieu de gonfler le L2, il a ajouté un niveau supplémentaire (L3 ou Infinity Cache), partagé à tout le GPU et d'une plus grosse capacité. Finissons par une vue plus macroscopique de cette architecture Ada au sein de son plus gros GPU.
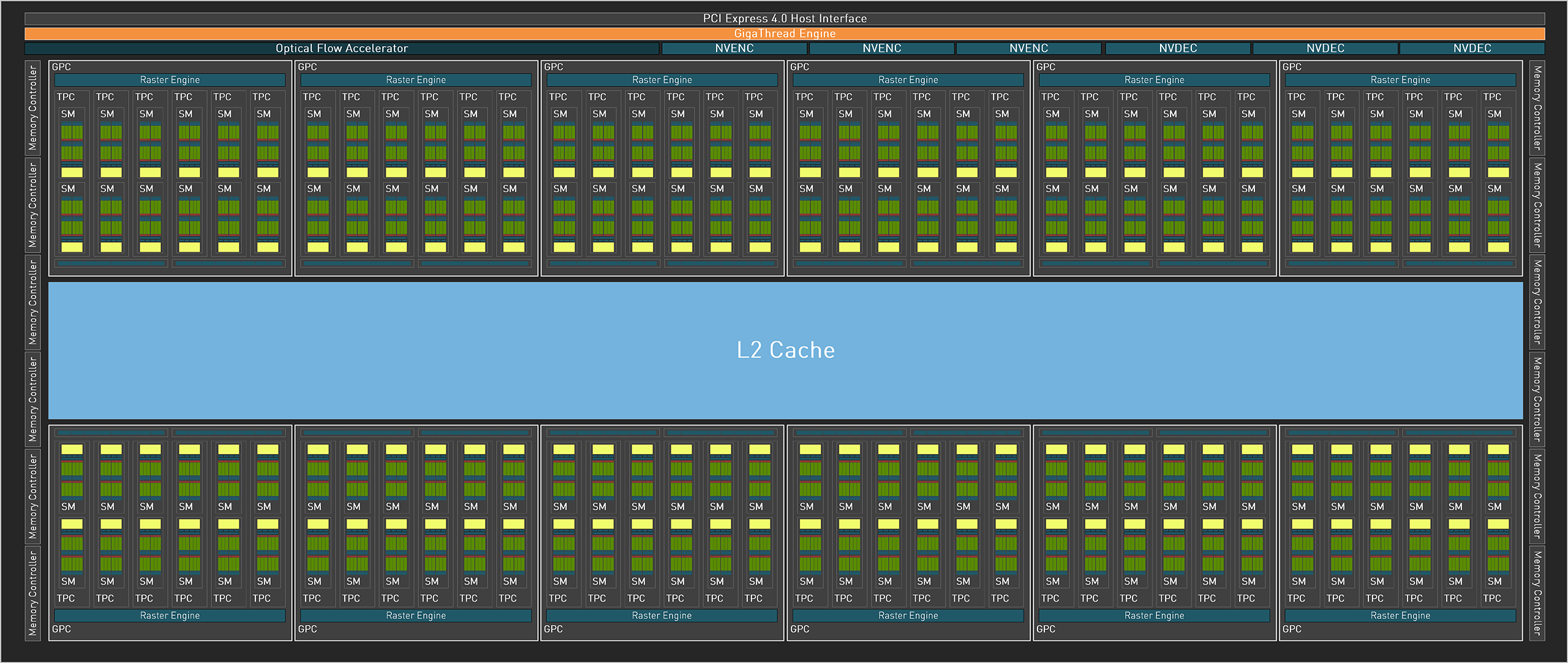
![Ad102 [cliquer pour agrandir]](/images/stories/articles/gpu/ada_lovelace/ad102_t.png "Si vous cliquez, vous cliquez.") Le diagramme d'un AD102 complet
Le diagramme d'un AD102 complet
Si vous êtes familiers des architectures vertes, vous ne serez pas désorientés par ce diagramme. Ainsi, les SM sont à l'instar de Turing, inclus par paire au sein de structures nommées TPC (Texture Processor Cluster), support du Polymorph Engine, c'est-à-dire les unités dédiées à la géométrie (vertice, tesselation). Les TPC prennent de leur côté place par groupe de six au sein des GPC (Graphics Processing Cluster), disposant d'une unité de rastérisation capable de traiter un triangle par cycle. Au total, AD102 comprend 12 GPC, soit 5 de plus que sur GA102, dans leurs versions complètes respectives.
Les ROP (Render Output Unit) sont intégrés au GPC depuis Ampere, et ce par paire de partitions (8 ROP) soit 16 en tout. Avec 12 GPC x 2 partitions x 8 ROP, ce sont pas moins de 192 ROP qui sont présents sur une puce intégrale, le fillrate va donc progresser en conséquence, d'autant que les fréquences font elles aussi un bon notable. Vous noterez également que le caméléon fait apparaitre sur le diagramme, une unité nommée Optical Flow Accelerator (sous GigaThread Engine). Ce n'est en rien une nouveauté, mais si Nvidia l'illustre à présent, c'est quelle prend une importance significative cette fois, comme vous le verrez page suivante, où nous allons poursuivre la description d'Ada Lovelace.
|
|
| Un poil avant ?La relève NUC Extreme chez Intel sera encore moins mini-PC-esque qu'avant | Un peu plus tard ...L'Unreal Engine 5.1 plus très loin de débarquer | |