Test • Nvidia GeForce RTX 4090 |
————— 11 Octobre 2022



Test • Nvidia GeForce RTX 4090 |
————— 11 Octobre 2022
Comme nous l'indiquions en page précédente, NVIDIA a conçu à partir de son architecture Ada Lovelace, un premier GPU portant la dénomination AD102. Dans la nomenclature verte, 102 désigne la puce la plus haut de gamme destinée au grand public. Alors que la génération précédente avait vu Nvidia se tourner (être contraint ?) vers Samsung pour graver ses GPU grand public, retour chez TSMC cette fois, avec le procédé le plus performant pour l'heure, à savoir son 4 nm. Le procédé est décrit comme personnalisé pour Nvidia, sans savoir ce que comprend cette personnalisation. Quoi qu'il en soit, c'est un saut important pour les verts, puisque l'on passe d'un 8 nm Samsung (nœud de gravure 10 nm) sur GA102 à ce 4 nm pour AD102, en faisant l'impasse sur le node 7 nm. Pascal avait en son temps fait l'objet d'un tel saut au niveau du process de fabrication (du 28 nm au 16 nm en faisant l'impasse sur le 20 nm), avec le résultat que l'on connait.

Nous restons pour notre part persuadés qu'Ampere n'a jamais été conçu initialement pour être fabriqué sur le nœud de gravure 10 nm (le 8nm n'est qu'une optimisation de ce node), mais 7 nm. Le manque d'anticipation des verts (pêché d'arrogance ?) les a probablement conduit à l'impossibilité d'obtenir des allocations de production suffisantes chez TSMC, pour toutes ses puces (seule la version Pro GA100 très haut de gamme est produite avec ce procédé 7 nm). Ils se seraient alors tournés vers Samsung et son 8 nm, mais vu le différentiel de performance entre les process respectifs, cela aurait contraint Nvidia à augmenter de manière considérable la consommation de ses cartes, pour obtenir le niveau de performance souhaité. Cela reste une conjecture et seul Nvidia connait la vérité sur le sujet. Pour éviter pareille mésaventure cette fois, le caméléon a mis la main à la poche bien avant.
| Gravure | GPU | Nombre de transistors | Superficie Die |
Densité (Millions de transistors / mm²) |
|---|---|---|---|---|
| 4 nm TSMC | AD102 | 76,3 Milliards | 608,5 mm² | 125,4 |
| 4 nm TSMC | AD104 | 35,8 Milliards | 294,5 mm² | 121.6 |
| 4 nm TSMC | AD103 | 45,9 Milliards | 378,6 mm² | 121.2 |
| 7 nm TSMC | GA100 | 54.2 Milliards | 826 mm² | 65,6 |
| 6 nm TSMC | ACM-G10 | 21,7 Milliards | 406 mm² | 53,4 |
| 7 nm TSMC | Navi 21 | 26,8 Milliards | 520 mm² | 51,6 |
| 7 nm TSMC | Navi 22 | 17,2 Milliards | 335 mm² | 51,3 |
| 7 nm TSMC | Navi 23 | 11,1 Milliards | 237 mm² | 46,8 |
| 6 nm TSMC | ACM-G11 | 7,2 Milliards | 157 mm² | 45,9 |
| 8 nm Samsung | GA102 | 28,3 Milliards | 628,4 mm² | 45 |
| 8 nm Samsung | GA104 | 17,4 Milliards | 392 mm² | 44,4 |
| 8 nm Samsung | GA106 | 12 Milliards | 276 mm² | 43,5 |
| 7 nm TSMC | Navi 10 | 10,3 Milliards | 251 mm² | 41 |
| 7 nm TSMC | Vega 20 | 13.2 Milliards | 331 mm² | 39,9 |
| 16 nm TSMC | GP102 | 12 Milliards | 471 mm² | 25,5 |
| 14 nm GF | Vega 10 | 12.5 Milliards | 495 mm² | 25,3 |
| 16 nm TSMC | GP100 | 15,3 Milliards | 610 mm² | 25,1 |
| 12 nm TSMC | TU104 | 13,6 Milliards | 545 mm² | 25 |
| 12 nm TSMC | TU102 | 18,6 Milliards | 754 mm² | 24,7 |
| 12 nm TSMC | TU106 | 10,8 Milliards | 445 mm² | 24,3 |
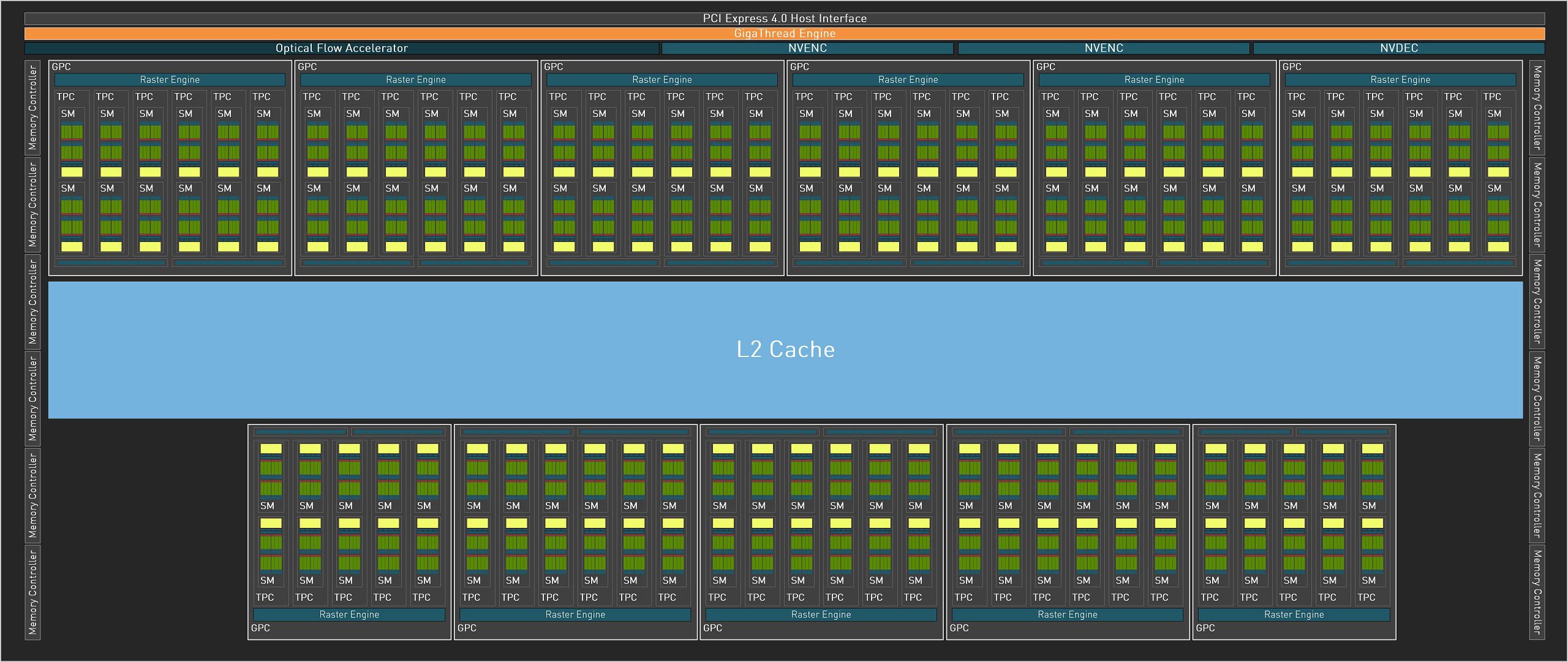
3 puces Ada Lovelace ont été annoncées, nous reviendrons en détails sur les AD103 et AD104, lors du dossier dédié aux RTX 4080. Ce qui est sûr, c'est qu'elles profitent d'une densité exceptionnelle liée au process 4 nm de TSMC. La densité progresse ainsi de presque 2,8 fois entre GA102 et AD102, de quoi coller 2,7 fois plus de transistors, dans une puce 3 % plus petite. Alors que deux cartes graphiques ont été déclinées au lancement d'Ampere à partir de GA102 (3080/3090), la RTX 4090 est la seule à utiliser AD102, en attendant peut-être d'éventuels futurs lancements (4080 Ti & 4090 Ti).
| AD102 | RTX 4090 | Complet |
|---|---|---|
| GPC | 11 | 12 |
| TPC / SM | 64 / 128 | 72 / 144 |
| FP32 | 16384 | 18432 |
| TMU | 512 | 576 |
| Tensor Cores | 512 | 576 |
| RT Cores | 128 | 144 |
| ROP | 176 | 192 |
| L2 (Mo) | 72 | 96 |
| Bus mémoire (bits) | 384 | 384 |
Alors que la RTX 3090 disposait de pratiquement 98% des unités présentes dans le die activées, ce chiffre chute à 88,9 % (un GPC complet est désactivé + 2 TPC dans d'autre(s) GPC, soit 16 SM en tout) pour la RTX 4090. Le cache L2 est de son côté amputé de 25%. Pourquoi un tel différentiel de traitement ? Nous en revenons à notre hypothèse précédente concernant la dégradation du procédé de fabrication d'Ampere, que le caméléon a probablement compensé en partie par ce biais. Ici, avec un procédé à la pointe de la technologie, mais aussi très onéreux, les verts sont probablement davantage confiants face à la concurrence, leur permettant de réduire les caractéristiques, augmentant d'autant les puces qualifiables pour ce modèle, sans faire exploser davantage les coûts.
![AD102 configuré pour la RTX 4090 [cliquer pour agrandir]](/images/stories/articles/gpu/ada_lovelace/rtx4090/ad102_4090_t.png "Enlarge your pe...icture") GA102 tel que configuré pour la RTX 4090
GA102 tel que configuré pour la RTX 4090
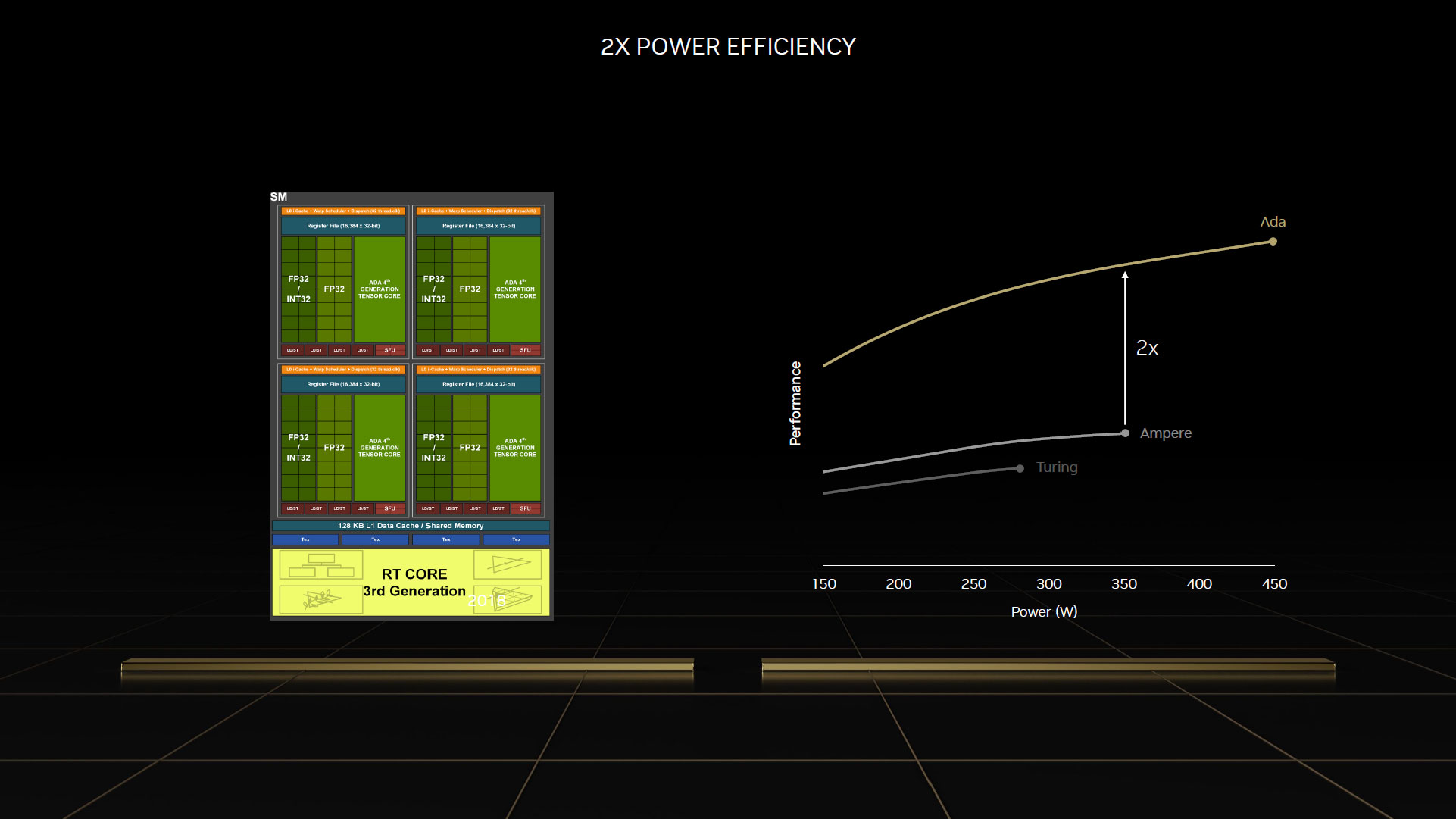
Nvidia précise que cette carte graphique dispose d'un TGP de 450 W, une valeur inimaginable il y a quelques années, et maintenant presque monnaie courante depuis les RTX 3090 Ti ou RX 6950 XT Customs. Si ce n'est pas sans poser des soucis d'ordre environnemental, 2 autres problèmes commencent à émerger avec de tels niveaux. Premièrement, le renchérissement important du prix de l'énergie. Même si nous sommes protégés en France, le prix du KW/h bondira de 15 % en février prochain, ce qui va conduire à un surcoût notable au moment de la facture, en particulier si votre configuration conjugue une carte graphique et un CPU gourmands. Le second point concerne la gestion des nuisances sonores et températures de fonctionnement, qui peuvent devenir problématiques (ce que nous vérifierons bien entendu au niveau des pages dédiées). Enfin, il faut que les performances suivent, car le rapport performance/watts a aussi toute son importance pour jauger de l'efficacité d'un GPU. Nvidia indique qu'Ada progresse notablement à ce niveau (à iso puissance), probablement bien aidé par le process. Nous ne manquerons pas de vérifier cette assertion lors de nos tests.
![Efficacité énergétique GA102 vs AD102 [cliquer pour agrandir]](/images/stories/articles/gpu/ada_lovelace/power_eff_t.jpg "Cliquédélique !")
Ada vs Ampere en efficacité énergétique selon Nvidia
Commençons par le moteur d'affichage. Le port Virtual Link est malheureusement mort et enterré pour les verts, qui l'avaient pourtant introduit avec Turing. Pour rappel, ce dernier permettait de regrouper au sein d'un connecteur USB Type C, le flux d'affichage, de données et l'alimentation destinée aux casques VR. De nombreux acteurs de la VR étaient partie prenante de ce projet, pourtant aucun casque n'a vu le jour utilisant ce format. C'est une déception, une de plus dans l'univers de l'informatique, impitoyable pour certaines technologies. Toujours au rayon des (petites) déceptions, Nvidia n'a, contrairement à Intel, pas intégré le DisplayPort 2.0. Probablement pas jugé nécessaire puisque le DP 1.4 convient parfaitement pour l'immense majorité des usages actuels. Couplé au DSC 1.2a, il permet d'aller jusqu'à 8K en 60 Hz + HDR. Le HDMI 2.1 qui était déjà présent sur Ampere, est toujours de la partie. Résumons les différentes normes contemporaines dans le tableau suivant.
| norme | Bande passante maximale | bande passante par ligne / canal |
Définition maximale supportée |
|---|---|---|---|
| DisplayPort 1.2 | 21,6 Gbps | 5,4 Gbps | 4K @60 Hz |
| DisplayPort 1.3 | 32.4 Gbps | 8,1 Gbps |
8K @ 60 Hz 4K @ 120 Hz |
| DisplayPort 1.4a | 32.4 Gbps | 8,1 Gbps |
8K @ 60 Hz + HDR* 4K @ 240 Hz + HDR* |
| DisplayPort 2.0 | 80 Gbps | 20 Gbps |
16K @ 60 Hz + HDR* 10K @60 Hz + HDR* |
| HDMI 1.4 | 10,2 Gbps | 3,4 Gbps | 4K @ 30 Hz |
| HDMI 2.0b | 18 Gbps | 6 Gbps |
4K @ 60 Hz 8K @ 30 Hz* |
| HDMI 2.1 | 48 Gbps | 12 Gbps |
4K @ 240 Hz + HDR* 8K @ 60 Hz + HDR* |
| * nécessite DSC 1.2a ou format de couleur 6-bit (4:2:0) | |||

Vous pouvez aussi vous rendre sur notre recap de référence avec plein de chiffres
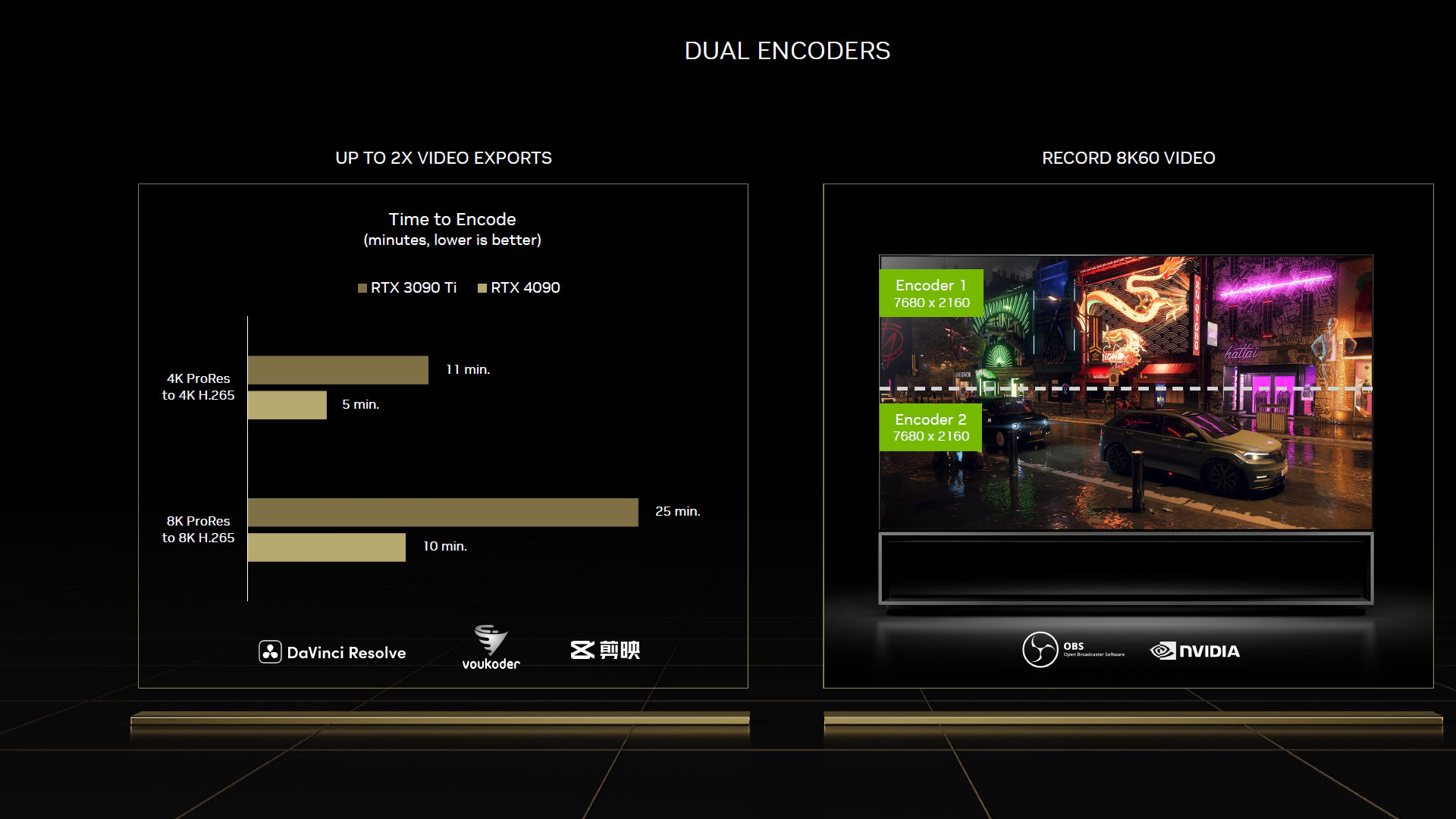
Passons à présent au moteur vidéo. Sur le front du décodage, Nvidia conserve ici la cinquième itération de son NVDEC, introduite avec Ampere et qui apportait le support plus que bienvenu de l'AV1. Ce codec ouvert sans royalties à payer, permet de meilleurs taux de compression ou de qualité d'image que les H.264 et HEVC / VP9. La contrepartie est une décompression très gourmande, pouvant mettre à genoux de nombreux processeurs en haute définition. Le décodage par le GPU permet de réduire à minima le taux d'usage du processeur central. Côté encodage, il y a cette fois du neuf à se mettre sous la dent, avec un NVENC qui passe à la génération 8 et assure l'accélération matérielle pour l'encodage AV1. Mais comme cela ne suffisait pas au caméléon, il a décidé d'en coller 2 au sein de la puce, de quoi réduire drastiquement les temps d'encodage, lorsque les logiciels seront en capacité de tirer partie de cette spécificité. Enfin, Nvidia affirme que son encodeur AV1 est 40 % plus efficient que celui H.264. Puisqu'un dessin vaut mieux qu'un long discours, voici un petit exemple fourni par le caméléon.
![Dual Encoder [cliquer pour agrandir]](/images/stories/articles/gpu/ada_lovelace/dual_encoder_t.jpg "Visionner en grand sur un magnifique pop-up")
Un petit mot sur l'interface de raccordement au PC : alors que l'on pouvait s'attendre à une interconnexion en PCIe Gen 5, vu l'émergence des plateformes à cette norme depuis 1 an, il n'en est rien. Que l'on soit clair, à l'instar du DP 2.0, c'est loin d'être un problème, car d'ici à ce que les GPU saturent l'interface PCIe 4.0 x16, il va se passer encore un bon bout de temps. Est-ce un choix délibéré afin d'économiser des transistors, du budget puissance ou une finalisation du design préalable à la démocratisation de l'interface ? Quoi qu'il en soit, si cela n'impacte en rien les performances, l'utilisateur qui paie une petite fortune pour sa carte graphique, aime bien avoir les toutes dernières normes, ce ne sera pas le cas ici, même si c'est plus une question d'ordre psychologique qu'autre chose dans le cas présent. Voyons d'autres fonctionnalités annoncées par le caméléon lors de ce lancement, page suivante.
|
|
| Un poil avant ?La relève NUC Extreme chez Intel sera encore moins mini-PC-esque qu'avant | Un peu plus tard ...L'Unreal Engine 5.1 plus très loin de débarquer | |