Test • NVIDIA GeFORCE GTX 1650 |
————— 06 Mai 2019



Test • NVIDIA GeFORCE GTX 1650 |
————— 06 Mai 2019
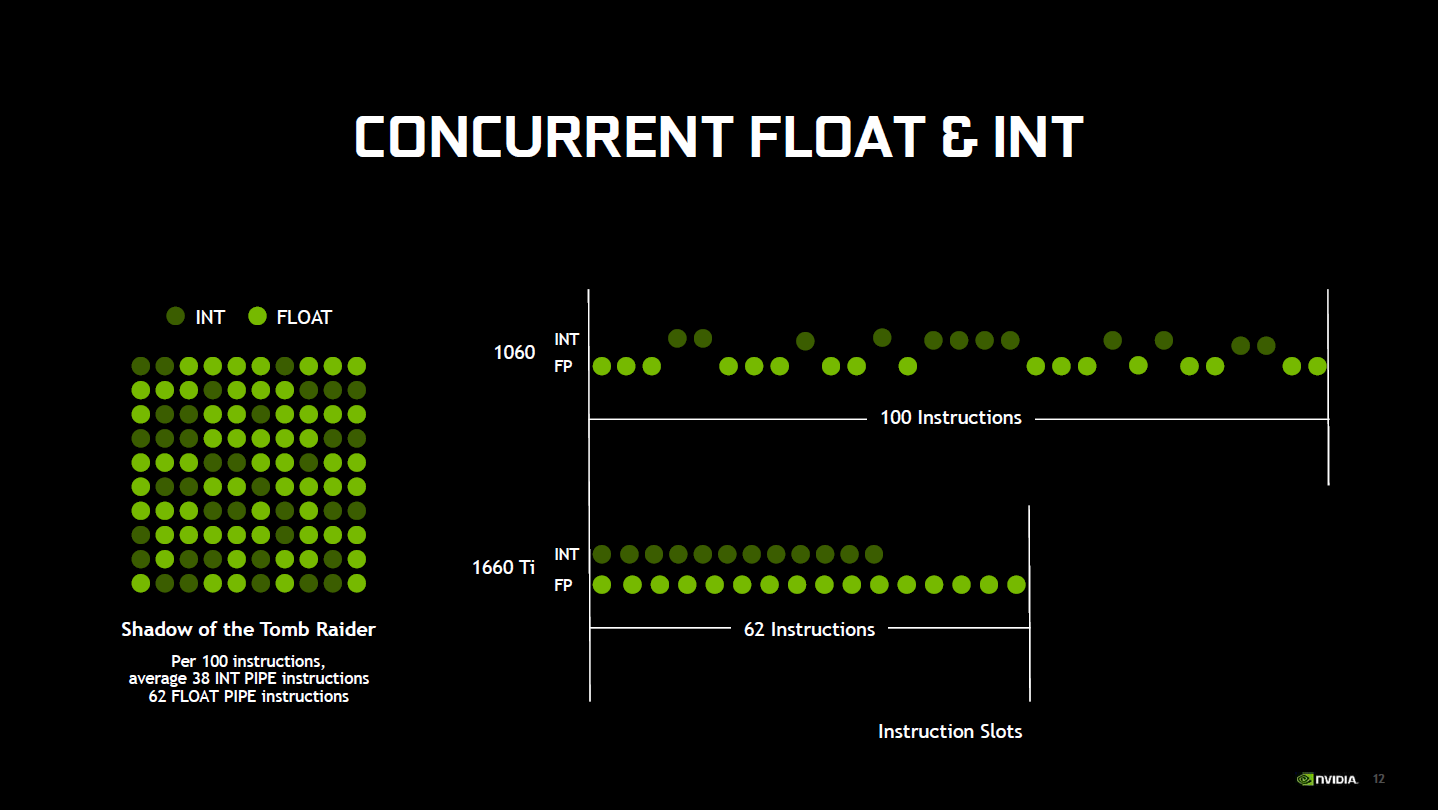
Pour ceux intéressés par l'architecture Turing, nous vous invitons à lire ou relire le dossier que nous lui avons consacré il y a quelque temps. Résumée en quelques lignes, cette dernière ressemble beaucoup à Volta avec quelques ajouts. Par rapport à Pascal (gaming) : des caches plus gros et plus rapides, des SM "plus petits" mais plus nombreux et capables de traiter en parallèle les calculs sur entiers ou en virgule flottante (y compris en demi-précision (FP16) à double vitesse).
![Exécution concomitante flottants et entiers [cliquer pour agrandir]](/images/stories/articles/gpu/turing/gtx_1650/concurrent_int_fp_t.png "Ultra bouzotron HD max def")
Voilà pour la partie "classique" de l'architecture, NVIDIA a complété cette dernière par des Tensor Cores, accélérant significativement les calculs liés à l'intelligence artificielle, en particulier l'inférence, ainsi que les RT Cores, dédiés à l'accélération matérielle (des calculs d'intersection rayons / triangles) du Ray Tracing, utilisable en temps réel dans les jeux via un rendu hybride, mixant cette technique à une base rastérisation.
![Turing en chiffres [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/turing_t.jpg "Si vous cliquez, vous cliquez.")
Turing en chiffres dans sa déclinaison dédiée à la RTX 2080 Ti
Mais ces nouvelles fonctionnalités sont loin d'être gratuites en termes de "coût transistors", avec pour conséquence des dies pour le moins imposants et donc onéreux à produire, du fait d'un nombre réduit de ces derniers par Wafer (disques en silicium sur lesquels sont gravés les puces). Mais ça, c'était avant, puisque les deux plus petits GPU Turing s'affranchissent des RT et Tensors Cores, afin d'atteindre un coût de production plus adapté au marché visé.
NVIDIA a donc conçu à partir de sa dernière architecture, un cinquième GPU nommé TU117, qui se retrouve au sein des GTX 1650, le préfixe rappellant l'absence des nouvelles fonctionnalités. Le die de TU117 mesure 200 mm², à mettre en perspective des 132 mm² de GP107 équipant les GTX 1050 (Ti). Cette augmentation sensible l'amène au niveau de la précédente série 6, GP106 prenant peu ou prou la même surface. Le procédé de fabrication évolue toutefois, le 12 nm FFN à nouveau utilisé pour une puce Turing, est personnalisé pour les verts (FFN = FinFET NVIDIA) par TSMC : il s'agit en fait d'une optimisation du "16 nm FinFET Plus" existant. Les gains ne sont pas à chercher du côté de la densité de gravure (qui régresse même par rapport au 14 nm LPP de Samsung utilisé pour GP107), mais de la performance des transistors, afin de rester dans une enveloppe thermique "gérable", malgré l'explosion de leur nombre. Vous retrouverez ci-dessous un résumé des différents GPU utilisés sur les GeForce série 10, 16 et 20.
| Cartes | GPU | Nombre de transistors | Superficie Die |
Densité (Millions de transistors / mm²) | Procédé de fabrication |
|---|---|---|---|---|---|
| GeForce RTX 2080 Ti | TU102 | 18,6 Milliards | 754 mm² | 24,7 | TSMC 12 nm FFN |
| GeForce RTX 2080 | TU104 | 13,6 Milliards | 545 mm² | 24,9 | TSMC 12 nm FFN |
| GeForce RTX 2070/60 | TU106 | 10,8 Milliards | 445 mm² | 24,3 | TSMC 12 nm FFN |
| GeForce GTX 1660 (Ti) | TU116 | 6,6 Milliards | 286 mm² | 23,1 | TSMC 12 nm FFN |
| GeForce GTX 1650 | TU117 | 4,7 Milliards | 200 mm² | 23,5 | TSMC 12 nm FFN |
| GeForce GTX 1080 Ti | GP102 | 12 Milliards | 471 mm² | 25,5 | TSMC 16 nm FF+ |
| GeForce GTX 1080/70 (Ti) | GP104 | 7,2 Milliards | 314 mm² | 22,9 | TSMC 16 nm FF+ |
| GeForce GTX 1060 | GP106 | 4,4 Milliards | 200 mm² | 22 | TSMC 16 nm FF+ |
| GeForce GTX 1050 (Ti) | GP107 | 3,3 Milliards | 132 mm² | 25 | Samsung 14 nm LPP |
TU117 s'appuie sur 2 GPC, réduisant d'autant les unités de rastérisation. Il reprend la configuration de ceux utilisés par TU102/116, c'est à dire incluant 4 TPC / 8 SM. L'interface mémoire est réduite d'un tiers par rapport à son grand frère, puisque le caméléon utilise un bus mémoire 128-bit via 4 contrôleurs 32-bit, qui prennent place au sein du die. Enfin, la réduction est du même ordre pour les éléments liés, c'est-à-dire les ROP (par partition de 8) et le cache L2, pour des valeurs respectives de 32 et 2 Mo. Le caméléon ne nous ayant pas fourni de diagramme pour TU117, nous avons modifié celui de TU116, les parties blanches correspondant aux "coupes" effectuées pour créer ce nouveau GPU par rapport au modèle supérieur.
![diagram tu117 [cliquer pour agrandir]](/images/stories/articles/gpu/turing/gtx_1650/diagram_tu117_t.jpg "La magie de la loupe, sans loupe")
Le GPU utilisé sur les GeForce GTX 1650 desktop est par contre incomplet, ce qui signifie que le caméléon désactive certains blocs/unités pour faciliter la production. Cela laisse donc la place à une hypothétique version Ti, si d'aventure le caméléon jugeait cette option pertinente. Voici résumées les principales caractéristiques de son GPU dans le tableau ci-dessous et les désactivations opérées.
| GeForce GTX 1660 | Quantité activée | Quantité Présente |
|---|---|---|
| GPC | 2 | 2 |
| TPC / SM | 7 / 14 | 8 / 16 |
| CUDA Cores | 896 | 1024 |
| TMU | 56 | 64 |
| Tensor Cores | - | - |
| RT Cores | - | - |
| ROP | 32 | 32 |
| L2 (Mo) | 2 | 2 |
| Bus mémoire (bits) | 128 | 128 |
A noter également que si le moteur d’affichage vidéo est inchangé par rapport aux précédentes puces Turing, il n'en est pas de même pour les encodeurs intégrés, puisque ils se "contentent" des fonctionnalités et performances de la génération VOLTA, avec pour principale différence, la non prise en charge du HEVC B Frame. Vous retrouverez résumées ici les différentes capacités selon les GPU. Finissons cette page par un dernier rappel, celui concernant le grand ordonnanceur des fréquences GPU des GeForce, à savoir GPU Boost dans sa quatrième itération, étrennée avec ces nouvelles générations de cartes, du moins les RTX.
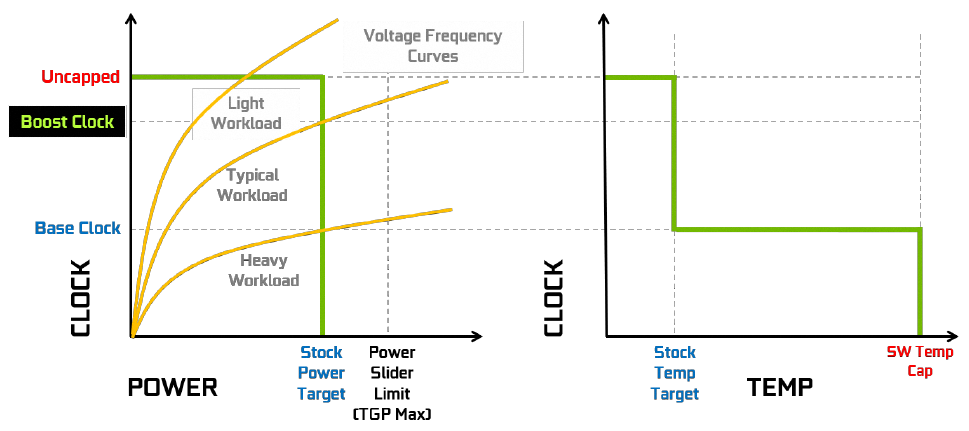
Ce mécanisme a pour objectif de pousser chaque puce au plus près de ses limites, en s'affranchissant de tests trop sélectifs en sortie de production. C'est en effet GPU Boost qui est chargé par la suite, de s'assurer que les conditions environnementales permettent au GPU de fonctionner de manière stable et sans risque. Pour ce faire, il impose un double carcan constitué d'une limite de consommation et de température selon l'itération. Avec la version 3 introduite lors du lancement de Pascal, à partir de 37°C et tous les 5°C supplémentaires, le GPU perd 1 bin (~13 MHz) et ce jusqu'à la consigne de température maximale. Il perd alors autant de bins que nécessaire pour rester sous celle-ci.
La fréquence progressant de concert avec la tension d'alimentation du GPU, c'est un moyen très efficace pour contrôler la consommation (qui évolue au carré de la tension et dispose aussi de sa propre limite), évitant ainsi une envolée des nuisances sonores, avec un refroidisseur pas forcément dimensionné pour la dissiper discrètement à fréquence maximale durant une charge soutenue, ce qui est le cas des Founders Edition à turbine. Le souci d'une telle approche, est la pénalisation de toutes les cartes Pascal, y compris les customs des constructeurs tiers, avec des refroidisseurs surdimensionnés. En effet, NVIDIA autorise la modification du TDP max. des cartes, mais en aucun cas des paliers de température par défaut de GPU Boost 3.0. Ci-dessous une représentation graphique de ce fonctionnement.
![GPU Boost 3.0 [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/gpuboost3_t.png "Cliquédélique !")
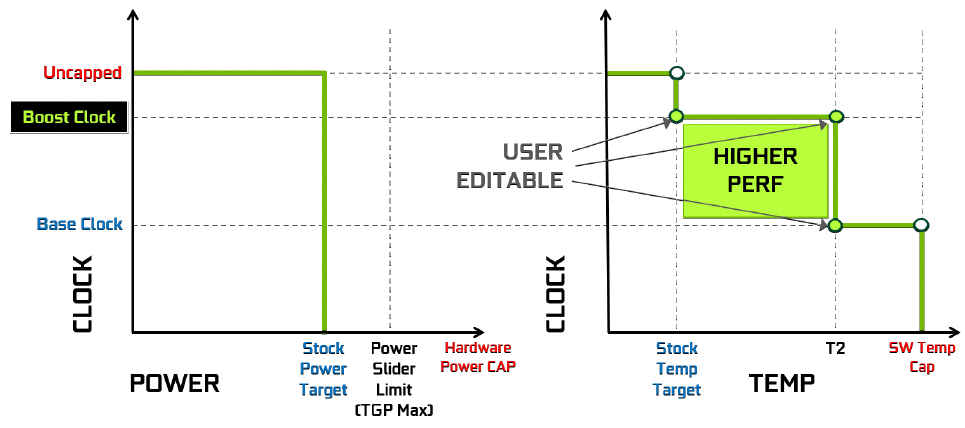
Avec Turing version RTX, NVIDIA a annoncé GPU Boost 4.0. En gros, ce dernier fonctionnerait de manière similaire, mais avec un ajustement qui fait toute la différence. En effet, les valeurs de températures sont à présent exposées, il est donc possible de les modifier. Bien sûr, il est nécessaire de rester dans la plage autorisée par le caméléon, mais le seuil à 37°C qui marquait le "début de la baisse" des fréquences, n'est plus imposé. Cela coïncide avec l’utilisation d'un refroidisseur plus performant sur les Founders Edition, qui ne perdent donc plus de fréquence du fait de la température. Toujours est-il, qu'il était très difficile de s'approcher du TDP max sur ces dernières en version Pascal, à part lors des premiers instants de forte sollicitation. Ce ne sera plus le cas avec les versions Turing RTX, qui seront davantage limitées par leur enveloppe thermique. Ci-dessous, la représentation schématique de GPU Boost 4.0. Notons également qu'un bin, prend à présent la valeur de 15 MHz, contre 13 MHz auparavant.
![GPU Boost 4.0 [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/gpuboost4_t.png "Enlarge your pe...icture")
Nous avons précisé RTX car il semble bien que la série 16 ne soit pas gouvernée par la dernière itération de GPU Boost, mais bien la précédente ou plutôt un mix des deux, plus de détails à ce sujet page 14. Voilà pour les rappels, passons page suivante à la description de la carte de test que nous avons reçue.
|
|
| Un poil avant ?Dans la série à ne pas faire : le SSD RGB ft. HyperX | Un peu plus tard ...Un système de mise à jour plus léger à venir sur Windows | |