Génération Ampère chez les verts : le point architectural |
————— 05 Septembre 2020 à 18h33 —— 42240 vues



Génération Ampère chez les verts : le point architectural |
————— 05 Septembre 2020 à 18h33 —— 42240 vues
Alors qu’Ampère est sujette à toutes les rumeurs concernant ses performances — prétendre doubler les prestations de la génération précédente, ce n’est pas anodin — NVIDIA ne pouvait décemment pas rester silencieux à propos des entrailles de sa machine. Quelles sont les améliorations effectuées ? Le comptoir déchiffre tout pour vous.
![]()
Pour faire un GPU, peu de choses sont nécessaires : prenez des cœurs très simples (nommés Cuda Cores par les verts depuis Fermi), capables d’effectuer les opérations arithmétiques de base (nombre entier et précision flottante), et agencez-en le plus possible tant qu’il reste de la place sur votre die. C’est ce qui est utilisé pour la rastérisation, méthode de rendu 3D ultra dominant dans les jeux vidéo, car bien plus rapide à exécuter que le Ray Tracing. Bien entendu il ne sagit ici que de la partie "calcul", puisque s'ajoutent les unités géométriques (génération des primitives, tesselation), de rastérisation (décomposition des triangles en pixels), de texturing et de rendu (ROP) et tout le sous-système mémoire.
Mais revenons aux différences fondamentales apportée par Ampère, au niveau des cœurs organisés en Stream Multiprocessor (SM) qui évolue légèrement par rapport à Turing. Nous retrouvons toujours un module RT Core sur lequel nous reviendrons plus tard, ainsi qu’un chemin de données dédié aux calculs flottants (FP32), et un second qui passe des entiers uniquement (INT32) sur Turing, à une compatibilité hybride (FP32 ou INT32) avec Ampere. Il en résulte un facteur 2 de la puissance en FP32 par SM en comparaison de la génération précédente, mais uniquement lorsqu'il n'est pas nécessaire de fournir un calcul sur entier. Pour accompagner cette augmentation de puissance, le cache L1 double sa bande passante et sa capacité passe de 96 ko à 128 ko par SM.
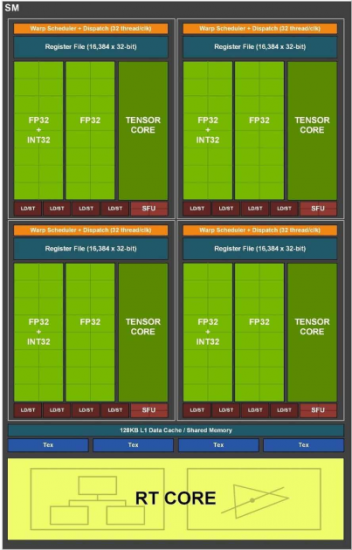
Les Tensor Cores évoluent également : on passe de 8 à 4 par SM, mais comme causé sur notre brève dédiée à la NVDIA A100, ces derniers gèrent en matériel les matrices creuses. Derrière ce nom barbare se cachent des structures de données présentant un nombre important de zéros, ce qui autorise une compression notable à la fois en matière d’espace, mais également de rapidité d’exécution. En effet, les calculs entre zéros ne sont tout bonnement pas effectués, ce qui permet aux verts d’afficher des puissances de calculs toujours plus démentielles.
Fort de ces changements, les verts annoncent pouvoir appliquer la technologie DLSS de manière toujours plus performante. Qu’est-ce que cela signifie ? Hé bien, pour pouvoir jouer en 8K, le DLSS serait (une nouvelle fois) appelé à la rescousse, dans des proportions toujours plus impressionnantes. Voyez donc :
| DéFinition d'affichage | Définition de rendu |
|---|---|
| FullHD (1920x1080 px) | HD (1280x720 px) |
| QHD (2560x1440 px) | Jensen's Favorite (1706x960 px) |
| UHD (3840x2160 px) | FullHD (1920x1080 px) |
| 8K (7680x4320 px) | quasi-QHD (2560x1400 px) |
Oui, vous avez bien lu : l’IA devrait permettre de multiplier par 9 le nombre total de pixels affiché tout en évitant le classique flou de la mise à l’échelle habituelle. Techniquement, rien n’est impossible au vu du matériel embarqué, particulièrement sur les rendus typés cartoon où le cell shading gomme une partie des détails... reste à voir le ressenti des joueurs aguerris.
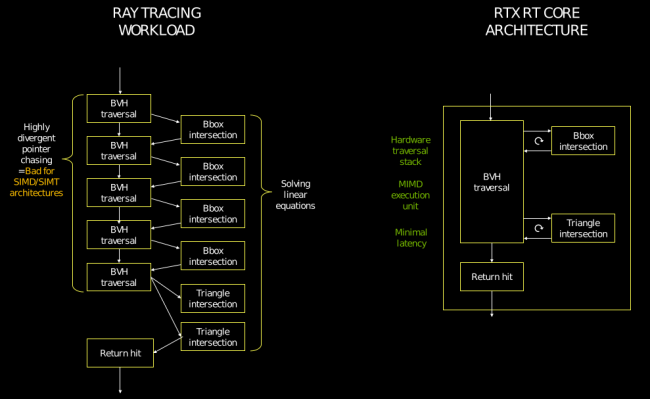
Passons désormais à notre raie préférée : Ampère utilise des RT cores de seconde génération, dont la principale nouveauté — outre un débit maximal doublé — réside dans la gestion matérielle du flou cinétique, qui fait l’objet de notre paragraphe suivant. Mais, avant cela, les verts ont (enfin !) été davantage loquaces sur l’organisation interne de leurs RT Cores : il était temps ! Le principal souci du BVH — l’algorithme accéléré par ces cœurs dédiés, permettant de calculer quel volume rentre en intersection avec un rayon — réside dans le pointer chasing, c’est-à-dire l’obligation du programme de sauter d’une zone mémoire à une autre sans ordre logique, ce que détestent particulièrement les organisations en SIMD/SIMT des GPU modernes. Le principe est très proche des SSD, où la lecture/écriture séquentielle est très rapide grâce au prefetching, mais les opérations en lecture/écriture aléatoires sont bien plus lentes. Du coup, les RT Cores intègrent, sur Turing, trois composants logiques : le premier effectue la traversée de l’arbre contenant la hiérarchie des volumes possiblement frappés par le rayon, le second se charge de trouver si une telle intersection à lieu sur le volume, et le dernier calcule le triangle touché.
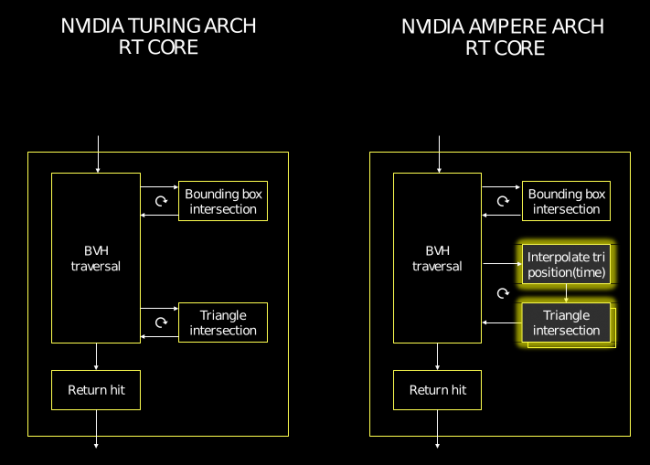
Et ce flou cinétique alors, qu’est-ce exactement ? Beaucoup de jargon pour peu de choses, finalement, car il est question d’un module supplémentaire retenant la position de rayon lancé antérieurement afin de réutiliser leur valeur dans le rendu courant. Ainsi, les objets en mouvement rapide se verront moins nets, renforçant la sensation de vitesse et de fluidité. Ce mécanisme permet ainsi de se passer de coûteux effet de post-processing après rendu, ce qui devrait améliorer les performances dans les titres au gameplay nerveux en faisant usage.
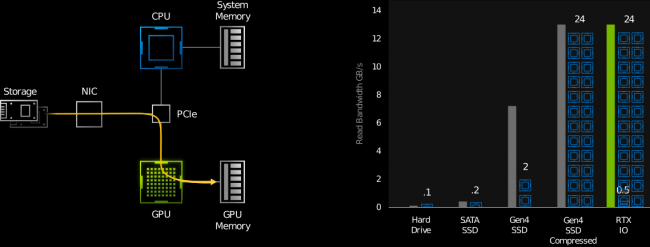
De plus, NVIDIA a rajouté dans ses cartes la technologie RTX IO. L’idée est ici de réduire les latences lors des temps de chargement en donnant directement un accès disque à la carte graphique, afin d’éviter les goulots d’étranglement liés à un CPU encombré. Cela se justifie d’autant plus par la taille toujours croissante des titres, qui dépassent désormais couramment la centaine de Go ; reste à voir si le GPU est capable de gérer correctement les algorithmes de décompression sans gêner les potentiels rendus effectués en parallèle.
Désormais que tous les termes sont clairs, voici, pour rappel, la gamme Ampère gaming telle qu’annoncée par Jensen :
| Nom | Cœurs CUDA | SM | GPC | VRAM |
|---|---|---|---|---|
| GeForce RTX 3070 | 5888 | 46 | 4 | 8 Go GDDR6 |
| GeForce RTX 3080 | 8704 | 68 | 6 | 10 Go GDDR6X |
| GeForce RTX 3090 | 10496 | 82 | 8 (?) | 24 Go GDDR6X |
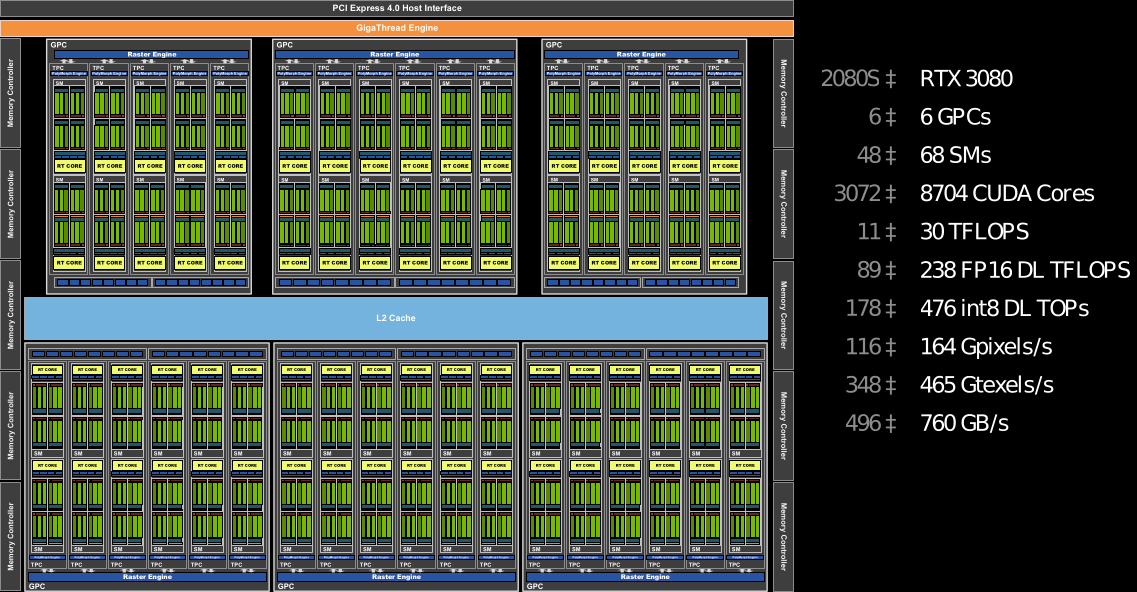
Ainsi, partant de deux de leur brique de base SM, NVIDIA assemble des Texture Processing Cluster (TPC), qui partagent leur PolyMorph Engine, un composant gérant diverses transformations. Ensuite, ces TPC sont regroupés en Graphic Processing Cluster à raison de 6 (donc 12 SM) par GPC. Il est toutefois possible de désactiver en leur sein un ou plusieurs TPC, afin de recycler des dies partiellement défectueux. Notez que ces GPC sont reliés chacun à leur propre unité de rastérisation, le tout étant coordonné par un GigaThread Engine... sans compter le L2, adressé par GPC ainsi que 2 partitions (8) de ROPs associé à ce dernier et enfin la connexion PCIe 4.0 avec le contrôleur hôte. Tout ceci donne un monstre de 28 milliards de transistors organisé ainsi sur la RTX 3080 :
![ampere archi rtx 3080 t [cliquer pour agrandir]](/images/stories/_cg/ampere/ampere-archi-rtx-3080_t.png "Ultra bouzotron HD max def")
Le diagramme logique du GA102 sauce RTX 3080 !
Dernier point sur lequel Nvidia insiste lors de sa description de son architecture, c'est l'amélioration des capacités d'exécution concomitante. En effet, il était possible avec Turing d'exécuter de manière simultanée des calculs mixant les unités de calcul traditionnel (en jaune ci-dessous) avec les RT Core (en vert) par exemple, mais on ne pouvait pas y superposer l'usage des Tensor Cores (violet). Ampere permet à présent de combler cette lacune, autorisant des gains supplémentaires lors du rendu d'une image, utilisant par exemple RT et DLSS. Nvidia indique par exemple que sous Wolfenstein Youngblood, la RTX 3080 avec Ray Tracing actif couplé au DLSS, obtiendrait un framerate 1,8x plus élevé qu'une GTX 1080 Ti en rastérisation uniquement...
![Traitement concomitant [cliquer pour agrandir]](/images/stories/_cg/ampere/async_t.png "Visionner en grand sur un magnifique pop-up")
Temps d'éxécution du rendu d'une image Pascal vsTuring vs Ampere
En conclusion, Ampère ne révolutionne certes pas le domaine des microarchitectures GPU, puisqu'il s'agit principalement d'une évolution de Turing (comme l'était Pascal vis-à-vis de Maxwell), mais elle résume tout à fait les objectifs des firmes dans ce domaine : partir d’un processus de gravure plus efficient permettant de caser directement plus de cœurs, et jongler avec les différentes possibilités de design afin de rendre ces derniers plus performants sans payer un coût déraisonnable en surface. Saupoudrez le tout de nouvelle technologie sauce raie tracée, et voilà un cocktail détonnant pour les fêtes de fin d’année. Avis aux gameurs ?
| Un poil avant ?1ère vague de RTX 30x0 : pour GIGABYTE aussi, le changement c'est maintenant | Un peu plus tard ...Gamotron • De la bonne petite sortie | |