Test • AMD Radeon RX 7900 XT & RX 7900 XTX |
————— 12 Décembre 2022



Test • AMD Radeon RX 7900 XT & RX 7900 XTX |
————— 12 Décembre 2022
Navi 31 est donc le premier GPU à étrenner l'architecture RDNA3. Outre les spécificités liées à l'architecture en elle-même, son point le plus marquant est bien évidemment son design en chiplet, comme détaillé page précédente. D'un point de vue taille, Navi 21 mesurait 519,8 mm², en étant gravé par TSMC à l'aide de son process 7 nm. C'était donc un beau bébé, mais Navi 31 n'a rien a lui envier en termes de superficie, puisque le cumul des différents chiplets, conduit à une valeur similaire de 522 mm².
![navi 31 [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/navi31_t.jpg "Cliquédélique !") Navi 31 et ses 7 chiplets le composant
Navi 31 et ses 7 chiplets le composant
Au lieu d'une puce monolithique, AMD procède ici à l'assemblage de pas moins de 7 dies différents, regroupés au sein d'un seul et même packaging. Cela donne à la puce un petit air de Fiji et Vega, sauf qu'il ne s'agit pas ici de piles HBM entourant un GPU traditionnel via un interposer. Au centre, le Graphics Compute Die regroupe toutes les fonctionnalités classiques d'un GPU, hormis le cache L3 et les contrôleurs mémoires. Le die de ce GCD nécessite une superficie de 300 mm² sur les Wafers du très performant procédé 5 nm de TSMC.
![Les deux types de chiplets [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/chiplet_t.jpg "3N C11QU4N7 C357 P1U5 6r4ND")
Autour, se trouvent les Memory Cache Dies, qui incluent les éléments absents du GCD, et qui utilisent pour leur part le procédé 6 nm de TSMC. Ne vous laissez pas abuser par la proximité de ces dénominations, il s'agit de deux nœuds de gravure bien distincts, ce dernier étant une optimisation du 7 nm, moins performant et onéreux que le 5 nm. La taille réduite de ces MCD facilite grandement leur production, davantage pouvant être gravés au sein d'un même Wafer, tout en étant moins sensibles aux imperfections de gravure, du fait de leur superficie unitaire.
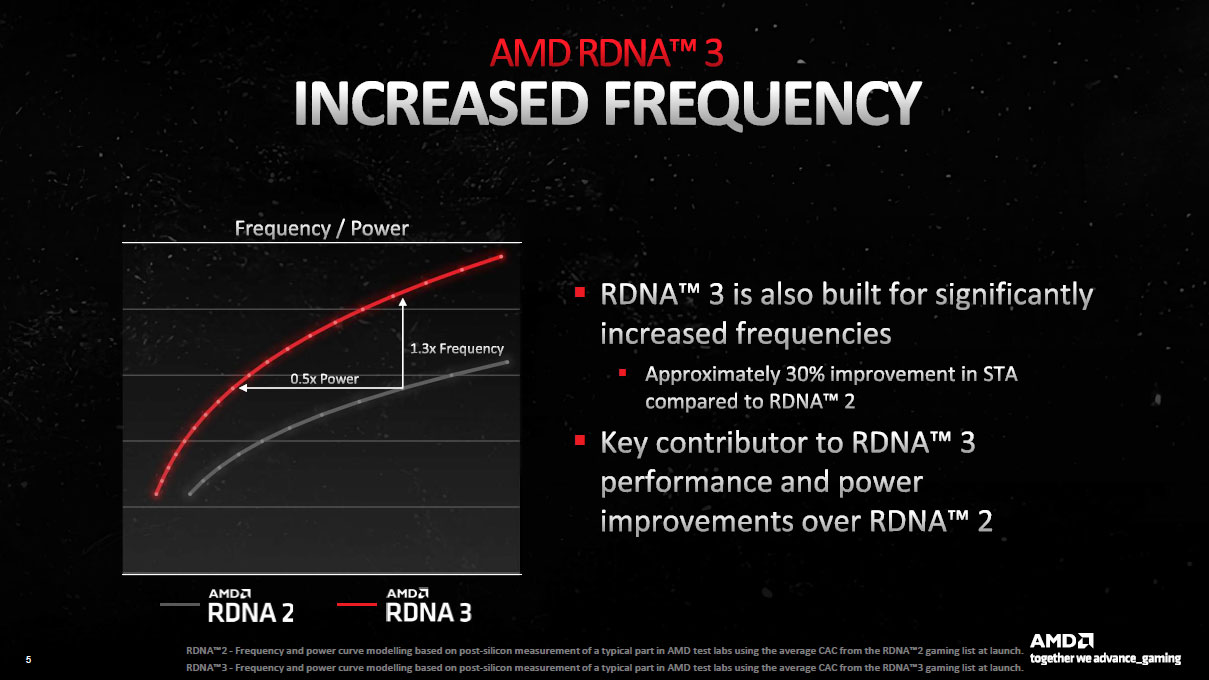
![Des fréquences découplées [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/frequences_t.jpg "Enlarge your pe...icture")
AMD indique également avoir particulièrement travaillé la montée en fréquence de son architecture, prévue pour des pointes à plus de 3 GHz, mais pas que. Ainsi, il est possible de découpler la partie shader (comprenant les unités de calculs) du reste du GPU. Techniquement, cela permet d'ajuster quelque peu à la baisse cette dernière, qui est de loin la plus grande consommatrice d'énergie, tout en conservant des fréquences plus élevées là où l'impact sur la consommation est moindre. Il ne s'agit donc pas ici de compenser une relative faiblesse de montée en fréquence de son GPU, mais bien de contrôler plus finement son efficience. AMD indique qu'il est possible avec RDNA3, d'atteindre davantage de fréquence pour la même puissance, (ou la même fréquence pour une puissance bien moindre) : il s'agit ici clairement des gains inhérents au progrès du procédé de fabrication, plus qu'une spécificité architecturale.
![Le travail sur les fréquences [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_frequences_t.jpg "3N C11QU4N7 C357 P1U5 6r4ND")
Si concernant la performance des transistors de chaque procédé de gravure, on ne peut que se baser sur les dires des fondeurs, rendant difficile toute comparaison objective entre eux, pour la densité, les informations d'AMD et Nvidia permettent de réaliser des ratios entre GPU. Même si cet élément n'a pas grande importance pour le client final, il permet de se faire une petite idée des coûts de production.
| Gravure | GPU | Nombre de transistors | Superficie Die |
Densité (Millions de transistors / mm²) |
|---|---|---|---|---|
| 4 nm TSMC | AD102 | 76,3 Milliards | 608,5 mm² | 125,4 |
| 4 nm TSMC | AD104 | 35,8 Milliards | 294,5 mm² | 121,6 |
| 4 nm TSMC | AD103 | 45,9 Milliards | 378,6 mm² | 121,2 |
| 5 nm + 6 nm TSMC | Navi 31 | 57,7 Milliards | 522 mm² | 110,5 |
| 7 nm TSMC | GA100 | 54.2 Milliards | 826 mm² | 65,6 |
| 6 nm TSMC | ACM-G10 | 21,7 Milliards | 406 mm² | 53,4 |
| 7 nm TSMC | Navi 21 | 26,8 Milliards | 520 mm² | 51,6 |
| 7 nm TSMC | Navi 22 | 17,2 Milliards | 335 mm² | 51,3 |
| 7 nm TSMC | Navi 23 | 11,1 Milliards | 237 mm² | 46,8 |
| 6 nm TSMC | ACM-G11 | 7,2 Milliards | 157 mm² | 45,9 |
| 8 nm Samsung | GA102 | 28,3 Milliards | 628,4 mm² | 45 |
| 8 nm Samsung | GA104 | 17,4 Milliards | 392 mm² | 44,4 |
| 8 nm Samsung | GA106 | 12 Milliards | 276 mm² | 43,5 |
| 7 nm TSMC | Navi 10 | 10,3 Milliards | 251 mm² | 41 |
| 7 nm TSMC | Vega 20 | 13.2 Milliards | 331 mm² | 39,9 |
| 16 nm TSMC | GP102 | 12 Milliards | 471 mm² | 25,5 |
| 14 nm GF | Vega 10 | 12.5 Milliards | 495 mm² | 25,3 |
| 16 nm TSMC | GP100 | 15,3 Milliards | 610 mm² | 25,1 |
| 12 nm TSMC | TU104 | 13,6 Milliards | 545 mm² | 25 |
| 12 nm TSMC | TU102 | 18,6 Milliards | 754 mm² | 24,7 |
| 12 nm TSMC | TU106 | 10,8 Milliards | 445 mm² | 24,3 |
D'après les chiffres communiqués, la densité de Navi 31 est plus que doublée par rapport à Navi 21. C'est d'autant plus remarquable, que "seuls" 57% du total profite in fine du nouveau nœud de gravure à 5 nm, le reste utilisant une optimisation du 7 nm, apportant des gains bien plus limités en matière de densité. Nvidia utilise de son côté un design monolithique gravé en 4 nm (personnalisation du 5 nm), qui doit lui coûter bien plus cher pour AD102, sa propre puce haut de gamme de plus de 600 mm². C'est par contre bien moins vrai concernant AD103 utilisé sur la RTX 4080, du fait d'une surface finalement pas si éloignée (+26%), de celle du seul GCD de Navi 31.
Deux cartes graphiques sont pour l'heure déclinées depuis ce GPU. Elles diffèrent selon le niveau d'activation des unités, mais aussi les MCD fonctionnels, permettant donc de segmenter l'offre tout en réduisant les coûts de production, en recyclant des puces "imparfaites" ou même défectueuses concernant le MCD.
| NAVI 31 | RX 7900 XTX | RX 7900 XT |
|---|---|---|
| Shader Engine | 6 | 5 |
| CU | 96 / 96 | 84 / 96 |
| SP | 6144 | 5376 |
| TMU | 384 | 336 |
| Ray Accelerator | 96 | 84 |
| ROP | 192 | 192 |
| Cache L2 (Mo) | 6 | 6 |
| Cache L3 (Mo) | 96 | 80 |
| Bus mémoire (bits) | 384 | 320 |
Ainsi, la RX 7900 XTX utilise la version intégrale de Navi 31, c'est-à-dire constituée du GCD totalement activé, couplé à 6 MCD fonctionnels. À noter que même dans ce cas, le cache L3 est en régression d'un quart par rapport à Navi 21, probablement une nécessité pour maintenir des MCD les plus petits (et rentables) possibles. La RX 7900 XT voit de son côté un Shader Engine désactivé et utilise un MCD défectueux (ou un substitut de silicium non gravé) pour maintenir l'équilibre physique de l'ensemble. Cela a pour conséquence la désactivation de 2 contrôleurs mémoire 32-bit, ainsi que 16 Mo de cache L3. L'écart séparant les 2 cartes devrait donc être plus marqué qu'il ne l'était entre 6800 XT et 6900 XT, qui partageaient le même sous-système mémoire. Tout cela permet d'afficher de gros chiffres, pain béni pour le marketing, nous verrons si c'est suivi d'effet en matière de performances dans quelques pages.
![navi 31 chiffres clé [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/navi31_chiffres_t.jpg "3N C11QU4N7 C357 P1U5 6r4ND")
S'il y a un point sur lequel AMD a particulièrement insisté lors de l'annonce de ses cartes, c'est bien sur le moteur d'affichage qui prend en charge la norme DisplayPort 2.1. À un point que les performances étaient presque reléguées au second plan. Un aveu implicite de faiblesse de ces dernières ? Quoi qu'il en soit, c'est une très bonne nouvelle que les rouges aient décidé d'adopter cette norme DP 2.1, la décision des verts de ne pas le faire (ne serait-ce que le 2.0 à l'instar des Intel ARC) reste incompréhensible, pour des cartes censées être au sommet de la technologie. Alors bien sûr, le DP 1.4 est parfaitement suffisant pour permettre des affichages en haute définition et fréquences de rafraîchissement confortables avec le complément du DSC, proposant une compression sans perte, mais cela fait toute de même pingre pour des cartes à ce tarif. Nous saluons donc les décisions d'Intel et AMD de les incorporer à leur GPU 2022.
![Un moteur vidéo dernier cri [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/moteur_video_t.jpg "Enlarge your pe...icture")
Finissons avec le Media Engine, qui lui aussi progresse de manière significative. Si la génération précédente avait apporté le décodage AV1, c'est l'encodage de ce codec qui est à présent assuré par Navi 31, rejoignant ainsi les puces Ada Lovelace et Arc Alchemist. AMD précise également que la fréquence de son moteur vidéo a été augmentée de 80 %, de quoi lui permettre de traiter simultanément décodage et encodage des flux H.264/H.265.
![Un moteur de décodage/encodage au goût du jour [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/media_engine_t.jpg "Si vous cliquez, vous cliquez.")
Voilà pour le GPU du jour, il est temps de passer page suivante, aux cartes l'utilisant.
|
|
| Un poil avant ?Combien de RX 7900 sur les étalages pour finir 2022 ? | Un peu plus tard ...Ventes de jeux vidéo : la fameuse nain-posture | |