Test • GeForce GTX 1650 SUPER vs Radeon RX 5500 XT |
————— 24 Décembre 2019



Test • GeForce GTX 1650 SUPER vs Radeon RX 5500 XT |
————— 24 Décembre 2019
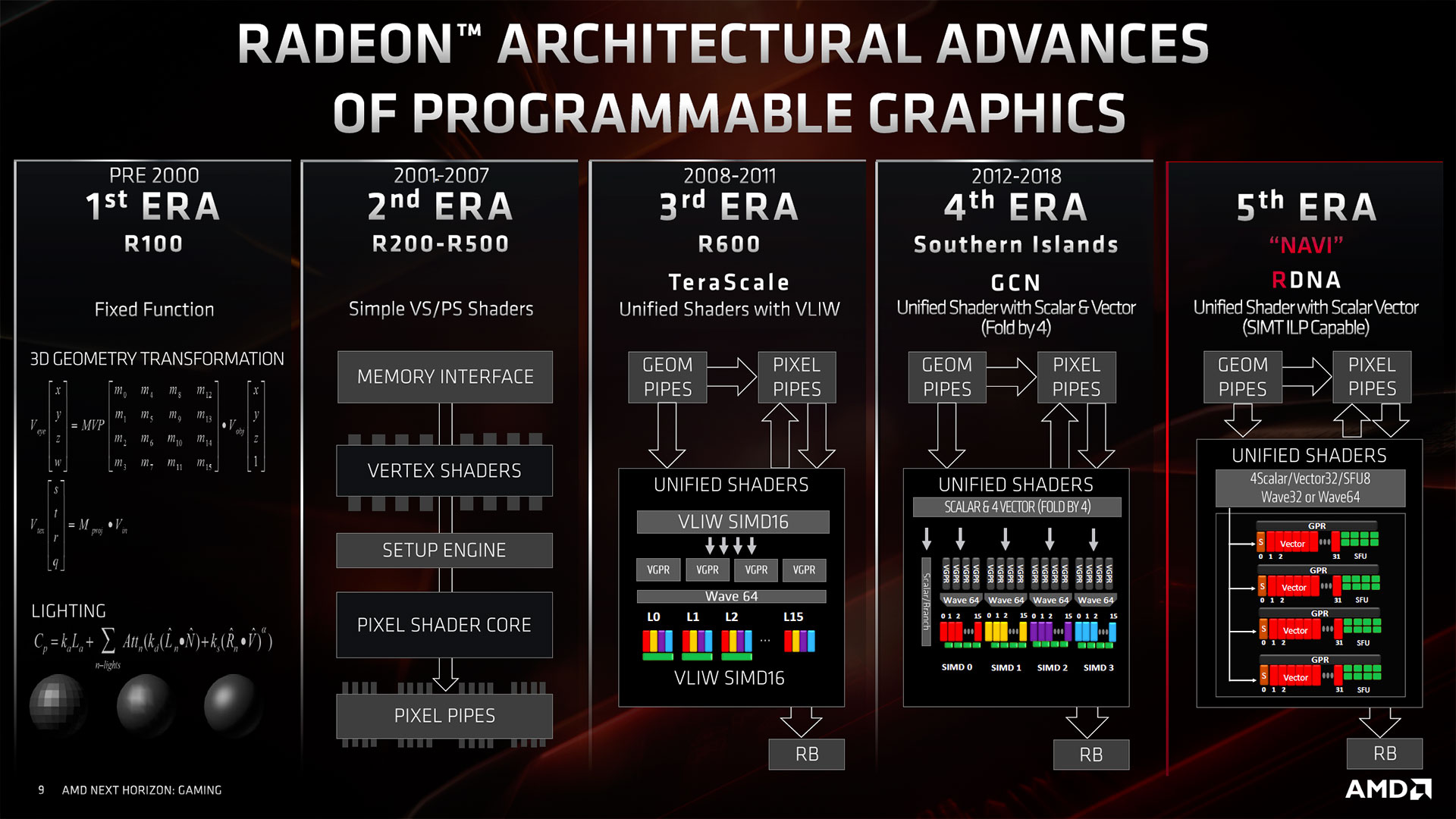
Pour ceux intéressés par l'architecture RDNA, nous vous invitons à lire ou relire les pages qui lui sont consacrées dans ce dossier. Résumée en quelques lignes, cette dernière est une profonde refonte des unités de calcul, avec le remplacement des 4 unités SIMD16 de GCN par 2 unités SIMD32 au sein d'un CU (Compute Unit). Ces dernières sont également plus flexibles avec la capacité de leur demander le traitement d'une instruction à chaque cycle d'horloge et ce pour chaque unité (via l'ajout d'un second ordonnanceur), alors qu'il n'était possible de ne le faire que pour une seule SIMD16 par cycle précédemment. À cela s'ajoute un traitement en parallèle des opérations spéciales via SFU et la présence d'une unité scalaire par SIMD (contre 1 / 4 précédemment). Enfin, le sous-système mémoire progresse avec l'introduction d'une nouvelle hiérarchie des caches (ajout d'un niveau), mais aussi des algorithmes d'économie de bande passante mémoire plus efficaces.
![Les différentes architectures d'AMD/ATi [cliquer pour agrandir]](/images/stories/articles/gpu/navi/architecture/ere_gpu_amd_ati_t.jpg "Ne pas appuyer ici")
Toutes ces modifications conduisent à un véritable bond au niveau de l'efficacité énergétique, du niveau de celui réalisé par NVIDIA lors de l'intronisation de Maxwell. Cela permet également un progrès significatif des performances avec les API plus anciennes, de quoi se montrer beaucoup plus compétitif que précédemment face au concurrent, évitant ainsi d'avoir à surdimensionner la puce et les éléments liés (étage d'alimentation, refroidisseur, largeur de bus mémoire) pour être à niveau dans le domaine ludique. Après Navi 10 lancé en juin dernier, c'est donc une puce plus petite qui nous arrive avec Navi 14.
![Die Navi 14 [cliquer pour agrandir]](/images/stories/articles/gpu/navi/rx_5500_xt/navi14_t.jpg "Si vous cliquez, vous cliquez.")
Navi 14, la seconde puce employant RDNA
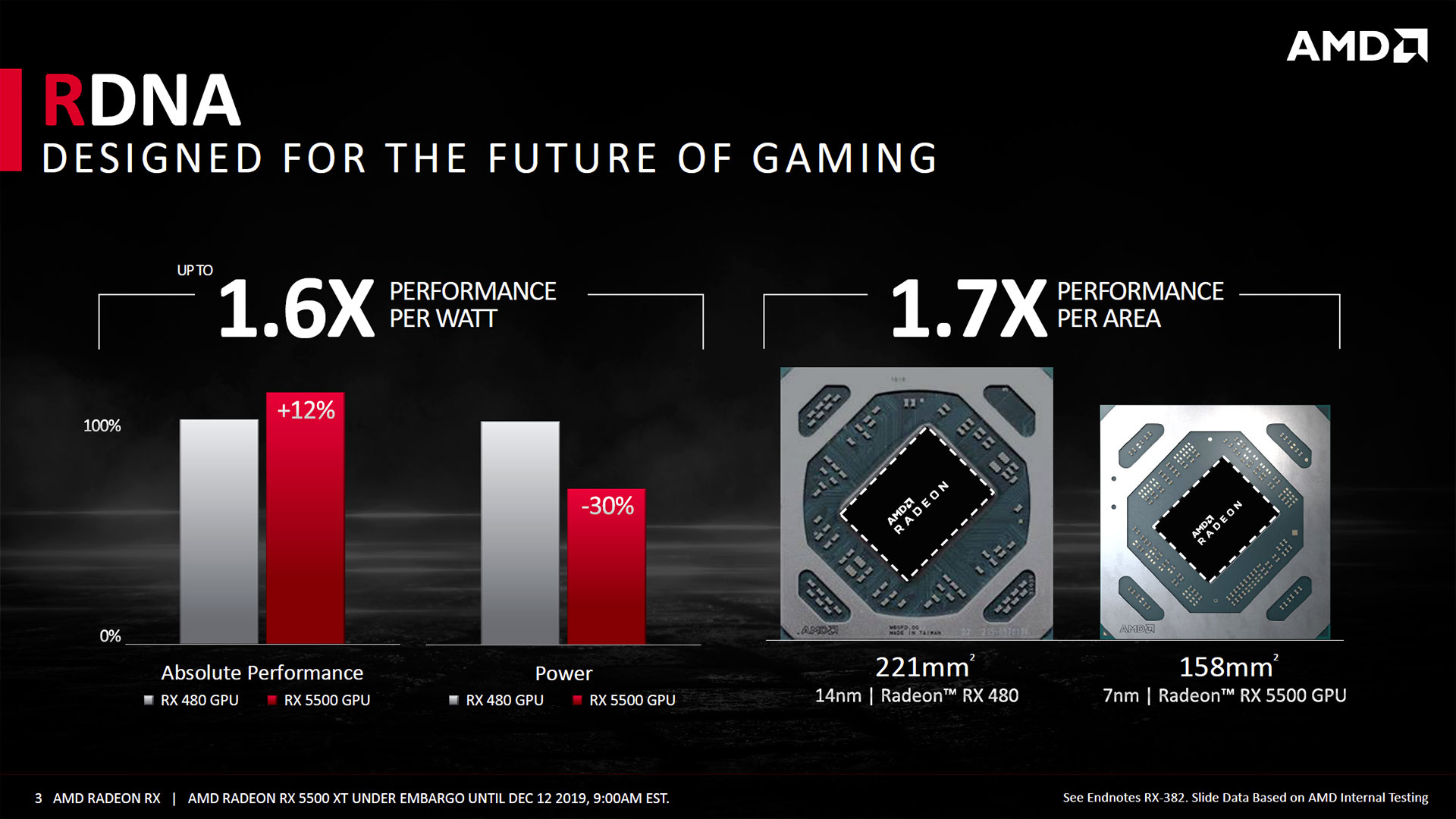
Cette nouvelle architecture a toutefois un coût relativement important en termes de complexité (nombre de transistors nécessaires), AMD peut néanmoins profiter de la nouvelle finesse de gravure 7 nm par le biais de TSMC (voir Samsung ). Ainsi, la superficie des premiers GPU RDNA reste contenue (donc davantage de puces par Wafer, qui sont les disques de silicium sur lesquels elles sont gravées), malgré un doublement du nombre de transistors par rapport à la génération précédente. C'est un choix différent de celui opéré par le caméléon, qui a augmenté la taille de ses dies en restant sur un process mature 12 nm. Difficile de dire quel est le plus pertinent financièrement, puisque les informations liées aux rendements (Yields) et aux coûts des Wafers sont confidentielles. Ce qui est certain par contre, c'est qu'AMD profite d'un process plus performant (fréquence/consommation) comme nous allons le détailler.
Si on se base sur les chiffres communiqués par AMD, bien que ces derniers aient tendance à changer avec le temps ente les premières communications et celles quelques années plus tard (comme Vega 10 qui a pris 9 mm² ou Polaris 10 qui en aurait perdu 11 ici), la densité augmente de 66% entre le 14 nm GF/Samsung et le 7 nm de TSMC. Cela permet un gain appréciable au niveau de la taille des puces, puisqu'il faut 286 mm² pour les 6,6 Milliards de transistors constituant TU116, alors que 158 mm² suffisent aux 6,4 Milliards de Navi 14. Mais ce n'est pas le seul atout, AMD annonce que ce process 7 nm de TSMC permet d'augmenter de 25% la fréquence à iso-consommation, ou une baisse de 50% de cette dernière à fréquence équivalente.
| Cartes | GPU | Nombre de transistors | Superficie Die |
Densité (Millions de transistors / mm²) | Procédé de fabrication |
|---|---|---|---|---|---|
| Radeon VII | Vega 20 | 13,2 Milliards | 331 mm² | 39,9 | TSMC 7 nm FF |
| RX 5700 / 5700 XT | Navi 10 | 10,3 Milliards | 251 mm² | 41 | TSMC 7 nm FF |
| RX 5500 / 5500 XT | Navi 14 | 6,4 Milliards | 158 mm² | 40,5 | TSMC 7 nm FF |
| RX 590 | Polaris 30 | 5,7 Milliards | 232 mm² | 24,6 | GF 12 nm LP |
| RX 580 | Polaris 20 | 5,7 Milliards | 232 mm² | 24,6 | GF 14 nm LPP |
| RX 560 | Polaris 21 | 3 Milliards | 123 mm² | 24,4 | GF 14 nm LPP |
AMD ne fournissant pas de diagramme officiel pour Navi 14, nous avons modifié celui de Navi 10 afin de représenter le nouveau venu selon notre appréciation (et l'observation du die représenté sur l'image précédente). Ainsi, le petit nouveau ne devrait se composer que d'un seul et unique Shader Engine, ce dernier comportant 24 CU soit 1536 SP et 96 TMU répartis équitablement au sein de 2 Shader Arrays. Le bus mémoire, les ROP et le cache L3 sont divisés par deux par rapport à Navi 10 à respectivement 128-bit, 32 (16 / Shader Array) et 2 Mo. Les éléments d'interface et ceux centralisés ne devraient pas évoluer de leur côté entre les 2 puces.
![Diagramme Navi 14 [cliquer pour agrandir]](/images/stories/articles/gpu/navi/rx_5500_xt/diagram_navi14_t.jpg "Enlarge your pe...icture")
Le GPU utilisé sur la RX 5500 XT est partiellement bridé pour améliorer les rendements et ainsi recycler certaines puces qui ne seraient pas parfaites. Cela a son importance en entrée de gamme où le coût est l'argument décisif. NVIDIA ne procède pas autrement avec sa GTX 1650 utilisant un TU117 légèrement bridé. AMD a ainsi désactivé 2 CU au sein de son Navi 14, limitant leur nombre actif à 22 pour 1408 SP et 88 TMU. Le bus mémoire et les éléments liés (ROP / L2) sont par contre inchangés.
| Radeon RX 5500 XT | Quantité activée | Quantité Présente |
|---|---|---|
| Shader Engine | 1 | 1 |
| WGP / CU | 11 / 22 | 12 / 24 |
| Streaming Processors | 1408 | 1536 |
| TMU | 88 | 96 |
| ROP | 32 | 32 |
| L2 (Mo) | 2 | 2 |
| Bus mémoire (bits) | 128 | 128 |
Au niveau de la mémoire, les rouges réutilisent la GDDR6 14 Gbps déjà associée à Navi 10. De quoi permettre une bande passante équivalente à la RX 570 malgré un bus mémoire divisé par 2. Les RX 580/590 conservent donc un avantage brute, mais c'est sans compter les progrès au niveau des mécanismes d'économie de bande passante. Enfin, toutes les autres fonctionnalités de Navi 10 sont conservées, tant au niveau des interfaces, moteur d'affichage vidéo et encodage/décodage. AMD met en évidence la comparaison avec Polaris 10/20/30, du fait de performances annoncées siimilaires, toutefois Navi 14 succède plutôt à Polaris 11/21 qui ne faisait que 123 mm² de son côté.
![Apport Navi 14 [cliquer pour agrandir]](/images/stories/articles/gpu/navi/rx_5500_xt/navi14_die_t.jpg "Enlarge your pe...icture")
Il n'en reste pas moins que les progrès apportés par cette nouvelle génération sont bel et bien réels et plus que bienvenus après des années GCN, qui montrait clairement ses limites dans certains domaines. L'avènement des API bas niveau ainsi que l'exclusivité au niveau des consoles qui utilisaient cette architecture, a permis toutefois de faire perdurer autant que possible cette dernière, pour le plus grand plaisir des acquéreurs de première heure.
|
|
| Un poil avant ?Les ventes de RDR2 décevantes ... sur l'Epic Games Store | Un peu plus tard ...Quoi de neuf dans le noyau Linux pour Noël ? | |