NVIDIA lève le voile sur Blackwell Ultra |
————— 25 Août 2025 à 18h10 —— 30977 vues



NVIDIA lève le voile sur Blackwell Ultra |
————— 25 Août 2025 à 18h10 —— 30977 vues
Le chemin qui mène de Blackwell à Rubin comprend une étape, Blackwell Ultra. NVIDIA a détaillé la conception de cette puce dans un article de blog dont le titre retranscrit bien le propos : Inside NVIDIA Blackwell Ultra: The Chip Powering the AI Factory Era.

D’emblée, écartons tout malentendu. Si tout laisse à penser qu’il y aura prochainement des GeForce RTX 50 Super, elles conserveront leurs GPU Blackwell ; Blackwell Ultra sied uniquement aux serveurs d’IA.
La puce Blackwell Ultra repose sur le procédé TSMC 4NP. Elle embarque 208 milliards de transistors, soit 2,6 fois plus que la génération Hopper (mais c'est aussi 1 vs 2 GPU). En contrepartie, son TGP autorise jusqu’à 1 400 W, soit le double de Hopper (la limite est fixée à 1 200 W pour Blackwell pas Ultra). La puce associe 160 SM répartis sur deux dies interconnectés via le lien NV-HBI (NVIDIA High-Bandwidth Interface) de NVIDIA, fournissant une interconnexion die-to-die de 10 To/s. Elle possède 288 Go de HBM3E et délivre jusqu’à 8 To/s de bande passante. Vous aurez aussi noté la prise en charge du PCIe 6.0.
| Génération | Hopper | Blackwell | Blackwell Ultra |
|---|---|---|---|
| Procédé de fabrication | TSMC 4N | TSMC 4NP | TSMC 4NP |
| Nombre de transistors | 80 milliards | 208 milliards | 208 milliards |
| Nombre de dies par GPU | 1 | 2 | 2 |
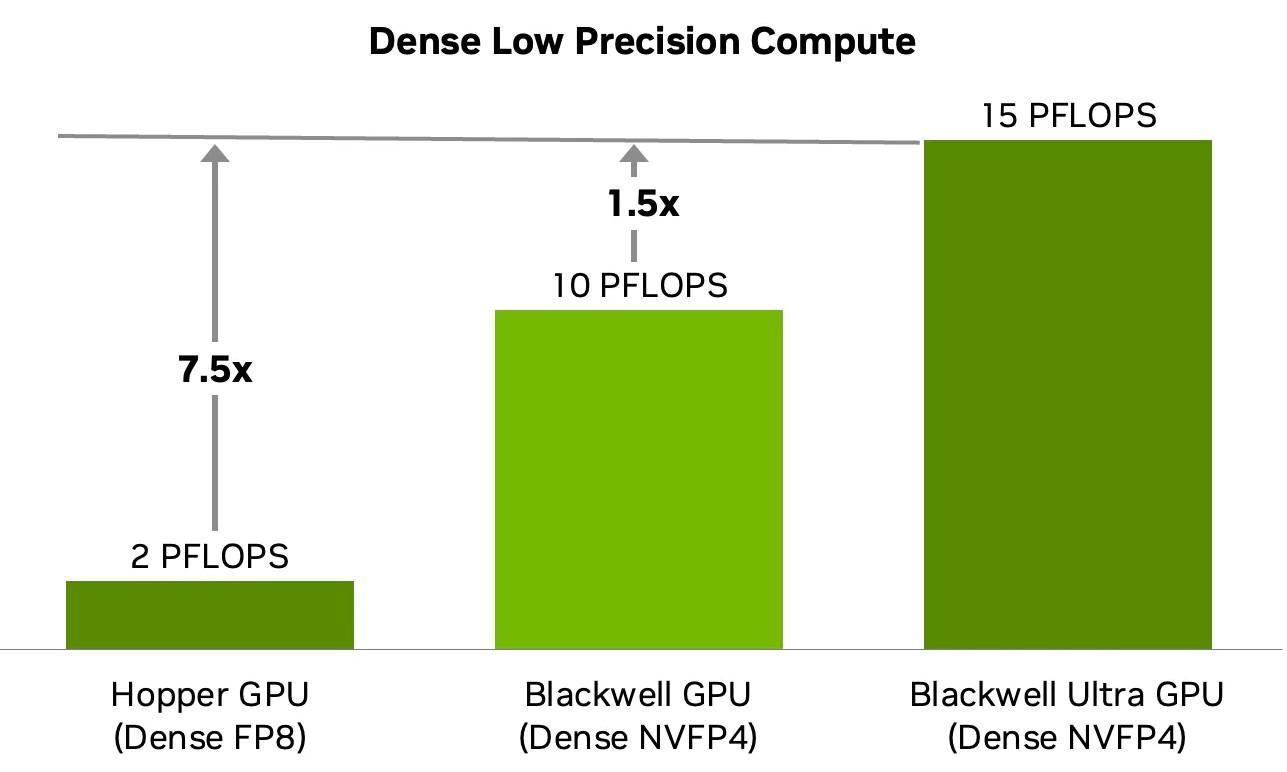
| NVFP4 dense | sparse performance | – | 10 | 20 PetaFLOPS | 15 | 20 PetaFLOPS |
| FP8 dense | sparse performance | 2 | 4 PetaFLOPS | 5 | 10 PetaFLOPS | 5 | 10 PetaFLOPS |
| Attention acceleration (SFU EX2) |
4,5 TeraExponentials/s | 5 TeraExponentials/s | 10,7 TeraExponentials/s |
| Capacité maximale HBM | 80 Go HBM (H100) / 141 Go HBM3E (H200) | 192 Go HBM3E | 288 Go HBM3E |
| Bande passante HBM maximale | 3,35 To/s (H100) / 4,8 To/s (H200) | 8 To/s | 8 To/s |
| Bande passante NVLink | 900 Go/s | 1 800 Go/s | 1 800 Go/s |
| Consommation maximale (TGP) | Jusqu’à 700 W | Jusqu’à 1 200 W | Jusqu’à 1 400 W |

Côté performances, le Blackwell Ultra offre une densité de calcul NVFP4 (un format de nombre à virgule flottante 4 bits ; plus d'infos sur le NVFP4 sur le site de la principale intéressée) environ 1,5 fois supérieure à celle du Blackwell, aux dires de NVIDIA.
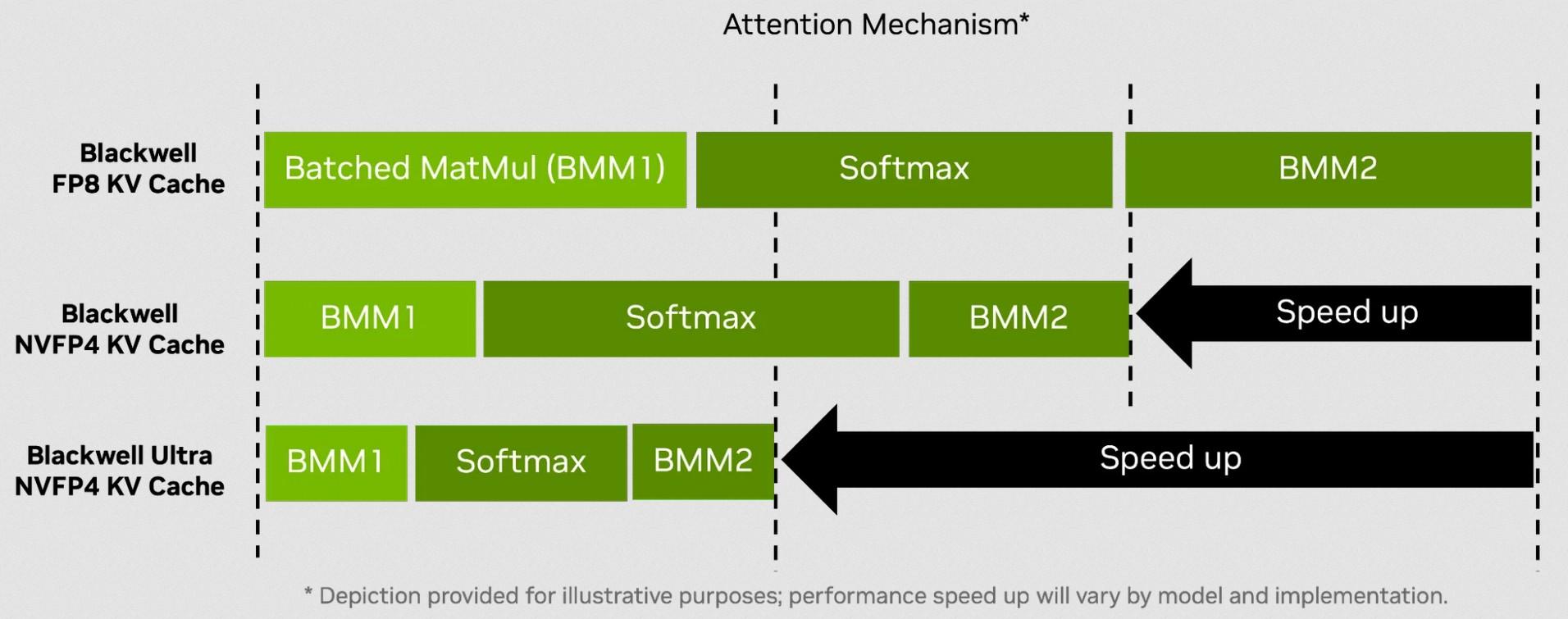
Les gains par rapport à Blackwell s’expliquent notamment par le doublement du débit des SFU (Special Function Units) pour les opérations d’attention des modèles Transformers. L’article précise à ce sujet : « Avec le Blackwell Ultra, le débit des SFU a été doublé pour les instructions clés utilisées dans l’attention, offrant jusqu’au double de performances dans les couches d’attention par rapport aux GPU Blackwell. Cette amélioration accélère aussi bien l’attention sur de courtes que sur de longues séquences, mais elle est particulièrement bénéfique pour les modèles de raisonnement avec de grandes fenêtres de contexte, où l’étape du softmax peut devenir un goulot d’étranglement en latence. »
Si ce qui précède ressemble pour vous à du charabia et que vous n'êtes pas un spécialiste de l'apprentissage automatique, c'est normal. Pour l’éclaircir, retenez que le softmax désigne une étape clé qui sert à déterminer comment chaque token influence la sortie via une pondération — en transformant des scores bruts d’attention en poids normalisés, appelés poids d’attention. Cette opération implique des calculs coûteux, surtout pour de longues séquences. Logiquement, plus ils sont optimisés, plus les modèles d’attention fonctionnent vite et efficacement. Si vous souhaitez approfondir ce sujet, IBM propose un excellent article de vulgarisation intégralement traduit en français : Qu’est-ce qu’un mécanisme d’attention ?
À l’échelle système, NVIDIA met en avant le GB300 NVL72 comme solution de référence : des baies à refroidissement liquide, bâties autour des Grace Blackwell Ultra Superchips, capables d’atteindre des performances FP4 denses de classe exascale, tout en offrant un gain significatif de débit par mégawatt face aux précédentes plateformes HGX. L’entreprise propose aussi des systèmes HGX B300 et DGX B300, des configurations standardisées à 8 GPU Blackwell Ultra.
Enfin, le Blackwell Ultra conserve bien entendu une compatibilité complète avec l’écosystème CUDA, tout en apportant des optimisations pour les frameworks IA de nouvelle génération. Il prend en charge nativement SGLang, TensorRT-LLM et vLLM avec des kernels optimisés pour la précision NVFP4 et l’architecture double-die. D'autre part, NVIDIA Dynamo optimise les déploiements massifs, tandis que la plateforme Enterprise AI fournit tous les outils cloud-native pour développer et gérer des charges IA à grande échelle. Ennfin, à propos des outils et bibliothèques CUDA à disposition des développeurs, l'article énumère CUTLASS, Nsight, Model Optimizer, cuDNN, NCCL et CUDA Graphs.
| Un poil avant ?2026, une période creuse pour les Ryzen mobiles ? | Un peu plus tard ...Clearwater Forest : les nouveaux Xeon E-core d’Intel en 18A | |





















