Test • AMD Radeon RX 7900 XT & RX 7900 XTX |
————— 12 Décembre 2022



Test • AMD Radeon RX 7900 XT & RX 7900 XTX |
————— 12 Décembre 2022
Pour vous aider dans la compréhension des pages à venir, nous vous invitons vivement à lire ou relire, si ce n'est pas déjà fait, celles que nous avions dédiées à RDNA au sein de ce dossier et son successeur ici. Cette architecture RDNA, est une refonte profonde de la précédente (GCN), avec pour objectif d'améliorer drastiquement les performances par watt. Pour ce faire, AMD a sérieusement revu l'organisation de ses unités de calculs, mais aussi le sous-système mémoire, en particulier la hiérarchie des caches. Pour la seconde itération de cette architecture, les rouges ont poursuivi dans ce sens avec 3 contributeurs principaux à l'amélioration. Le premier est l'augmentation significative de l'IPC, en particulier avec l'inclusion d'un cache de niveau 3. Le second est la réduction de la puissance nécessaire pour atteindre une fréquence donnée ou exécuter certaines tâches, et enfin le dernier consiste à améliorer la capacité à monter en fréquence de l'architecture. Le tout combiné, permettait un gain de 54% au niveau du rapport performances par watt. Quels sont cette fois les contributeurs qui ont présidé à la naissance de RDNA3 ?
![RDNA 3 main specs [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/caract_t.jpg "Enlarge your pe...icture")
Nous détaillerons les parties chiplet et display/media engine dans les pages suivantes, pour nous concentrer sur l'architecture au sein de celle-ci. Commençons par le diagramme de blocks de Navi 31. Tout comme son prédécesseur, nous y retrouvons les composants standards des rouges. Un processeur de commande central est toujours chargé de planifier et ordonner les différents threads. Selon AMD, il est à présent 2,3x plus performant que son prédécesseur pour les commandes de rendus multiples, permettant de réduire l'overhead CPU au niveau des pilotes ou de l'API.
A ses côtés, se trouvent les unités chargées de l'organisation et de la gestion des tâches Compute, ainsi qu'un processeur géométrique central et le cache L2. Diverses interfaces, moteurs vidéo & d'affichage, complètent cette partie du GPU. Le cache L3 et les contrôleurs mémoires sont à présent répartis au sein de 6 dies dédiés (cf. page suivante). Le bus mémoire passe donc à 384-bit, par contre le L3 se voit amputé d'un quart, avec 96 Mo maximum, contre 128 Mo précédemment sur Navi 21.
Enfin, l'exécution des programmes est toujours réalisée au sein des Shaders Engine, dont le nombre progresse de 50 % également, à 6 en tout. Chacun dispose de leurs propres cache L1, unité de rastérisation (découpe des triangles en pixels), Primitive Unit (génération et traitement des triangles), ainsi que 32 ROP (unité de rendu/sortie) et 8 Dual Compute Unit, (contre 10 par Shader Engine sur Navi 21) comprenant comme leur nom l'indique, 2 CU. Au final leur nombre total progresse donc de 20%, à 96 en tout.
![RDNA 3 architecture [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_diagram_t.jpg "Cliquédélique !")
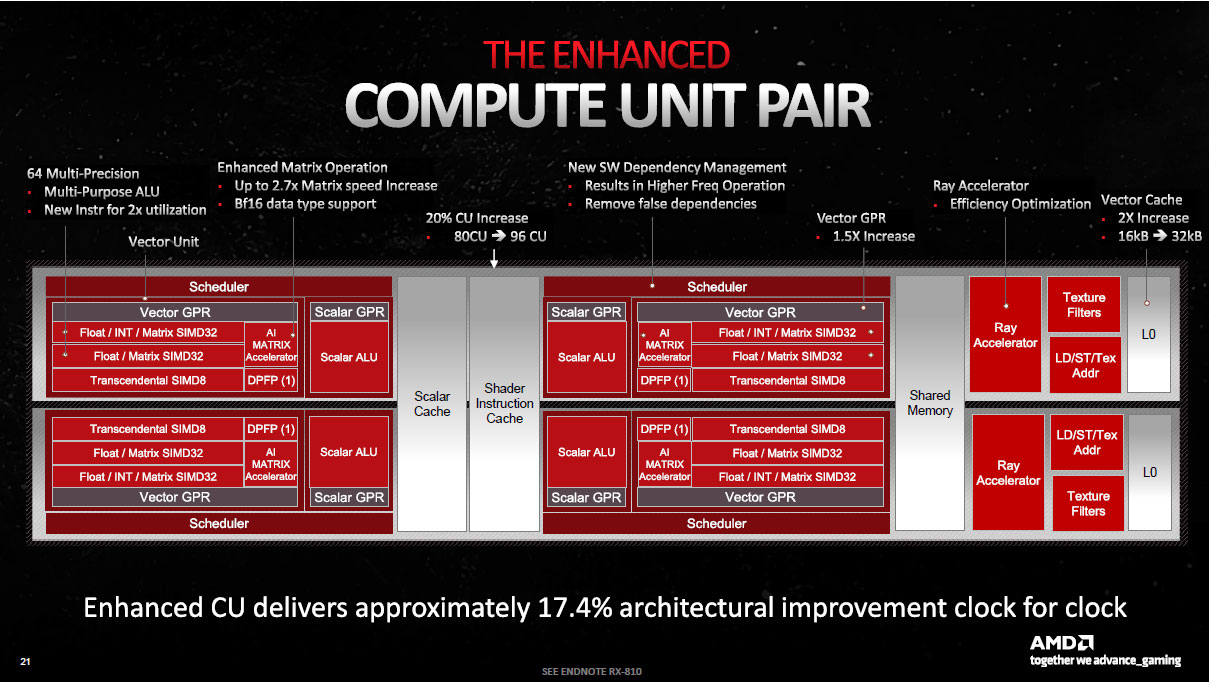
Concentrons nous donc à présent sur ces Compute Unit Pair ou Dual CU. Leur structure est très similaire à celle de la génération précédente, on notera tout de même un ajout notable via la présence d'une unité matricielle que nous détaillerons un peu plus bas.
![RDNA 3 compute units refreshed [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_cu_pair_t.jpg "Visionner en grand sur un magnifique pop-up")
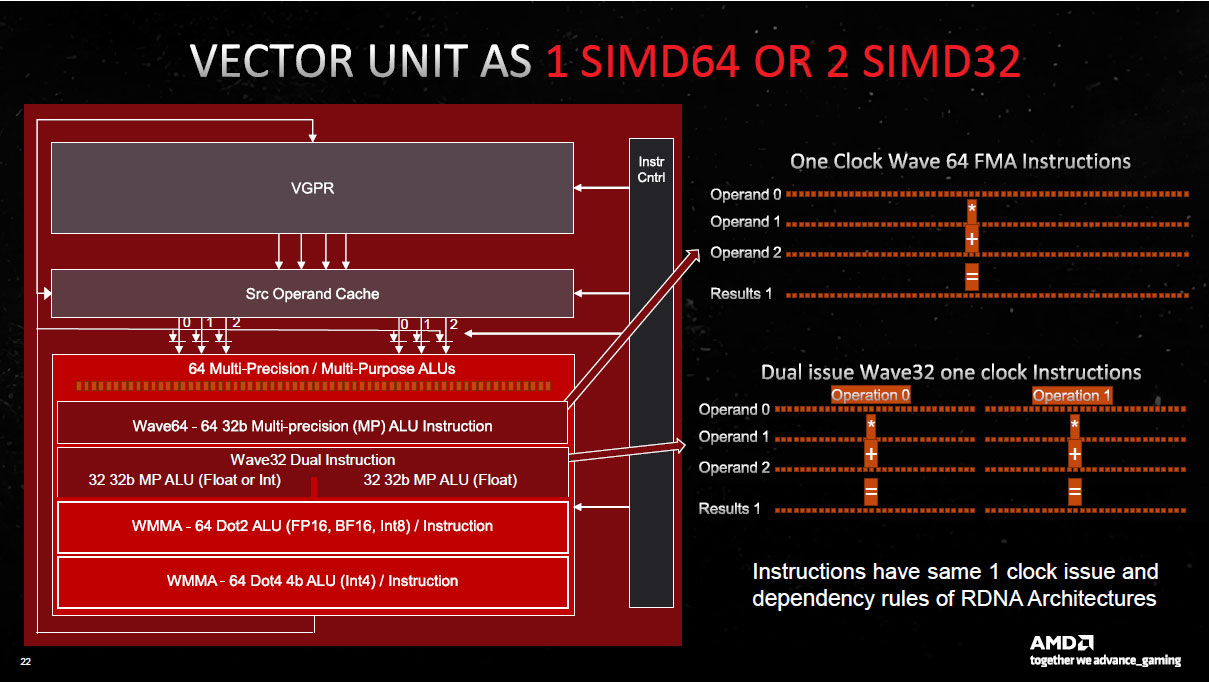
Mais similaire ne veut pas dire identique, loin de là. Car une des nouveautés de ces Compute Units, est la possibilité de doubler le taux d'exécution via Dual Issue. Comment tout cela fonctionne-t-il ? Eh bien AMD a tout simplement doublé le nombre d'ALU FP32 par SP au sein des unités SIMD, qui sont donc théoriquement capables d'exécuter 2 instructions par cycle. Toutefois, afin que l'implémentation ne soit pas trop coûteuse, il y a des contraintes à leur utilisation. Ainsi, ce doublement n'est effectif que lorsque le compilateur est capable d'extraire une seconde instruction d'un même WaveFront (liste de tâches à traiter envoyées au GPU). C'est mine de rien un gros changement de philosophie, et si RDNA 2 ne changeait pas grand chose à ce niveau par rapport à l'itération originelle, ce n'est pas le cas ici. L'efficacité de cette implémentation dépendra donc fortement de la partie logicielle en fonction du type de tâches à traiter.
![RDNA 3 vector units [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_vectorunit_t.jpg "La magie de la loupe, sans loupe")
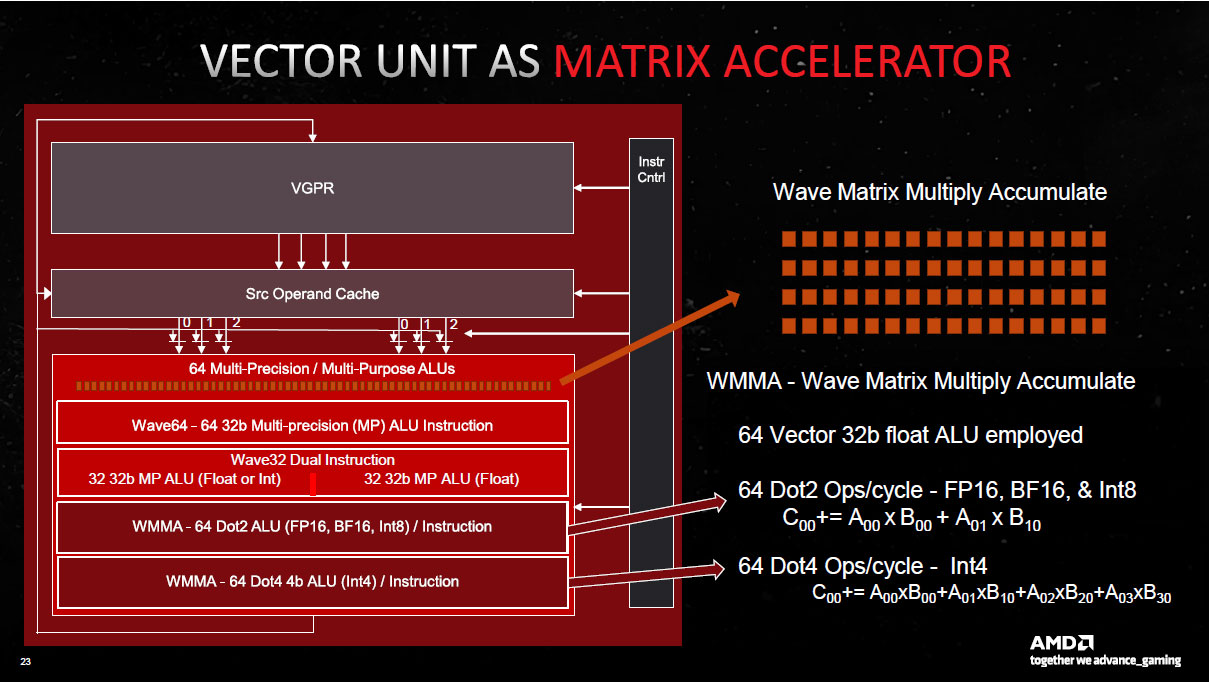
Autre gros changement que nous évoquions précédemment, l'ajout d'unités matricielles permettant de traiter beaucoup plus rapidement les faibles précisions. Cet usage est fortement utilisé en IA, en particulier pour les tâches d'inférence, mais aussi d'apprentissage. AMD rejoint donc Nvidia et Intel en implémentant de telles unités au sein de leur GPU grand public. Reste à voir ce qu'en feront les rouges dans le domaine ludique, puisque le FSR par exemple, n'utilise pour l'heure pas l'IA.
![RDNA 3 vector units [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_matrix_t.jpg "Visionner en grand sur un magnifique pop-up")
Un des points faibles avérés de RDNA2, est son implémentation faiblarde de l'accélération du BVH pour le Ray Tracing. AMD indique avoir retravaillé cela sur plusieurs axes. Le premier est la prise en charge de marqueurs géométriques, permettant d'éviter de lancer une traversée du BVH pour rechercher une intersection entre rayon et triangle, si ce dernier peut-être éjecté préalablement (culling) car non visible dans une scène.
![RDNA 3 ray tracing [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_rt1_t.jpg "Visionner en grand sur un magnifique pop-up")
Le second point d'amélioration concerne le filtrage et tri des rayons préalablement à leur entrée dans le BVH, afin d'éviter des itérations supplémentaires lors de la traversée de ce dernier. Ainsi, les rayons sont classés en fonction de la distance les séparant du premier impact, mais aussi ceux qui vont présenter des chevauchements (ombres) ou se terminant à la première intersection.
![RDNA 3 ray tracing [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_rt2_t.jpg "Enlarge your pe...icture")
Enfin, la dernière optimisation est une prise en charge Hardware directement au sein des Ray Accelerator, de l'ordonnancement et la traversée du BVH, qui étaient auparavant directement réalisés via shaders sur les unités de calcul traditionnelles, les libérant ainsi pour d'autres tâches. AMD précise également qu'un nouvel algorithme d'ordonnancement permettrait d'optimiser l'usage des ressources, à l'image du SER des verts ou de son équivalent chez les bleus. Enfin, les rouges indiquent que le débit brut de ces Ray Accelerator, progresse de 50 % par rapport à la génération précédente.
![RDNA 3 ray tracing [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_rt3_t.jpg "Même pas cap' de cliquer")
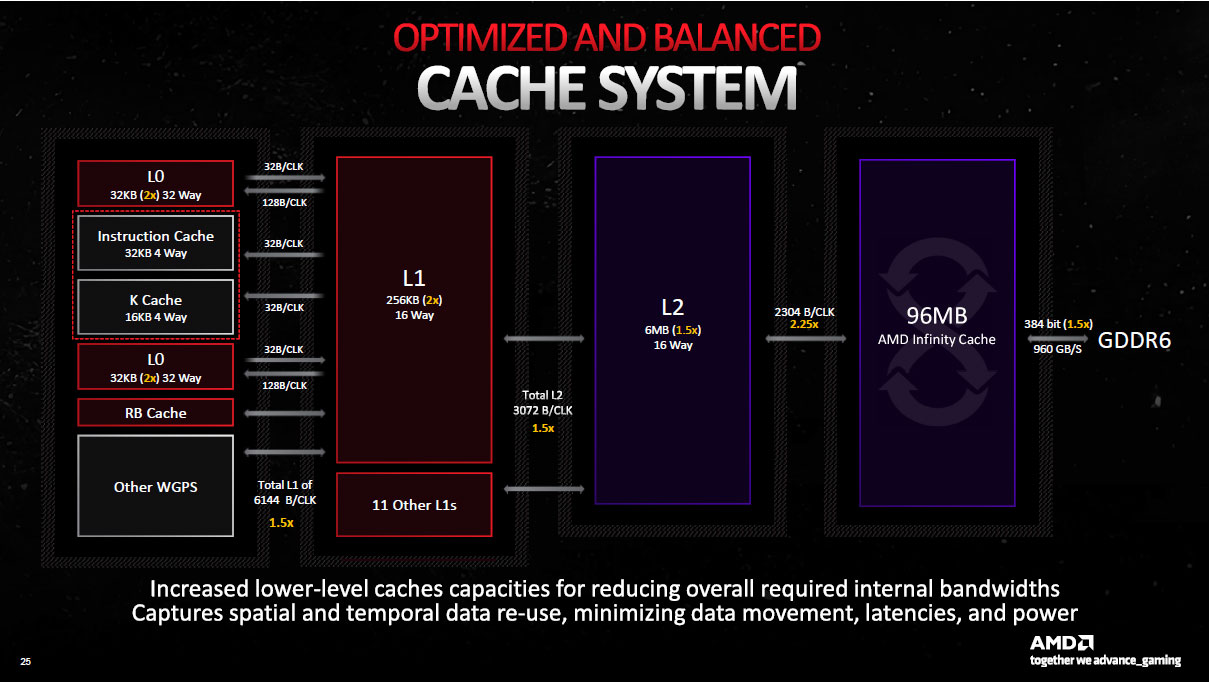
Un mot concernant les différents caches. Le L2 progresse de 50 %, suivant ainsi l'augmentation du nombre de Shader Engines, la progression est par contre plus marquée pour les L0 et L1, qui sont eux, doublés. En définitive, seul le L3 (Infinity Cache) recul au niveau de sa capacité, comme précisé en début de page. On notera également une progression de certains débits entre niveaux de cache.
![RDNA 3 cache improvements [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_cache_t.jpg "Ne pas appuyer ici")
Voilà ce que nous pouvions vous dire sur cette architecture, passons à présent à l'autre évolution notable apportée par RDNA3 sur Navi 31.
|
|
| Un poil avant ?Combien de RX 7900 sur les étalages pour finir 2022 ? | Un peu plus tard ...Ventes de jeux vidéo : la fameuse nain-posture | |