Test • AMD Radeon RX 7900 XT & RX 7900 XTX |
————— 12 Décembre 2022



Test • AMD Radeon RX 7900 XT & RX 7900 XTX |
————— 12 Décembre 2022
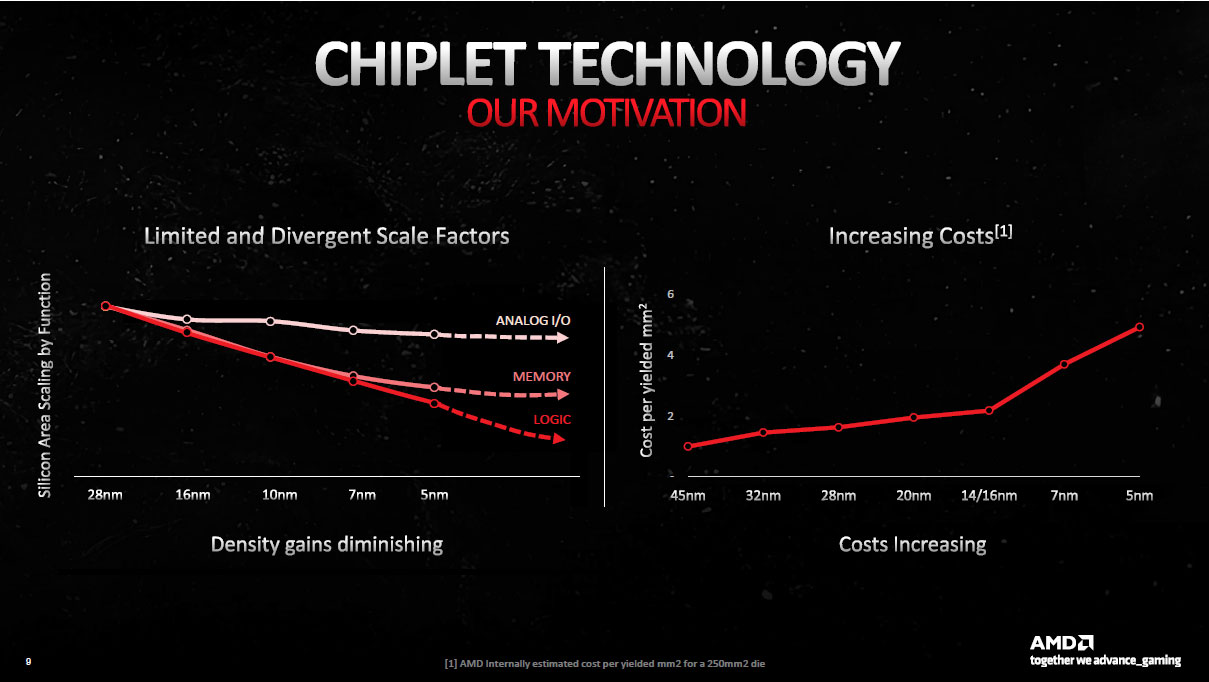
Si AMD a réussi à se montrer aussi compétitif ces dernières années dans le domaine des CPU grand public, il le doit à une architecture efficace couplée à une efficacité industrielle remarquable. Cela passe par une attention particulière apportée au design de ses puces pour minimiser la taille nécessaire, tout en couplant cela avec une approche innovante, les chiplets. Si vous êtes un lecteur régulier de nos colonnes, ce terme doit vous être familier, pour les autres, voici une définition simple du concept : au lieu de concevoir une seule puce monolithique de taille conséquente, il est préférable selon AMD, de créer plusieurs puces plus petites dédiés à des fonctions précises. Elles seront ainsi plus aisées à produire et pourront utiliser des procédés de fabrication différents.
![RDNA 3 chiplets design [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_usage_silicium_t.jpg "La magie de la loupe, sans loupe")
Pourquoi utiliser des procédés de fabrication distincts ? Selon les rouges, la raison principale provient du fait que certaines parties d'un GPU ne profitent que très peu des nouvelles finesses de gravure, tant du côté de la densité que des performances des transistors. Comme dans le même temps, le coût de production des dernières lithographies devient de plus en plus important, il parait plus que légitime de réserver ces dernières aux éléments qui vont en tirer bénéfice (les unités logiques) et se contenter d'un procédé moins coûteux pour d'autres (interfaces & mémoires).
![RDNA 3 chiplets design [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_chiplets1_t.jpg "Visionner en grand sur un magnifique pop-up")
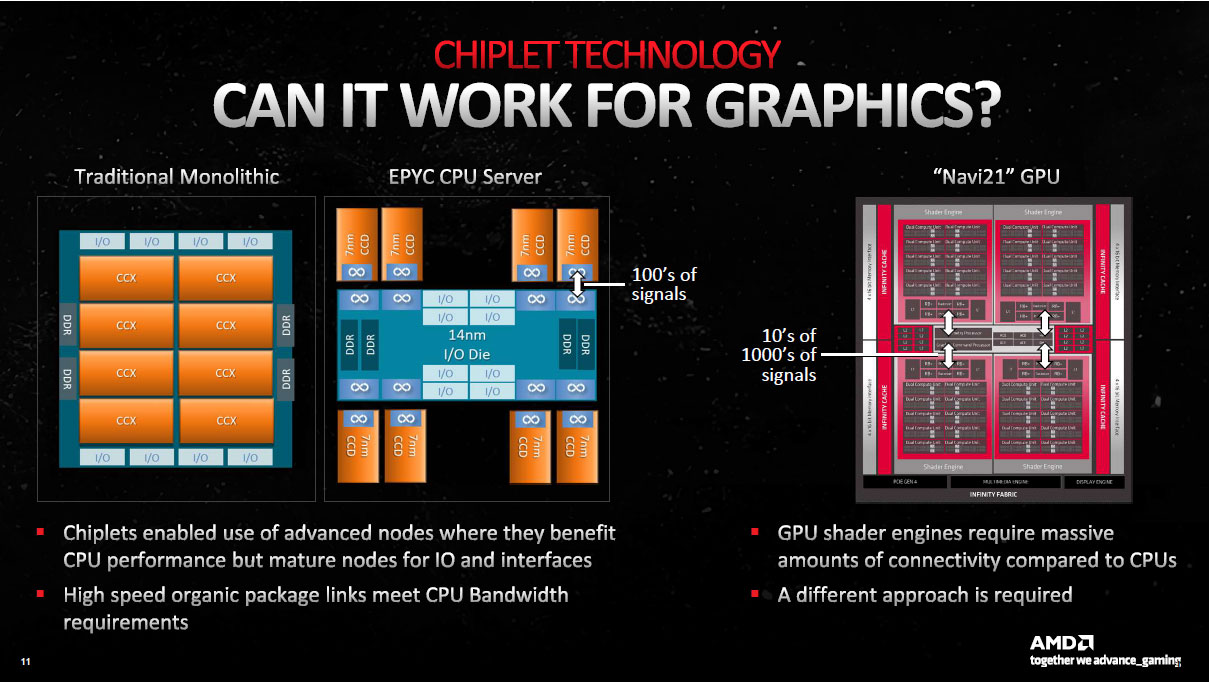
Voilà pour la théorie, mais identifier les éléments qui vont pouvoir profiter ou non de l'amélioration de la lithographie est une chose, être capable de les désolidariser au sein de dies séparés, en est une toute autre. Car le plus gros défi qui se pose ici, vient de la complexité de l'interconnexion entres éléments d'un GPU, sans comparaison avec celle d'un CPU. Pour imager cela, AMD compare le besoin d'interfaçage entre dies d'un CPU Epyc et de "blocs comparables" au sein d'un GPU. Le rapport de complexité est de 1 pour 100, ce qui signifie que les rouges ne pouvaient pas se contenter de copier-coller la solution existante pour ses CPU.
![RDNA 3 chiplets interconnexion design vs epyc [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_chiplets2_t.jpg "Ne pas appuyer ici")
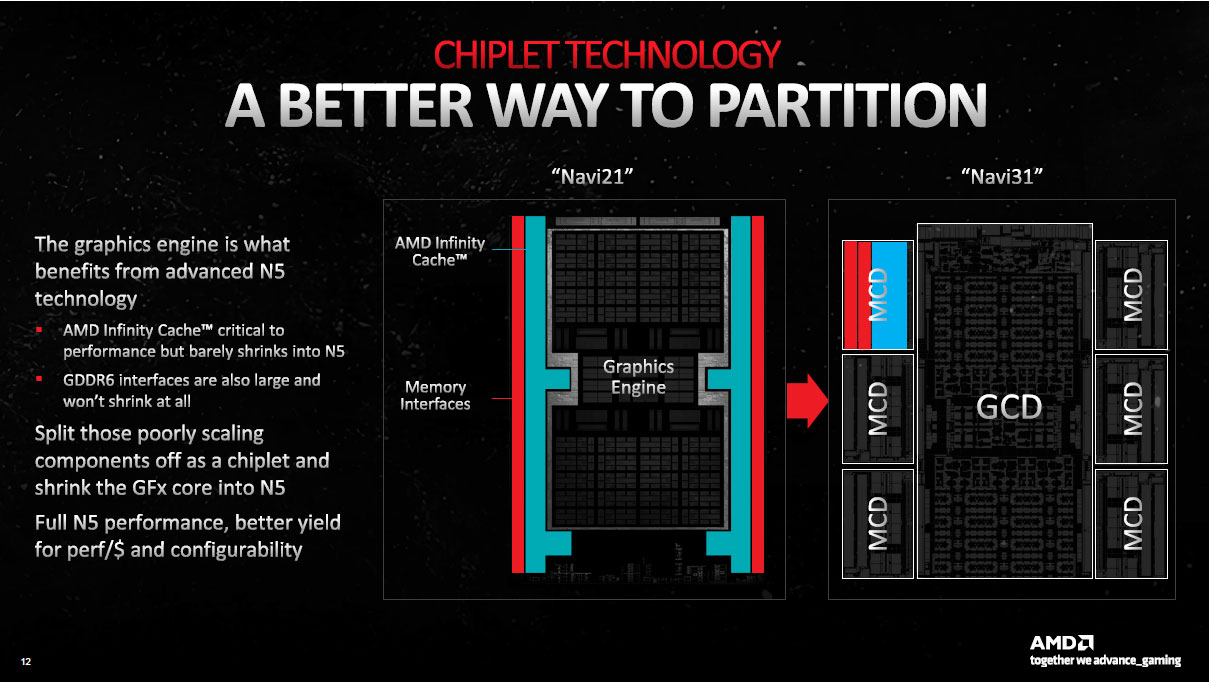
Pour commencer, il a fallu déterminer où procéder à la partition. Après analyse, les rouges ont identifié que le cache L3 qui constitue l'avancée majeur de RDNA 2, profitait finalement assez peu d'un passage à la gravure 5 nm. Il en est de même pour les interface GDDR6, ce sont donc ces éléments qui ont été logiquement désignés comme pertinents à extraire du die 5 nm, pour les transférer sur des chiplets annexes, conservant un procédé de gravure similaire à la génération précédente.
![RDNA 3 chiplets interconnexion design [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_chiplets3_t.jpg "Enlarge your pe...icture")
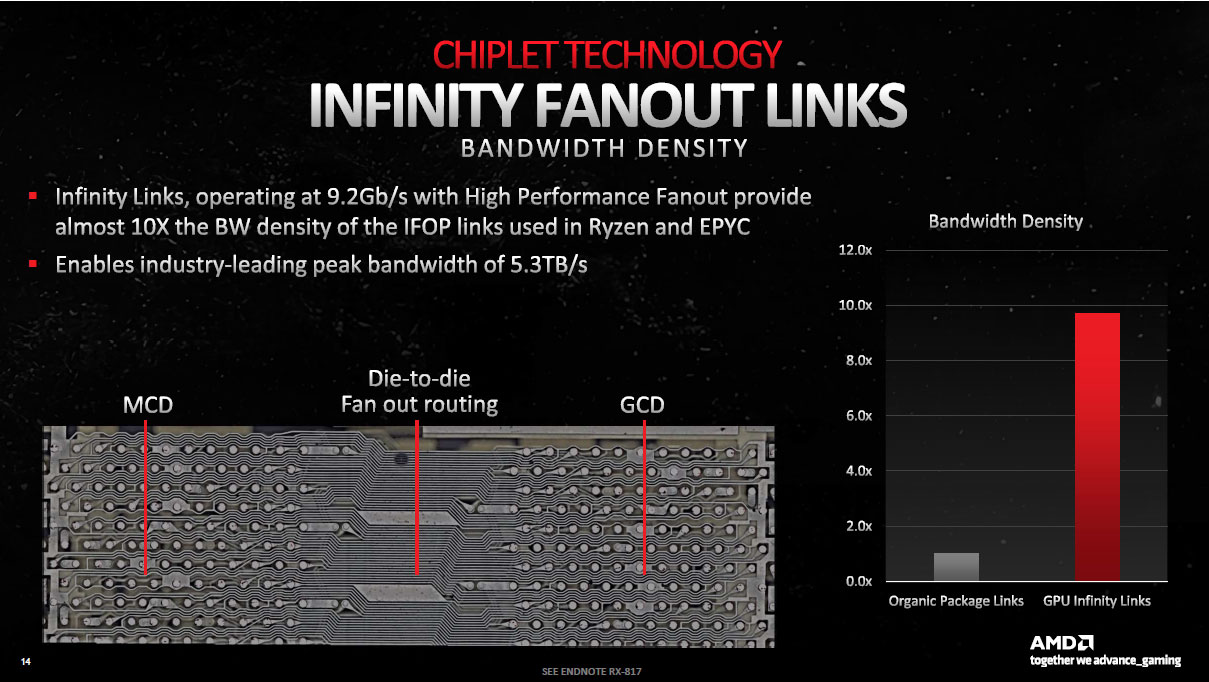
Voilà pour répondre à la question "où pratiquer la séparation au sein d'un GPU ?", restait maintenant à définir le "comment procéder ?". Car ce n'est pas une mince affaire, sachant que la bande passante nécessaire entre GCD-MCD, est plus de 10 fois supérieure à celle entre chiplets CPU. Il a donc fallu revoir les techniques de packaging pour proposer une interface jusqu'à présent inédite entre dies.
![RDNA 3 chiplets interconnexion design [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_chiplets4_t.jpg "Enlarge your pe...icture")
Cette dernière est nommée Infinity Fanout Links par AMD. Comme son nom l'indique, elle s'appuie sur l'Infinity Fabric qui autorise dans cette implémentation, jusqu'à 9,2 Gb/s. La bande passante cumulée de tous les MCD avec le GCD, culmine à 5,3 To/s, soit un peu moins de 900 Go/s entre un MCD et le GCD.
![La technologie pour l'interconnexion [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_chiplets5_t.jpg "Cliquédélique !")
Pour cette interconnexion au sein du packaging, AMD n'utilise plus de substrat organique comme c'était le cas jusqu'à présent. Les rouges ne vont pas plus loin dans les détails à ce niveau, cela doit de toute façon faire appel à de la chimie complexe, excédant nos compétences en la matière. Ce qu'il faut en retenir, c'est que cette technologie permet de doubler le nombre de lignes d'interconnexion au sein de l'interface, en comparaison de ce qui peut se faire via un traditionnel substrat organique.
![La complexité d'une telle interconnexion [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_chiplets6_t.jpg "Ne pas appuyer ici")
AMD précise également que cette interface n'est pas seulement performante, elle a aussi été développée pour être économe. Pour ce faire, la tension de fonctionnement est faible, et l'ajustement des fréquences est très agressif, pour permettre de réduire ces dernières dès que c'est possible. Selon les rouges, cela permettrait de sauver 80 % d'énergie par bit, en comparaison de liens d'un packaging traditionnel. Au final, une bande passante effective de 3,5 To/s, ne couterait que 5% de la puissance électrique totale du GPU d'après AMD.
![L'efficacité énergétique de la solution retenue [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_chiplets7_t.jpg "Si vous cliquez, vous cliquez.")
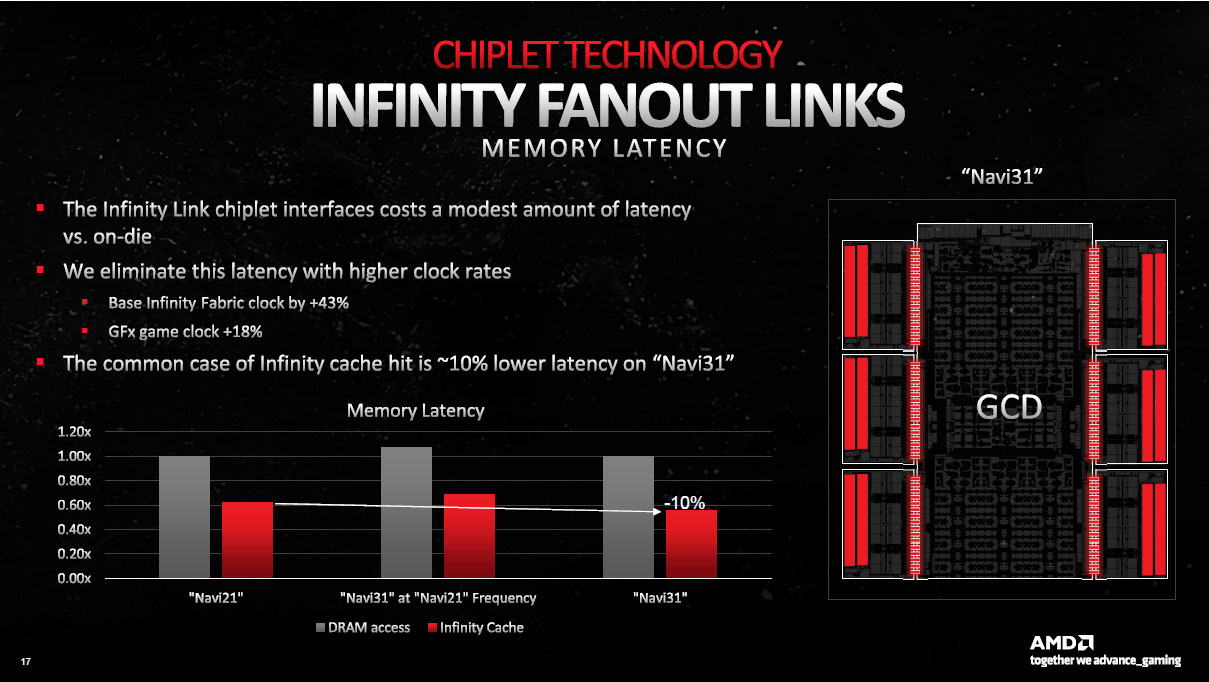
Un dernier mot concernant l'augmentation de latence induite par cette interface. Toujours selon AMD, cette dernière serait limitée en comparaison d'une approche monolithique traditionnelle. Néanmoins, pour la compenser, AMD a augmenté de respectivement 43 % et 18 % la fréquence de fonctionnement de l'Infinity Fabric et du GPU. Ces deux actions combinées, conduiraient à une baisse de 10 % de la latence d'accès au cache L3 sur Navi 31, en comparaison de celle mesurée pour Navi 21.
![Les performances de l'interconnexion [cliquer pour agrandir]](/images/stories/articles/gpu/rdna3/archi/arch_chiplets8_t.jpg "Ultra bouzotron HD max def")
Voilà c'est tout pour cette partie, jetons à présent un coup d'œil plus précis sur Navi 31, page suivante.
|
|
| Un poil avant ?Combien de RX 7900 sur les étalages pour finir 2022 ? | Un peu plus tard ...Ventes de jeux vidéo : la fameuse nain-posture | |