Test • Nvidia GeForce RTX 4090 |
————— 11 Octobre 2022



Test • Nvidia GeForce RTX 4090 |
————— 11 Octobre 2022
A l'occasion du lancement de la RTX 4090, Nvidia insiste très fortement sur la troisième itération de sa technique d'upscaling assisté par IA, aka DLSS. Mais avant de parler de cette dernière, petit rappel des 2 précédentes, dont l'origine remonte à l'introduction de Turing. La promesse était d'offrir des performances en nette hausse, pour une qualité visuelle équivalente à celle atteinte avec un TAA classique. Pour ce faire, le caméléon utilise une build d'un jeu fourni par les développeurs et procède au rendu de dizaines de milliers d'images avec une qualité visuelle parfaite ou presque (64 échantillons par pixel), collectant ainsi le résultat de sortie et les données d'entrée brutes (images en basse résolution et aliasées) qui vont pouvoir être utilisés lors de l'opération d'apprentissage profond (Deep Learning) à venir.
Un réseau de neurones artificiels (de type auto-encodeur convolutif) est ensuite entraîné à obtenir cette qualité de sortie avec ces données d'entrée, au moyen de méthodes fortement matheuses (back propagation), ce qui lui permet "d'apprendre" les spécificités propres à ces images. Il résulte de cet apprentissage un DNN model (Deep Neural Network signifie "réseau de neurones profond") capable d'imiter le comportement observé sur l'échantillon utilisé lors de l'apprentissage, et ce pour un coût bien moindre que la technique originelle. Comment ? Par le biais des Tensor Cores, qui utilisent alors le DNN model sur l'image brute aliasée de définition plus faible, pour infèrer en temps réel le rendu anti-aliasé à la définition d'affichage requise. L'inférence est friande des calculs en faible précision où les Tensors Cores excellent.
![DLSS [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/dlss_t.jpg "Enlarge your pe...icture")
Voilà pour la théorie, mais à l'exception notable du tout premier jeu proposant cette fonctionnalité (FFXV), la plupart des réalisations suivantes ont été décevantes avec un rendu souvent flou, comme nous l'indiquions ici ou là par exemple, Battlefield V détenant le pompon à ce niveau. Toutefois, les verts ne se sont pas contentés de ces premiers essais largement perfectibles, et après une étape intermédiaire encourageante, la version 2.x a revu en profondeur l'auto-encodeur convolutif, mais ce n'est pas tout.
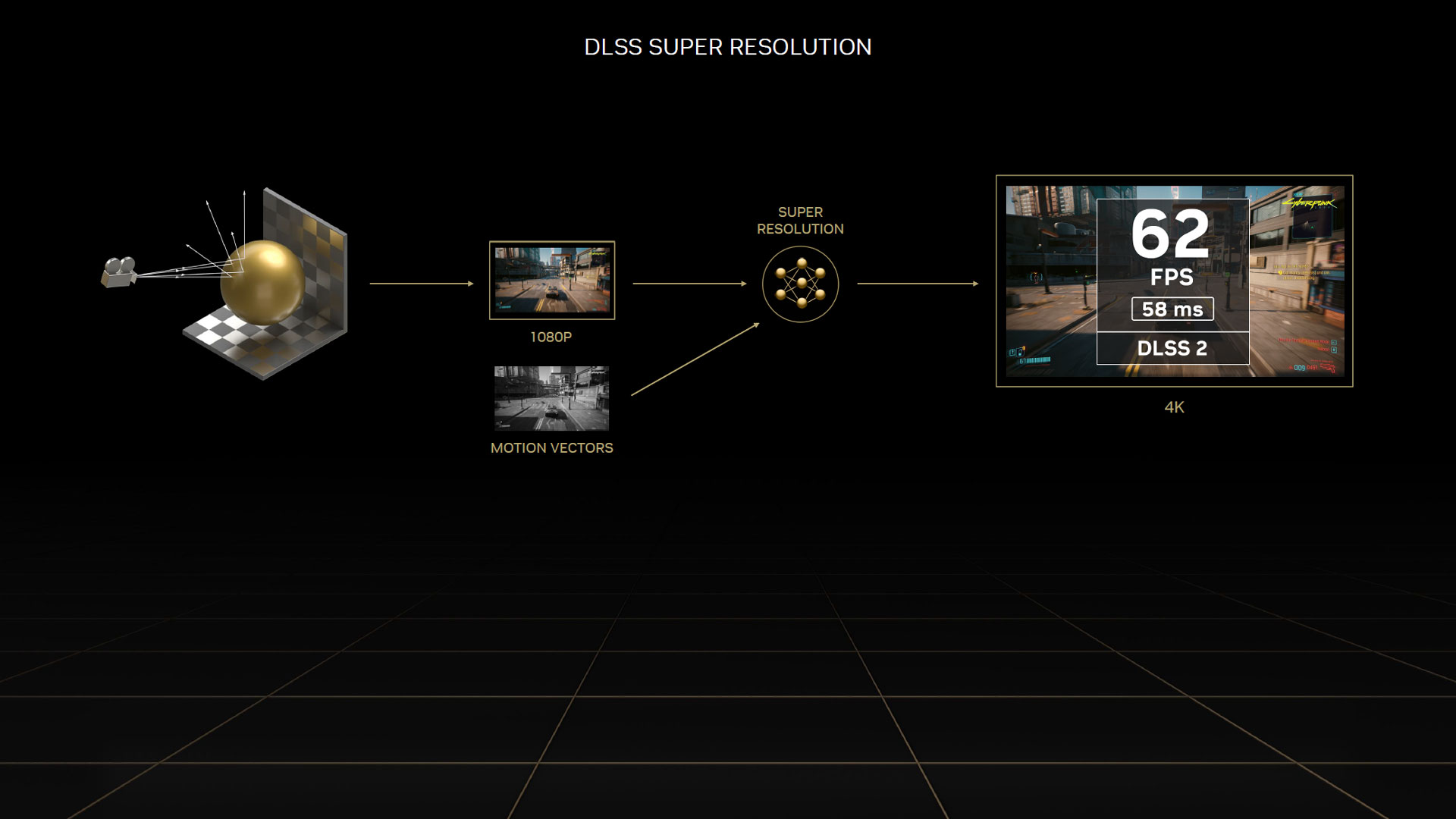
Ainsi, la notion de Temporal Feedback a également été ajoutée, comme illustré ci-dessous. Derrière cette dénomination, se cache l'intégration des vecteurs de mouvement, aux données d'entrée collectées en basse résolution. Ceux-ci sont ensuite appliqués à la précédente image de sortie (haute qualité), afin d'estimer plus précisément quelle sera l'apparence de la prochaine. Cela permet de rendre des images plus nettes (diminuant très notablement le flou qui était le défaut de la première itération) tout en améliorant la stabilité d'une image à la suivante.
![DLSS 2.x [cliquer pour agrandir]](/images/stories/articles/gpu/ada_lovelace/dlss2_t.jpg "Enlarge your pe...icture")
Un mot supplémentaire concernant l'auto-encodeur : ce dernier est à présent commun à tous les jeux (facilitant et accélérant ainsi son intégration au processus de création). Toutefois, il est toujours nécessaire de générer (via apprentissage profond ou Deep Learning dans la langue de Shakespeare) un DNN Model spécifique à chaque jeu par le biais de ce réseau de neurones. A noter également que cette seconde itération de DLSS, permet de choisir différents niveaux de qualité afin de laisser le choix à l'utilisateur. En pratique, il s'agit de faire varier la définition du rendu avant l'inférence des images dans la définition finale.
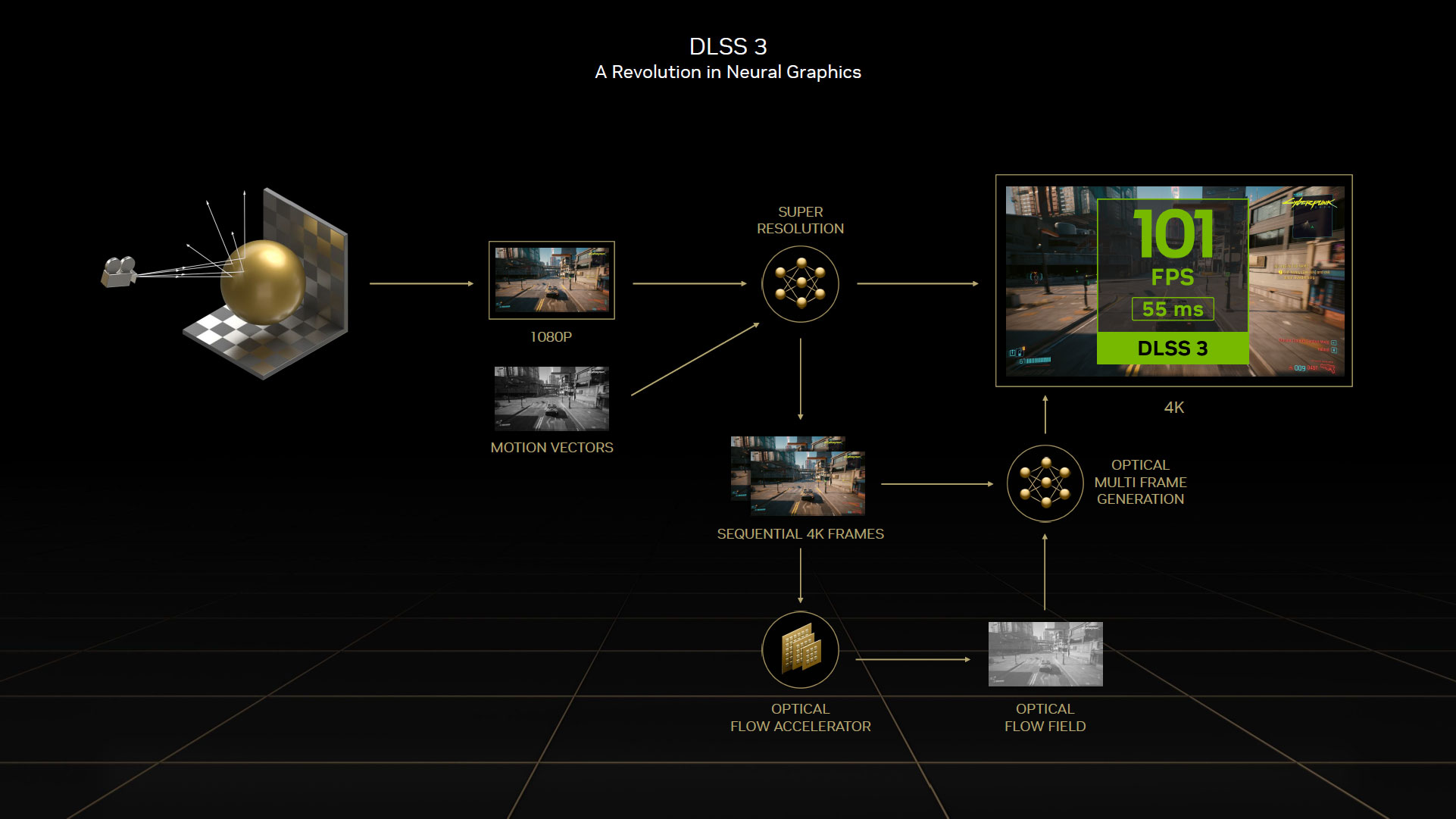
Si vous êtes un habitué du Comptoir, vous avez du voir passer bon nombre de dossiers où nous analysons la qualité visuelle à l'aide de captures vidéo. Le résultat atteint est à présent très satisfaisant dans la plupart des cas, même si certains puristes préfèreront toujours l'option de rendu natif. Pour le DLSS 3, les verts n'ont pas mis l'accent sur une amélioration de la qualité visuelle, cette dernière continuant à s'améliorer au fur et à mesure que le DNN model s'affine par Deep Learning, mais sur la performance. C'est là qu'entre en jeu la fameuse unité OFA décrite dans la page architecture.
![DLSS 3 [cliquer pour agrandir]](/images/stories/articles/gpu/ada_lovelace/dlss3_principe_t.jpg "Même pas cap' de cliquer")
Cette dernière va analyser deux images séquentielles dans le jeu et calcule un champ de flux optique. C'est en fait une sorte de carte sur laquelle vont être positionnées la direction et la vitesse à laquelle les pixels se déplacent entre l'image 1 et l'image 2. L'unité OFA est capable de capturer des informations au niveau du pixel telles que des particules, réflexions, ombres et éclairage, qui ne sont pas inclus dans les calculs de vecteur de mouvement du moteur de jeu.
![Suivi des vecteurs de mouvement [cliquer pour agrandir]](/images/stories/articles/gpu/ada_lovelace/dlss3_principe5_t.jpg "Enlarge your pe...icture")
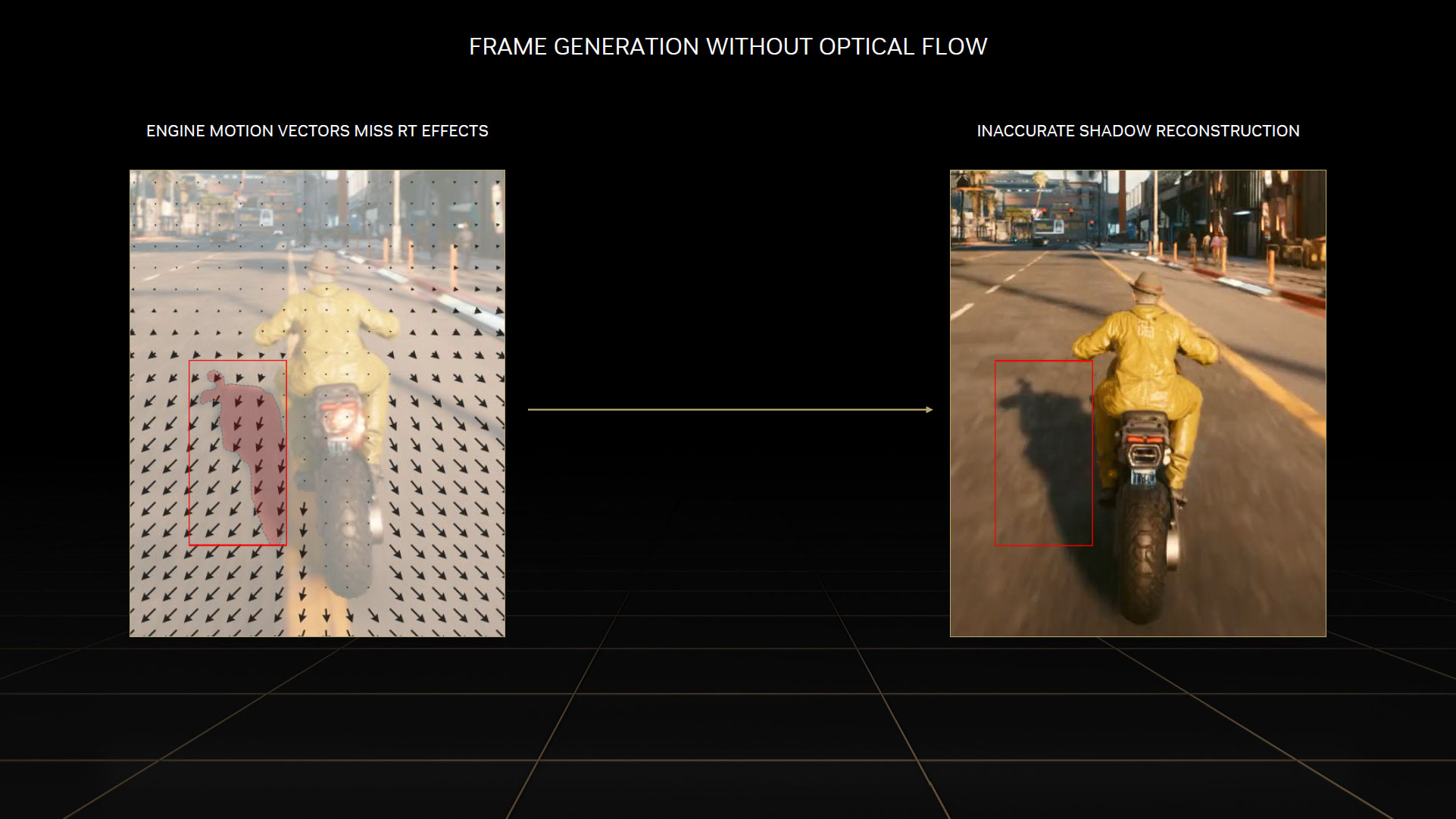
Le DLSS 3 utilise (à l'instar de la version 2) également ces vecteurs de mouvement, pour suivre avec précision les déplacements géométriques au sein de la scène. Dans l'exemple ci-dessous, les vecteurs de mouvement suivent avec précision la route passant devant le motard, mais pas son ombre qui est en réalité fixe par rapport à la position de la moto. La génération d'images à l'aide des seuls vecteurs de mouvement du moteur 3D, risquerait donc d'entraîner des anomalies visuelles, telles que le clignotement de cette ombre par exemple.
![Suivi de la géométrie du moteur 3D en parrallèle [cliquer pour agrandir]](/images/stories/articles/gpu/ada_lovelace/dlss3_principe6_t.jpg "Enlarge your pe...icture")
Pour chaque pixel, le DLSS 3 va donc "décider" avec l'appui de l'IA, de la meilleure façon d'utiliser toutes ces données collectées pour générer des images intermédiaires cohérentes. Il ne s'agit donc pas ici d'ajouter artificiellement des images pour gonfler les performances, sinon ce serait la foire aux artefacts visuels.
![Association des données collectées [cliquer pour agrandir]](/images/stories/articles/gpu/ada_lovelace/dlss3_principe7_t.jpg "Si vous cliquez, vous cliquez.")
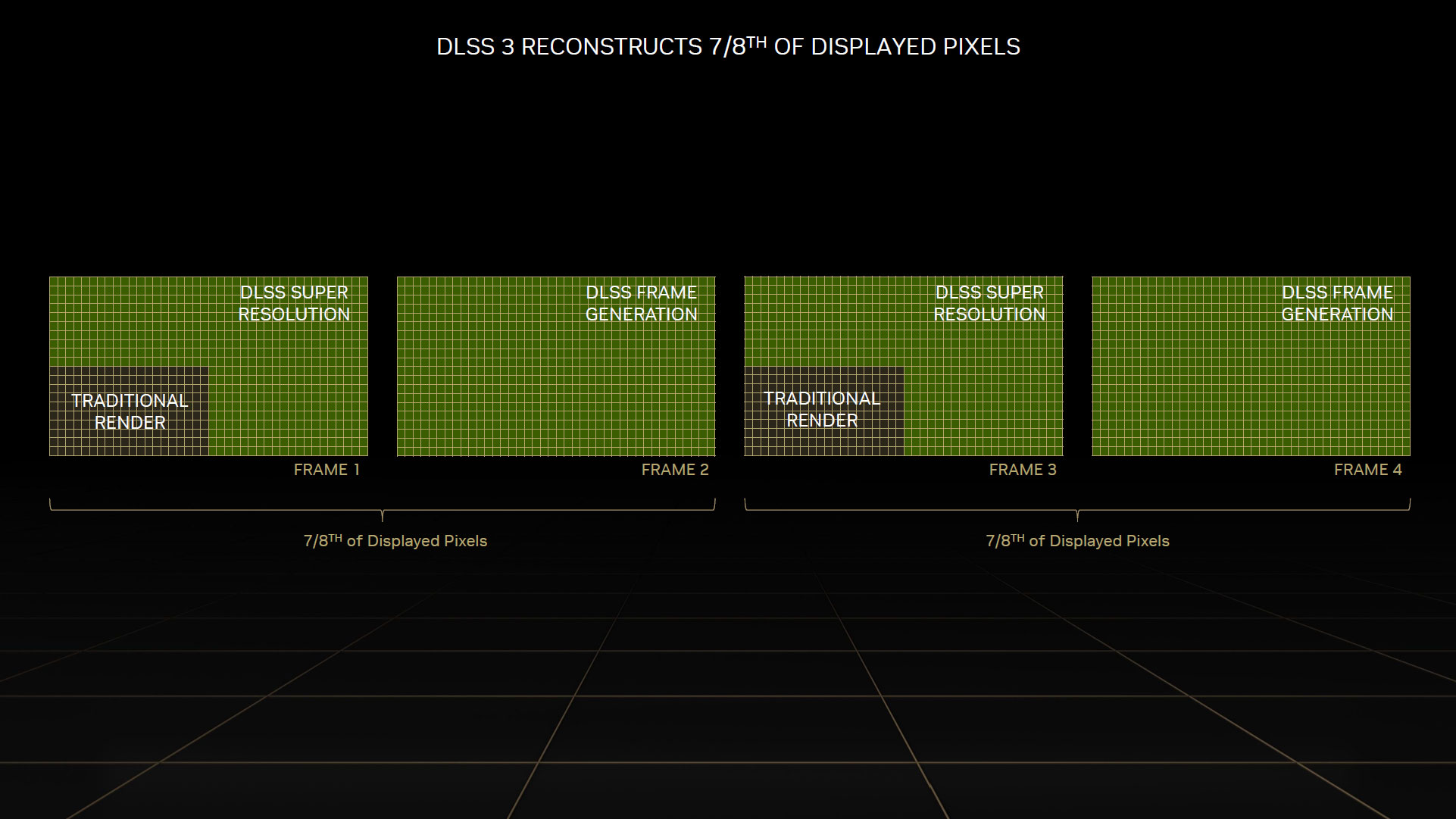
Comme vous pouvez vous en douter, cette technique lorsque fonctionnelle est redoutable, puisqu'aux gains liés à l'upscaling, il faut ajouter ceux liés à la génération d'une image intermédiaire. En pratique, les sept huitièmes que constituent deux images consécutives ne sont pas rendu, mais générés par le DLSS 3. Reste à vérifier l'impact visuel, ce que nous allons faire page suivante. Autre effet positif, la charge de rendu traditionnel est fortement réduite, allégeant le nombre d'appels à rendu à produire pour le CPU, qui devient alors moins limitant.
![Les gains liés au DLSS 3.0 [cliquer pour agrandir]](/images/stories/articles/gpu/ada_lovelace/dlss3_principe2_t.jpg "La magie de la loupe, sans loupe")
Pour parfaire l'expérience de jeu et éviter une latence accrue consécutive à cette insertion d'images, le DLSS 3 intègre nativement Reflex au sein du pipeline. Voici résumé en un slide les différentes "pierres" logicielles et matérielles mises en œuvre pour le DLSS 3. Que l'on aime ou pas la société, il faut bien reconnaitre que ses équipes travaillent d'arrache pied pour proposer des solutions innovantes et très évoluées technologiquement.
![Les différentes pierres logiciels et matériels du DLSS 3.0 [cliquer pour agrandir]](/images/stories/articles/gpu/ada_lovelace/dlss3_principe4_t.jpg "La magie de la loupe, sans loupe")
Dernière question que l'on est en droit de se poser, pourquoi limiter le DLSS 3 aux seuls cartes Ada alors que l'unité OFA est présente depuis Turing ? Selon Nvidia, cela s'expliquerait par les performances respectives de chaque implémentation. La version Turing n'aurait des capacités réellement exploitables que pour les flux vidéos, et celle d'Ampere ne disposerait pas d'un débit adapté à une analyse suffisamment précise des images rendues.
Techniquement, il serait donc possible de faire fonctionner le DLSS 3 avec des cartes de génération précédente, mais la qualité s'en ressentirait avec la présence d'artefacts visuels. C'est en tout cas l'affirmation des verts, même si elle est difficilement vérifiable, elle ne parait pas aberrante pour autant. Quoi qu'il en soit, toute belle que puisse être une solution sur le papier, ce qui compte en définitive, c'est le résultat obtenu en pratique : quid des premières implémentations du DLSS 3 ?
|
|