Test • RADEON RX 480 |
————— 29 Juin 2016



Test • RADEON RX 480 |
————— 29 Juin 2016
Le voici enfin ce nouveau GPU dont AMD parle depuis janvier ! Si le département marketing lui a trouvé un non qui claque avec Polaris 10 (puisqu'une version 11 plus petite sera également lancée sous peu), il dispose toutefois d'un nom de code correspondant comme à l'accoutumée à une île, en l'occurrence Ellesmere située dans l'océan arctique (logique puisqu'il fait parti de la série Arctic Island). A l'image de la génération Pascal du concurrent, ces GPU étaient très attendus par les amateurs pour deux raisons : d'une part l'évolution de l'architecture avec GCN dans sa 4ème itération, mais aussi (enfin) le passage à un nouveau procédé de gravure !
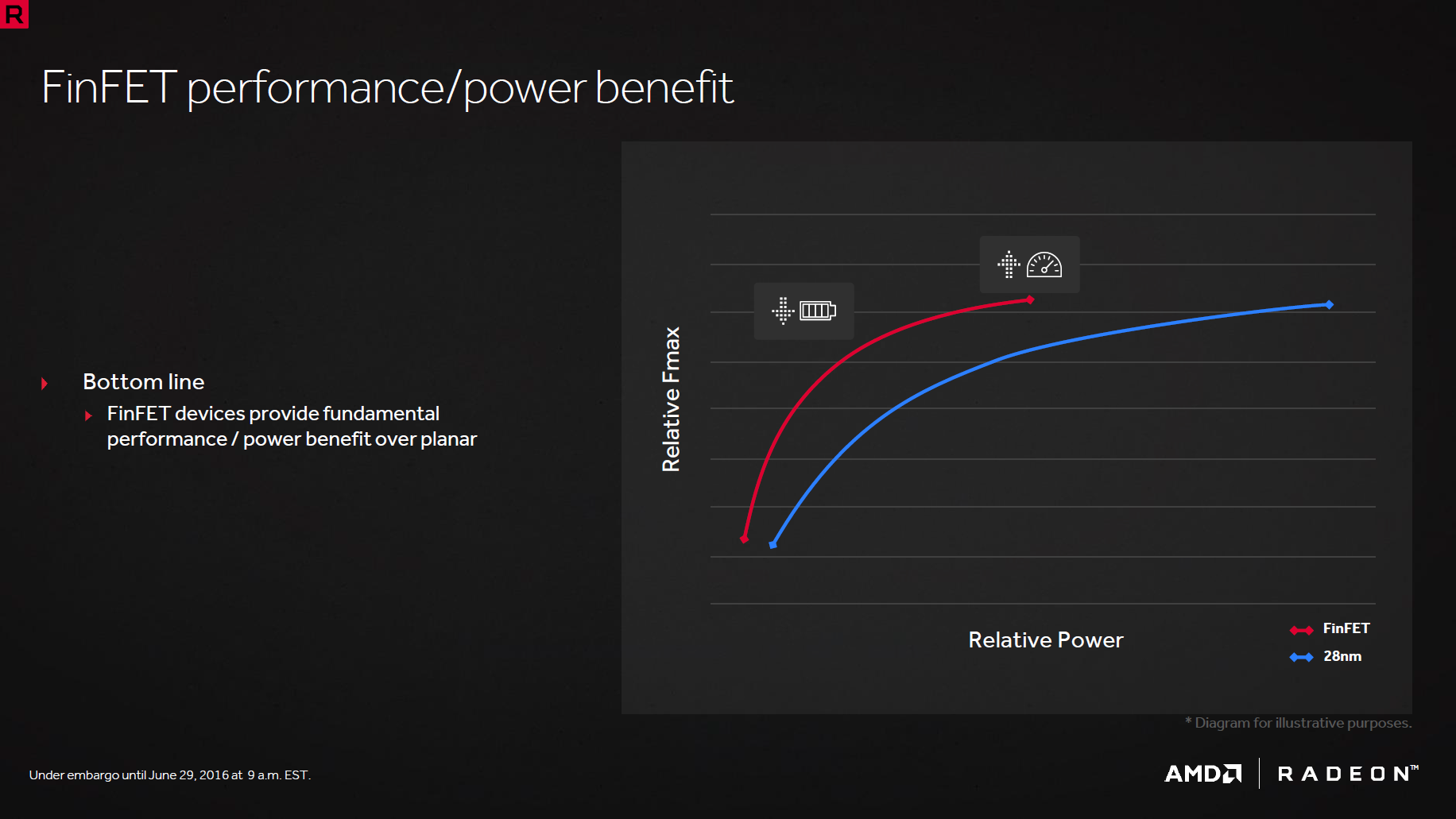
![FinFET [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/finfet_t.png "Enlarge your pe...icture")
![FinFET [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/finfet2_t.png "Enlarge your pe...icture")
En effet, exit le 28 nm de TSMC et place à un 14 nm réalisé par Global Foundries sous licence technologique Samsung. Par rapport au 16 nm de TSMC utilisé par le concurrent, AMD indique un avantage de 8% en terme de densité de transistors même si ce point n'est qu'une composante définissant la qualité du process ( quid de la montée en fréquence et consommation par exemple ?). Point commun aux deux procédés concurrents, le FinFET, c'est à dire l'utilisation de transistors "3D" permettant de réduire les courants de fuite et augmenter significativement les fréquences. Par contre, à contrario des verts qui avait inauguré leur nouveau process avec une puce très complexe (GP100 mesurant plus de 600 mm²), les rouges sont beaucoup plus mesurés avec une puce de "seulement" 232 mm² pour 5.7 Milliards de transistors. C'est donc notablement plus petit que le GP104 des GTX 1070/1080 (7.2 Mds de transistors pour 314 mm²), AMD ne cherche donc pas à se battre avec ces cartes d'un strict point de vue des performances. Poursuivons avec une vue du die de Polaris 10 :
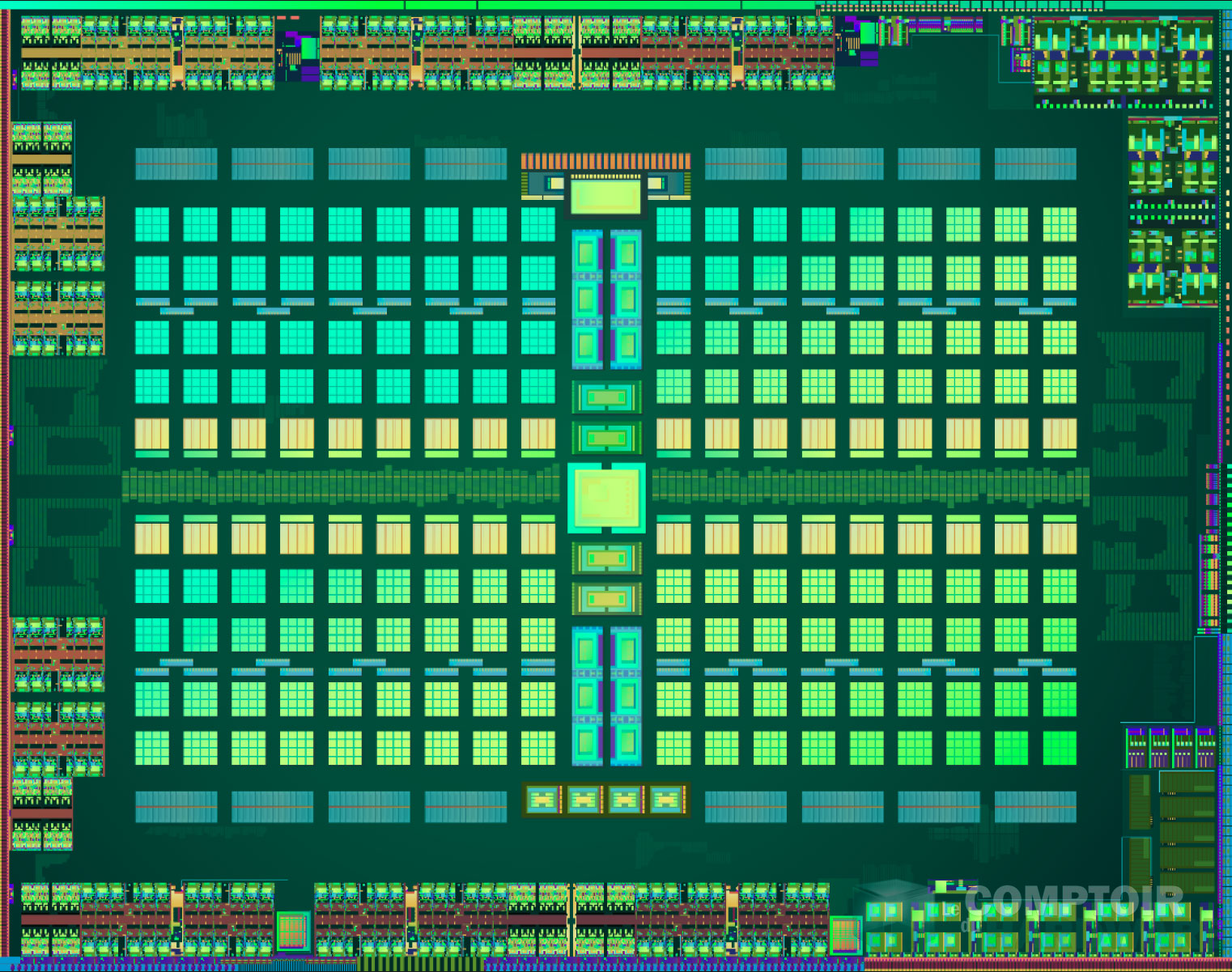
![diagramme logique de polaris 10 [cliquer pour agrandir]](/images/stories/_cg/polaris/polaris_10_diag_t.jpg "La magie de la loupe, sans loupe")
Die de Polaris 10
Une bien belle image mais à quoi avons nous droit en pratique avec ces 5.7 Mds de transistors ? AMD s'appuie toujours sur GCN (Graphics Core Next) et en profite d'ailleurs pour nommer les différentes révisions, chose qu'il s'était toujours refuser à faire précédemment. Nous en sommes donc à la version 4 et le concepteur en profite pour indiquer les 4 principes (ça tombe bien, hein !) retenus pour développer les puces Polaris.
![les 4 principes retenus par AMD pour l'architecture polaris [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/polaris_flip1_t.jpg "Cliquédélique !")
![4e génération GCN [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/polaris_flip2_t.jpg "Ne pas appuyer ici")
Evolution GCN et les 4 principe de Polaris
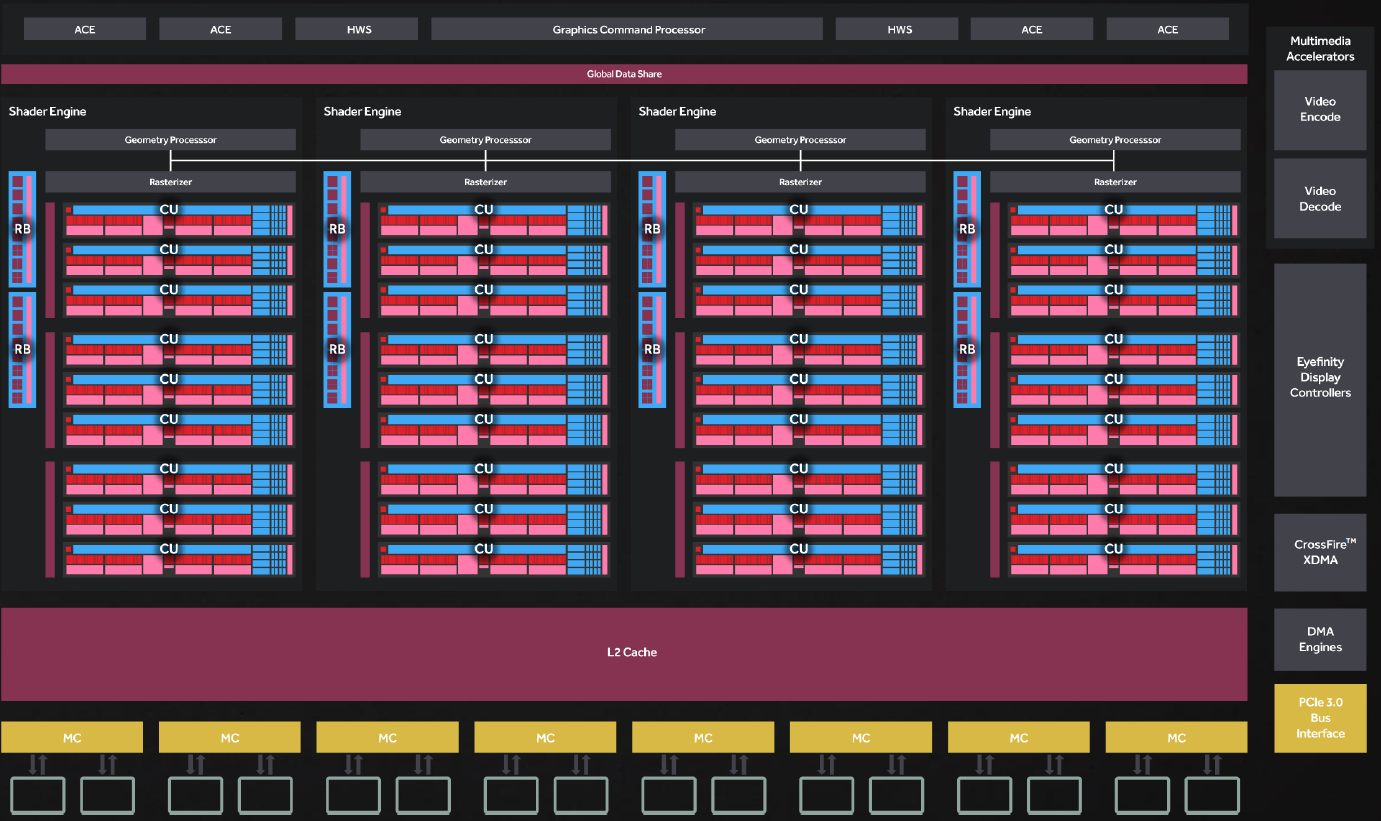
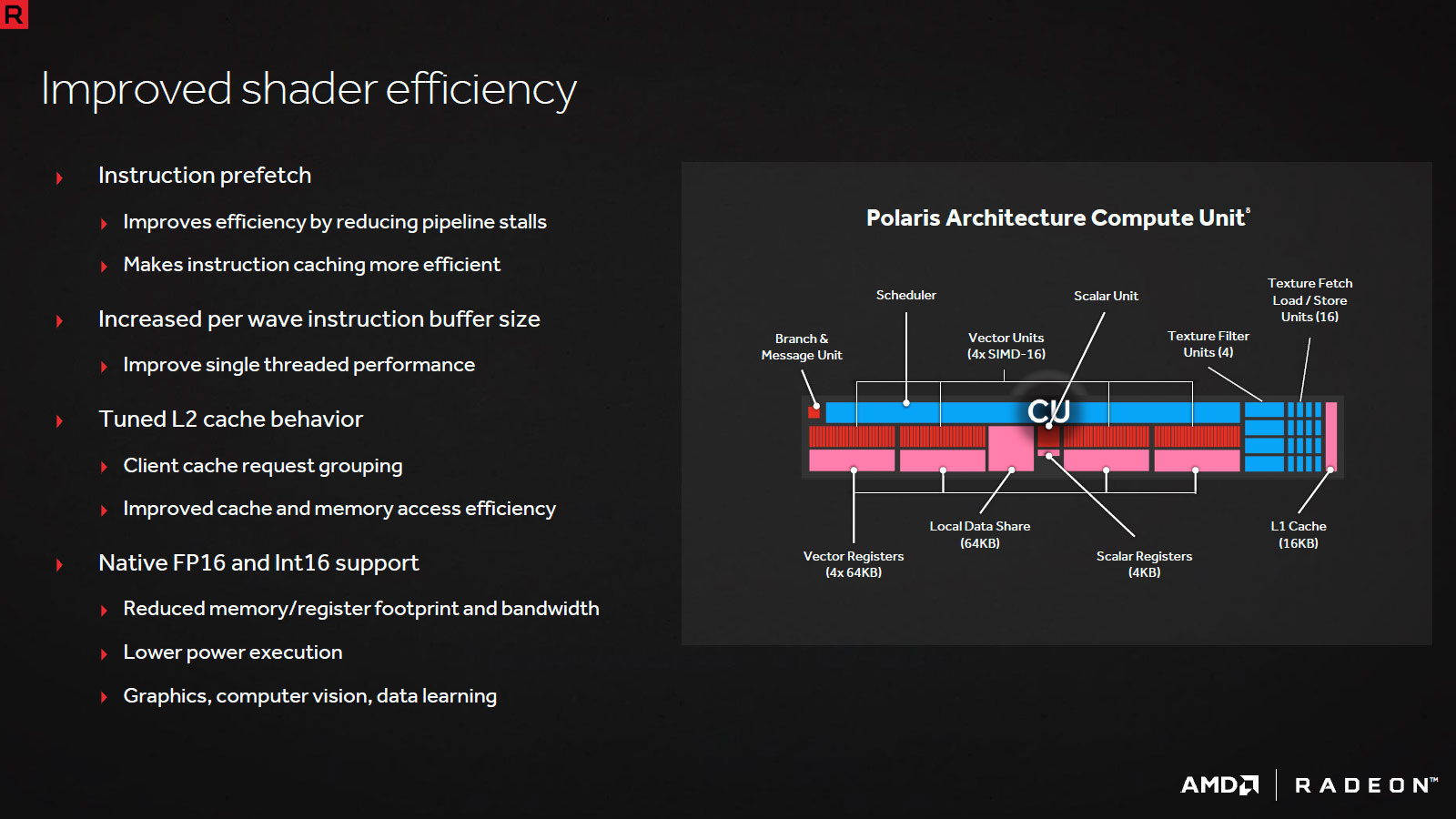
Passons à présent au diagramme logique du GPU. Pas de refonte profonde de l'architecture, AMD s'appuie toujours sur des structures internes nommées Shader Engine. Ces dernières comprennent les unités géométriques (génération des triangles, tesselation) et de rastérisation (transformation des triangles en pixels), les ROP (unités écrivant en mémoire) et les CU (Compute Unit) qui sont dédiées au calcul et au texturing.
![Diagramme logique P10 [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/diagram_t.png "Cliquédélique !")
Diagramme logique de Polaris 10
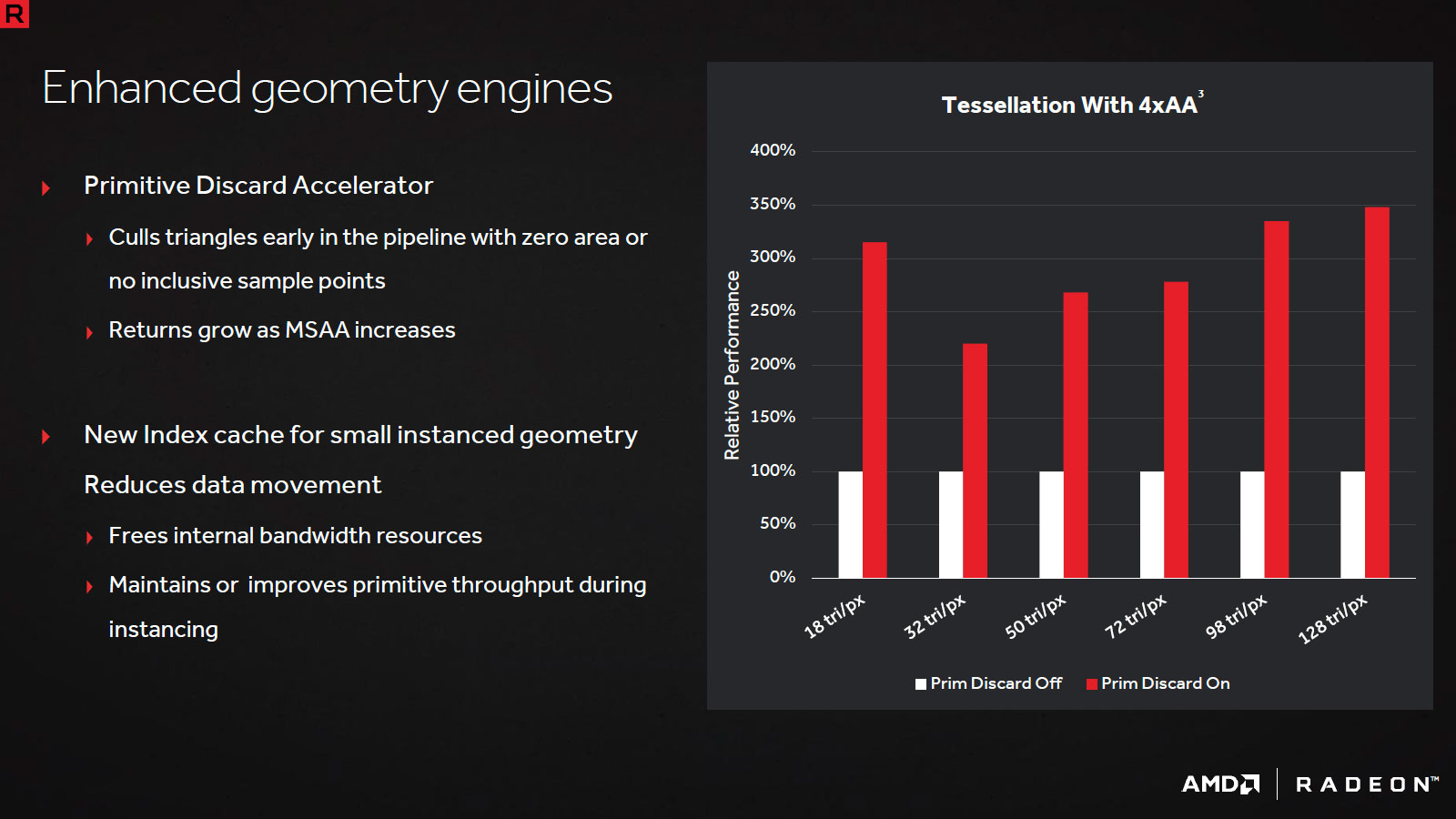
A l'instar des dernières création d'AMD (Tonga et Fiji), on reste à 4 Shader Engine ce qui implique un maximum de 4 triangles par cycle. Notons tout de même que les unités géométriques progressent légèrement afin d'éviter de saturer les buffers lors d'un usage extrême de la tesselation, via le Primitive Discard Accelerator chargé d'éjecter très rapidement les primitives dans ce cas particulier. Du côté des CU, leur efficacité est en hausse par le biais de buffers élargis et d'un prefetch optimisé, enfin l'accès au cache L2 et donc à la mémoire a été amélioré.
![plus de perfs en géométrie par la réduction des données transférées dans le moteur de rendu [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/polaris_flip5_t.jpg "Même pas cap' de cliquer")
![plus d'efficacité dans le pipeline de Polaris... [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/polaris_flip6_t.jpg "Ne pas appuyer ici")
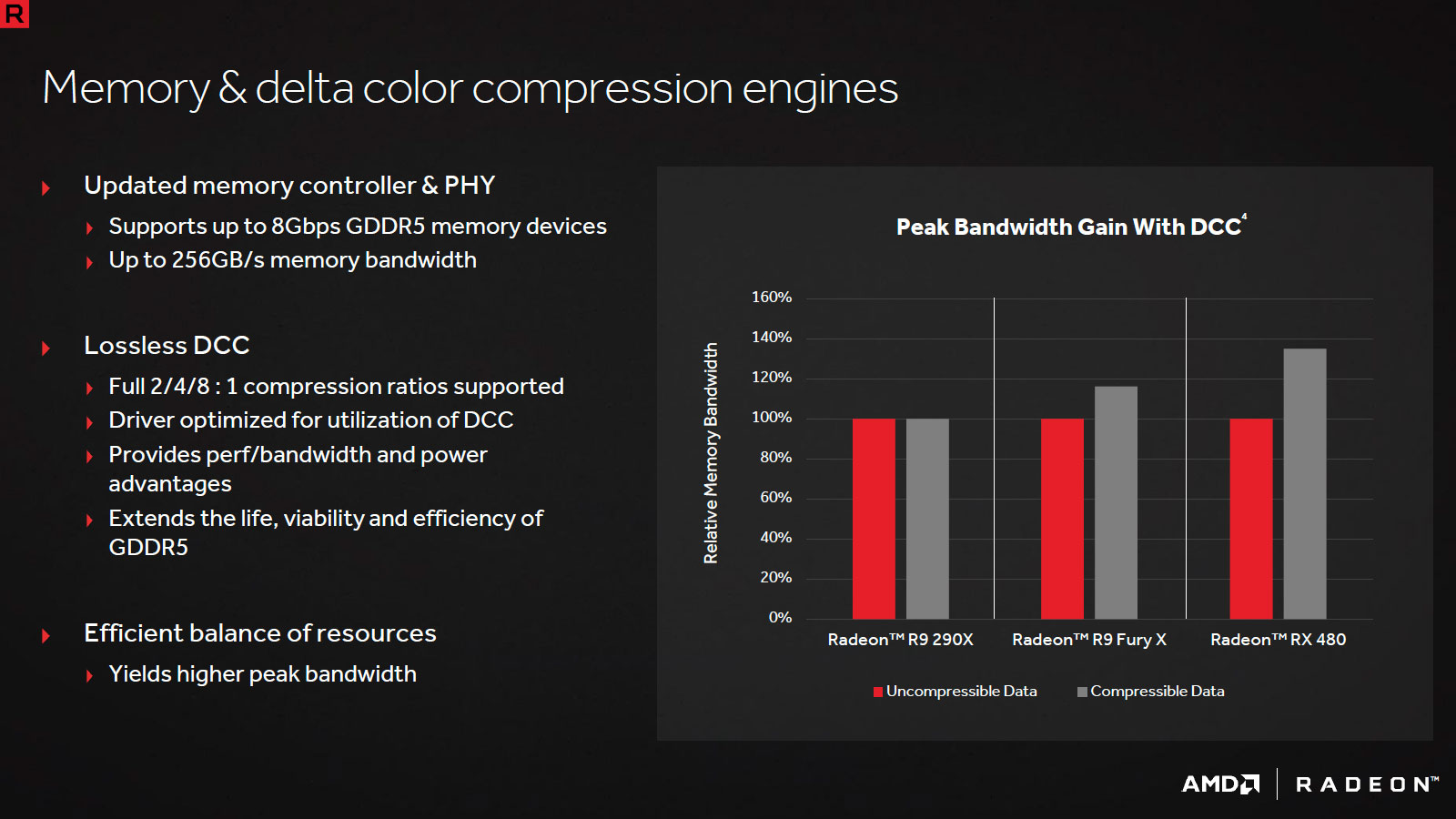
Tout ceci permettrait selon AMD une augmentation de 15% de l'efficacité des CU par rapport aux versions précédentes. Du côté de l'interface mémoire, vu la taille de la puce, les rouges se contente de 32 ROP associés à une largeur de bus 256-bit, mais la compression Delta Color (codage différentiel des couleurs) progresse également pour augmenter la bande passante effective.
![...vraiment plus efficace qu'ils disent ! [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/polaris_flip7_t.jpg "Ultra bouzotron HD max def")
![un moteur de compression amélioré, comme chez les verts. [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/polaris_flip8_t.jpg "Visionner en grand sur un magnifique pop-up")
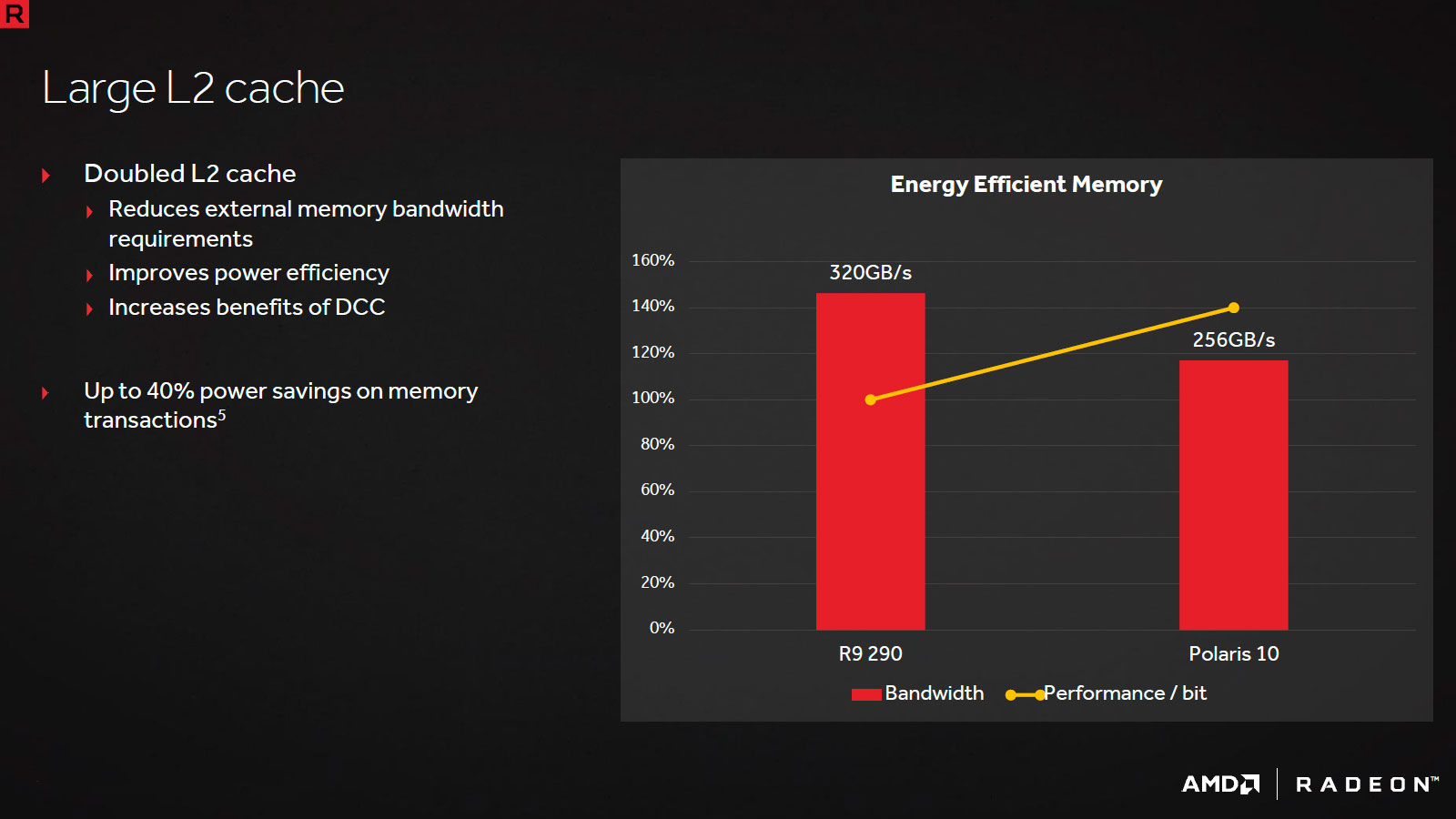
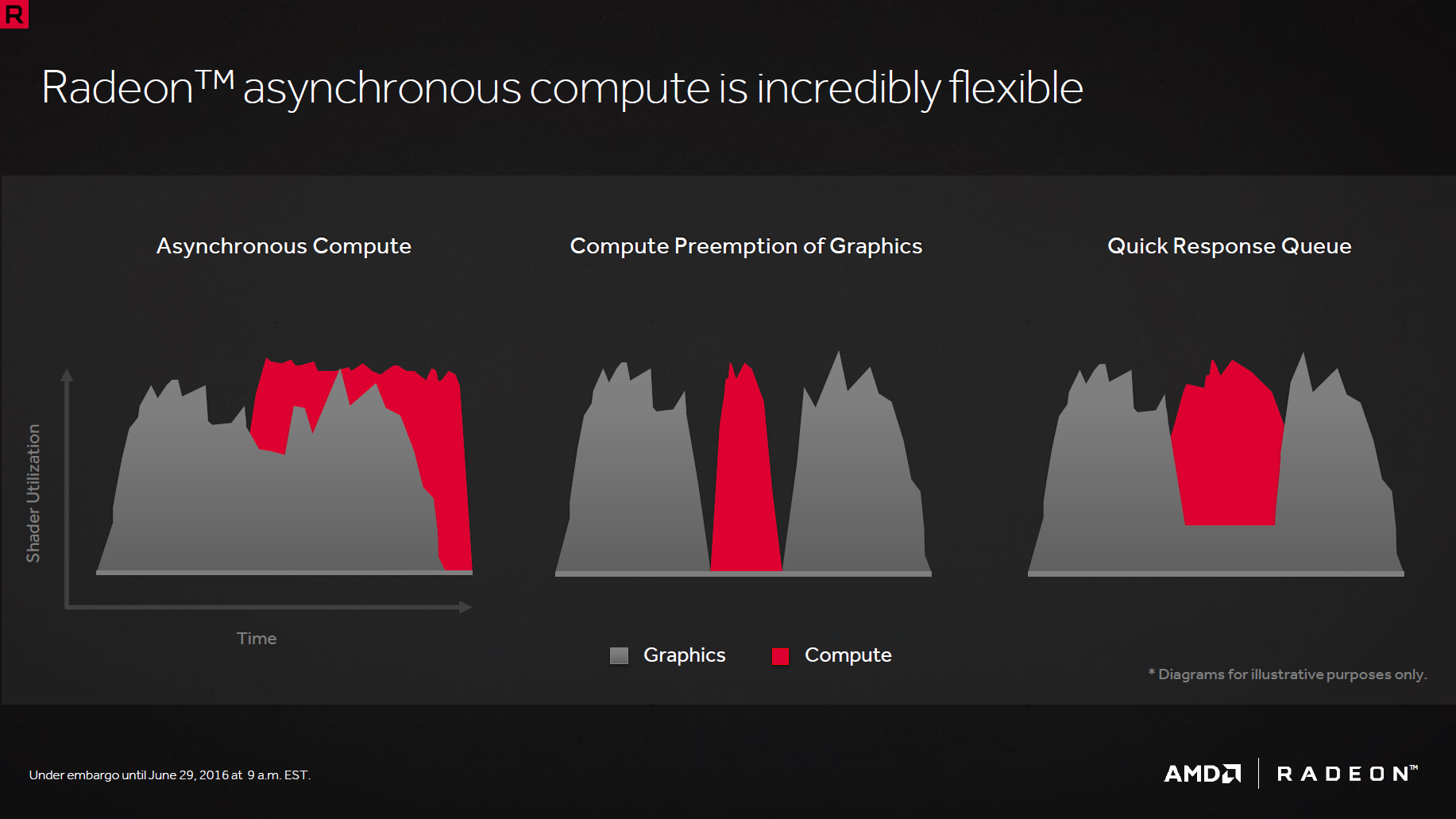
A l'instar de ce qu'avait fait le concurrent avec Maxwell, le cache L2 est porté à 2 Mo afin d'améliorer le rendement des contrôleurs mémoires et réduire la consommation. L'effet cumulé de ces 2 points permettrait un gain de 40% à ce niveau par rapport à Hawaii (qui ne dispose pas de compression delta color). Du côté des Async Compute, AMD propose en sus des modes concomitants et préemption (arrêt d'une tâche pour traiter en priorité une autre) un mode Quick Response Queue qui permet cette fois d'attribuer arbitrairement plus des ressources à une tâche compute traitée en concomitance avec d'autres afin d'accélérer son traitement.
![un cache L2 doublé, enfin ! [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/polaris_flip9_t.jpg "Enlarge your pe...icture")
![async [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/async_t.png "Ultra bouzotron HD max def")
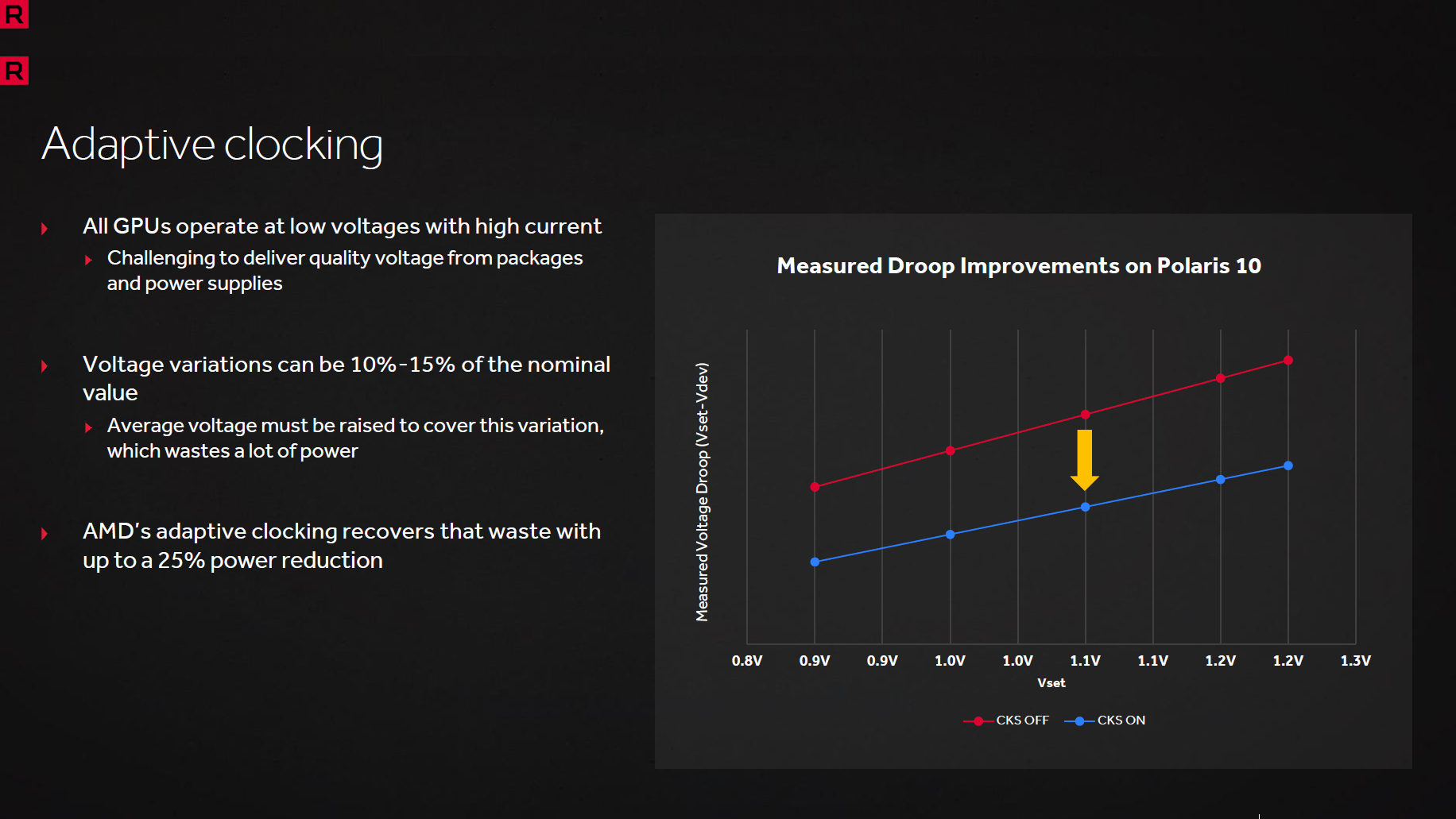
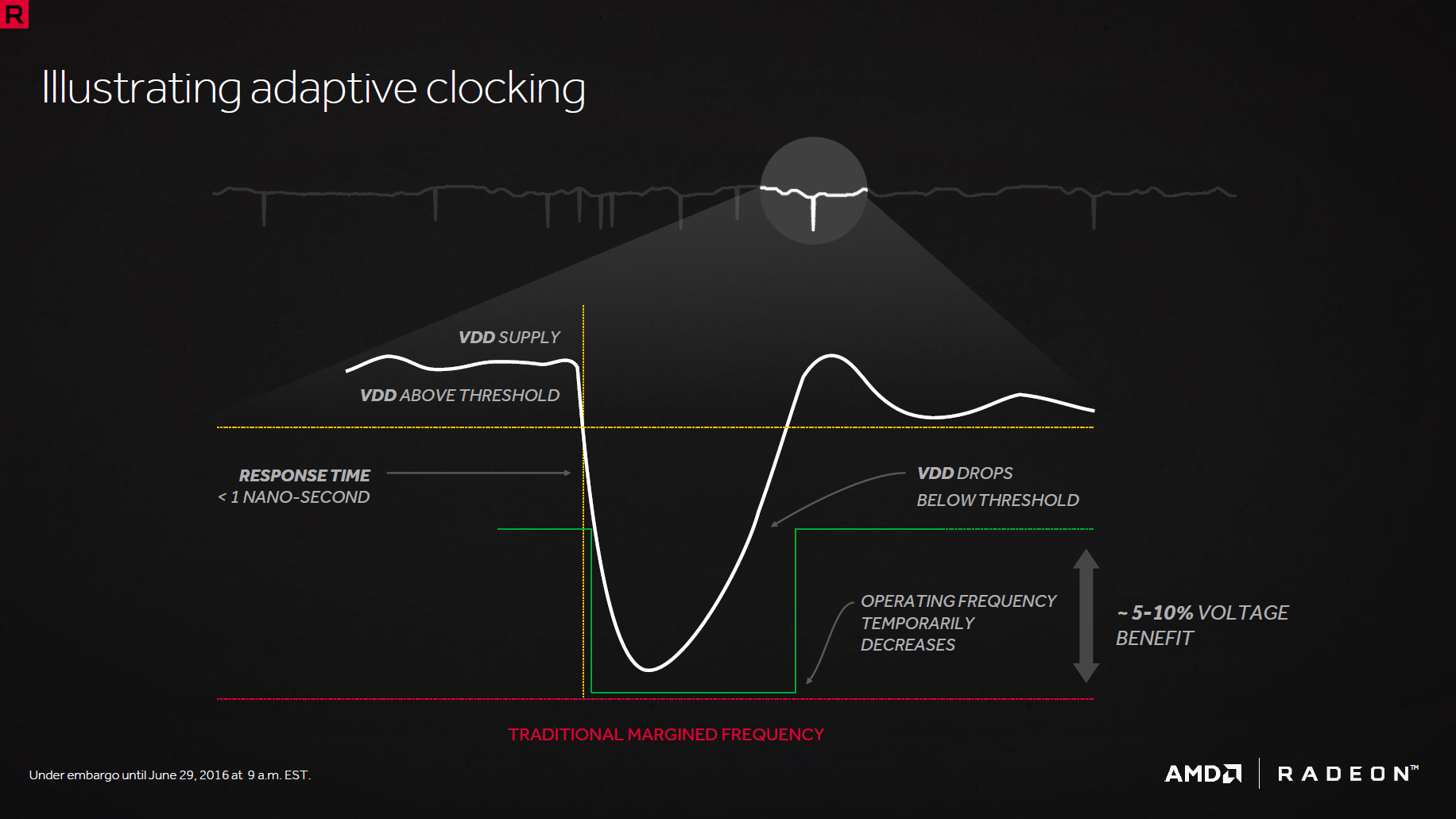
AMD n'a pas oublié le gros point faible de son architecture face au concurrent à savoir l'efficacité énergétique. En sus de l'action au niveau de l'interface mémoire, Il ne s'est donc pas contenté des gains apportés par le process mais a mis en place toute une série de technologies destinées à améliorer ce point. Commençons par l'adaptative clocking qui induit une baisse de fréquence (inférieure à 1 ns) du GPU pour permettre de compenser les chutes de tensions survenant au niveau de l'alimentation GPU. De quoi réduire la marge de sécurité de cette dernière et donc la tension de 5 à 10% .
![adaptativeclocking [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/adaptativeclocking1_t.png "Visionner en grand sur un magnifique pop-up")
![adaptativeclocking [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/adaptativeclocking_t.png "Cliquédélique !")
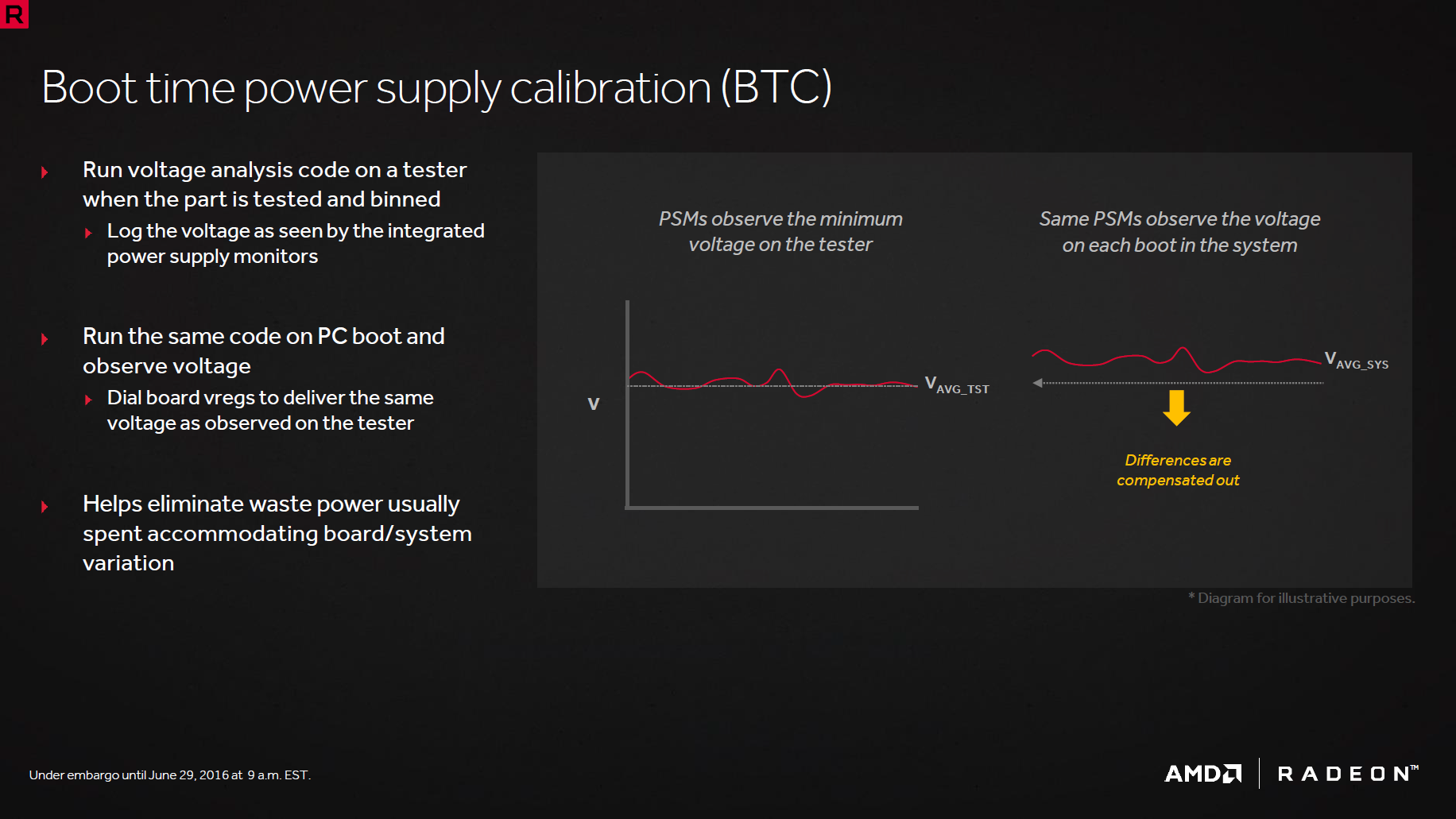
Poursuivons avec l'AVFS pour adaptative voltage & frequency scaling. Kesako ? AMD a en fait ajouté des capteurs de fréquence et tension à divers emplacements de la puce lui permettant de définir la tension idéale en fonction de sa "qualité". Il s'agit donc d'une individualisation des puces, certaines pourront donc être meilleures que d'autres et profiter de ce fait de gain de consommation au lieu de se voir attribuer par défaut la tension correspondant au cas le plus défavorable. Vient ensuite le BTC qui reprend le principe de l'auto-détermination mais appliqué à l'étage d'alimentation permettant ainsi d'éviter là-aussi des marges de sécurité induisant des surconsommations, l’information étant remontée à l'AVFS.
![avfs [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/avfs_t.png "Enlarge your pe...icture")
![btc [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/btc_t.png "Cliquédélique !")
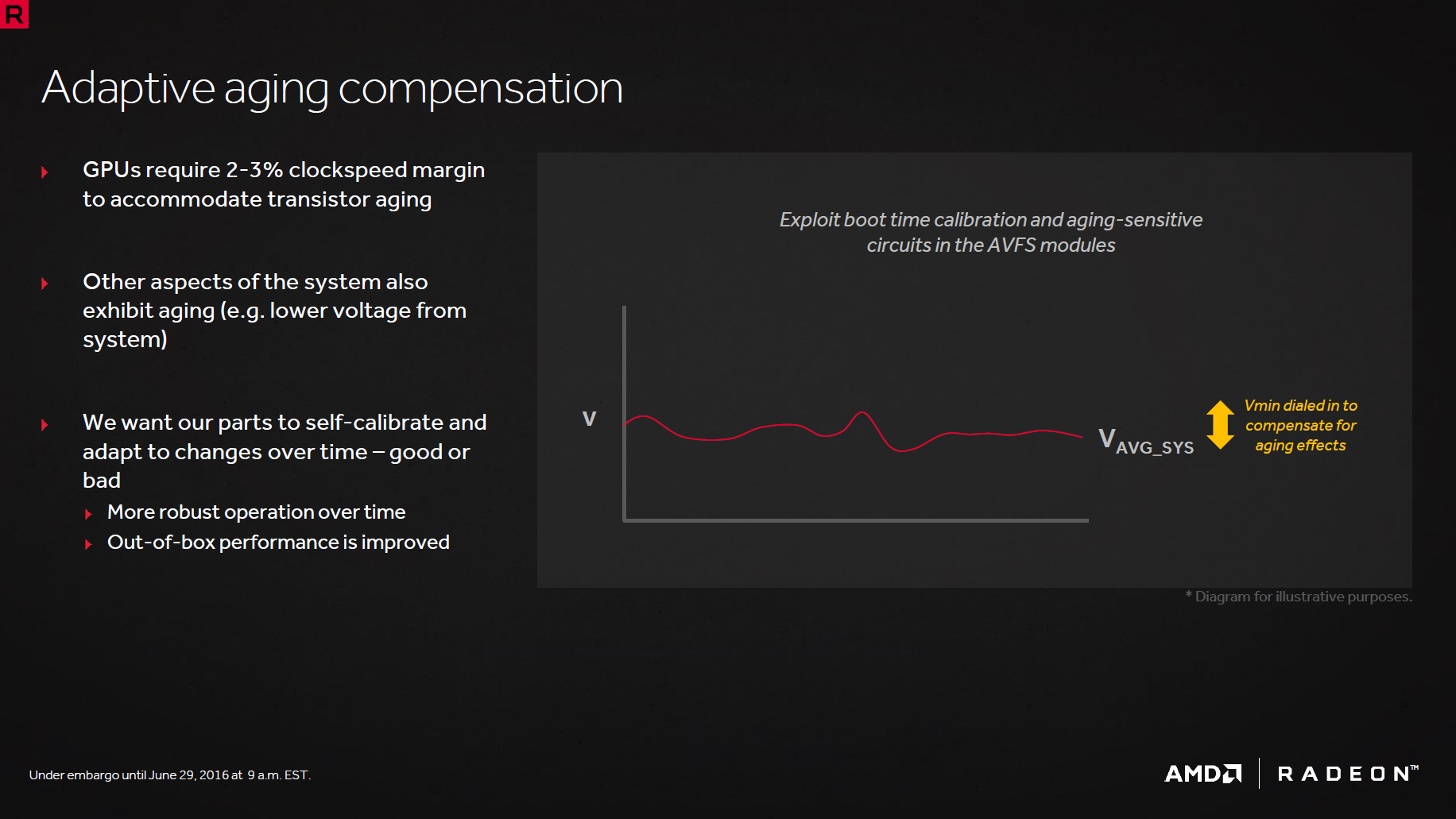
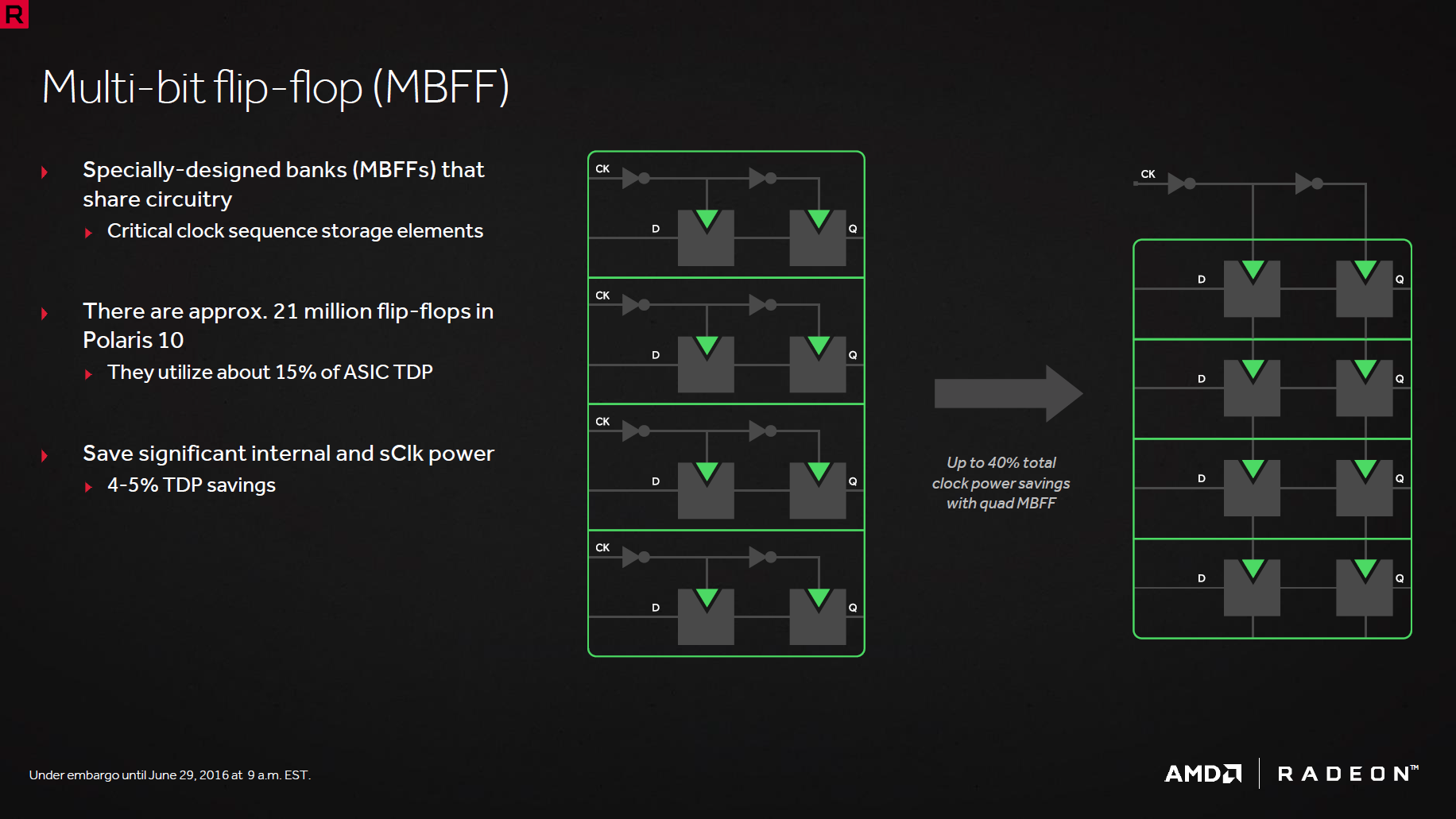
Finissons ce point d'optimisation énergétique avec les 2 derniers éléments sur lesquels communique AMD : l'adaptative aging compensation permet de supprimer la marge de sécurité normalement appliquée pour compenser le vieillissement des transistors. Cette dernière disparaît puisque le GPU s'autocalibre et enverra à l'AVFS une information demandant une augmentation de tension si le besoin s'en fait sentir au cours de la vie du GPU. Cela permet des gains dans l’immédiat mais la puce peut s'avérer moins économe en vieillissant. Enfin, le MBFF (Multi-bit-flip-flop) permet de gagner 4 à 5% au niveau de la consommation du GPU en optimisant les changements d'états qui correspondent, mine de rien, à 15% de la consommation totale de la puce.
![agingcomp [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/agingcomp_t.png "La magie de la loupe, sans loupe")
![mbff [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/mbff_t.png "Ultra bouzotron HD max def")
Terminons le tour des évolutions apportées par Polaris 10 avec un moteur vidéo enfin au goût du jour puisque AMD rattrape son retard sur NVIDIA en proposant le HDMI 2.0b incluant l'HDCP 2.2 nécessaire pour visualiser certains Blu-ray UHD. Pour le Display Port, il est prêt pour les normes 1.3 et 1.4, c'est à dire le 5K en 60 Hz pour le premier et l'HDR 10-bit en 4K jusqu'à 96 Hz pour le second. Côté encodage/décodage, la prise en charge du HEVC jusqu'en 4K 60 Hz ainsi qu'un nouvel algorithme destiné à améliorer la qualité des vidéos encodées via 2 passes.
![HDR [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/hdr_t.png "La magie de la loupe, sans loupe")
![Decodage [cliquer pour agrandir]](/images/stories/articles/gpu/rx480/images/decodage_t.png "Ne pas appuyer ici")
Voilà, c'est tout pour Polaris, passons aux spécifications des cartes employant ce nouveau GPU.
|
|
| Un poil avant ?Les waterblocks EK pour GP104 arrivent dans le commerce | Un peu plus tard ...Microsoft ajouterait un bouton pour refuser l'offre de mise à jour vers Windows 10 | |