Il est déjà là, le die shot de RDNA 3, avec tout plein de rumeurs sur son architecture |
————— 05 Novembre 2022 à 19h15 —— 25535 vues



Il est déjà là, le die shot de RDNA 3, avec tout plein de rumeurs sur son architecture |
————— 05 Novembre 2022 à 19h15 —— 25535 vues

Alors que le concurrent bleu n’est pas vraiment fan des dies shots de produits tout juste voire pas encore sortis (nous n’y sommes presque pour rien), voilà que du côté rouge, rien n’est fait pour conserver la chose secrète, loin de là. En effet, une photo du CGD (die de calcul) était présente en relativement haute définition dans la présentation des nouvelles RX 7900, de quoi laisser le cher @Locuza_ travailler sur ses annotations habituelles… ce qui réserve bien des surprises ! Si nous apprenions via le mystérieux Cortek que, selon ses sources, les fréquences n’augmenteraient que de 3 % en overclocking, ce n’est pas la seule caractéristique étonnant à première vue de la puce.
![Ouh my god que c'est beaucoup de pixels pour un die shot ! [cliquer pour agrandir]](/images/stories/_cg/navi3x/navi31-die-shot-locuza_t.jpg "Enlarge your pe...icture")
The N31 reveal got a couple of big surprises, in both good and bad ways.
— Locuza (@Locuza_) November 3, 2022
A good surprise was AMD sharing die shots of Navi31, the GCD and MCD dies!
I took a first look at Navi31, which due to the usual pixel mess is simple and may include misinterpretations.
1/x pic.twitter.com/NFSY1fb4Ub
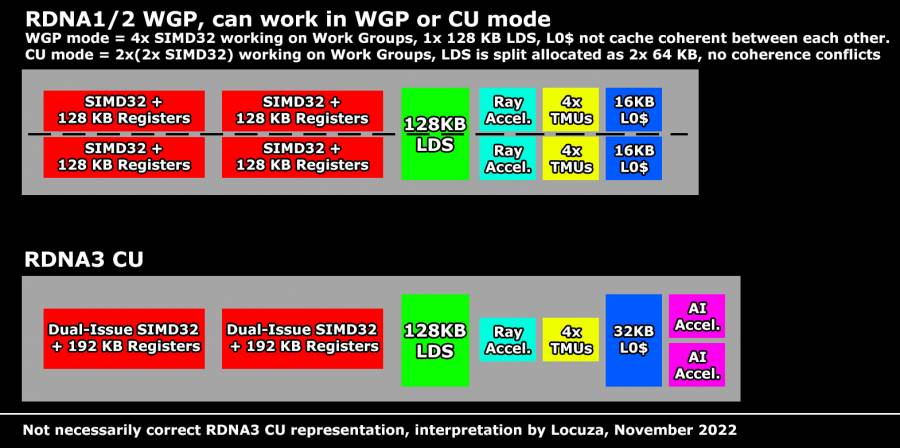
En effet, RDNA 3 ayant abandonné le pipeline legacy, l’agencement de certains composants se retrouve fortement modifié. En particulier, le command front-end est relativement plus petit que sur RDNA 2, laissant penser que les fonctions de calcul géométriques qui y étaient précédemment intégrées sont désormais réalisées entièrement de manière non native par les CU. De plus, le L2 semble avoir une structure légèrement inattendue, car non uniformément dense. Comprenez que les blocs proches des interfaces seraient plus étalés que ceux à la limite du command front-end (carrés non surlignés sur le cliché), peut-être du fait des connexions non lointaines vers les interconnexions avec les MCD (dies de caches). Les Shader Engines ainsi que les ROP n’évolueraient pas, par contre, le cache des paramètres (un large buffer composé de SRAM sur RDNA 1/2) semblerait absent : soit le bousin a pu être retiré, soit il a pu être explosé et davantage dispersé. Reste encore la question des CU, pour lesquels rien n’est clair : sur les RDNA précédents, deux CU formaient un WorkGroup Processor (WGP), pouvant fonctionner au choix en mode CU pour exécuter des Waves sur 2 modules de 2 SIMD32, ou dans le nouveau mode 4 SIMD32. En mode CU, les mémoires (L0 et LDS) se retrouvent partagées ; il semblerait que l’unification vantée par la firme soit la disparition du premier mode, renommant ainsi les WGP en dual issue CU (et en rajoutant au passage des accélérateurs d’IA). Ce faisant, les unités SIMD32 seraient aussi fusionnées pour fonctionner en dual issue également, mutualisant une partie de leurs ressources (la distribution des instructions ? Un genre de SMT ?) : de quoi afficher 2 FMA par CU et justifier les 12 288 unités FP 32 affichées ici et là pour 6144 CU, sans pour autant que cette performance brute ne soit aisément exploitable en pratique. Pour le moment, tout cela ne reste que pures spéculations, nous attendons avec impatience le whitepaper architectural de la firme afin d'en savoir plus.
Tout cela est également à mettre en relation avec l’interconnect inter-die utilisé. Sur RDNA 3, l’utilisation des pistes du package ne suffisait pas (contrairement à Zen), et une technologie nommée Elevated Fannout Bridge (EFB) est utilisée pour caser un petit die de silicium passif entre les dies (actifs) GDC et MCD. Cela ne vous rappelle rien ? Hé oui, il s’agit bel et bien de l’analogue rouge de l’EMIB, que l’on attend au passage toujours côté grand public — un signe que la technologie n’est peut-être pas encore mature pour atteindre un niveau de performance/prix acceptable. Les premières estimations au doigt mouillé donneraient 20 à 80 W de consommation rien que pour cet interconnect : si cela se vérifiait, cela pourrait expliquer en partie les goulots d’étranglement de la carte empêchant la montée en fréquence au-delà des spécifications. Enfin, l’analyse du die de mémoire confirmerait (avec un bon gros conditionnel) la possibilité de 3D V-Cache à ce niveau, similairement à ce que le Ryzen 9 5800X3D offre sur le plan des CPU. Reste que la technologie est encore coûteuse, et qu’il n’est pas certain que l’assemblage soit cohérent du point de vue de la conception générale du SoC, particulièrement en matière de packaging, de répartition de la chauffe et de ratio final performances/prix. D’un autre côté, la réduction de l’Infinity Cache (passant de 128 Mio sur la RX 6900 XT à 96 Mio sur la 7900 XTX) est fortement suspecte, ce qui pousse en faveur d’un futur (possible) refresh. Reste que un « tiens » vaut mieux que deux « tu l’auras », mieux vaut déjà regarder les performances de la belle avant de fantasmer sur son éventuel successeur !
| Un poil avant ?Après les zombies font du ski, voici les zombies jouent aux chevaliers ! | Un peu plus tard ...Gamotron • Une question de protocole | |





















