3D V-Cache et latence avec un EPYC, y'a bon ? |
————— 17 Janvier 2022 à 09h10 —— 12241 vues



3D V-Cache et latence avec un EPYC, y'a bon ? |
————— 17 Janvier 2022 à 09h10 —— 12241 vues
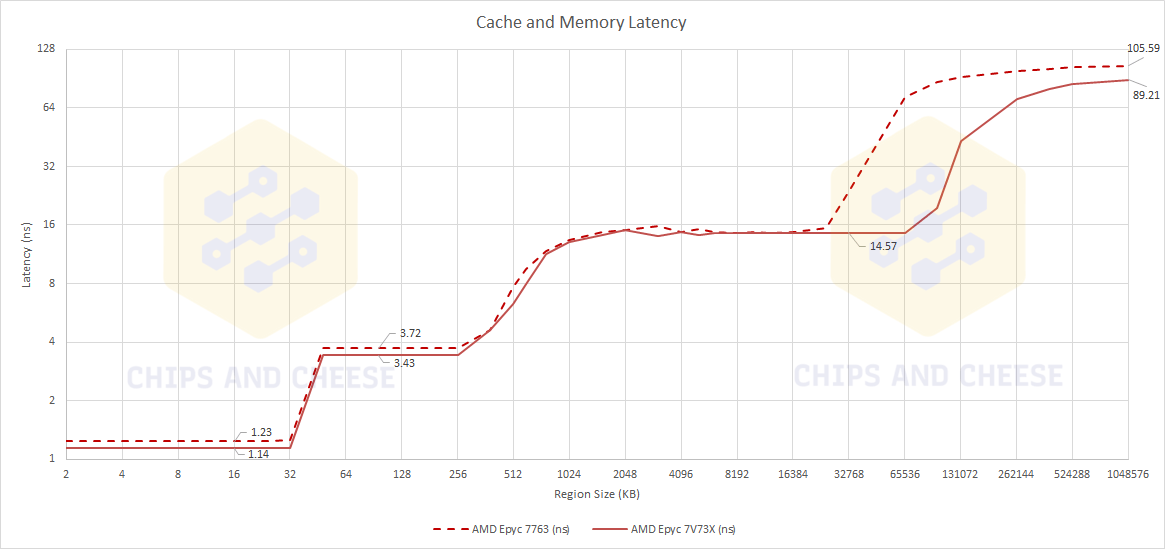
Lorsqu'AMD avait présenté son fameux 3D V-Cache — en principe, basé sur des technologies de packaging 3D de chez TSMC — en juin dernier, outre s'interroger de son impact sur les performances, les spéculations allaient aussi de bon train quant aux conséquences pour la latence du cache et de la mémoire. En effet, avec le processeur ainsi surplombé d'un gros cache additionnel fusé sur le dessus de chaque CCD, il est tout à fait cohérent de penser que cela puisse affecter les latences en question et c'est précisément ce qu'a voulu démontrer Chips and Cheese, en opposant le nouveau EPYC Milan-X 7V73X avec un « ancien » EPYC Milan 7763. Le premier possède 768 Mo de cache L3 grâce aux 512 Mo du 3D V-Cache venus compléter les 256 Mo d'origine, soit 8 chiplets de cache SRAM en 7 nm de 64 Mo chaque, et donc trois fois plus qu'un EPYC 7763.
![milan vs milan-x : latence cache et mémoire [cliquer pour agrandir]](/images/stories/_cpu/7nm_amd/milan-vs-milan-x-3d-vache-cache-memory-latency-test-1_t.png "3N C11QU4N7 C357 P1U5 6r4ND")
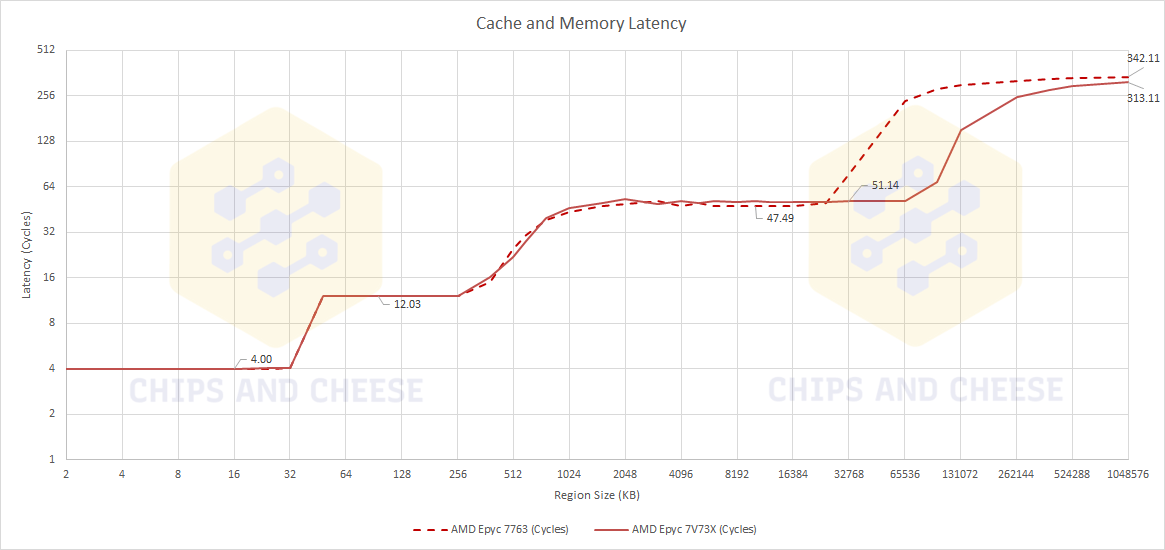
![milan vs milan-x : latence cache et mémoire [cliquer pour agrandir]](/images/stories/_cpu/7nm_amd/milan-vs-milan-x-3d-vache-cache-memory-latency-test-2_t.png "Même pas cap' de cliquer")
Résultat des courses, la comparaison présentée est plutôt impressionnante et l'augmentation mesurée de la latence n'a ici été que de 3 à 4 cycles supplémentaires. Le testeur fait aussi remarquer — sans trop donner de détails — que Milan-X se comporte aussi bien mieux en boost, en dépit de ses fréquences plus basses par rapport à Milan, ce qui a eu pour effet de nullifier l'impact de l'augmentation de la latence.
De toute évidence, AMD a donc effectué un très bon travail - que nous vous avions déjà exploré et raconté en détail plusieurs fois, ici et là. C'est indéniablement une bonne nouvelle et encourageant pour l'avenir du 3D V-Cache, une technologie à laquelle le mainstream pourra prochainement goûter avec le Ryzen 7 5800X3D - et son cache L3 triplé par rapport au 5800X, mais également en contrepartie de fréquences inférieures. Par conséquent, les résultats et le comportement observés avec cet EPYC 7V73X devraient logiquement se retrouver avec le futur 5800X3D - et accessoirement tout éventuel Ryzen subséquent intégrant un 3D V-Cache ! Il reste à voir si cela se traduira effectivement avec les gains annoncés par AMD lors du CES 2022, mais pour l'instant, cela semble bien parti.
| Un poil avant ?Gamotron • Un anneau pour les gouverner tous ou presque | Un peu plus tard ...Les EPYC bientôt plus chers et Sapphire Rapids (encore) retardé ? | |