L'IA et le hardware : et si tout était à recommencer ? |
————— 13 Août 2018 à 13h30 —— 17593 vues



L'IA et le hardware : et si tout était à recommencer ? |
————— 13 Août 2018 à 13h30 —— 17593 vues
Si l'IA cartonne bien sur les cartes graphiques du fait de leur architecture massivement parallèle, ce n'est pas pour autant qu'elles sont les plus adaptées pour ce job. En effet, nombreux sont les chercheurs qui doutent de la capacité des serveurs actuels à traiter massivement les données inhérentes aux problématiques d'apprentissage automatisé ; le fameux machine learning dont les entreprises raffolent à l'heure actuelle. Non pas que la marge de progression soit totalement rognée, mais il s'agirait en fait d'une faiblesse structurelle de nos machine.
En effet, toutes les puces actuelles sont construites suivant un même modèle logique abstrait : une ou plusieurs unités de traitement, reliées à une unique mémoire centrale accessible à tous. Ce modèle est appelé Architecture de Von Neumann en référence à son créateur (mort en 1957, c'est dire l'ancienneté du principe). Si des caches ou des mémoires dédiées ont bien été développés depuis (on pense notamment à la VRAM des cartes graphique ou les cache L1/L2/L3 CPU), il est toujours nécessaire de passer par un bus pour synchroniser les données avec la RAM globale.

Si c'était trop simple, voilà de quoi vous perdre !
Or les réseaux de neurones n'ont pas besoin de tels mécanismes. En fait, il suffit d'une mémoire locale privée à chaque unité de calcul pour retenir les poids des différentes entrées du neurone : on se passe ainsi d'un coûteux accès RAM qui, en plus d'utiliser ce bus global pouvant être encombré, doit sortir du silicium de la puce pour contacter les barrettes, autant vous dire que cela est coûteux en temps comme en énergie.
Le problème est tel que An Chen, un docteur (en informatique !) employé par IBM assigné à la Nanoelectronics Research Initiative va même jusqu'à déclarer que le transistor CMOS ne serait pas la brique de base idéale pour l'IA, car leur vitesse de fonctionnement est structurellement limitée par un effet capacitif, ce qui augmente également sa consommation d'énergie. Des travaux récents sur les Tunnel-FET - TFET - ainsi que les structures à nanotubes permettraient d'améliorer les choses, mais on est encore loin de la production industrielle.
Pour rapprocher le stockage des unités de traitement, les alternatives ne manquent pourtant pas : la HBM est en effet un candidat tout désigné. Dans un avenir plus lointain on pensera à la ReRAM, de la mémoire non volatile basée sur les propriétés conductimétriques d'un matériau ; mais aussi à des mémoires à changement de phase comme la PCM (passage d'un composée d'une phase amorphe à une phase cristalline) ou encore la STT-MRAM, une idée qui utilise quant à elle le spin de particules. Le nec plus ultra de la BX qui tue serait atteint en réussissant à empiler sur l'unité de calcul sa mémoire correspondante, ce qui réduirait l'encombrement et la latence... mais attention à la chauffe !
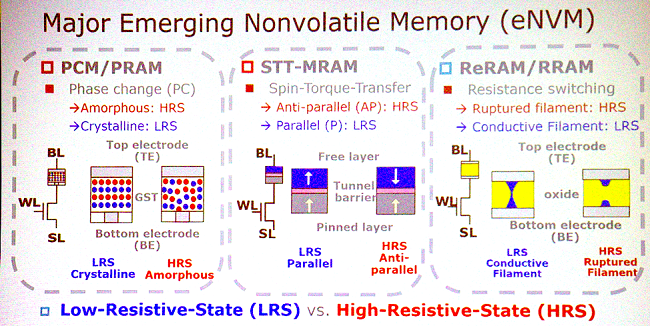
Pas tout suivi ? Un petit récap', sauce scientifique toujours !
Si tout cela paraît bien charmeur sur papier, gardons en tête que la plupart des idées ne sortent pas des labos fautes de moyens ou de rentabilité trop faiblarde. Par exemple, la STT-MRAM que nous citions précédemment était déjà dans le collimateur de Toshiba il y a un peu plus de quatre ans ! Et même si l'idée de calcul-en-mémoire est séduisante, encore faut-il un système, une API et le coûteux investissement qui leur est lié, pour un rentabilité encore incertaine, ce qui doit avoir de quoi refroidir les géants des semi-conducteurs actuels. On en reparle dans 20 ans ?(Source : SemiEngineering)
| Un poil avant ?Seulement 12 cartes mères Z390 à l'horizon chez GIGABYTE ? | Un peu plus tard ...Test • AMD Ryzen Threadripper 2950X / 2990WX | |





















