IA : Groq et ses LPU pourraient bien venir gâcher la fête de NVIDIA et autres vendeurs de GPU |
————— 26 Février 2024 à 12h30 —— 46150 vues



IA : Groq et ses LPU pourraient bien venir gâcher la fête de NVIDIA et autres vendeurs de GPU |
————— 26 Février 2024 à 12h30 —— 46150 vues
Alors que NVIDIA n’en finit plus de fourguer ses GPU à la planète entière et que Jensen a même avoué qu’il avait fallu trouver une méthode « équitable » — au plus offrant sans doute ? — pour décider qui aurait le droit de les acheter, le petit monde de l’IA ne se repose pas sur ses lauriers et de nouveaux acteurs menacent peut-être l’hégémonie des GPU. C’est en tout cas ce que Groq nous fait miroiter avec ses LPU, ou Language Processing Unit, qui reviennent sur le devant de la scène.

Une carte vieille de 4 ans et qui met à l'amende les plus gros GPU ?
C'est possible, dans certains domaines.
Pas un CPU ni un GPU donc, mais une espèce d’hybride à mi-chemin. Un CPU est une puce ultra complexe capable de gérer un très grand nombre d’opérations et qui doit être le plus souple possible dans son exécution. Un GPU, lui, regroupe des unités moins polyvalentes mais en plus grand nombre. Elles seront plus lentes sur certaines opérations mais étant donné qu’un GPU moderne embarque plusieurs milliers d’ALU — Arithmetic Logic Unit — il est communément admis qu’une fraction d’entre elle peut bien fonctionner à demie vitesse pour traiter quelques opérations plus complexes si le besoin s’en fait sentir. Dans les deux cas, une portion du die est dédiée à la prédiction, a l’organisation et au stockage des instructions, ne laissant qu’une part réduite véritablement dédiée à la puissance de calcul. Le LPU de Groq est lui beaucoup plus spécialisé. Il intègre une flopée d’ALU, comme un GPU, mais avec une mémoire directement embarquée sur le die et un minimum de transistors dédiés à autre chose que ces deux fonctions.
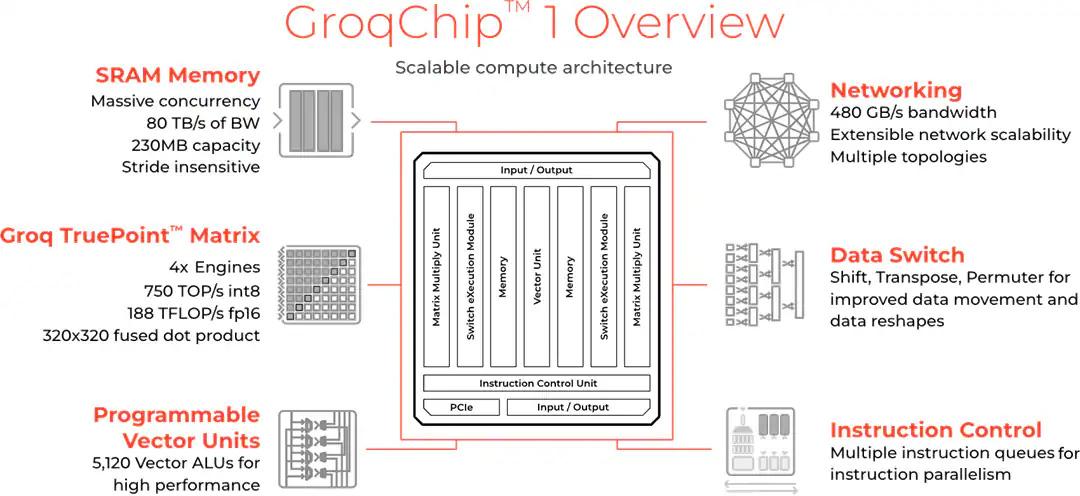
Ceci permet d’une part d’embarquer une mémoire qui fonctionne a 80 To/s, en comparaison du 1 To/s sur une RTX 4090 ou encore 1,7 To/s sur une H100 en HBM3. Cette mémoire ultra rapide permet donc d’éviter le goulot d’étranglement classique des GPU utilisés pour l’IA, mais aussi de fournir aux ALU un flux constant de données afin d’optimiser le rendement de la puce. D’autre part, en faisant la part belle aux ALU et non aux caches et autres jeux d’instructions, Groq peut augmenter le ratio performance/surface de die, et donc le ratio performance/cout.
Ainsi le GroqChip totalise certes 725 mm², une puce plutôt conséquente — le GH100 fait 814 mm² et même l’AD102 de la RTX 4090 totalise 609 mm² — mais qui n’est pourtant gravée qu’en 14 nm chez TSMC. Ceci permet de profiter d’un taux de rebuts minimum et d’abaisser les couts de production au maximum. Elle intègre aussi 230 Mo de SRAM qui peuvent s’assimiler à du cache. Ça parait peu en comparaison des 80 Go de HBM3 des H100 mais c’est ce qui permet d’atteindre une bande passante folle. La start-up a également indiqué vouloir passer au 4 nm au deuxième semestre 2025 si les finances le permettent, ce qui laisse présager de jolis gains du côté du prix et/ou des performances.

Alors en pratique, a quoi ça sert tout ce bazar ? A accélérer les requêtes, c’est-à-dire faire en sorte que votre IA comprenne votre ordre et vous réponde le plus vite possible sans que vous deviez aller boire un café le temps que Chat-GPT ait fini de taper son roman vous expliquant comment il faut faire pour attirer le sexe opposé. Ça parait bête dit comme ça, mais pensez à la traduction en direct. Si vous devez attendre 5 à 10 secondes, ou plus, pour que l’IA vous traduise ce qui a été dit, ça introduit un délai qui fait que la technologie n’est pas vraiment utilisable. A ce compte autant se faire des signes, façon Les Bidochon en vacances. C’est aussi ce qui fait la différence entre un piéton tout plat ou un piéton évité pour l’IA qui pilote votre voiture. Enfin, même dans le monde de la finance et du HFT — High Frequency Trading, qui consiste à profiter de minuscules différences pour faire des profits — chaque milliseconde de gagnée réduit les risques d'accuser une perte sur une transaction.
Il y a toutefois un gros hic, c’est qu’avec 0,23 Go de mémoire, le GroqChip n’est pas du tout adapté au traitement des données, à savoir la phase d’apprentissage du langage. Cette solution ne serait donc pas la réponse à tout. Qui plus est, même pour héberger une API, la quantité de mémoire est tellement réduite qu’il est nécessaire de grouper un grand nombre de ces processeurs afin de mettre en commun suffisamment de mémoire pour abriter l’ensemble du modèle. Pour utiliser Mixtral, il serait donc nécessaire d’associer pas moins de 576 GroqChips alors qu’un à deux H100 suffiraient !
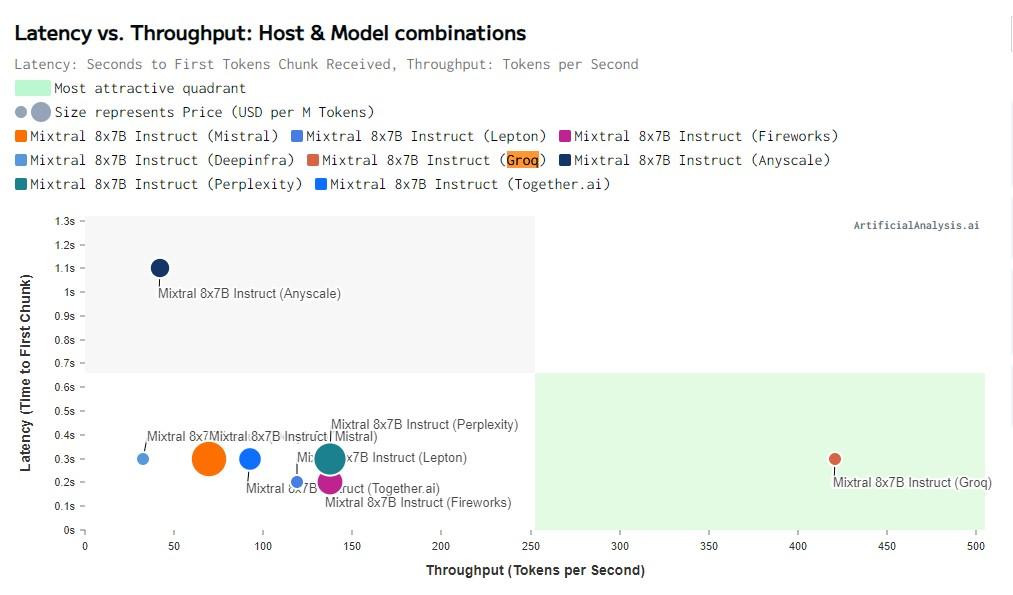
D'après les tests de artificialanalysis.ai, Groq permet d'héberger le modèle Mixtral 8x7B a moindre cout tout en étant le plus rapide par un facteur 3 à 4.
Mais ça n’empêche pas Groq d’enterrer tous les autres acteurs du marché en termes de token par seconde, une métrique importante pour le traitement de l’information. En effet, en IA, un token s’apparente à un bloc élémentaire, par exemple un mot, groupe de mots ou groupe de lettres. Il faut donc décoder ces tokens pour comprendre la requête puis fournir une réponse. Plus le nombre de tokens/seconde est élevé, plus l’IA est réactive et comprend ce qu’on lui demande rapidement. Et il en va de même pour la réponse, qui est bien plus rapide à être délivrée avec Groq qu’avec les autres fournisseurs.
Tout ceci est permis par une optimisation software pour combler le manque d’unités de contrôle au sein du GroqChip, mais d’après l’équipe, ce n’est pas un problème puisqu’il est très facile de prévoir l’exécution du code dans le cas d’une IA.
Attention toutefois, tout cela n’a rien à voir avec Grok, le chatbot d’Elon Musk. Pour rappel, nous vous parlions déjà de Groq — avec un Q — en 2020 alors que Grok — avec un K — n’a fait son apparition que vers Juillet 2023. Soit dit en passant, ce cher Musk, qui avait co-fondé OpenAI en 2015 puis quitté en 2018, avait appuyé un moratoire de 6 mois sur l’IA juste après le lancement de ChatGPT en Mars 2023. En Avril, il retournait déjà sa veste et parlait de son futur TruthGPT, qui sera finalement renommé en Grok. En même temps venant de l’homme qui a nommé ses enfants X Æ A-12, Techno Mechanicus, ou encore Exa Dark Sideræl, faut-il encore s’étonner ?





















