Un CPU à cache adaptatif, de quoi améliorer les performances sans nouvelle finesse de gravure ? |
————— 22 Juillet 2017 à 17h17 —— 19515 vues



Un CPU à cache adaptatif, de quoi améliorer les performances sans nouvelle finesse de gravure ? |
————— 22 Juillet 2017 à 17h17 —— 19515 vues
Après avoir pondu les peut être processeurs du futur, les chercheurs du MIT qui ont décidément beaucoup de matière grise à revendre en cette période estivale remettent le couvert. Leur idée se base sur un concept simple : au lieu de produire une puce "fixe" possédant deux ou trois niveaux de cache d'une certaine taille donnée, pourquoi ne pas concevoir une puce adaptative, allouant le cache de manière dynamique en fonction des programmes ?
La recette semble porter ses fruits, puisque l'institut annonce des gains sur simulateur allant de 20 à 30% pour une consommation réduite de 35 à 85% ! Bon, le processeur simulé possède la bagatelle de 36 coeurs, possédant chacun 512 Ko de SRAM propre et 4 x 256 Mo de SRAM partagés. En fait, les applications simulées ne tirent pas parti de tous les coeurs, mais piquent du cache aux unités de calcul libres voisines afin de se satisfaire. Il s'agit donc d'une optimisation lors de l'exécution simultanée de plusieurs programmes faiblement multithreadés plus qu'une révolution pour les gourmandes applications de calculs parallèles. Pour gérer tout ce petit monde, un algorithme du nom tout mignon de Jenga est utilisé, et tel Tron, c'est lui qui surveille le partage des ressources.
Pour une utilisation multitâche, l'idée semble reluisante. Cependant il faut garder en tête que Jenga devra être implémenté en dur dans ce type de puce, introduisant potentiellement une latence supplémentaire lors des accès mémoire. Il faut également que ce dernier soit capable de communiquer efficacement avec n'importe quel coeur, ce qui n'est pas gagné d'avance non plus, comme l'a constaté AMD avec l'Infinity Fabric, qui est un des principaux goulots d'étranglement de Ryzen.
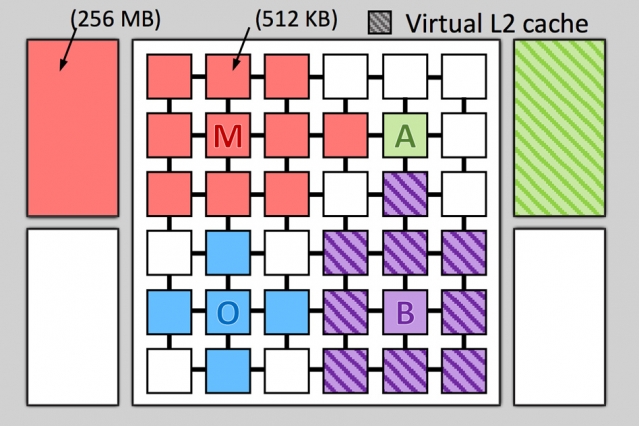
Chacun son domaine, le splix.io des programmes !
Cette initiative va à contre-courant d'Intel, qui avait intégré de l'eDRAM jouant le rôle de gros cache L4 sur ses processeurs Broadwell et Kaby Lake-U. C'est sûr qu'avec des brouzoufs, on peut se permettre d'y aller à la force brute en intégrant directement une quantité importante de cache, et tant pis pour la consommation !
| Un poil avant ?La fibre déployée partout en France... via Altice ? | Un peu plus tard ...Gamotron • Vous voyez le mal partout, c'est fou ! | |





















