Intel Architecture Day 2021 • Xe HPG, des GPU bleus en provenance de TSMC |
————— 20 Août 2021 à 14h30 —— 23749 vues



Intel Architecture Day 2021 • Xe HPG, des GPU bleus en provenance de TSMC |
————— 20 Août 2021 à 14h30 —— 23749 vues
À l’occasion de son Architecture Day 2021, Intel ne s’est pas contenté de causer CPU : comme à son habitude, le fondeur de Santa Clara ne pouvait pas se passer de la causette à propose de sa future gamme de GPU basée sur la microarchitecture Xe, désormais connu sous son appellation commerciale Intel Arc. Dévoilé sous les noms de Xe-HPC et Xe-HPG, ce duo illustre à la perfection les capacités de R&D faramineuses de la firme, qui a réussi en quelques années à faire sortir ex nihilo (ou quasiment) non pas une, mais deux microarchitectures GPU jumelles.
![]()
Dédié au hardcore gamers, Xe-HPG se matérialise par son implémentation dans le SoC Alchemist, prévu pour Q1 2022, auquel fera suite Battlemage, Celestial puis Druide dans les années suivantes - un petit message très subtil des bleus quant à l’usage destiné à ces puces.
![Des puces au nom de classe de RPG pour des GPU : why not? [cliquer pour agrandir] [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/intel-arc-roadmap_t.jpg "Ne pas appuyer ici")
Par rapport au Xe-LP déjà sur le marché, Xe HPG introduit de nombreux changements. La notion d’Execution Units file à la corbeille et est remplacée par des Vector Engines (VE) ainsi que des Matrix Engines (XMX). Probablement du fait de la complexité de faire passer oralement une microarchitecture, le fondeur de Santa Clara n’est pas allé plus loin dans leur fonctionnement : ce sera pour une autre fois ! Cependant, le reste de l’organisation architecturale est, elle, dévoilée : la brique de base se nome Xe-core, et se compose de 16 VE et 16 XMX gérant respectivement des données sur 256 bits et 1024 bits.
![xe hpg core t [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/xe-hpg-core_t.jpg "Même pas cap' de cliquer")
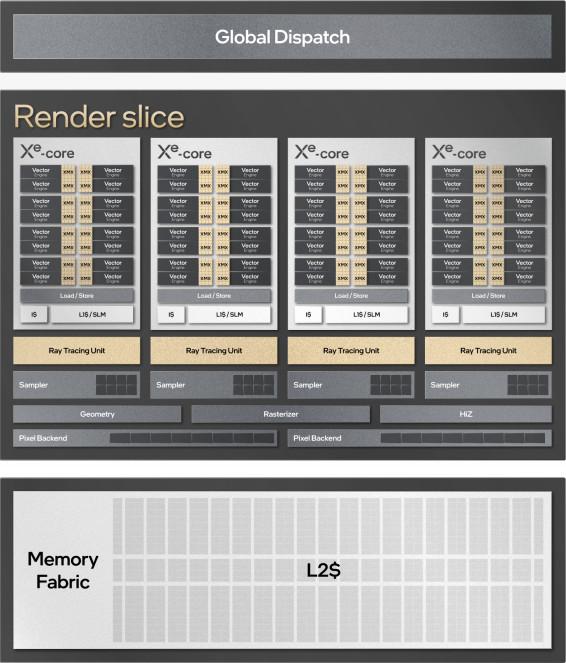
Ces Xe-core sont ensuite assemblés par 4 en slices, en rajoutant au passage tout ce qui est nécessaire au rendu d’image : le fixed functions servant aux fonctionnalités usuelles (pixel backend, samplers, pipeline de géométrie et de rastérisation), mais, surtout, des unités de Ray Tracing accélérant la totalité du BVH : traversée de l’arbre, intersection avec les Bounding Boxes et intersection avec les triangles (contrairement à AMD qui ne gère que les deux derniers). De quoi préfigurer des performances particulièrement compétitives dans le domaine !
![xe hpg core t [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/xe-hpg-slice_t.jpg "Si vous cliquez, vous cliquez.")
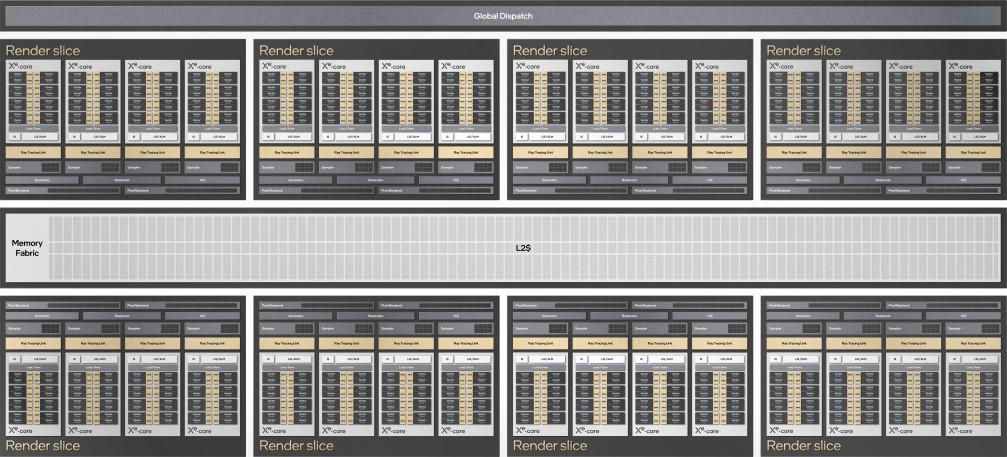
Enfin, une ou plusieurs de ces slices sont adjointes à un global dispatch, une sorte de scheduler sauce GPU, et une certaine quantité de cache L2 encore indéterminée afin de former un die utilisable. Si Intel illustre ses propos avec deux exemples à 1 et 8 slices, cela ne dit rien sur les modèles intermédiaires ni sur les fréquences et consommations des bousins. Pour une comparaison frontale avec la concurrence, il y a encore du chemin à faire !
![xe hpg core t [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/xe-hpg-one-slice_t.jpg "Cliquédélique !")
![xe hpg core t [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/xe-hpg-eight-slice_t.jpg "Si vous cliquez, vous cliquez.")
À gauche, un design à une seule slice ; à droite, pas moins de 8 slices soit 512 Vector Engines !
Si le niveau architectural met la barre haut, l’herbe n’est pas aussi verte de tous les côtés : en effet, ces GPU seront gravés par... TSMC, avec son N6, et non avec le Intel 7 ou Intel 5 concurrent. Coup dur pour les bleus, pour lequel deux explications sont possibles : soit des raisons de cadence de productions insuffisantes pour satisfaire les besoins en CPU et en GPU sur la même technologie, soit une mise au point insatisfaisante du procédé pour cet usage. Quoi qu’il en soit, ces deux cas de figure auraient pû être traités en amont... et c’est bien là que le bât blesse, le géant bleu accusant à ce niveau des années de gestion hasardeuse.
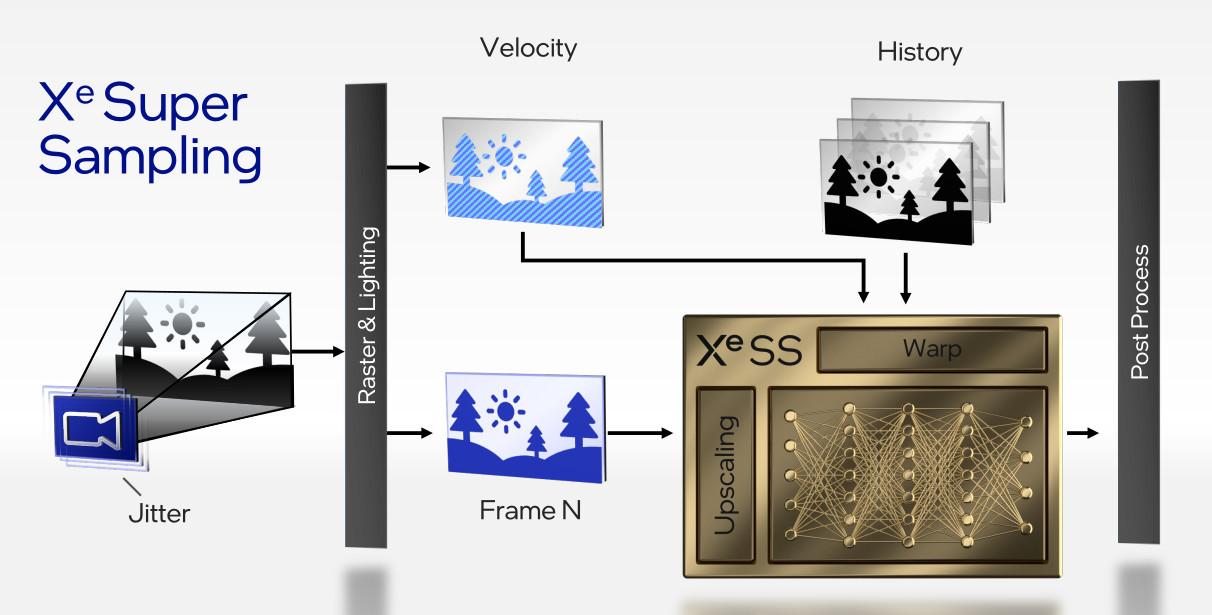
Puisque Xe intègre des accélérateurs de Ray Tracing ainsi que des unités de traitement vectorielles, il aurait été surprenant de ne pas voir un concurrent du DLSS sortir de la hotte des bleus... bingo, dites bienvenue au Xe Super Sampling. Dans la théorie très proche, le Xe SS est même extrêmement proche du DLSS V2 tous deux tirent partie d’un réseau de neurones utilisant à la fois des informations de rendu immédiat (frame complète) mais également passé (vecteurs vitesse et images précédentes) afin de rendre une version haute définition de l’image pour un coût computationnel plus faible, i.e. une augmentation du taux de FPS.
![Machine Learning, Upscaling : les mots-clefs sont présents ! [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/intel-supersampling_t.jpg "Ultra bouzotron HD max def")
Illustrée dans une brève démonstration, la chose semble aboutie ; reste qu’un entraînement minutieux du réseau reste nécessaire : comprenez que le rendu de trailers aux images connues d’avance est une chose aisée, et que son intégration au même niveau de qualité dans un titre vidéoludique en est un autre - prenez le DLSS premier du nom, hétérogène dans son niveau de précision visuel selon les titres. Notez d’ailleurs que, au vu de la difficulté du DLSS à se démocratiser, nous émettons quelques doutes sur le panel compatible day one ; à voir si les moyens et les réseaux des bleus leur permettent une prise en charge étendue. Enfin, tout comme le FSR d’AMD, le Xe SS sera également disponibles pour les GPU des autres vendeurs, mais fera alors usage du jeu d’instruction DP4a commun aux cartes graphiques depuis la GTX 1050 environ au lieu des accélérateurs XMX maison.
![1080p versus 1080p + ML : la différence est flagrante ! [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/xess-vs-lowres_t.jpg "Enlarge your pe...icture")
| Un poil avant ?NVIDIA admet que l'acquisition d'Arm n'est pas encore gagnée... | Un peu plus tard ...Live Twitch • Il a coulé mon porte-avion ! | |
![Des puces au nom de classe de RPG pour des GPU : why not? [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/intel-arc-roadmap.jpg)