Les premiers processeurs grand public Armv9, les Cortex-X2, Cortex-A710 et Cortex-A510, sont officiels |
————— 28 Mai 2021 à 18h40 —— 20465 vues



Les premiers processeurs grand public Armv9, les Cortex-X2, Cortex-A710 et Cortex-A510, sont officiels |
————— 28 Mai 2021 à 18h40 —— 20465 vues
Arm avait annoncé son renouveau avec la nouvelle architecture Armv9 en avril dernier, mais, à l’époque, un écueil de taille était présent : aucun design n’avait été annoncé, si ce n’est côté serveur, avec un Neoverse-N2, mais qui ne risquait pas de se retrouver dans nos appareils. Pourtant, ce N2 dérive bel et bien d’un design plus généraliste, et c’est bien de celui-là dont il est question aujourd’hui : le Cortex-X2, pour un maximum de performances. Pour qui chercherait des performances sans trop sacrifier l’autonomie, alors la firme met un autre modèle dans sa poche : le Cortex-A710. Enfin, Arm obligeant, ces gros out-of-order ne sont pas prévus pour être intégrés seuls dans un SoC de téléphone ou de tablette, mais sera accompagné d'autres coeurs in-order plus efficients, qui doivent assez logiquement répondre, eux aussi, aux nouvelles contraintes imposées par l'Armv9. Pour ce faire, les britanniques annoncent en parallèle le Cortex-A510, nouveau cador de cette catégorie « meilleure efficacité performance/consommation ».
Pour le Cortex-X2, notre cher design fait suite au Cortex-X1 de l’an dernier en reprenant une partie de son agencement logique. Tout comme les processeurs x86, les améliorations se divisent en trois catégories : front-end, back-end et sous-système mémoire. Pour le premier, les constructeurs restent taciturnes afin de ne pas trop fournir d’information à la concurrence, nous savons simplement que la prédiction de branchement a été améliorée afin de garantir un prefetch plus efficace des instructions lors des modifications du flot d’exécution des programmes ; tout en doublant le nombre d’état du prédicteur et en augmentant au passage le branch target buffer.
Côté back-end, le pipeline n’est pas modifié dans sa structure et garde 10 unités d’exécution ; les améliorations se cachant dans la taille de la fenêtre out-of-order (le nombre d’instructions visible à un instant donné par le processeur), qui grimpe de 224 à 288 entrées, ainsi que dans les latences des opérations, désormais toutes dans une enveloppe de 10 cycles en comptant la prédiction de branchement. Rajoutez le support SVE2, qui double la puissance brute disponible en int8 ; une aubaine pour les tâches de machine learning !
Enfin, la mémoire n’est pas en reste, avec une augmentation moyenne de 33 % des files de chargement/rangement, en parallèle d’un agrandissement de 20 % du TLB, prenant 48 entrées supplémentaires. Néanmoins, les bandes passantes ne changent pas avec 3 chargements et deux rangements par cycle : circulez, il n’y a rien de plus à voir !
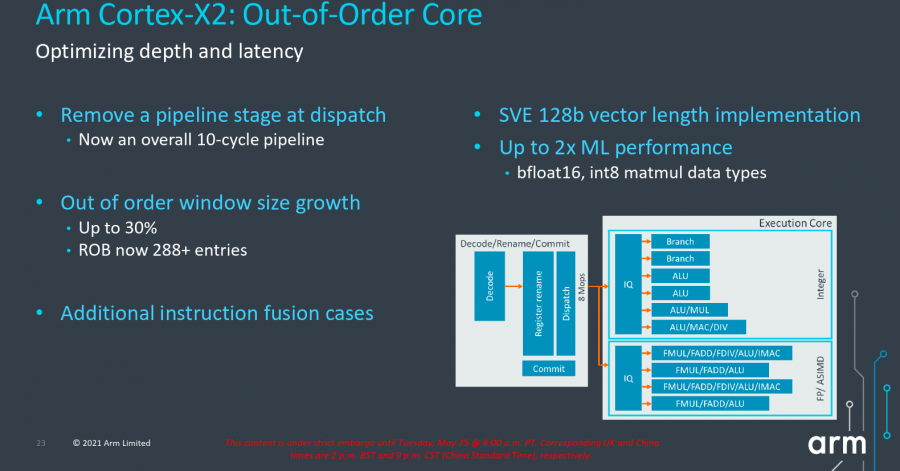
Le Cortex-A710 reprend les grandes lignes du Cortex-X2 tout en coupant largement là où le silicium devenait trop gourmand. Ainsi, les 10 cycles en moyenne du pipeline sont retenus, mais adaptés à la structure de l’ancien Cortex-A78 dont notre A710 est issu. De plus, l’étage de décodage a subi un sérieux régime en passant de 6 micro-instructions envoyées aux unités de calcul à 5, diminuant également la bande passant du cache concerné en conséquence. Pour contrebalancer cela, les améliorations du front-end, partagées en majorité avec le X1, réussissent à transformer cette cure d’amaigrissement en victoire du point de vue des performances — selon la maison-mère tout du moins. Rajoutez 32 ou 64 kio de L1 privé, 256 ou 512 kio de L2, toujours privé, et voilà le bousin !

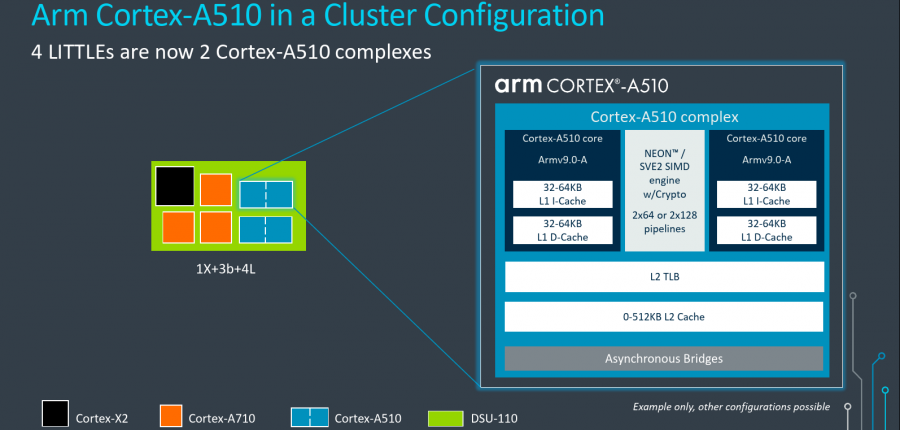
Côté A-510, nous avons à faire à un design bien plus modeste avec seulement 32 kio de L1, un L2 optionnel d’un taille maximale de 512 kio, mais surtout un pipeline d’exécution in-order (un sacrifice nécessaire pour une efficience maximale) à cinq voies : trois ALU, une unité de multiplication/accumulation et de division et une dédiée aux branchements. Pour le front-end, trois instructions peuvent être décodées en parallèle, contre 2 pour le Cortex-A55 précédent. Notez que les unités SVE2 — également compatibles NEON et calcul flottant scalaire — sont partagées entre deux cœurs (ce qui n’est pas sans rappeler la peu glorieuse époque de Bulldozer). Enfin, le sous-système mémoire tire également partie du développement du Cortex-X2 tout en l’allégeant, avec 1 chargement et un chargement ou un rangement maximum par cycle, tous deux en 128 bits.
Pour ce qui est de la disponibilité, nous attendons typiquement les premiers modèles équipés pour le semestre suivant, les principaux fabricants de puces Arm ayant généralement bien anticipés la pénurie et préréservés leurs créneaux de production chez Samsung/TSMC, contrairement aux GPU. Avis aux amateurs ? (Source : WikiChip)
| Un poil avant ?AMD va demander l'autorisation de racheter Xilinx à la Commission Européenne | Un peu plus tard ...French Days • Des bons plans à la pelle ? (MàJ bis) | |





















