Test • Zen 3 : Ryzen 9 5950X & 5900X / Ryzen 7 5800X / Ryzen 5 5600X |
————— 05 Novembre 2020



Test • Zen 3 : Ryzen 9 5950X & 5900X / Ryzen 7 5800X / Ryzen 5 5600X |
————— 05 Novembre 2020
Le grand chambardement dans l’organisation interne des cœurs Zen 3, réside dans le passage à des CCX de 8 cœurs. Contrairement à Zen 1 & 2, qui devaient caler 8 cœurs selon une topologie 4 + 4 sur le die contenant les cœurs, liant ainsi le L3 (toujours de type victime) par l’Infinity Fabric, cette limitation disparaît au profit d’un plus "simpliste" 1x 8 cœurs par die.
![Fusion CCX [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/fusion_ccx_t.jpg "Même pas cap' de cliquer")
Deux effets se font alors sentir : d’une part, la synchronisation des 16 Mo de cache L3 entre CCX — par rapport à Zen 2 — n’a plus lieu d’être, ce qui devrait franchement améliorer les performances multithread des applications gourmandes en bande passante RAM. Et ce d’autant plus que l’implémentation au sein de Zen 2, faisait passer les communications entre CCX d'un même die par la puce distincte gérant les entrées/sorties (cIOD). Le progrès est donc de taille. D’autre part, un programme monothread pourra désormais utiliser pleinement les 32 Mo de L3 présents sur le die, alors que dans le cas de Zen 2, les 16 Mo accompagnant chaque CCX étaient privés à ce dernier. Autant dire que les gains devraient, ici aussi, être au rendez-vous. La fusion ne s’effectue par contre pas sans inconvénient : la latence d’accès au L3 augmente fatalement de 39 à 46 cycles, bien que ce ne soit pas nécessairement visible : sur Zen premier du nom, cette valeur était encore plus basse, avec 35 cycles seulement.
![Hiérarchie des caches [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/cache_hierarchie_t.jpg "Si vous cliquez, vous cliquez.")
Au passage, la macro-organisation reste identique : un die nommé cIOD s’occupe des entrées/sorties et de la connexion entres cœurs de calcul regroupés au sein de dies nommés CCD, abritant chacun le CCX (à présent unique). Les CCD demeurent donc indépendants (permettant une meilleure granularité des coûts de production avec un seul type de die quelque soit le niveau de performance recherché), leur liaison avec le cIOD étant toujours confiée à l’Infinity Fabric, sauce Die-to-Die, c’est-à-dire en utilisant directement les couches conductrices du substrat. Cette non-innovation permet ainsi de conserver intact le cIOD, qui est toujours produit en 12 nm chez GlobalFoundries. Pour les processeurs qui nous intéressent aujourd'hui, l’AM4 reste de mise, et la compatibilité avec les chipsets série 500 et 400 assurée, si tant est que les fabricants mettent à jour les BIOS. Semi-déception pour les plus rêveurs, car cette série ne pourra pas pointer à plus de 16 cœurs sur le segment desktop, il vous faudra une fois de plus vous tourner vers les Threadripper pour cela.
![Topology à un CCD [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/topology_1ccd_t.jpg "Si vous cliquez, vous cliquez.")
Pour les CPU équipés de 8 cœurs ou moins, l’IHS cachera une organisation du type du schéma ci-dessus, et pour les processeurs à 12 et 16 cœurs, c’est au-dessous qu’il faut regarder.
![Topology à 2 CCD [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/topology_2ccd_t.jpg "Ultra bouzotron HD max def")
Les chiffres ne changent pas par rapport à Zen 2 : chaque CCX accède à la RAM selon un débit montant de 16 o/cycle et 32 o/cycle en descendant, sachant que la bande passante des CCX est limitée par le cIOD du fait de l’interfaçage avec le contrôleur mémoire unifié. Notez qu’une configuration à deux CCD risque ainsi de saturer le contrôleur mémoire, expliquant de potentielles irrégularités de performances entre les différentes gammes sur certains benchmarks. A contrario, le débit d'un seul et unique CCD à direction du cIOD, ne permet pas de tirer partie de l'intégralité du bus mémoire. Côté cache, les bandes passantes de 32 o/cycles sont par contre bidirectionnelles, et, concernant la communication avec les périphériques, cette dernière s’effectue sur un bus séparé à raison de 64 o/cycle.
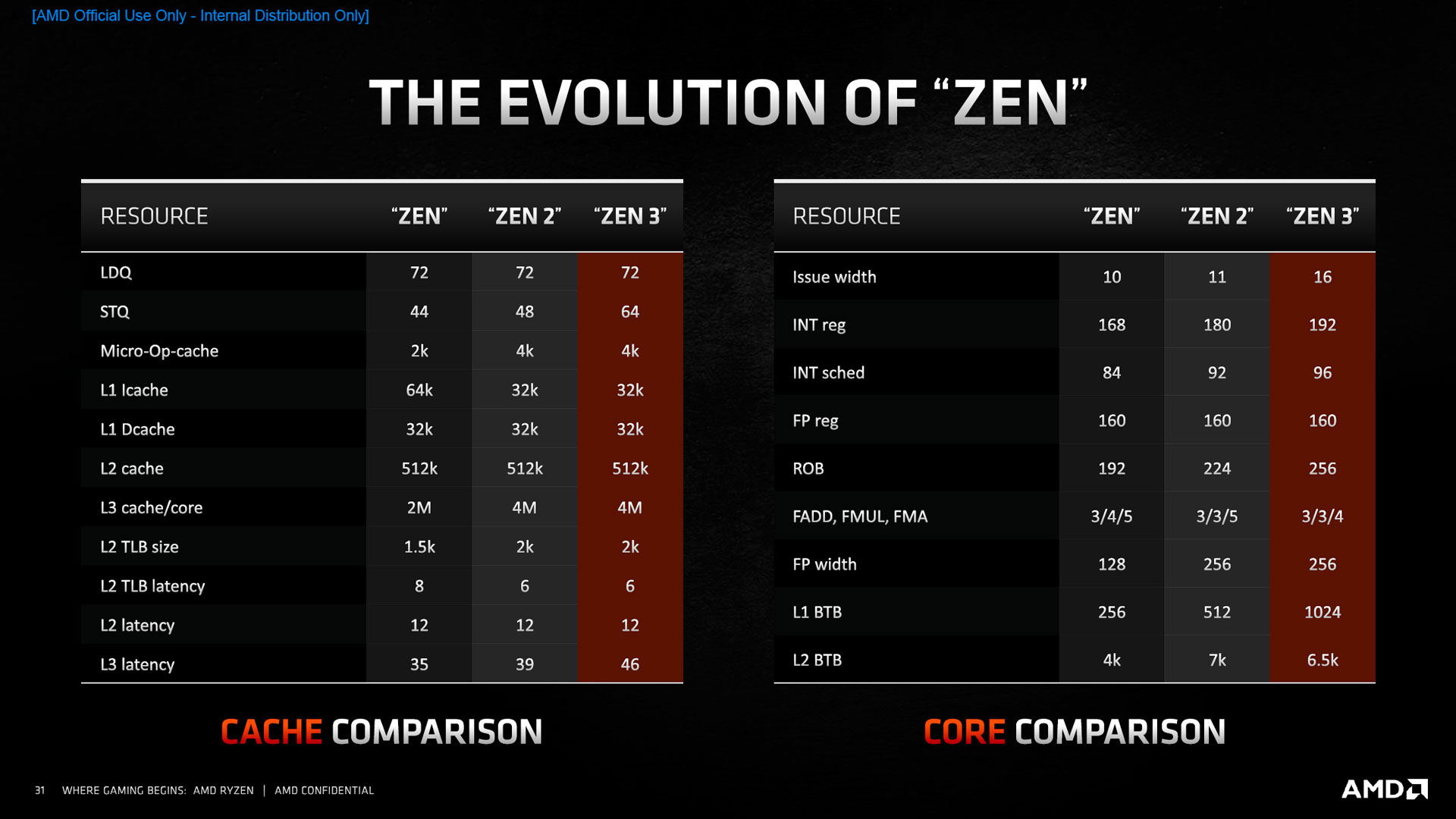
![Evolution Zen [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/zen_evo_t.jpg "Même pas cap' de cliquer")
Alors qu’Intel avait profité de Sunny Cove pour muscler son L1 et le passer à 48 ko, AMD est resté sage sur le reste de ses caches : seule la Store Queue, le buffer utilisé pour rassembler les éléments à ranger à nouveau en L1, prend du galon, et passe de 48 à 64 entrées.
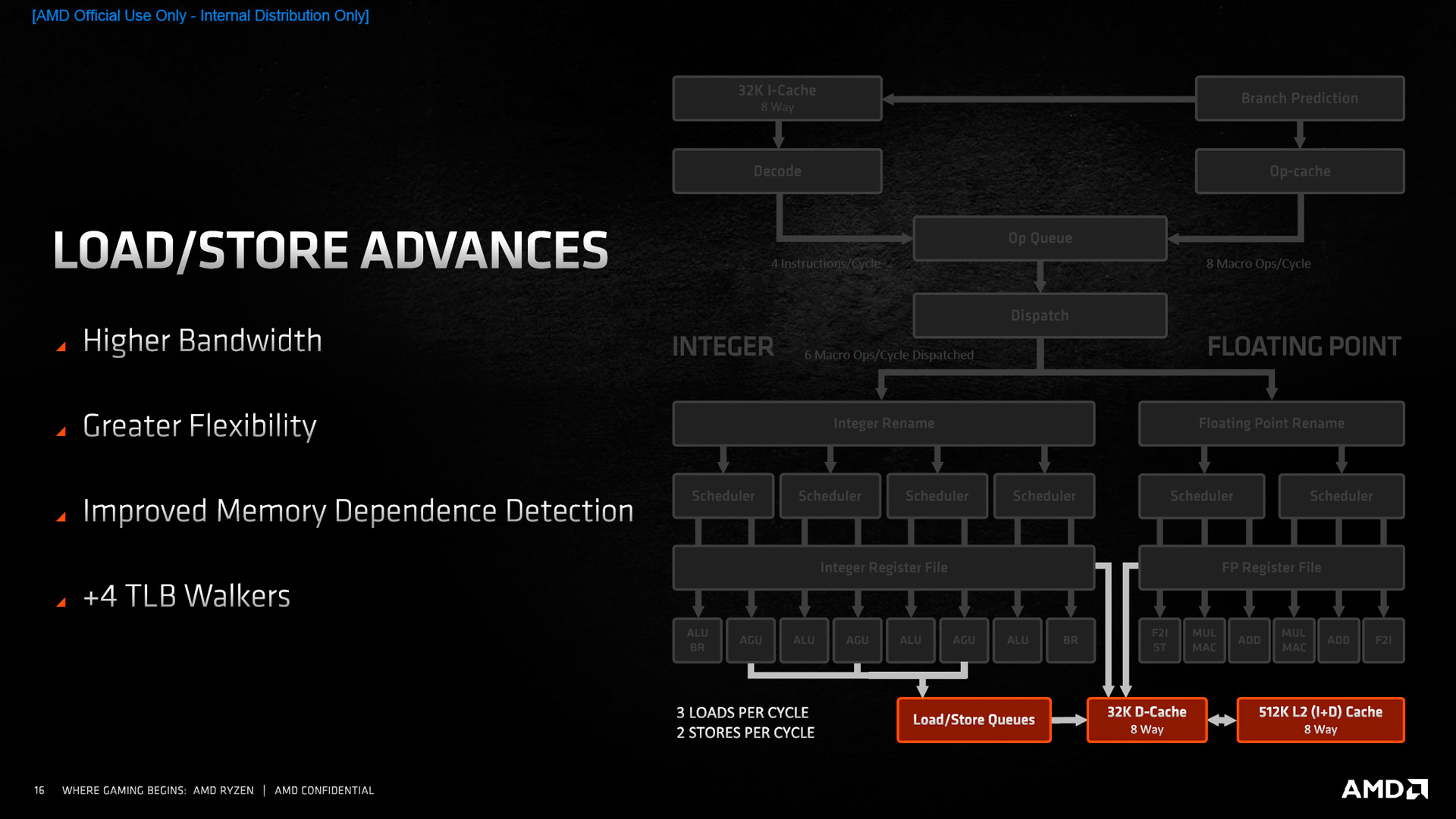
![Load/Store [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/load_store_t.jpg "Enlarge your pe...icture")
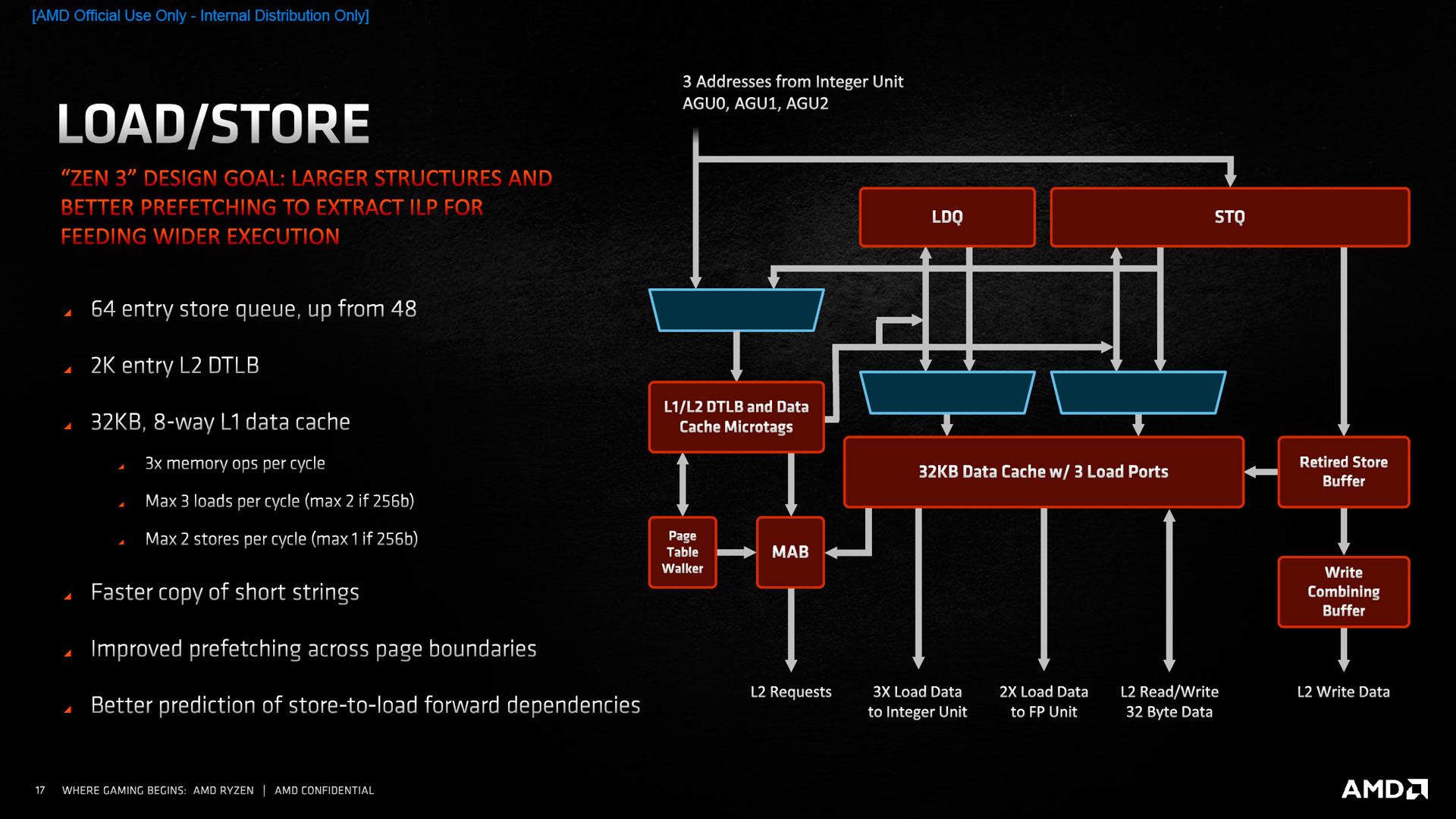
Pour transmettre les données du L1 à l’intérieur du cœur, AMD a dopé son sous-système mémoire. Rattaché à la partie s’occupant des calculs entiers (les chargements mémoire sont effectués à partir d’adresses, qui ne sont rien d’autre que des entiers 64 bits), ses bandes passantes explosent, avec la possibilité d’effectuer un chargement ou un rangement de plus par cycle, soit 3 opérations maximum, dont au plus 2 stores. Attention par contre, dans le cas d’utilisation des instructions AVX (utilisation de vecteurs de 256 bits), le processeur devra se contenter 2 chargements et 1 rangement, ce qui donnera des performances similaires à Zen 2. Du côté de la table des pages, les caches restent identiques avec un L2 à 2048 entrées, mais, surtout 4 page walkers supplémentaires, pour un total de 6. Ces composants servent à parcourir la mémoire allouée pour trouver la bonne entrée correspondante. Une évolution qui suit donc assez logiquement l’élargissement de la bande passante mémoire, et devrait masquer les latences dues aux accès chevauchant deux pages.
![Load/Store [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/load_store2_t.jpg "Même pas cap' de cliquer")
Tout cela est bien beau, mais comment le CPU peut-il utiliser efficacement ces données nouvellement acquises ? La réponse page suivante, dans la dissection complète des unités de calcul d’un cœur Zen 3.
|
|
| Un poil avant ?Du SSD RGB, encore ? Eh oui, avec le T-FORCE TREASURE Touch ! | Un peu plus tard ...Windows Insider 20251 : toujours plus de rustines pour Windows 10 | |