Preview • Les puces Lunar Lake en détail, et sans HyperThreading |
————— 04 Juin 2024



Preview • Les puces Lunar Lake en détail, et sans HyperThreading |
————— 04 Juin 2024
En plus des 2 clusters de cores que l'on vient de détailler, la Compute Tile embarque aussi un GPU Xe2. Pour rappel, Xe2 constitue la nouvelle architecture GPU d’Intel, que l’on retrouvera notamment dans les cartes Battlemage. Bien entendu, Intel ne s’est pas trop attardé sur les détails de la configuration haute puissance de Xe2, et a préféré parler de la déclinaison mobile qui intègre Lunar Lake.
![Le Xe Core, mais en version 2 ! [cliquer pour agrandir]](/images/stories/_cpu/5nm-20a_intel/lunar-lake/intel-lunar-lake-xe2-core_t.jpg "Si vous cliquez, vous cliquez.")
![Tous les apports de Xe2 résumés en une slide. Si c'est pas beau la vie. [cliquer pour agrandir]](/images/stories/_cpu/5nm-20a_intel/lunar-lake/intel-lunar-lake-xe2-improvements_t.jpg "Même pas cap' de cliquer")
On retrouvera donc toujours 8 Xe cores, mais de 2nde générations, 8 unités Ray Tracing et 8 Mo de cache L2. Difficile de dire si cet iGPU sera capable d’animer des jeux de façon convaincante, mais Intel avance des performances en jeu 50% supérieures à celles de Meteor Lake. Ça vaut ce que ça vaut hein.

Si Lunar Lake embarque 8 Xe cores, Battlemage pourrait en intégrer 64, le niveau de puissance est donc incomparable.
La partie affichage pourra gérer un flux 8K 60 Hz, 3 flux 4K 60 Hz ou du 1440p jusqu’à 360 Hz. Le tout via du HDMI 2.1, DisplayPort 2.1 ou l’eDP 1.5. Cette dernière connectique sert surtout pour l’écran du laptop, afin d’optimiser la consommation via une modulation de fréquence gérée par le GPU ainsi que de nombreuses petites optimisations : ne pas rafraichir des portions fixes de l’image, envoyer les signaux plus rapidement pour couper l’alimentation de certaines parties de la mémoire, du GPU, ou du moteur d’affichage, et ainsi limiter les sorties de veille des ces entités, décoder des batches d’images et les transmettre immédiatement plutôt que de décoder chaque image une par une, etc.
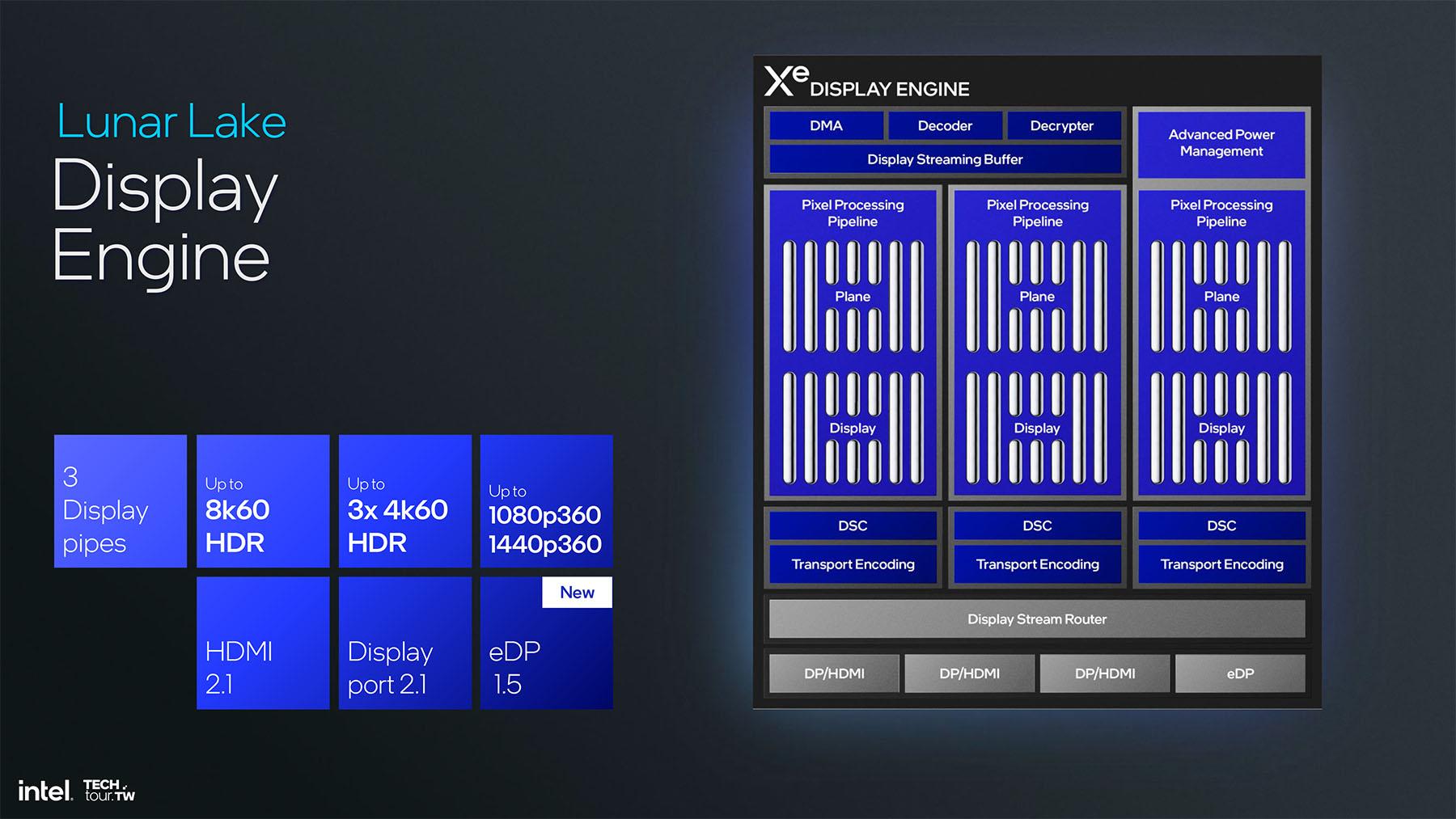
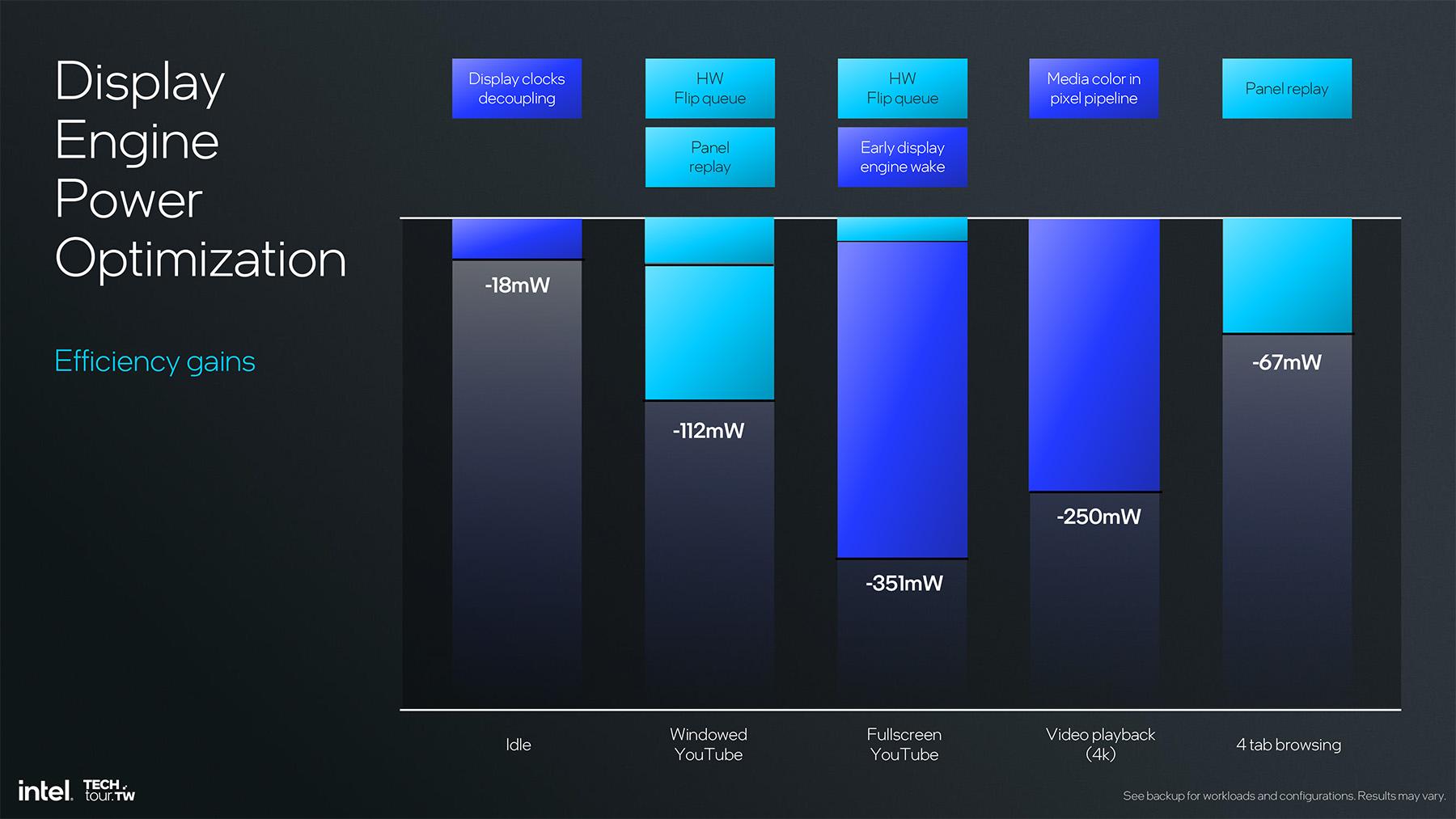
Tout ceci permet donc de réduire la consommation de toute la partie affichage. Intel avance des chiffres allant jusqu’à 351 mW pour de la lecture vidéo Youtube en plein écran par exemple. Un chiffre pas bien parlant, qui représenterait au mieux un gain d’autonomie de l’ordre de 1%, mais qui montre que le x86 fait tout ce qu’il peut pour rogner les watts et proposer une expérience similaire aux offres ARM notamment.
Les décodage H.266 et AV1 sont également de la partie, l’AV1 étant même supporté matériellement en encodage, le tout jusqu’aux flux 8K 60 Hz HDR 10 bits.
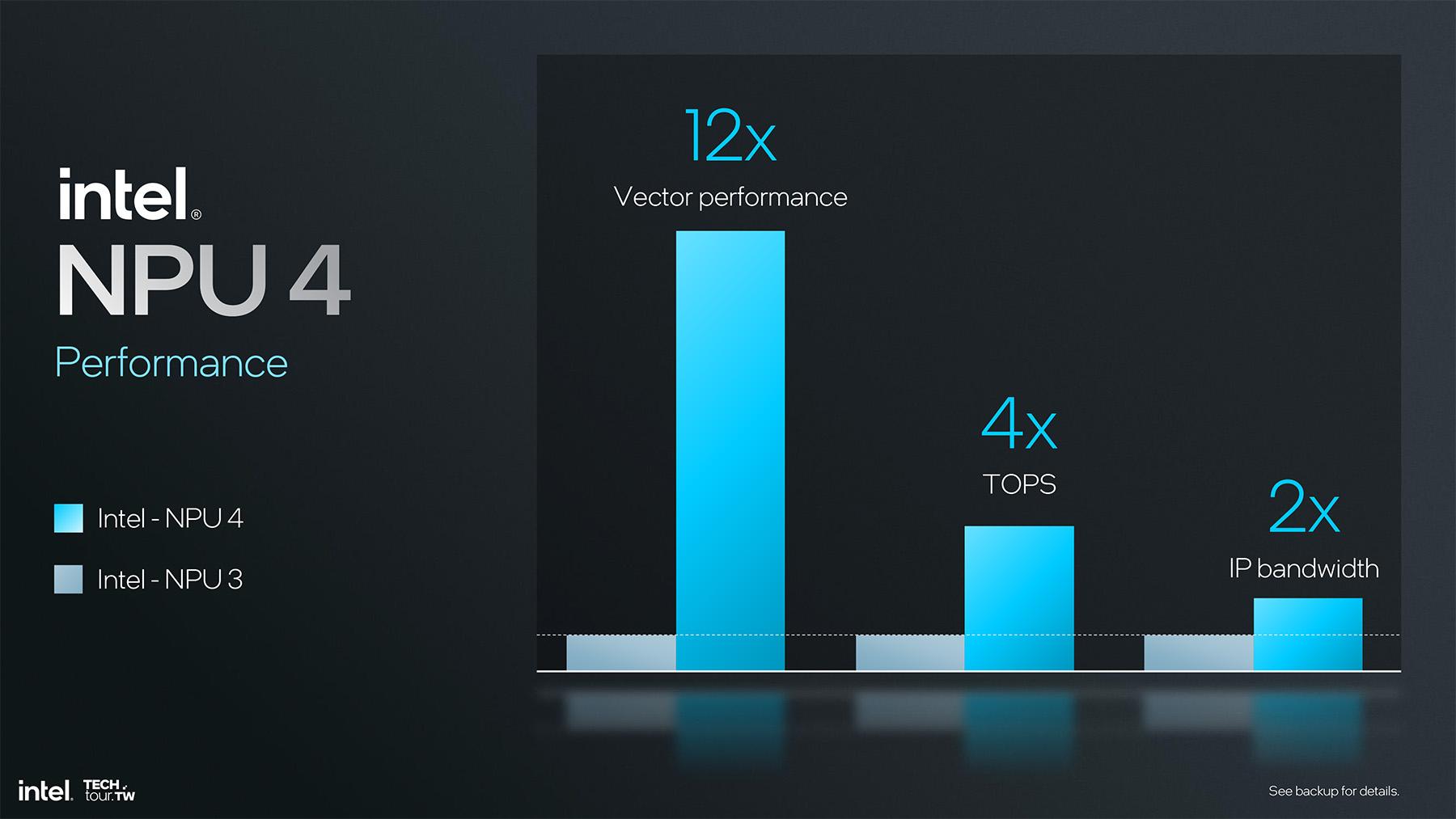
Impossible de passer à côté de l’aspect IA qui fait mouiller le slip de tous les gourous de la finance en 2024, alors Lunar Lake embarque bien sûr un NPU. NPU 4 atteint 48 TOPS, un net cran au-delà des 40 minimum pour profiter du label Microsoft Copilot+, et largement plus que les misérables 11,5 du NPU 3 de Meteor Lake. Intel ne blague pas à ce niveau, et en profite pour annoncer jusqu’à 120 TOPS pour la plateforme complète, dont 67 pour le GPU et 5 pour le CPU. Il est intéressant de noter que les premiers leaks parlaient de « plus de 100 TOPS », mais qu’avec l’arrivée des APU Strix Point d’AMD, qui dépasseraient les 110 TOPS, Intel semble avoir ajusté son chiffre en toute dernière minute, peut-être via l’ajout d’un SKU un peu plus performant pour coiffer AMD au poteau ?

La marque atteint de tels chiffres en triplant le nombre de NCE — Neural Compute Engines — et en augmentant la fréquence d’environ 40%. Chaque NCE ne traite pas plus de MACs — Multiply and ACumulate, 2 opérations de base pour l’IA — de sorte que NPU 4 s’apparente plus à un NPU 3 sous stéroïdes. Une approche un tantinet bourrin qui contraste avec la philosophie appliquée pour les cores CPU. Doit-on y voir un léger retard technologique ?
![Des registres 4 fois plus gros sur les DSP de NPU4 [cliquer pour agrandir]](/images/stories/_cpu/5nm-20a_intel/lunar-lake/intel-lunar-lake-npu4-vs-npu3-vector_t.jpg "Cliquédélique !")
![Et des unités triplées pour faire bonne figure. [cliquer pour agrandir]](/images/stories/_cpu/5nm-20a_intel/lunar-lake/intel-lunar-lake-npu4-vs-npu3_t.jpg "Même pas cap' de cliquer")
Intel tente d’avancer de nombreuses améliorations au niveau architectural, mais nous ne voyons que 2 changements profonds. D’abord le passage à des registres vectoriels de 512-bit au lieu de 128 auparavant sur les DSPs — Digital Signal Processors — multipliant par 4 leur puissance de traitement. Et puisque chaque NCE comporte toujours 2 DSP, mais qu'on a triplé les NCE, la puissance de traitement vectorielle est multipliée par 12. Ces DSP bénéficient d’une bande passante quadruplée également afin de communiquer avec le reste des unités du NPU. Dans le Machine Learning, il est important de vectoriser les données afin de pouvoir les traiter, et c’est à ce nivequ qu’interviennent ces DSP améliorés.
Le second changement profond concerne la bande passante doublée vers la DDR, ce qui servira notamment afin de traiter plus rapidement les LLMs — Large Language Models. Dans les deux cas, même s’il s’agit d’améliorations notables, on a plutot l’impression d’un NPU 3.5.
|
|
| Un poil avant ?Asus met au monde sa troisième génération d’alimentations ROG Thor | Un peu plus tard ...Acemagic dévoile un PC portable double écran et des mini-PC bling-bling | |
| 1 • Préambule |
| 2 • Des P-cores qui picotent |
| 3 • E-cores au régime |
| 4 • |
| 5 • Connectique |
























