Preview • Turing : la révolution Ray Tracing & IA ? |
————— 14 Septembre 2018



Preview • Turing : la révolution Ray Tracing & IA ? |
————— 14 Septembre 2018
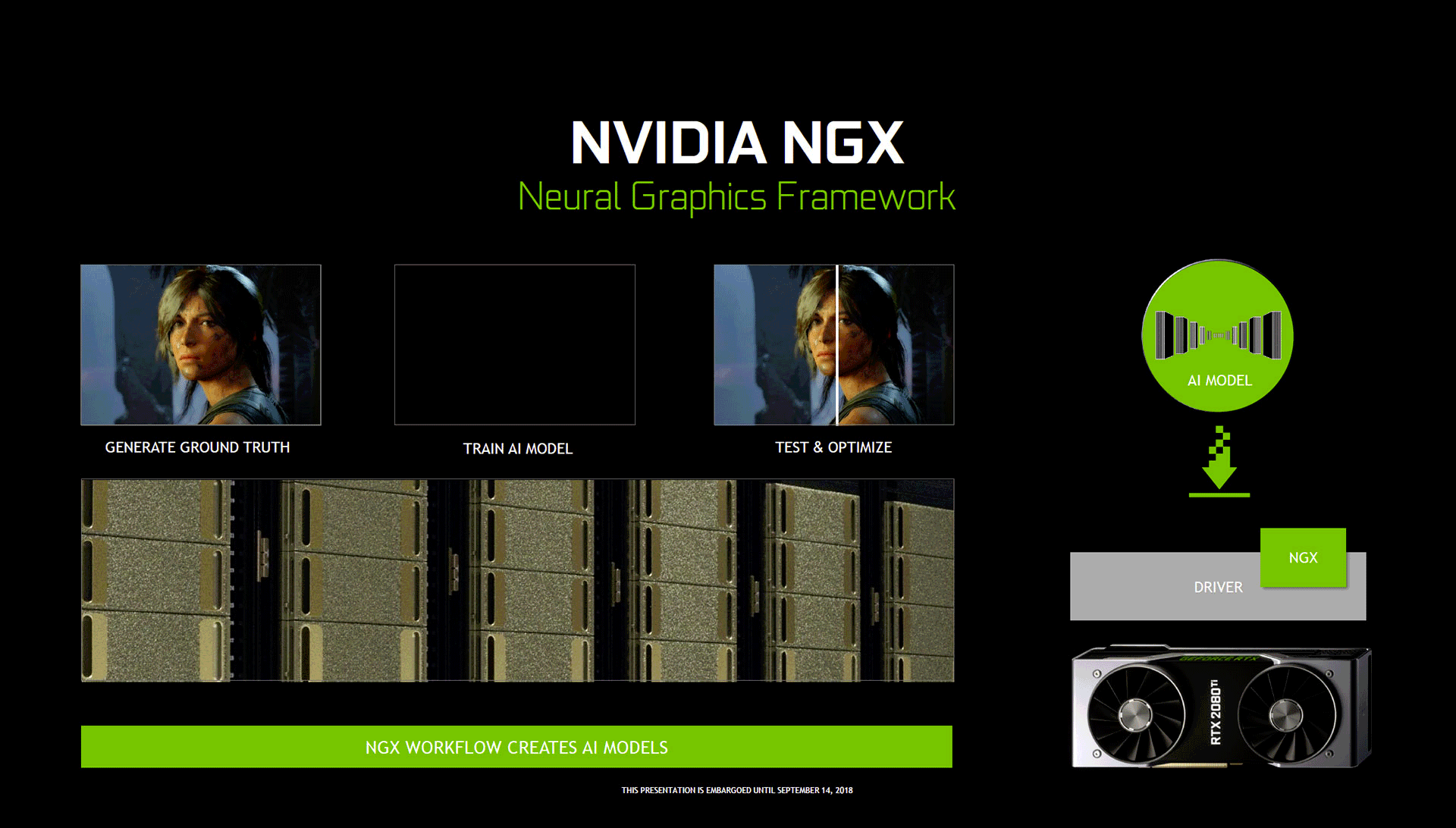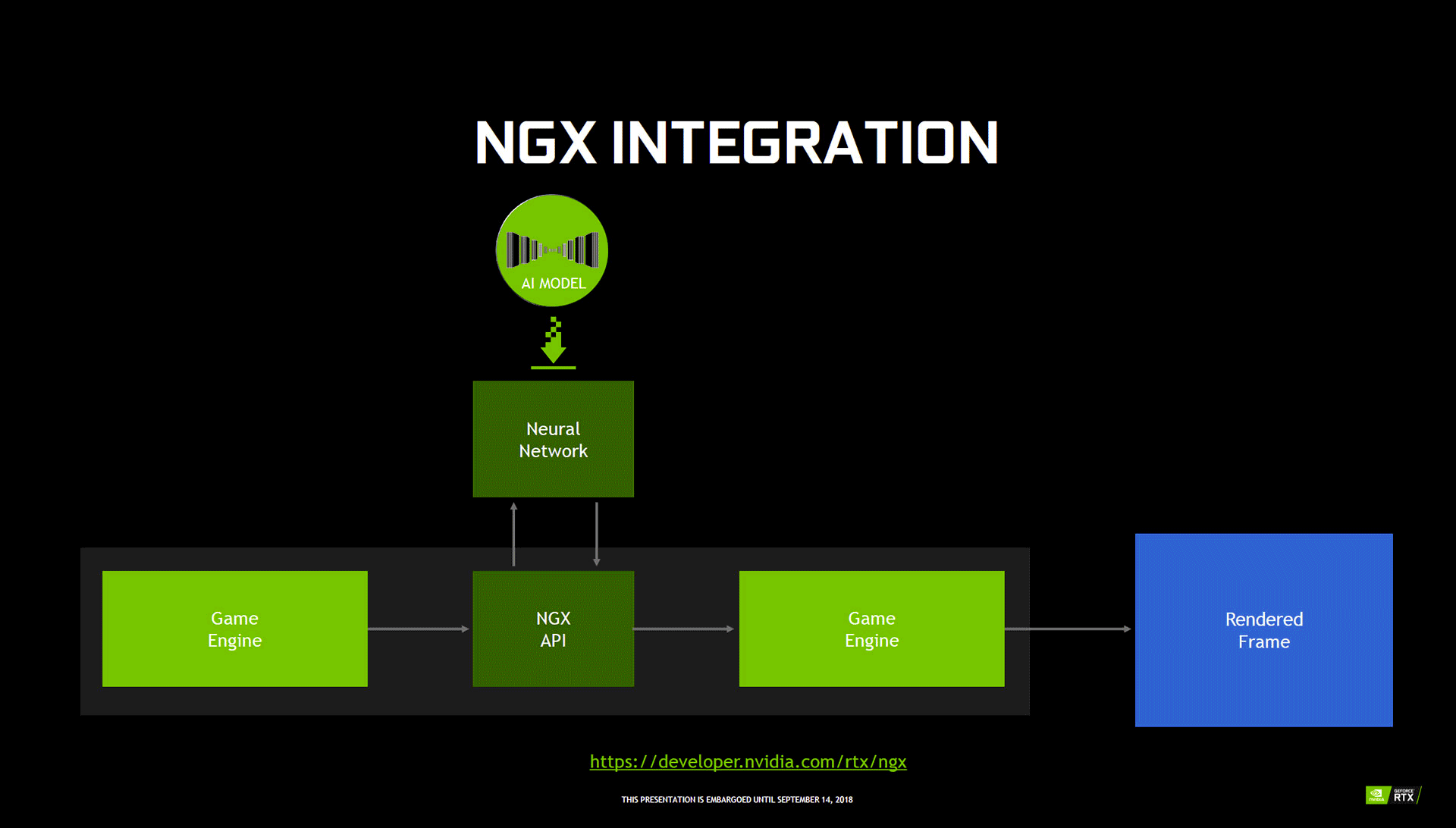
Vous l'aurez certainement noté, NVIDIA insiste lourdement sur l'IA et son usage ludique au cours de ce lancement. Derrière la bannière RTX, se cache bien évidemment la technologie Ray Tracing mise en œuvre, mais aussi ce point crucial selon le caméléon. Une des pierres angulaires de cette stratégie est le Neural Graphics Framework, ou NGX comme le nomment les verts. Ce dernier est constitué de plusieurs éléments : un réseau de neurones artificiels (DNN) déjà entraîné du côté NVIDIA, avec une API à disposition des programmeurs et un ensemble logiciel du côté utilisateur, s'appuyant sur GeForce Experience (GFE), les pilotes et NGX Core. Qu'est-ce que c'est encore que cet engin ? Simplement la base logicielle autour de laquelle s'articule la communication entre les pilotes et les résultats des apprentissages (nommés DNN models), utiles pour une application donnée.
![NGX [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/ngx_t.gif "Même pas cap' de cliquer")
En pratique, GFE détecte si un GPU Turing est présent dans le système. Si oui, il procède à l'installation de NGX Core (ce dernier peut également s'installer directement via le programme d'installation du pilote) et lui transmet la liste des jeux installés. Lorsqu'un modèle - comprendre un réseau déjà entraîné par le géant vert sur un bon tas d'images de l'application cible - est disponible pour des jeux ou logiciels installés, alors celui-ci sera téléchargé. Lors de l’exécution du jeu (ou logiciel), le DNN model est alors mise en œuvre par inférence via les Tensors Cores. Tout ceci doit rester encore quelque peu abstrait pour certains, c'est pourquoi l'observation d'un exemple pratique sera potentiellement plus parlant. Cela tombe plutôt bien, puisque les verts en ont présenté un avec le DLSS.
Nous avions rapidement évoqué le sujet lors d'un billet durant la Gamescon, NVIDIA faisant face à une certaine agitation des médias du web, quant à un déficit (supposé) de performances de ses nouvelles-nées. Le géant vert du GPU avait donc décidé de lever le voile sur une partie de ce point et avait même été jusqu'à indiquer des gains doublés dans certaines conditions, via ce Deep Learning Super-Sampling. Comment est-ce possible en pratique ? NVIDIA utilise une build d'un jeu fourni par les développeurs et procède au rendu de dizaines de milliers d'images avec une qualité visuelle parfaite ou presque (super-sampling 64x), collectant ainsi le résultat de sortie et les données d'entrée brutes (définition, etc.) permettant ce rendu.
Un réseau de neurones spécifique (auto-encodeur convolutif) est par la suite "habitué / entraîné" à cette qualité au moyen de méthodes fortement matheuses à base de "back propagation", ce qui lui fait "apprendre" les spécificités propres à ces images. Il en ressort un DNN model capable d'imiter le comportement observé sur l'échantillon utilisé lors de son apprentissage, et ce pour un coût bien moindre que la technique originelle (super-sampling 64x). Grâce aux Tensor Cores, il est donc possible de fournir au DNN model, l'image brute aliasée de qualité dégradée (pour des raisons de performances) et d'inférer en temps réel le rendu anti-aliasé. La question qui se pose est de savoir comment la qualité de l'image brute est dégradée : via une définition moindre ?
A priori non d'après NVIDIA, puisqu'il ne s'agirait (notez le conditionnel) techniquement, ni d'un upscaling puisque aucune image de définition inférieure ne serait calculée (et donc pas d'adaptation ni de flou habituel à cette technique), ni de down-sampling (technique utilisée dans le super-sampling consistant à calculer une image mieux définie, et de l'adapter sur une définition inférieure afin de gommer l'aliasing). Tout ceci nous parait tout de même pour le moins étrange et mérite d'être éclairci à l'avenir, une définition moindre en entrée semblant la raison la plus probable aux gains annoncés, puisque l'on dépasse les performances atteintes sans AA dans la définition cible avec le DLSS actif... Les premiers jeux employant le DLSS devraient dans tous les cas apporter leur lot d'enseignements.
![Deep Learning Super-Sampling [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/dlss_t.jpg "Si vous cliquez, vous cliquez.")
Les captures d'écrans suivantes (la qualité est altérée par le format que nous avons retenu pour limiter la taille) permettent de comparer l'aliasing et la netteté des 2 rendus. Dans tous les cas, nous attendrons de pouvoir juger sur nos écrans avant de nous prononcer définitivement sur le côté qualitatif, même si pour avoir vu "tourner' les démos, le résultat nous parait tout aussi fin qu'un 4K + TAA, avec une netteté accrue. Il reste aussi à savoir si la mise en pratique suivra, à l'heure actuelle, 25 jeux ont prévu d'y faire appel. Finissons par le DLSS 2X qui est une variante du précédent, avec cette fois des données pour le rendu en entrée du DNN model, correspondant pour sûr à la définition de sortie (point confirmé par le caméléon laissant sous-entendre que ce n'est pas le cas de la version "standard" de DLSS malgré la volonté de ne pas parler d'upscaling). L'apprentissage vise cette fois à s'approcher au plus près du SSAA 64x, sans le coût toutefois (inutilisable en pratique). À ce sujet, NVIDIA reste toutefois flou et ne communique pour l'instant, pas de niveau de performance lié au DLSS 2x.
![dlss t [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/dlss_t.gif "Visionner en grand sur un magnifique pop-up")
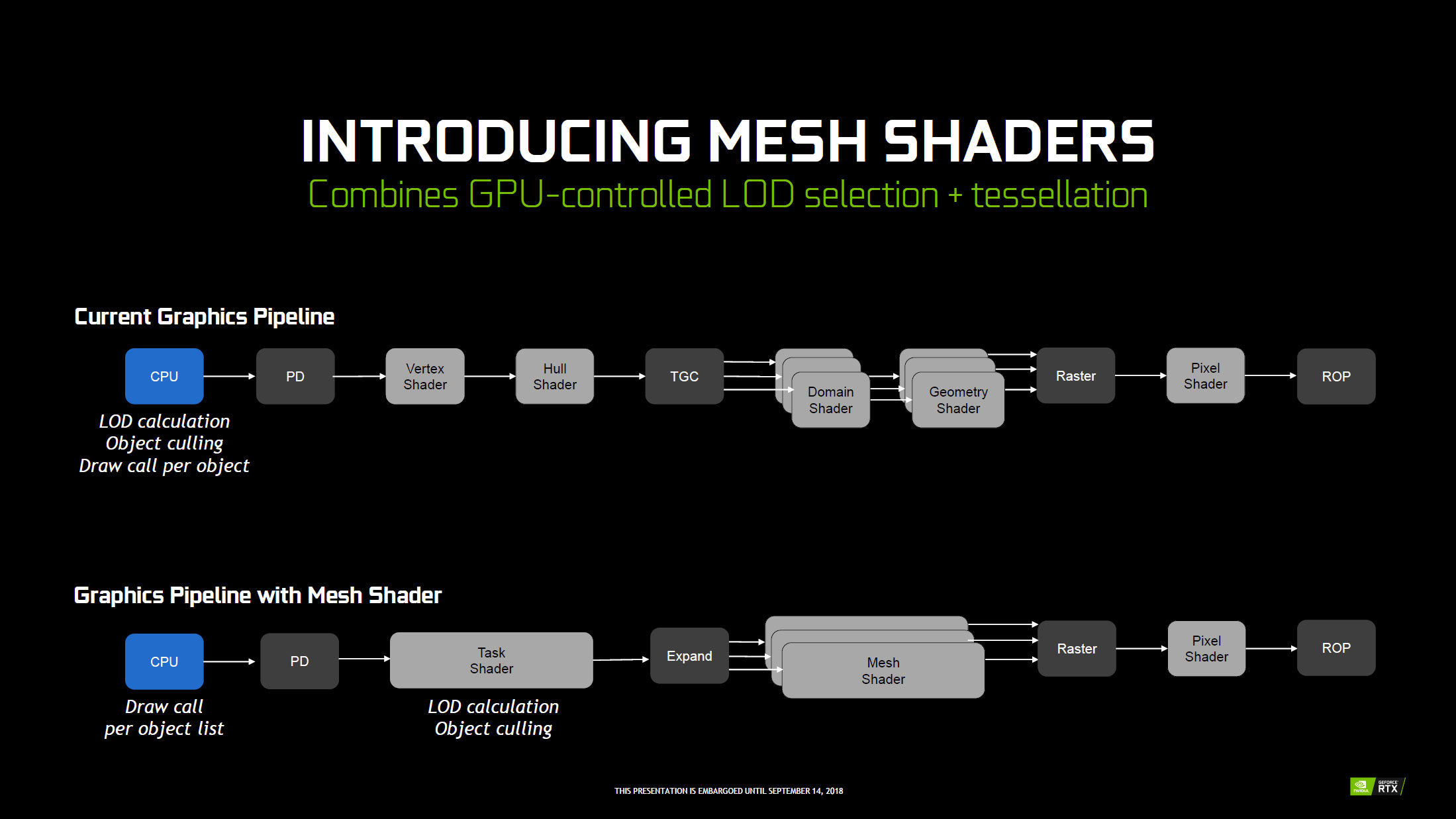
NVIDIA profite de ce lancement pour rappeler que dans la chaîne de rendu des images 3D, le CPU est toujours partie prenante même s'il est bien aidé (de plus en plus) par les GPU. Ainsi, Il est encore en charge de déterminer si un objet doit être rendu ou non (en dehors du champ de vision) et le niveau de détails à lui appliquer (selon la distance, etc.). Enfin, il doit lancer les commandes de rendu ou draw calls correspondantes. Ce dernier point peut d'ailleurs profiter des API bas niveau pour réduire drastiquement le coût CPU lié au rendu 3D, reste qu'il est toujours nécessaire pour ce dernier d'envoyer une commande de rendu par objet, ce qui peut vite devenir très lourd, si le nombre de ces derniers explose.
![Complexité géométrique [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/complexite_geometrique_t.jpg "Visionner en grand sur un magnifique pop-up")
Le caméléon, décidément pas avare en propositions, juge en conséquence que le mode de fonctionnement actuel peut être largement amélioré. Une des problématiques vient du fait que le "début" du pipeline graphique est très faiblement parallélisé. Pour tenter de changer cet aspect, il introduit pour les développeurs deux nouveaux types de shaders : les Mesh et Task. Le premier cité (qui donne son nom à cette technique), produit les triangles (avec ou sans tesselation) à destination du rasterizer. Par contre, il est capable de paralléliser ces opérations via plusieurs tâches simultanées, contrairement aux shaders qu'il remplace. Le task shader se positionne en début de pipeline et peut lui-aussi traiter en parallèle, une liste d'objets fournie par le développeur, alors qu'il aurait fallu pour le CPU lancer autant de draw calls que d'objets avec le rendu traditionnel. Il est également capable d'éjecter les objets masqués, et demander aux Mesh shaders d'appliquer le niveau de détails requis pour chaque objet (nombre de triangles et niveau de tesselation).
![Mesh Shaders [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/mesh_shaders_t.jpg "Cliquédélique !")
Comme toujours, ce sont les développeurs qui choisiront ou non d'utiliser cette technologie. AMD avait proposé lui aussi de modifier la gestion de la géométrie au sein du pipeline graphique avec Vega 10 et les Primitive shaders, remplaçant ainsi Vertex et Geometry shaders. La réponse du berger à la bergère ? Poursuivons avec une autre "nouveauté" des verts.
Depuis plusieurs générations, NVIDIA travaille à améliorer les performances de ses GPU en multipliant les sources de gains opportunistes. On pense immédiatement au Multi-Resolution Shading introduit avec Maxwell 2, suivi du Simultaneous Multi-Projection avec Pascal. L'objectif de ces technologies est de réduire le nombre de pixels calculés en réduisant la résolution là où l’œil ne se focalise pas (les côtés) ou en mutualisant le calcul de la géométrie en usage VR. Cela permet également d'adapter le rendu aux déformations optiques d'une lentille de casque VR ou la courbure d'un écran. Le Variable Rate Shading part d'une philosophie similaire, mais l'étend au traitement des pixels sur l'intégralité de l'image, en faisant varier le niveau de ce dernier, selon le besoin d'une scène. Il peut donc être utile dans les cas sus-mentionnés, mais aussi appliqué à d'autres situations.
![Usage variable rate shading [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/usage_variable_rate_shading_t.jpg "Ultra bouzotron HD max def")
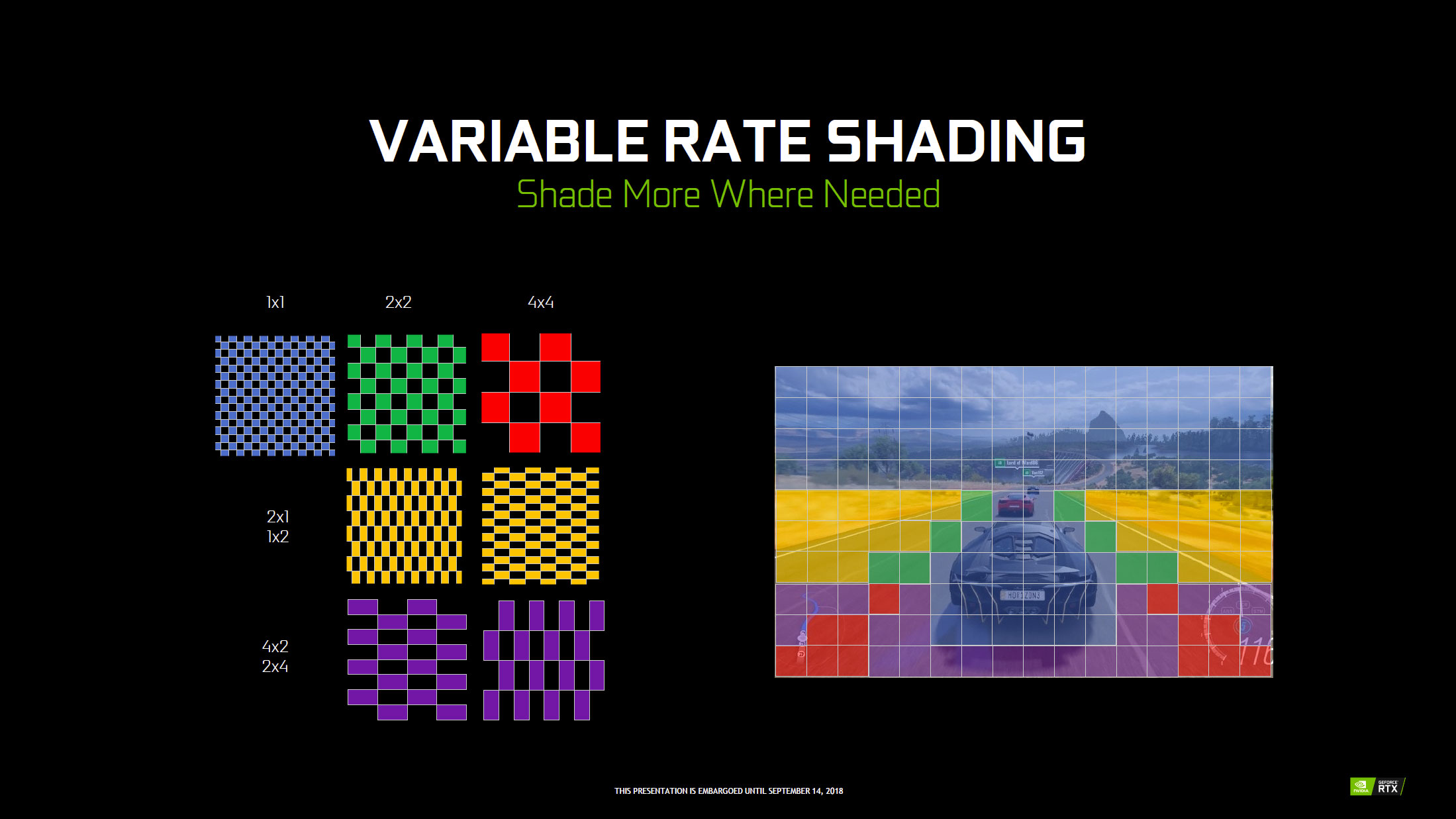
Le principe est de diviser le traitement des pixels en une multitudes de zones réduites (Tiles) de 16x16 pixels, et d'appliquer un niveau de shading variable (7 valeurs possibles) pour chacune d'entre-elles. Ainsi, au sein d'un Tile, le développeur peut choisir d'utiliser le taux nominal (1x1 = shading de chaque pixel), minimum (4x4 = shading identique de 16 pixels à la fois) ou une valeur intermédiaire. Il est même possible de dépasser le taux nominal (doublant, quadruplant, etc.) de shading de chaque pixel, en utilisation MSAA par exemple, outrepassant même - si besoin - le nombre de samples de ce dernier. L'objectif n'est donc pas forcément de dégrader l'aspect visuel du rendu, mais d'optimiser le besoin de calcul : niveau de granularité des détails maximal là où c'est nécessaire, le réduire à d'autres endroits (une surface uniforme fixe par exemple). Tout dépendra en fait des souhaits des développeurs à ce niveau. C'est ce que NVIDIA nomme Content Adaptive Shading, les cases colorées ci-dessous montrant le niveau de shading par tile.
![content adaptive shading [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/content_adaptive_shading_t.jpg "Ultra bouzotron HD max def")
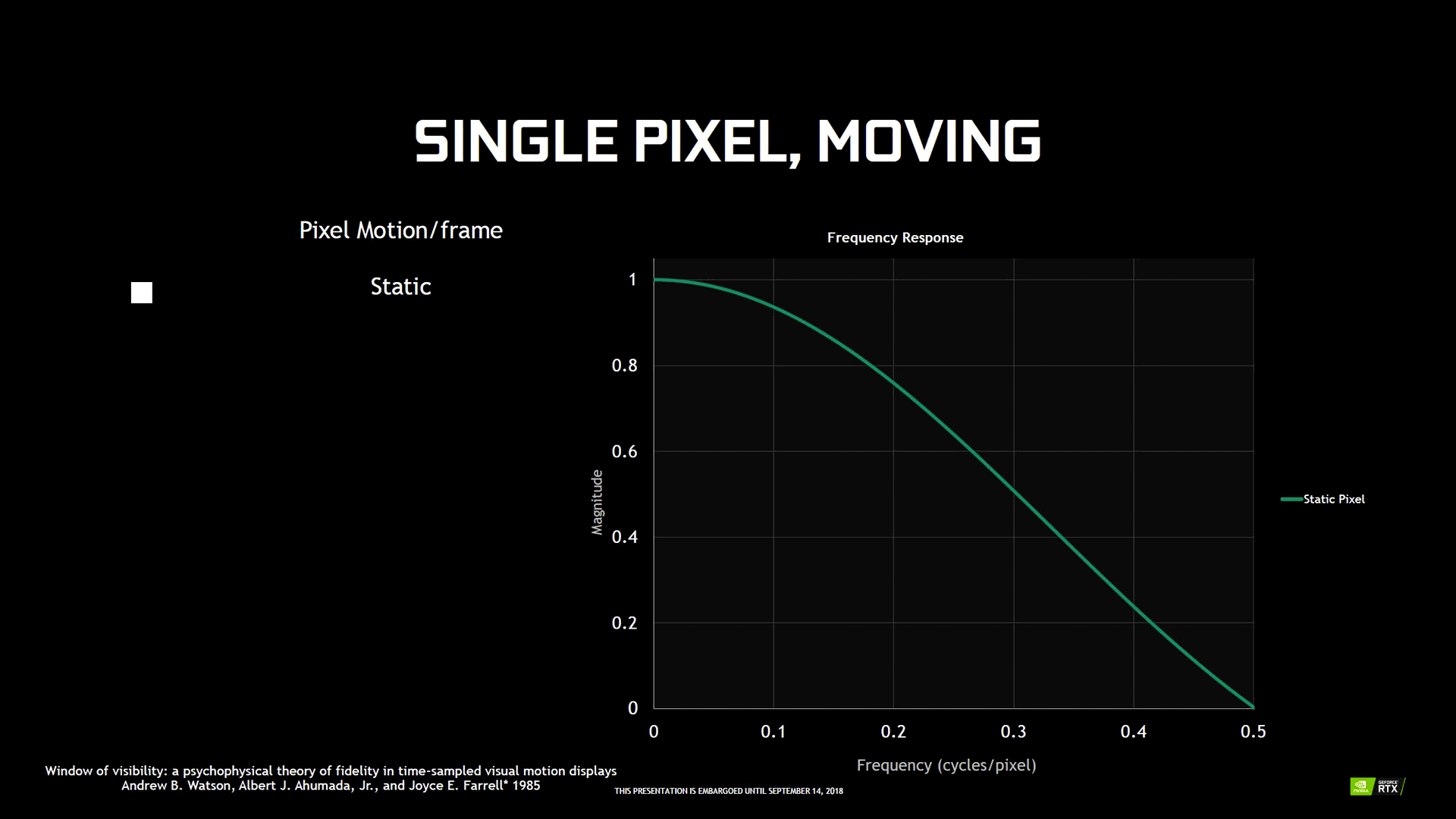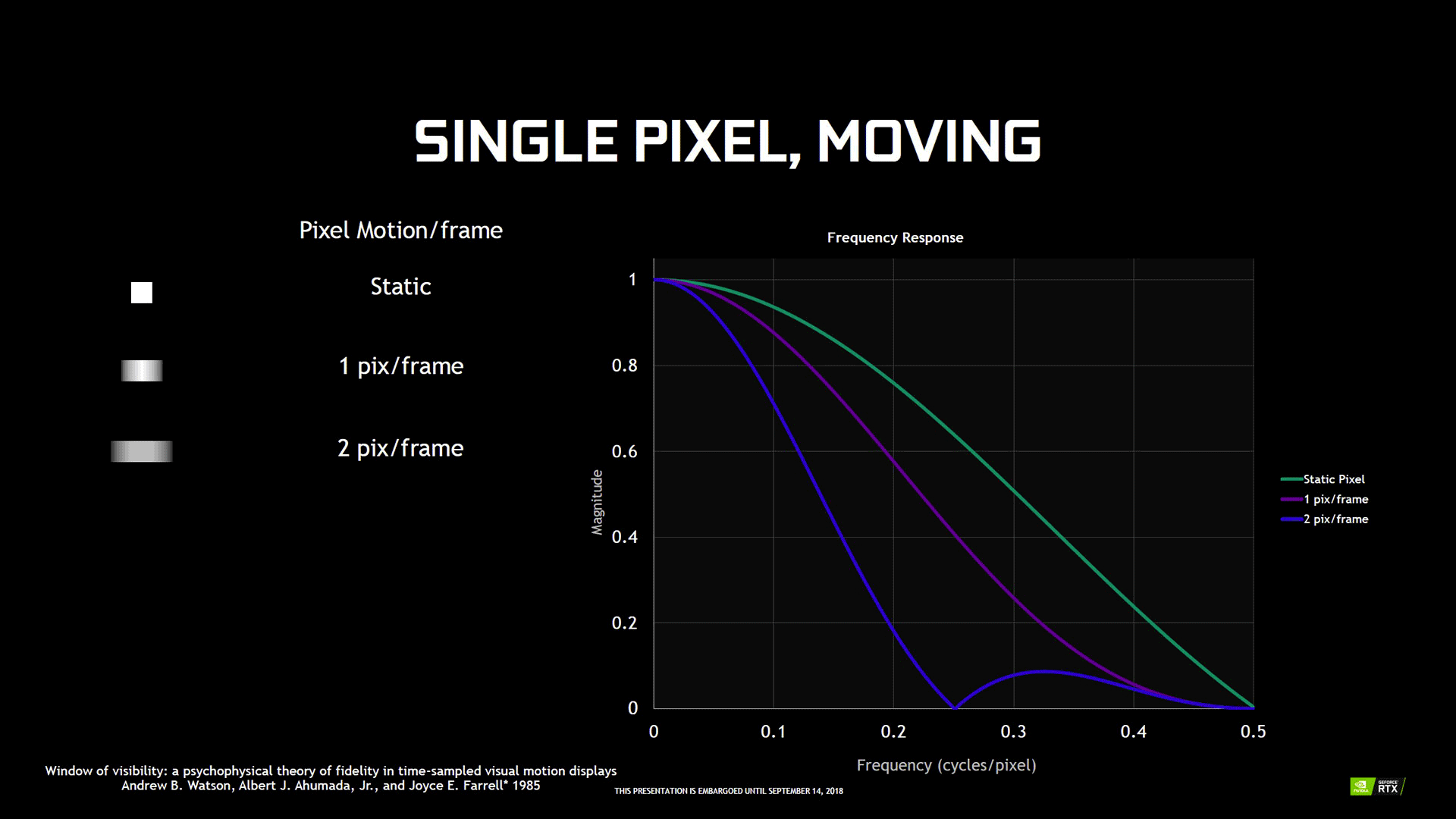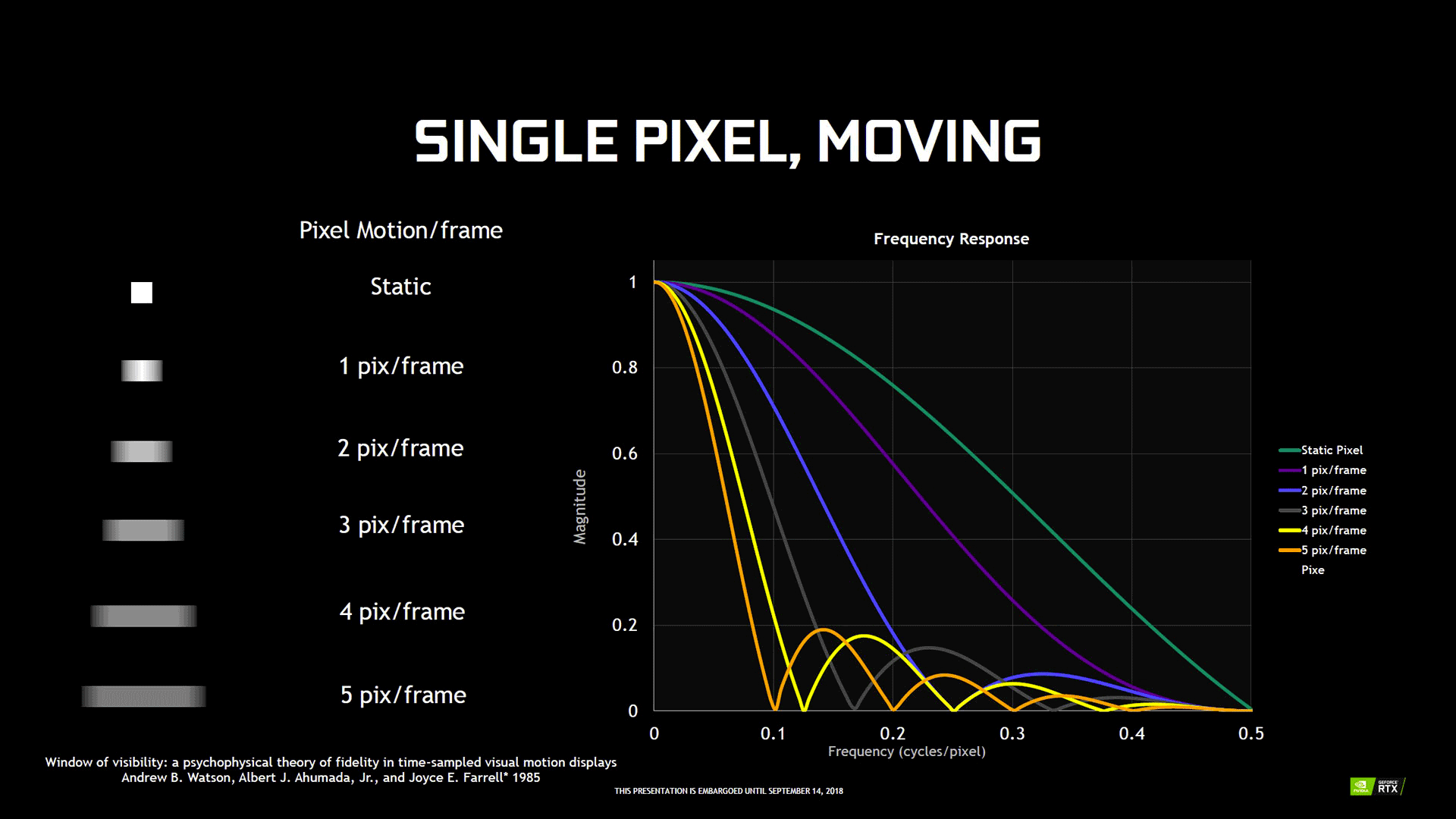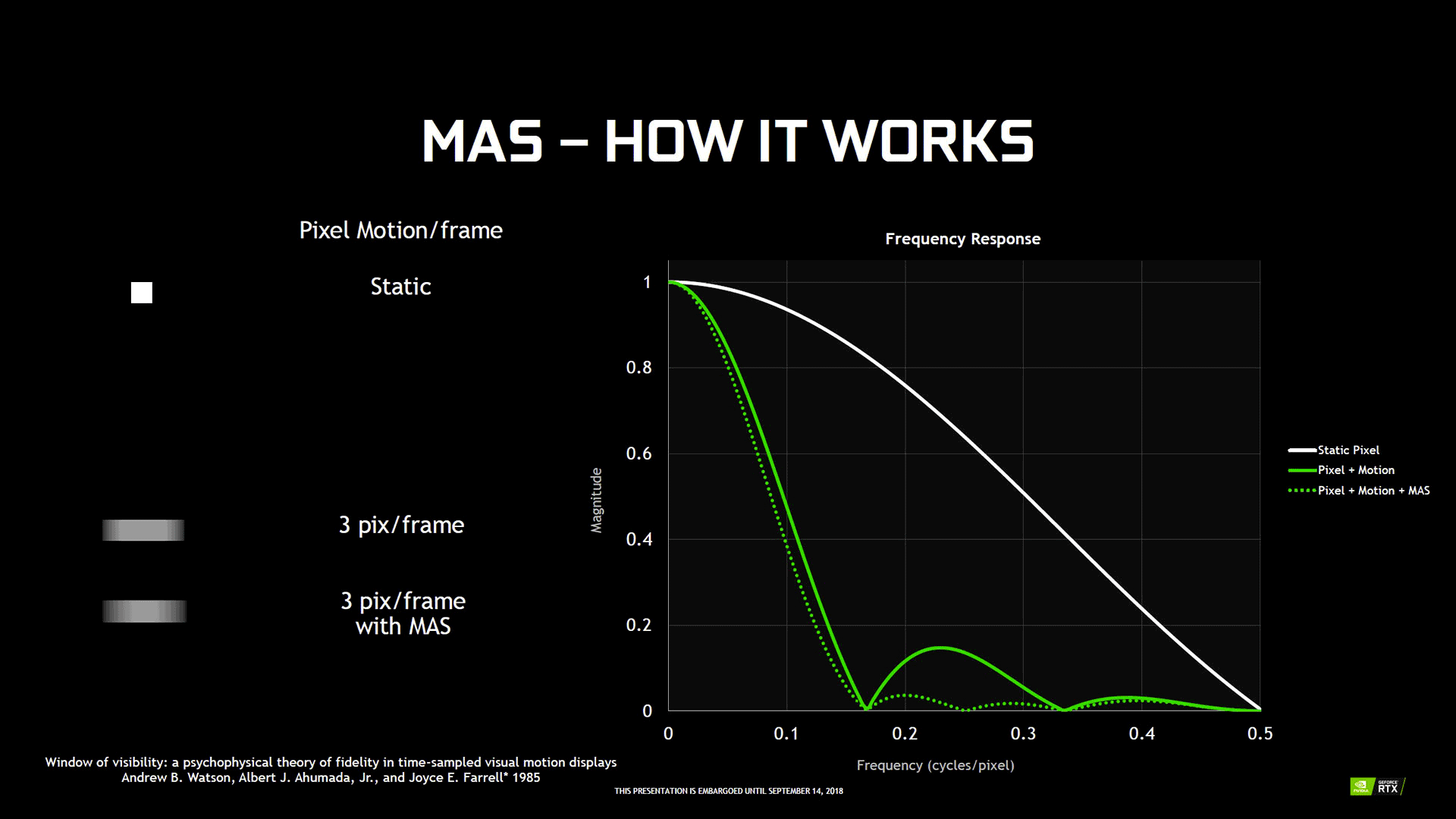
Mais le Variable Rate Shading peut également trouver une utilité dans les cas particuliers où un niveau de shading maximal est un pur gâchis, puisqu'il est n'est pas possible de différencier le taux maximal d'un autre réduit. Tout est une question d'optique et en particulier de persistance rétinienne et de technologie des afficheurs. L’œil humain est en principe "câblé" pour distinguer les détails lors de mouvements, pourvu que ces derniers soient linéaires et fluide. Mais sur un afficheur LCD, ces derniers sont reproduits différemment, puisqu'ils se "téléportent" d'un endroit à un autre en suivant le taux de rafraîchissement de l'écran.
![perception rétinienne image animée [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/perception_retinienne_image_anime_t.gif "Visionner en grand sur un magnifique pop-up")
Un écran 144 Hz sera donc moins affecté qu'un modèle plus traditionnel à 60 Hz, mais sur des animations extrêmement rapides avec beaucoup d'amplitude (déplacement du pixel), une sensation de flou pourra apparaître également, l'amplitude jouant un rôle important dans ce domaine (cf. image ci-dessous).
![Pourquoi le motion adaptive shading ? [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/motion_adaptive_shading_t.gif "3N C11QU4N7 C357 P1U5 6r4ND")
Le Motion Adaptive Shading utilise donc le principe du Variable Rate Shading, pour économiser de la puissance de traitement, là où l'impact visuel sera imperceptible (zone de déplacement maximale). Ce gain pourra alors être utilisé pour augmenter par exemple le taux d'images par seconde ou la qualité de zones ne se déplaçant pas ou à très faible amplitude. L'image ci-dessous illustre ce principe de fonctionnement.
![Motion adaptive Shading [cliquer pour agrandir]](/images/stories/articles/gpu/turing/rtx_2080/variable_rate_shading_t.jpg "Cliquédélique !")
Notons également qu'il existe une troisième technique mettant en oeuvre le VRS, il s'agit du Foveated Rendering. Ce dernier s'appuie sur la perception réduite de l’œil en périphérie, et donne donc l'opportunité aux développeurs d'utiliser cette particularité pour économiser du budget de traitement à ce niveau.
Une autre fonctionnalité intéressante mis en avant par NVIDIA est le TSS ou Texture Space Shading. Ce dernier autorise le découplage des opérations de rastérisation / Z-testing de celles de shading, permettant ainsi de les réaliser à une vitesse différente ou à un moment différent. Un exemple illustrant cette possibilité consiste à réaliser via une opération compute pure (ne sollicitant pas le pipeline graphique), un éclairage complexe sur des matériaux et de stocker le résultat obtenu dans une texture. Lorsque c'est nécessaire, cette dernière est utilisée par un simple échantillonage lors de la rastérisation. Ce découplage permet de réduire la charge lors du rendu et ce quelque soit la complexité de l'éclairage utilisé en amont tout en limitant l'aliasing.
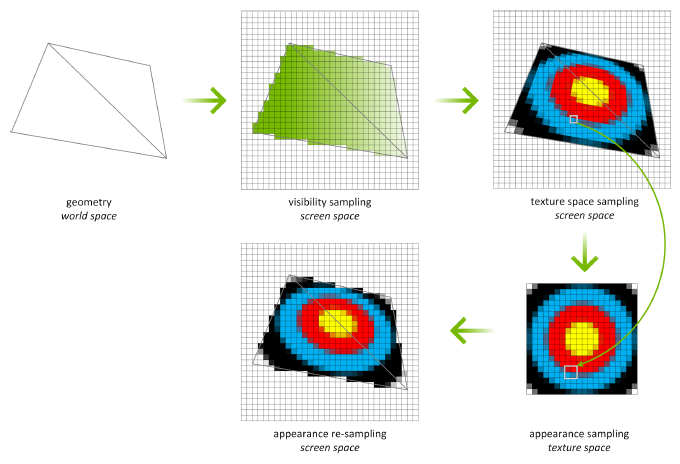
A noter que le TSS peut également s'avérer très utile pour la VR, qui nécessite un rendu stéréo (pour chaque oeil). Il permet ainsi de réutiliser pour le rendu du second oeil une grande parte de celui du premier, limitant ainsi le besoin aux seuls texels qui ne sont pas valides (par exemple un objet d'arrière plan qui était masqué sur le premier oeil du fait de la perspective, etc.), limitant d'autant la charge sur le pipeline graphique.

Pour finir sur les fonctionnalités, NVIDIA précise que Turing supporte à présent sous DX12, le Tier 3 pour Resource Binding et Tier 2 pour Resource Heap, revenant ainsi au niveau de VEGA 10 à ce niveau.
Intéressons-nous à présent à quelques autres nouveautés, principalement hardware, en page suivante.
|
|
| Un poil avant ?Live Twitch • Démo de Forza Horizon 4 sur PC | Un peu plus tard ...Lara benchée par tous les... GPU bien sûr ! | |
| 1 • Préambule |
| 2 • Turing, une architecture qui évolue |
| 3 • RT Cores / Tensor Cores / Rendu hybride |
| 4 • 3 cartes = 3 GPU |
| 5 • |
| 6 • VR, Vidéo & Encodage / NV Scanner / SLi |
| 7 • Conclusion |