NVIDIA a des idées pour spécialiser ses GPU "trop généralistes" au machine learning |
————— 09 Avril 2021 à 13h15 —— 12692 vues



NVIDIA a des idées pour spécialiser ses GPU "trop généralistes" au machine learning |
————— 09 Avril 2021 à 13h15 —— 12692 vues
Avec l’écosystème CUDA, lancé en 2007 par NVIDIA, les cartes graphiques de la firme peuvent également effectuer du calcul généraliste via une interface C permettant de déporter une partie de la charge d’un programme sur le GPU, qui prend alors le nom de General Purpose GPU, ou GPGPU. Bien évidemment, tout cela n’est pas si simple : les cœurs GPU sont bien moins puissants que les cœurs CPU, rendant l’accélération intéressante uniquement pour des tâches spécifiques tel le calcul scientifique. Depuis, l’eau a coulé sous les ponts : AMD s’y est également mis avec OpenCL, et le machine learning a explosé, influençant ainsi les cartes graphiques qui incorporent désormais des accélérateurs de calcul matriciel, d’où la divergence des gammes entre les professionnels et les joueurs.
Cependant, la base des puces reste similaire, et pour cause : développer une microarchitecture est coûteux, qu’il s’agisse de design, mais aussi de production et de vérification ; les entreprises doivent ainsi mutualiser les coûts. Dans cette optique, cinq chercheurs de chez NVIDIA se sont penchés sur la possibilité de développer un GPU modulaire, basé sur un tronc commun pour le calcul haute performance, mais facilement extensible au moyen de chiplets à d’autres applications — comprenez « au machine learning ». Son nom de code ? COPA-GPU pour Composable On-PAckage GPU.
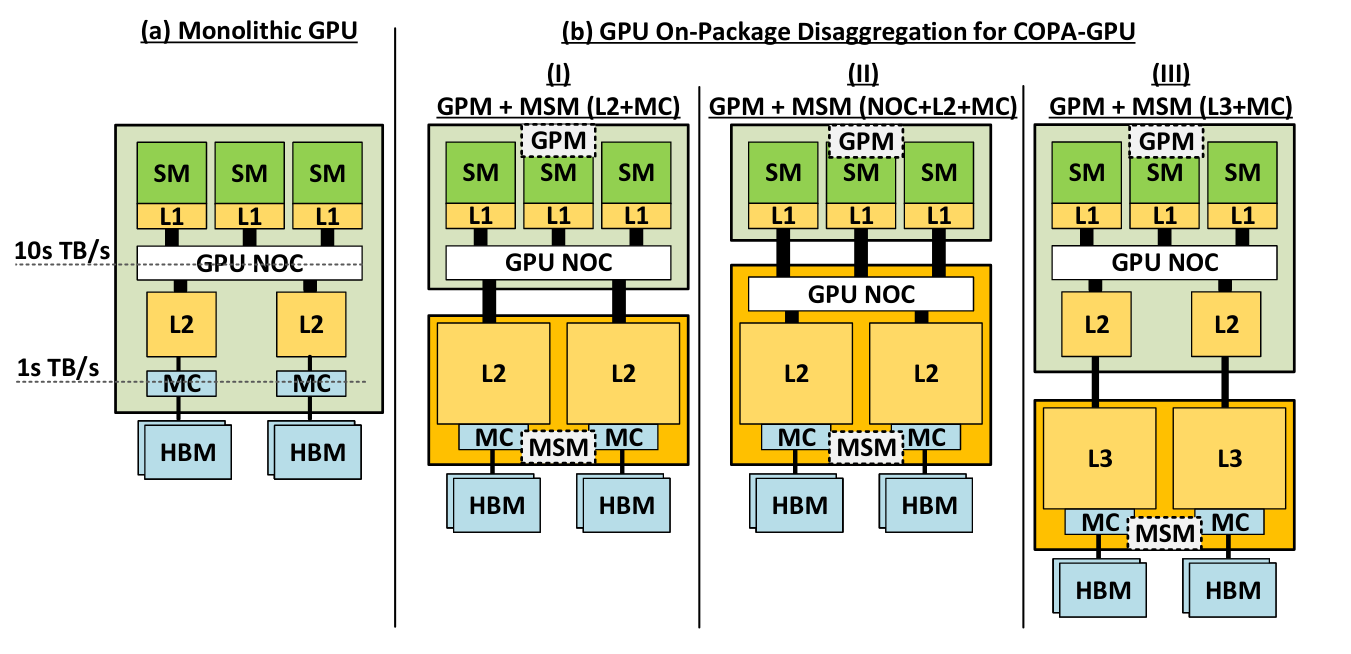
Divers diagrammes logiques pour ce COPA : monolithique, à l’interconnect (NOC, pour Network-On-Chip) faisant partie du die de calcul, ou du cache L2, ou, carrément, un système inspiré des CPUs à trois niveaux de cache. Notez le « MSM », pour Memory Submodule, « GPM », pour GPU Module et « MC » pour Memory Controller
Sur le papier, ce projet propose toute la sauce en vogue : des chiplets en veux-tu en voilà — il faut dire que la solution est ô combien adaptée à la réutilisation de dies polyvalents et à leur expansion — de la HBM, application pro obligeant, et la classique décomposition du GPU en Stream Multiprocessor chère aux verts. Le principal objectif de ce COPA n’est clairement pas de proposer un GPU ultime pour le futur de la firme, mais d’explorer, tester et défricher les arrangements microarchitecturaux possibles étant donné les technologies actuelles. Par exemple, quel que soit l’agencement retenu, la polyvalence du GPM s’effectue au détriment de sa taille ; et les options externalisant le L2 s’avèrent impossibles du fait du manque solutions techniques pour une communication à très (très !) haut débit/faible latence inter-die.
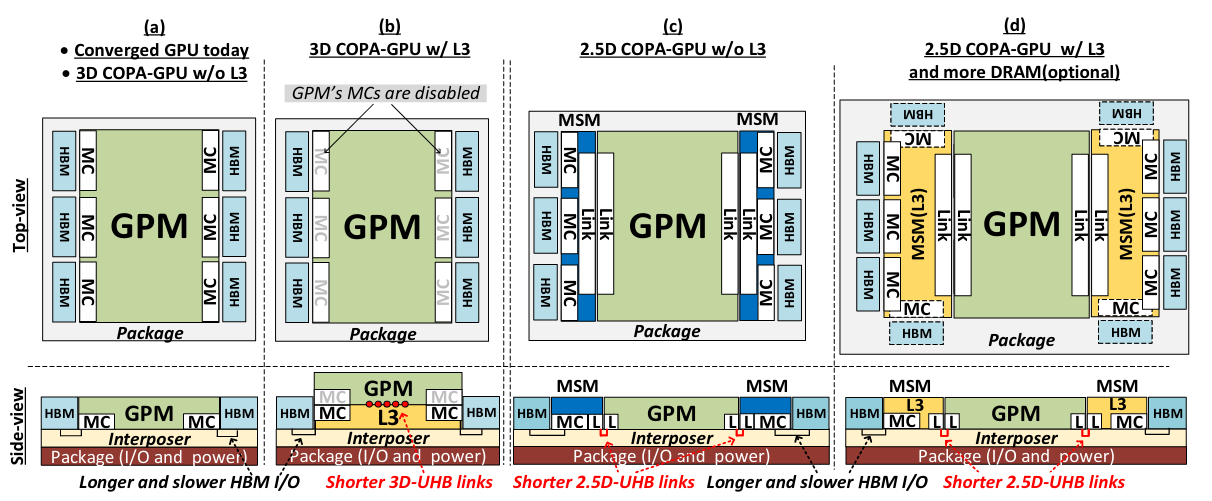
COPA-GPU est, sur le plan de l’intégration, davantage un passage en revue des technologies disponibles et de leurs avantages qu’un prototype : 2,5 D, interposer, empilement... Tout y est !
Qu’il s’agisse de la production (même d’un simple tape-out, prototype sur silicium) ou de performances réelles — les simulations donnant diverses puissances en fonction de l’interconnect, de la VRAM, du cache ou encore du nombre d’unités de calcul retenu —, rien n’est disponible à l’heure actuelle, et pour cause : ces designs proviennent de la branche « Recherche » de NVIDIA, et non « Recherche et Développement ». Autrement dit, la firme peut aussi bien choisir d’investir dans le projet pour en dériver une puce commercialement acceptable, ou laisser ce travail de côté si le caméléon ne croit pas en sa rentabilité. Repris ou non, ce genre d’étude demeure toujours instructif quant aux tendances en vogue chez les architectes GPU : de quoi y voir une puce à chiplets chez NVIDIA à moyen terme ?
| Un poil avant ?Des potins pour le DG2 d'Intel, quel niveau graphique attendre ? | Un peu plus tard ...45 jeux pour départager RX 6700 XT et RTX 3070 | |





















