Test • AMD Ryzen 9 7950X, 7900X, Ryzen 7 7700X & Ryzen 5 7600X : Zen 4, AM5, X670E, B650E & DDR5 |
————— 26 Septembre 2022



Test • AMD Ryzen 9 7950X, 7900X, Ryzen 7 7700X & Ryzen 5 7600X : Zen 4, AM5, X670E, B650E & DDR5 |
————— 26 Septembre 2022
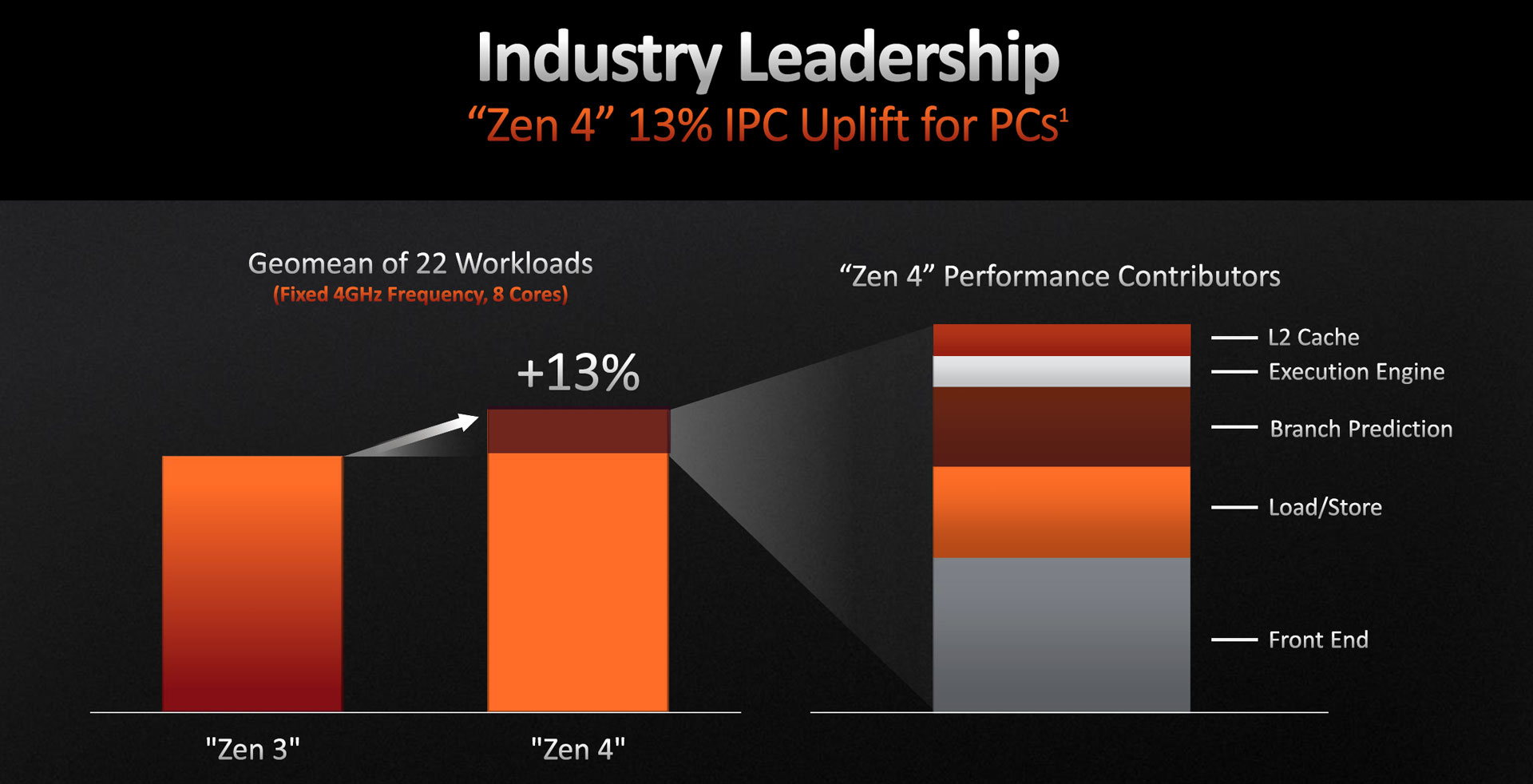
Alors que Zen 3 inaugurait une refonte en profondeur de la microarchitecture incluant une nouvelle organisation des CCX (de 4 à 8 cœurs) et un élargissement du pipeline (14 voies d’exécutions différentes), la mise à jour de Zen 4 est un peu plus sage. En effet, fort d’un back-end gonflé aux hormones de la dernière version, les efforts ont été concentrés sur l’optimisation de son utilisation, ce qui se traduit par deux axes principaux de progression : le front-end permettant d’exprimer toujours plus de parallélisme, limité à la prédiction de branchement, et le sous-système mémoire, histoire de limiter au maximum les cycles perdus à attendre une donnée (stall) provenant de la RAM. Officiellement, le gain en IPC s’élève à 13 % ; vous verrez dans ce test si la promesse est tenue.
![Répartition des gains d'IPC [cliquer pour agrandir]](/images/stories/articles/cpu/zen4/slide_gains_ipc_t.jpg "Même pas cap' de cliquer")
En parallèle à l’IPC en hausse de par les changements architecturaux, AMD a retravaillé son implémentation afin de se plier au nouveau procédé de gravure — le 5 nm de chez TSMC —, ce qui permet une montée en fréquence conséquente, et donc des gains en puissance de calcul brut. Rajoutez le passage à la DDR5 pour gonfler les débits mémoires, et vous comprenez pourquoi le back-end n’a pas eu besoin d’être revu en profondeur sur cette génération-là. Voyons maintenant tout cela en détail.
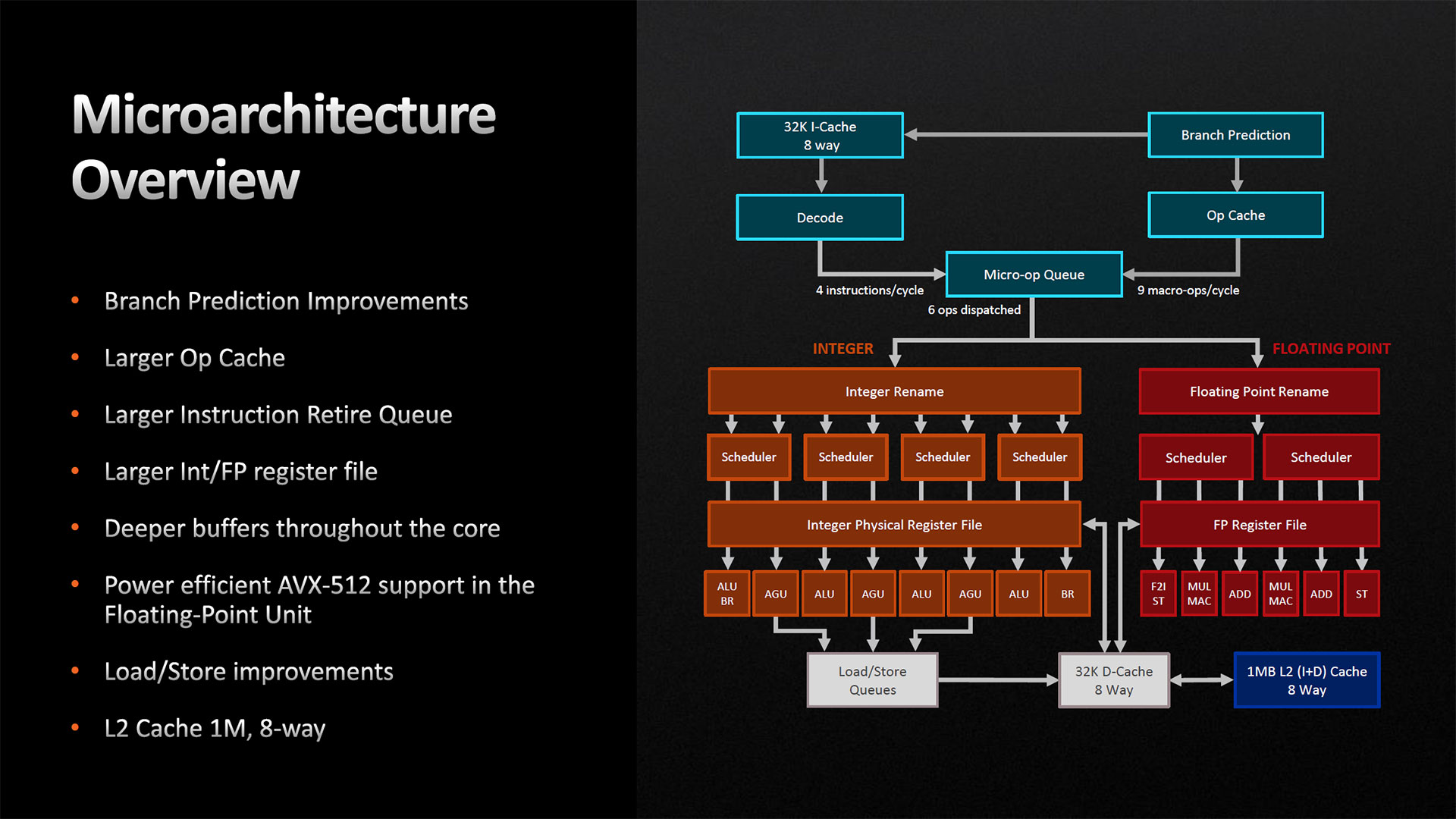
![Vue globale de la microarchitecture [cliquer pour agrandir]](/images/stories/articles/cpu/zen4/slide_microarch_overview_t.jpg "La magie de la loupe, sans loupe")
Sachant que les charges de travail non-scientifiques exposent en moyenne un branchement toutes les 5 instructions, le front-end se doit de prédire correctement la quasi-totalité des instructions du ReOrder Buffer (ROB) - 320 µOPs sur cette nouvelle micro-architecture. Avec les mains, cela signifie que près de 70 branchements doivent être correctement prédits pour que le CPU fonctionne à sa vitesse optimale : un travail de titan !
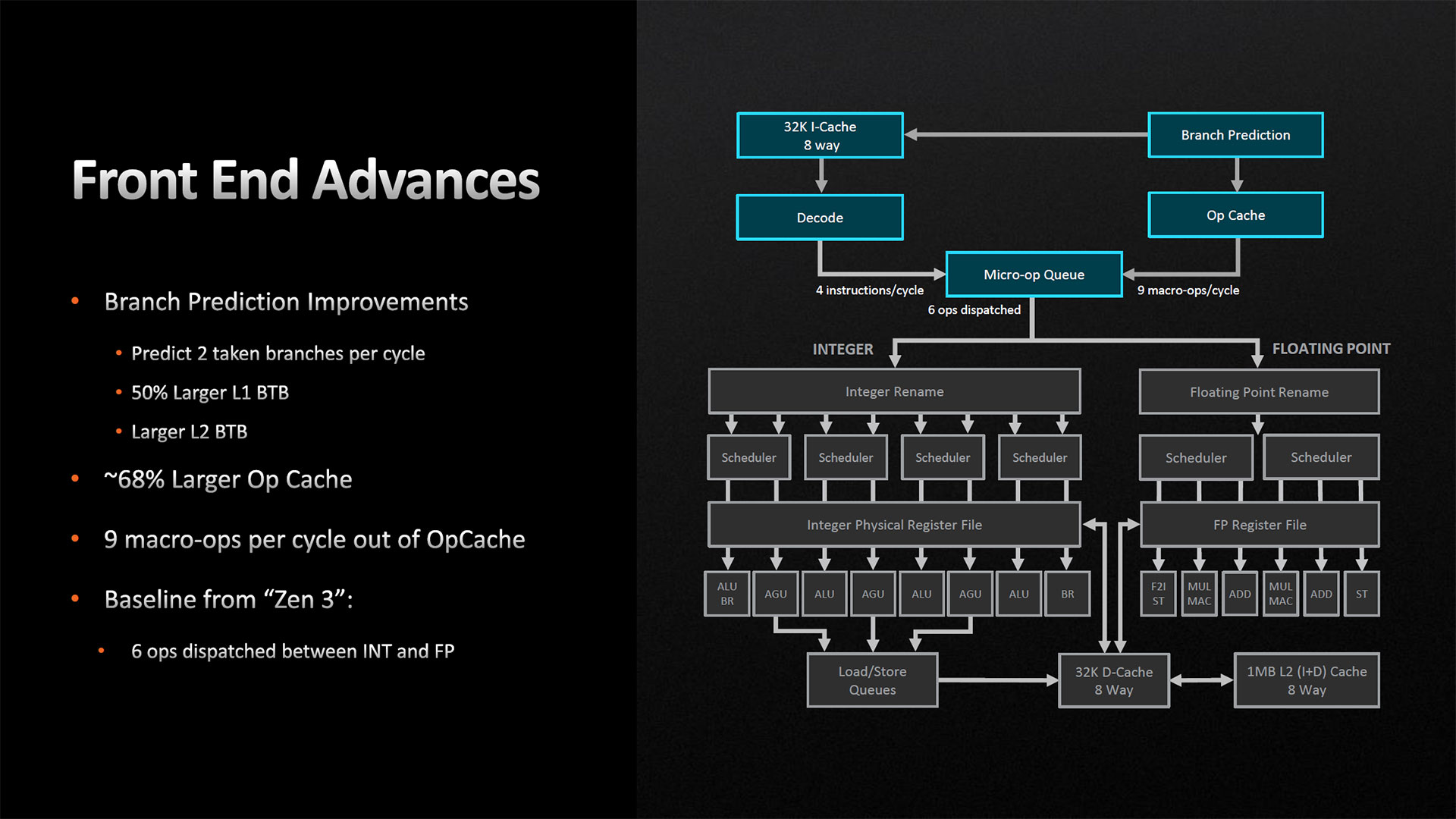
Pour cela, rien de magique : le cache des micro-opérations, servant à masquer le coût de décodage des instructions déjà vues auparavant dans le programme, passe de 4 kilo-entrées à 6,75 kilo-entrées (+68 % par rapport à Zen 3) et fournit 9 micro-ops par cycles, potentiellement fusionnés pour gagner en place. L’étage prédisant les branchements est également gonflé en augmentant de 50 % son L1 (passant à 2x 1,5 kiloentrées — une division par 2 imposée par le SMT) ; et son cache de niveau 2 augmente également, mais dans une moindre proportion : seulement 500 entrées de plus, de quoi passer à 7k entrés par cœur logique. Témoins de la marge de progression de Zen 3, le débit vers le ROB et les unités d’exécutions ne change pas avec 6 µOps/cycle, à partager entre pipeline entier et pipeline flottant — une spécificité de l’architecture rouge.
![Front End [cliquer pour agrandir]](/images/stories/articles/cpu/zen4/slide_front_end_t.jpg "Cliquédélique !")
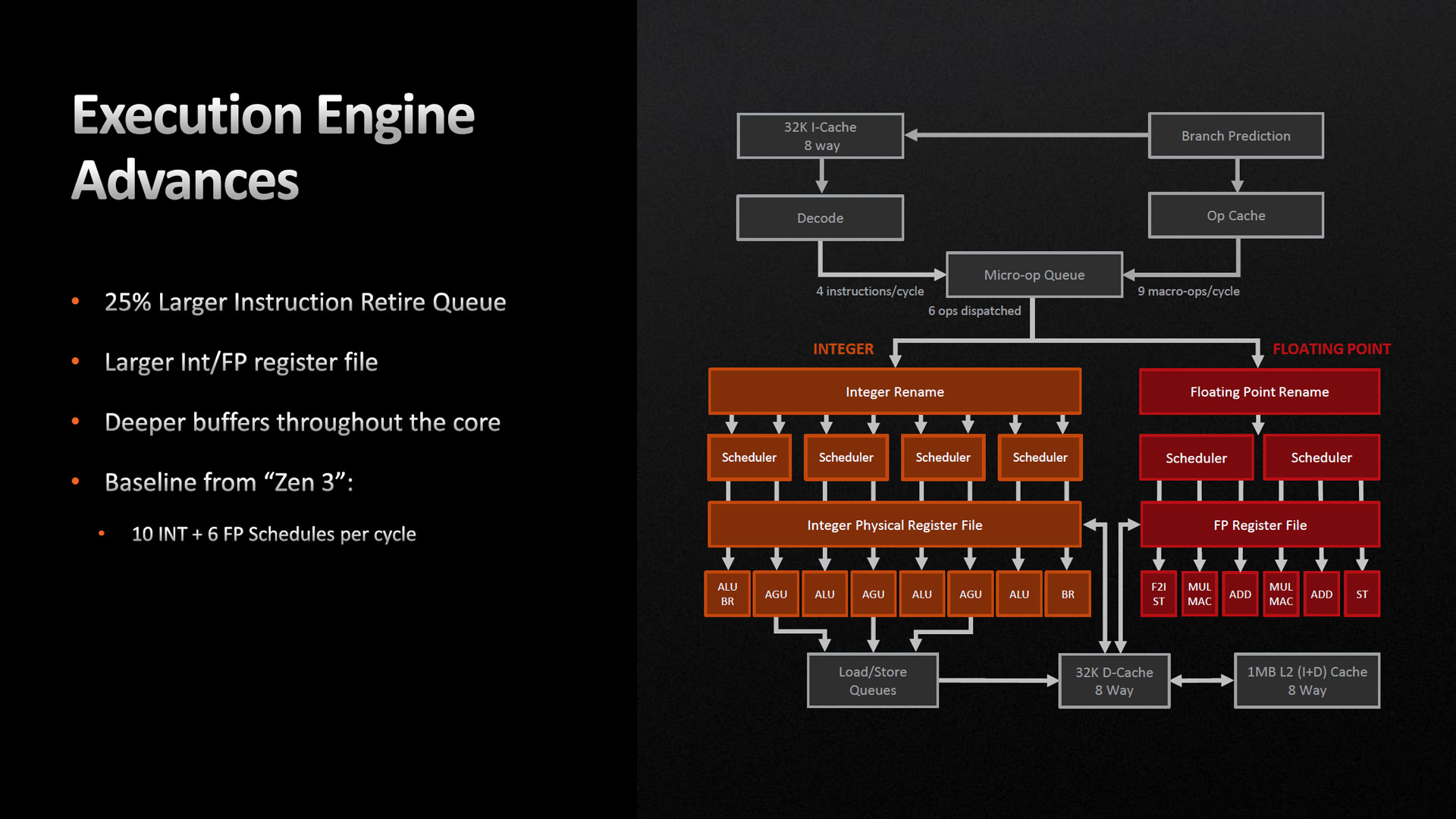
Si le pipeline n’est pas retouché dans sa puissance brute de calcul (comprenez, sa largeur), ce n’est pas pour autant que le back-end fait du sur-place. En effet, le ROB grandit pour atteindre 320 entrées, contre 256 précédemment : de quoi garder les unités de calcul existant bien occupées ! Pour garder traces des lectures et écritures de ces instructions, le nombre de registres virtuels entiers passe à 224 (contre 192 auparavant), et 192 pour ceux flottants (contre 160 sur Zen 3). Pour information, ces registres « virtuels » permettent de stocker les valeurs intermédiaires des registres X86 exposés à l’utilisateur (RAX, RBX, etc) ; permettant ainsi de traiter en parallèle deux chaines d’opérations utilisant des registres communs, mais des données différentes (typiquement, deux mises à jour de deux cases mémoires distinctes utilisant le même registre pour le traitement). Pour le reste, les 8 +6 ports de calculs sont toujours présents, et offrent au maximum un débit de 8 µOps/cycle, limités par le Retire Buffer ; tout ce beau monde étant alimenté par 4 scheduler sur le pipeline entier, et 2 pour le pipeline flottant.
![Unités d'exécution [cliquer pour agrandir]](/images/stories/articles/cpu/zen4/slide_execute_engines_t.jpg "Si vous cliquez, vous cliquez.")
Une des majeures avancées présentées par AMD réside dans le support de l’AVX-512 : des extensions vectorielles permettant de manipuler en une instruction une quantité de données deux fois supérieure à ce que l’AVX2 précédent proposait. Du fait de son intégration dans les Xeon Phi, puis dans Skylake et ses successeurs, l’AVX-512 n’est pas un seul ensemble de fonctionnalité, mais se raffine en multiples sous-ensembles. Grosso modo, Zen 4 se met ici à jour sur Sunny Cove (Ice Lake), supportant ainsi VNNI (pour les réseaux de neurones) et GFNI (pour la cryptographie) ainsi que le BFloat16.
![AVX-512 [cliquer pour agrandir]](/images/stories/articles/cpu/zen4/slide_avx512_t.jpg "Visionner en grand sur un magnifique pop-up")
En interne, aucune unité AVX-512 n'est en fait intégrée, l'exécution étant en fait effectuée en interne par les deux unités AVX présentes. De ce fait, la puissance théorique est la même, ce que AMD présentait sous le doux sobriquet de « Double Pumb ». Si cela semble ridicule à première vue, sachez que la stratégie retenue par Intel sur Sunny Cove version grand public est similaire, ainsi que les CPU d’entrée de gamme des serveurs : si le silicium est bien présent pour une "vraie" unité AVX-512, cette dernière se fait concurrencer par les deux unités AVX offrant conjointement un débit identique ! Pour autant, les instructions AVX-512 permettent de désengorger le front-end : autant dire que la chose est loin d'être inutile, en plus de fournir une interface fonctionnelle pour les développeurs désireux d'utiliser cette nouvelle fonctionnalité. Notez que leur utilisation n’impactera pas la fréquence, ce qui n’était pas le cas sur les premières implémentations bleues, avant que la firme ne cesse de communiquer à ce sujet.
![Extensions AVX-512 [cliquer pour agrandir]](/images/stories/articles/cpu/zen4/slide_avx512_ext_t.jpg "La magie de la loupe, sans loupe")
C’en est tout pour ce qui concerne la microarchitecture côté exécution, voyons sur la page suivante les progrès effectués du côté des caches et de la mémoire.
|
|
| Un poil avant ?Intel Arc A770, très rapidement maintenant ? | Un peu plus tard ...Ventes de jeux vidéo : l'île aux singes, vite fait | |