Test • Zen 3 : Ryzen 9 5950X & 5900X / Ryzen 7 5800X / Ryzen 5 5600X |
————— 05 Novembre 2020



Test • Zen 3 : Ryzen 9 5950X & 5900X / Ryzen 7 5800X / Ryzen 5 5600X |
————— 05 Novembre 2020
Si le refresh Zen+ n’avait été à Zen premier du nom, qu’un simple boost de la fréquence grâce à une technologie de lithographie plus avancée, laissant inchangée la microarchitecture interne, tel n’est pas le cas de Zen 3. En effet, tout l’inverse se produit ici : cette troisième itération reprend le procédé 7 nm de TSMC inauguré par Zen 2, et se contente de modifier l’organisation interne des CPU pour offrir plus de performances — nous verrons dans quelle mesure dans la suite de ce test. Ironie du sort, ce saut technologique suit, finalement, la stratégie Tick-Tock qui avait fait les beaux jours d’Intel.
![Evolution par rapport à Zen 2 [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/vszen2_gains_t.jpg "Visionner en grand sur un magnifique pop-up")
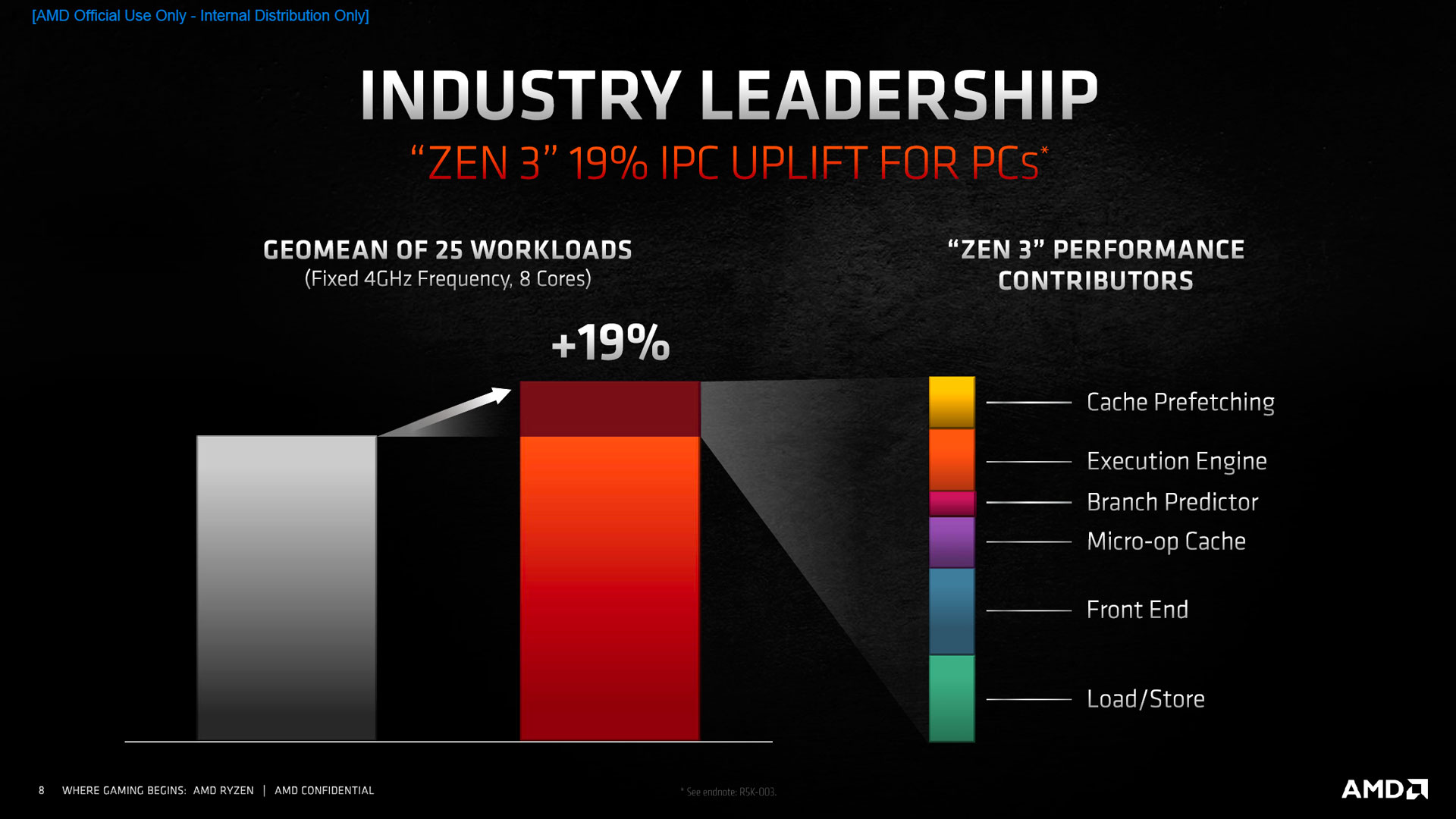
+19 % d’IPC au prix d’une restructuration d’à peu près tous les éléments de la puce
Lors de la mise à jour vers Zen 2, la microarchitecture avait comblé sa principale lacune face à Skylake en doublant sa capacité de calcul (ainsi que les chemins de données pour les chargements/rangements) du côté du calcul flottant. Pour gagner toujours plus de performances en partant d’un CPU équilibré, AMD a emprunté de manière logique un chemin semblable à son concurrent sur Sunny Cove : un pipeline d’exécution plus large, qui s’accompagne pour le nourrir, d’une bande passante mémoire accrue, ainsi qu’une révision des principaux mécanismes à l’œuvre, à savoir l’ordonnancement de micro-instructions et la prédiction des branchements. Officiellement, le gain moyen est de 19 % d’IPC (métrique dont nous nous méfions toujours), soit plus que lors du passage à Zen 2 (15 %).
![Contributeurs aux gains [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/vszen2_contributeurs_t.jpg "3N C11QU4N7 C357 P1U5 6r4ND")
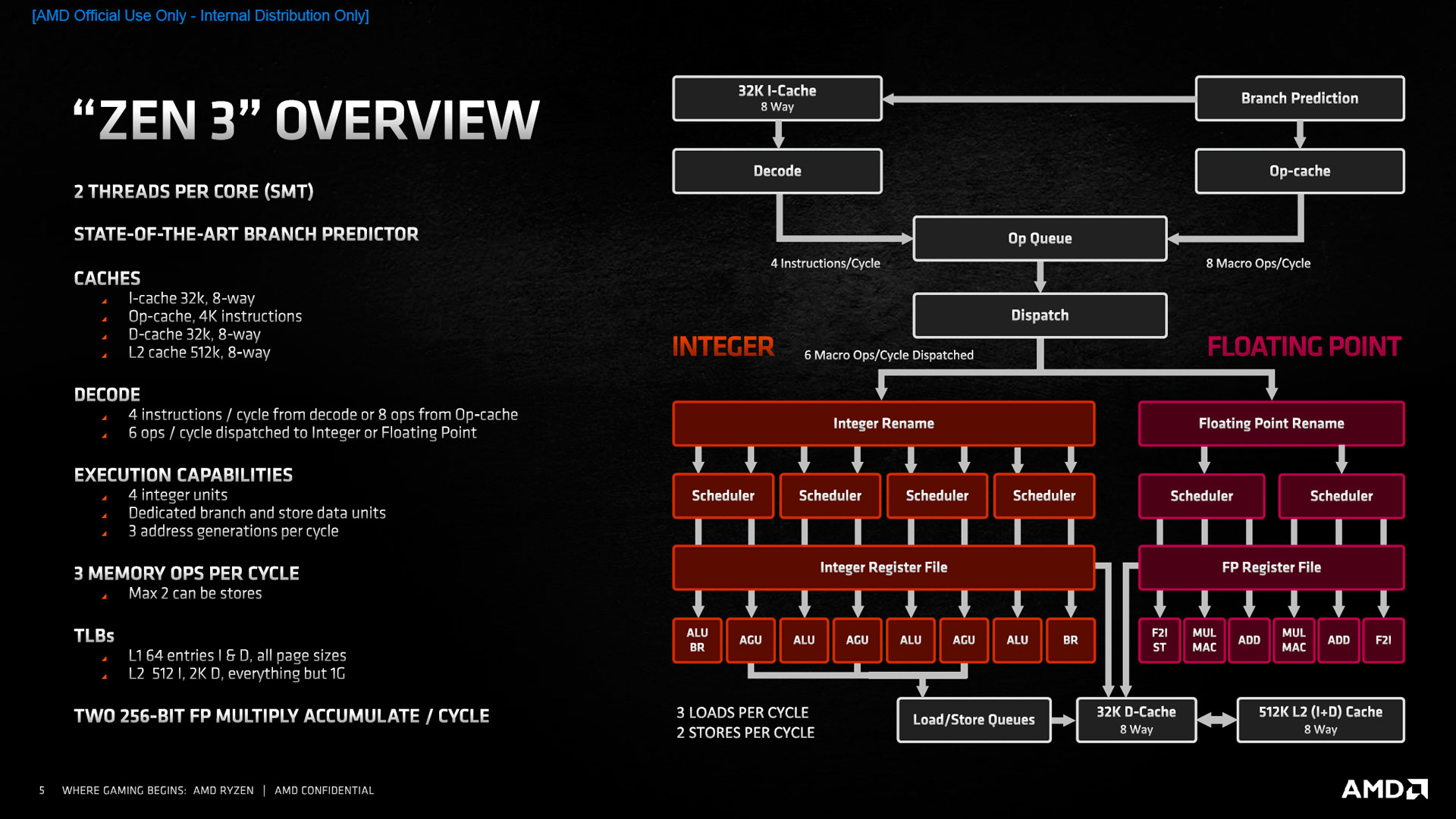
Débutons par une vue d’ensemble de la microarchitecture, telle que schématisée par AMD ci-dessous, avant de détailler point par point les évolutions à chaque "étage".
![Zen 3 : vue d'ensemble [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/zen3_overview_t.jpg "Si vous cliquez, vous cliquez.")
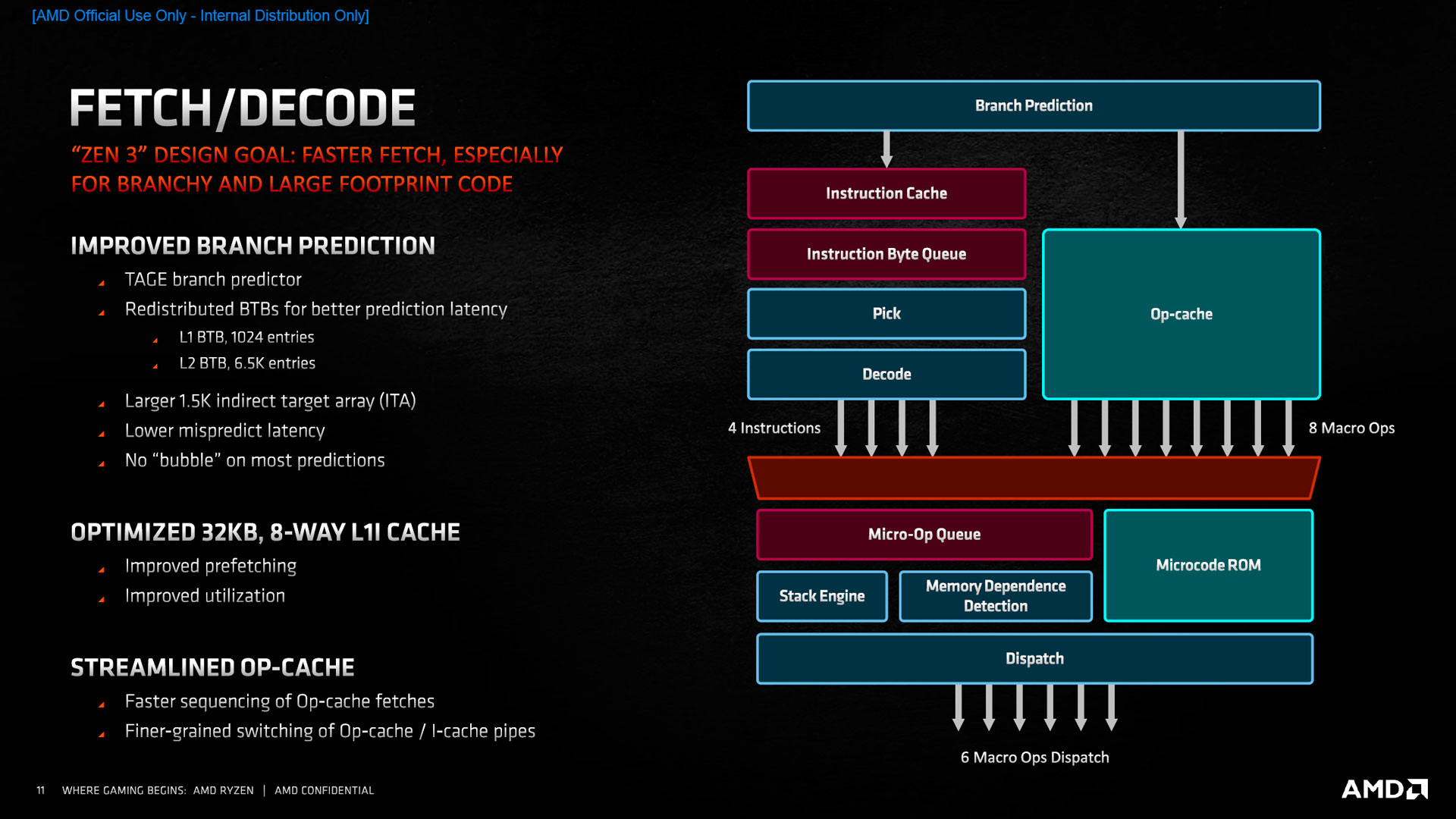
Dans un processeur, le front-end compose la partie dédiée au décodage des instructions formées par le programme source, ainsi que le prédicateur de branchement, tout deux chargés de remplir une mémoire tampon de macro-opérations, qui sont par la suite traduites en micro-opérations dans le ROB (Reorder Buffer). Qu’il s’agisse de l’étage de décodage ou de la prédiction de branchements, la bande passante reste inchangée, avec respectivement 4 instructions/cycle et 8 macro-ops/cycle (anciennement dénotées « instructions fusionnées »). La taille du cache d’instruction ne change pas avec toujours 32 ko, bien que le prefetching et « l’utilisation » soient revus. Attention, par rapport aux terminologies d’Intel, AMD considère qu’une macro-op est, globalement, une instruction x86 « simple » contenant éventuellement de l’arithmétique de pointeur afin d’accéder aux variables concernées, éventuellement fusionnée avec des instructions environnantes. L’unité suivante de dispatch, composée du ROB se charge par la suite d’envoyer les macro-ops aux unités de traitement entières ou flottantes, à raison de 6 macro-ops par cycle. Par ailleurs, ce ReOrder Buffer (ROB), chargé de stocker toutes les micro-instructions en cours d’ordonnancement, n’est pas en reste et passe de 224 à 256 entrées.
![fetch/decode [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/fetch_decode_t.jpg "Ultra bouzotron HD max def")
Au niveau du prédicateur de branchements, la hiérarchie des caches est revue : le L2 perd 512 entrées au profit du L1, doublant ainsi sa taille pour atteindre 1024 entrées, contre 6500 sur le second niveau. Attention, il est bien question ici de cache BTB (Branch Target Buffer), c’est-à-dire de mémoire chargée de retenir les chemins pris lors de sauts conditionnels : rien à voir avec le cache L1/L2 usuel, retenant des données situées en RAM. Tout comme Zen 2, cette prédiction de branchements suit une version modifiée de l’algorithme TAgged GEometric (TAGE) — une implémentation développée au niveau recherche vers 2006 en France, pour l’anecdote. AMD communique également sur une latence diminuée en cas de mauvaise prédiction, ainsi que l’absence de « bulle » caractéristique d’un miss L1 ou d’une prédiction erronée sur la plupart des cas courants. Il s’agirait en fait d’amélioration diminuant la latence lors d’accès conditionnels dépendants, permettant ainsi de commencer à prédire au sein même d’une prédiction. Enfin, l’Indirect Target Array (ITA) grandit encore, passant à 1,5 kilo-entrées. Ce buffer servant quant à lui lorsque les adresses de saut nécessitent de déréférencer un pointeur, typiquement lorsque cette dernière se situe sur la stack... mais également dans les cas d’application de Spectre V2 sur les processeurs non patchés.
Par opposition au front-end, le back-end comprend toute la tambouille interne que le processeur effectue pour extirper autant de parallélisme que possible, c’est-à-dire l’ordonnanceur ou scheduler, chargé de sélectionner les micro-instructions exécutables reçues du front-end, et les envoyer sur un port d’exécution libre. Contrairement à son concurrent bleu, AMD sépare les chemins de données suivant leur type : flottant (nombre à virgule) ou entiers.
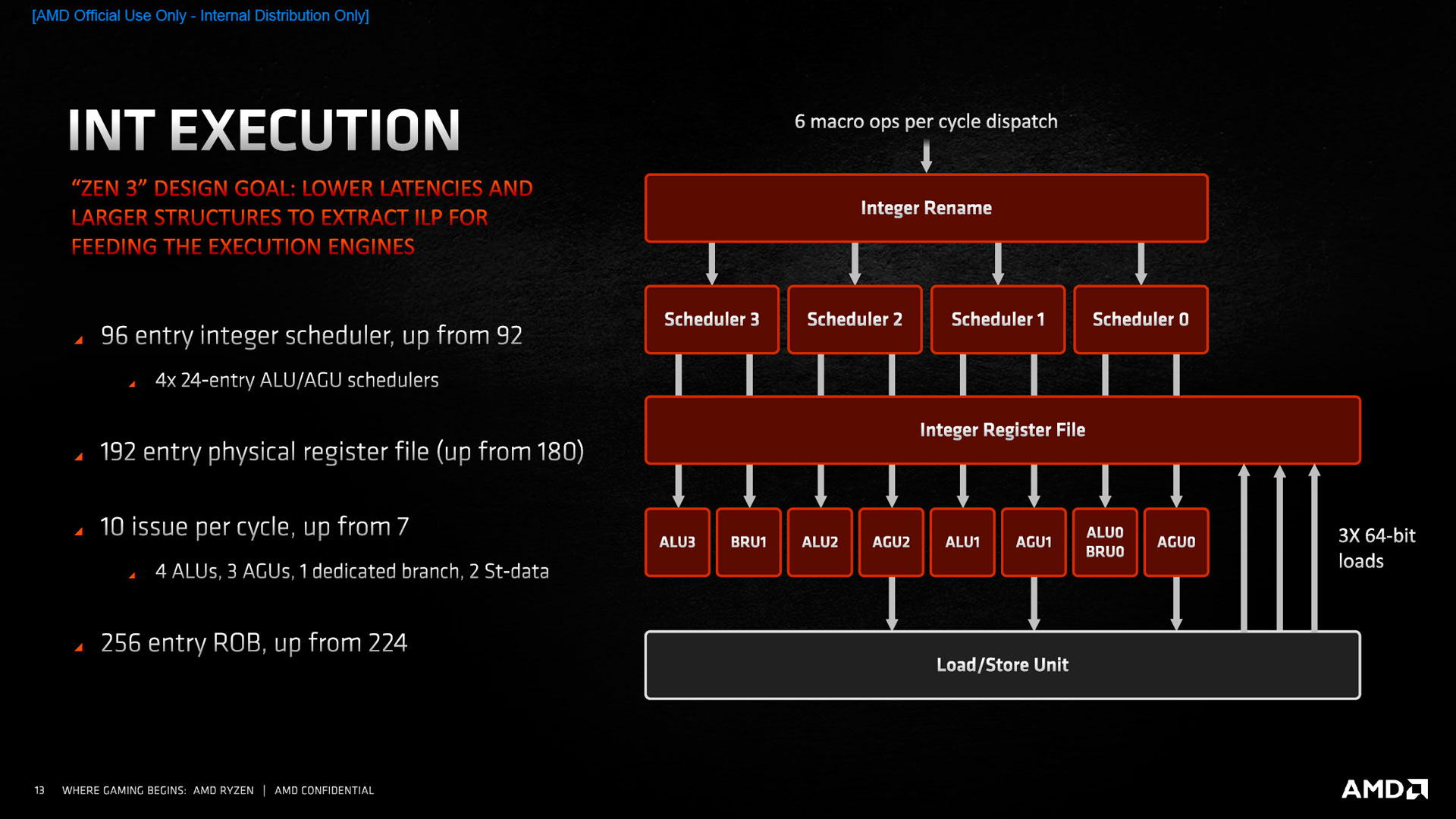
![INT Execution [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/intexec_t.jpg "3N C11QU4N7 C357 P1U5 6r4ND")
Côté entier, le scheduler progresse lentement en passant de 92 à 96 entrées, qui se décomposent en 4 composants séparés, chargés de vérifier si les données utilisées par l’instruction à exécuter, ont bien été préalablement calculées. Ces sous-schedulers communiquent chacun avec une unité arithmétique et logique (ALU), capable d’effectuer des calculs et une unité de génération d’adresse (AGU) ou une unité dédiée aux branchements, pour un total de 8 unités logiques. La cohérence entre ces bousins incombe à une mémoire nommée Register File, qui gonfle également pour afficher 192 entrées. Par rapport à Zen 2, AMD a rajouté une unité dédiée au branchement et a augmenté le nombre total d’opérations possibles simultanément, qui passe à 10 micro-ops (4 sur les ALU, 3 sur les AGU, un sur l’unité dédiée au branchement et deux chargements mémoire combinés aux calculs de pointeurs), alors que, précédemment, chaque unité était pourvue de son scheduler, ce qui limitait le nombre d’opérations parallèles possible à 7 (4 ALU et 3 sur les AGU ou sur les opérations mémoires). Notez par contre que le système de retirement, c’est-à-dire de prise en compte de la terminaison des micro-instructions, n’évolue pas, et ne permet d’exécuter que 8 micro-ops maximum : autant dire que ce 10 est purement marketing. En outre, l’interfaçage avec la mémoire, vu à la section précédente, permet de charger 3 valeurs 64-bit simultanément, et d’en stocker 2, soit respectivement 1 de plus (chacun) par rapport à Zen 2.
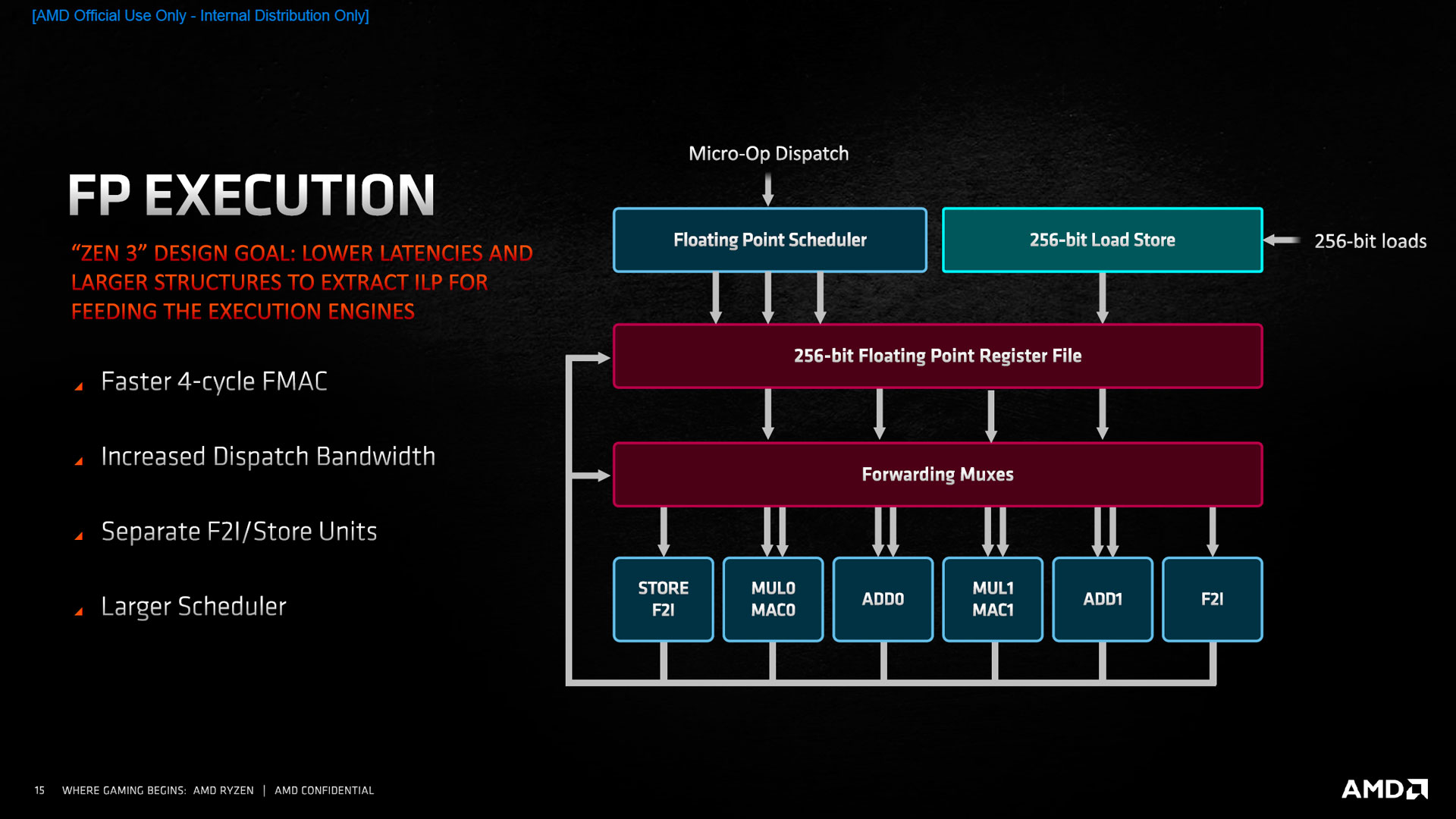
![FP Execution [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/fpexe_t.jpg "Même pas cap' de cliquer")
Pour ce qui est des opérations flottantes, AMD conserve son organisation des unités en tant que coprocesseur, cloisonné des opérations entières. Ici, c’est sur la latence que s’effectuent les améliorations, avec une multiplication-accumulation qui passe à 4 cycles, ainsi que quelques autres instructions non dévoilées. Les chargements s’effectuent toujours par blocs de 256 bits, AVX2 oblige. Toutefois, les unités d’exécutions sont plus nombreuses avec le rajout de deux éléments traitant les conversions depuis les entiers, l’un d’entre eux récupérant en plus l’unité de stockage, auparavant fusionnée avec une unité de calcul. Pour ce qui est des chargements, tout passe par contre par l’unité entière, ce qui induit une latence supplémentaire lorsque la donnée doit être utilisée dans la foulée.
![ISA architecture Zen 3 [cliquer pour agrandir]](/images/stories/articles/cpu/Zen3/R9_5000/archi/isa_t.jpg "La magie de la loupe, sans loupe")
L’ISA évolue également avec le support des extensions MPK permettant de protéger les accès RAM via une clef à 4 bits associée à chaque page virtuelle, partageant ainsi l’adressage de chaque processus en 16 domaines distincts. Rajoutez en sus la compatibilité avec certains morceaux manquant de l’AVX : VAES, pour le chiffrement, et VPCLMULQD pour une multiplication matricielle offrant des options de configuration avancées, mais pas d’AVX-512, la complexité d’intégration ne valant pas la chandelle des quelques applications professionnelles en tirant partie. Enfin, on notera l’intégration des instructions CET (Control-flow Enhancement Technology), une extension du jeu d’instruction x86 permettant de sécuriser davantage les programmes contre le piratage via l’utilisation de piles fantômes et de mécanismes de contrôle des sauts.
En quelques mots, que retenir des évolutions de Zen 3 ? Architecturalement parlant, cette nouvelle itération mérite tout à fait son nom d’évolution majeure, en améliorant l’intégralité du pipeline d’exécution, qu’il s’agisse du front-end comme du back-end, avec une emphase mise sur les performances de traitement des entiers au détriment de nouvelles extensions vectorielles. Autant dire que les progrès ont principalement été centrés sur réactivité dans les utilisations courantes, tout particulièrement concernant les prestations en jeu. La puissance de traitement brute pour les utilisations applicatives devrait ainsi demeurer proche de Zen 2, en bénéficiant toutefois des gains dûs au cache unifié. Qu’en est-il en pratique ? La réponse dans la suite de ce dossier.
|
|
| Un poil avant ?Du SSD RGB, encore ? Eh oui, avec le T-FORCE TREASURE Touch ! | Un peu plus tard ...Windows Insider 20251 : toujours plus de rustines pour Windows 10 | |