SiFive P650 : enfin le début de la montée en gamme du RISC-V ? |
————— 06 Décembre 2021 à 19h16 —— 16542 vues



SiFive P650 : enfin le début de la montée en gamme du RISC-V ? |
————— 06 Décembre 2021 à 19h16 —— 16542 vues
Alors que de nouvelles cartes graphiques chez NVIDIA approchent à grands pas, le caméléon n’est pas le seul à sortir de nouveaux produits. En effet, SiFive, une start-up mature (si tant est que cela puisse exister) proche d’Intel, vient de lancer un nouveau P650 à l’occasion du RISC-V Summit, (en ce moment à Las Vegas) un processeur dans la lignée des créations de la firme : utilisation du jeu d’instruction libre RISC-V, mais architecture maison de plus en plus haute-performance.
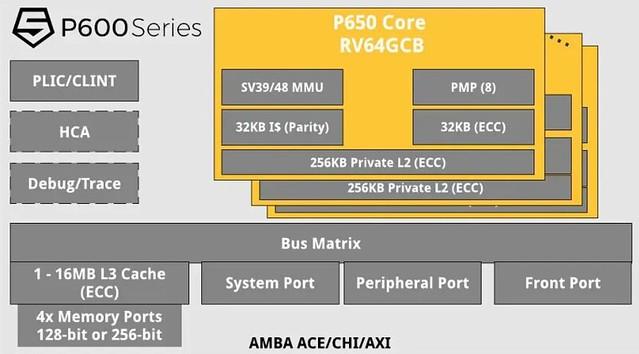
Une présentation qui n’est pas sans rappeler les CPU Arm
Ce dernier membre de la famille est costaud : tournant en interne en 64-bit, il surpasserait de 50 % en matière de performance le P550, pourtant dévoilé en juin dernier. Pour cela, la fréquence maximale de 3,5 GHz est bien utile, atteinte grâce à une gravure en 7 nm (TSMC ?) ; tout comme les 32 Kio de L1-D, de L1-I et les 256 Kio de L2, tous privés. Un L3 partagé est également possible, pour une taille allant de 1 à 16 mégots. Au niveau du back-end, le pipeline supporte 4 instructions maximum en parallèle, répartie sur trois chemins d’exécutions possibles : mémoire, calcul entier et calcul flottant, dont l’agencement interne n’est pas encore communiqué.
Au niveau des puces intégrant ce nouveau design, il est question de SoC munis de 16 cœurs maximum. En outre, SiFive s’affiche comme dépassant un Cortex-A77 de chez Arm sur le plan du ratio performance/surface (sur des applications spécifiques, ne vous emballez pas) ; l’idée étant clairement de venir dans le futur s’attaquer au marché des serveurs avec des solutions de plus en plus proches du massivement multicœur. Pour quel succès en pratique ? L’avenir nous le dira, car, si le prix, encore inconnu, est un facteur de taille dans le choix d’une nouvelle infrastructure, la compatibilité logicielle l’est tout autant : un point sur lequel Arm, pourtant de taille respectable, n’est pas toujours au niveau. De quoi lever bien des défis pour le jeune RISC-V ! (Source : MiniMachines)
| Un poil avant ?Bon plan • Ryzen 7 5800X à 344,99 € | Un peu plus tard ...Bon plan • Tè vé ! la mémoire là ! (32 Go dès 116,99 €) | |





















