L’architecture Blackwell des GeForce RTX 50 mise en lumière |
————— 17 Janvier 2025 à 07h30 —— 43930 vues



L’architecture Blackwell des GeForce RTX 50 mise en lumière |
————— 17 Janvier 2025 à 07h30 —— 43930 vues
Présentées à l’occasion du CES 2025, les premières GeForce RTX 50 Series Blackwell seront disponibles à partir du 30 janvier prochain. NVIDIA a exposé les rouages de son architecture ; nous allons essayer de vous résumer les principaux aspects ici.
Pour commencer, Blackwell implique la 5e génération de cœurs Tensor, la quatrième génération de cœurs RT. En outre, NVIDIA mentionne la présence d’un processeur de gestion de l'IA. Plus aucune trace de l'accélérateur de flux optique (l’Optical Flow Accelerator) de la génération Ada par contre. Par ailleurs, les GPU adoptent la mémoire GDDR7.

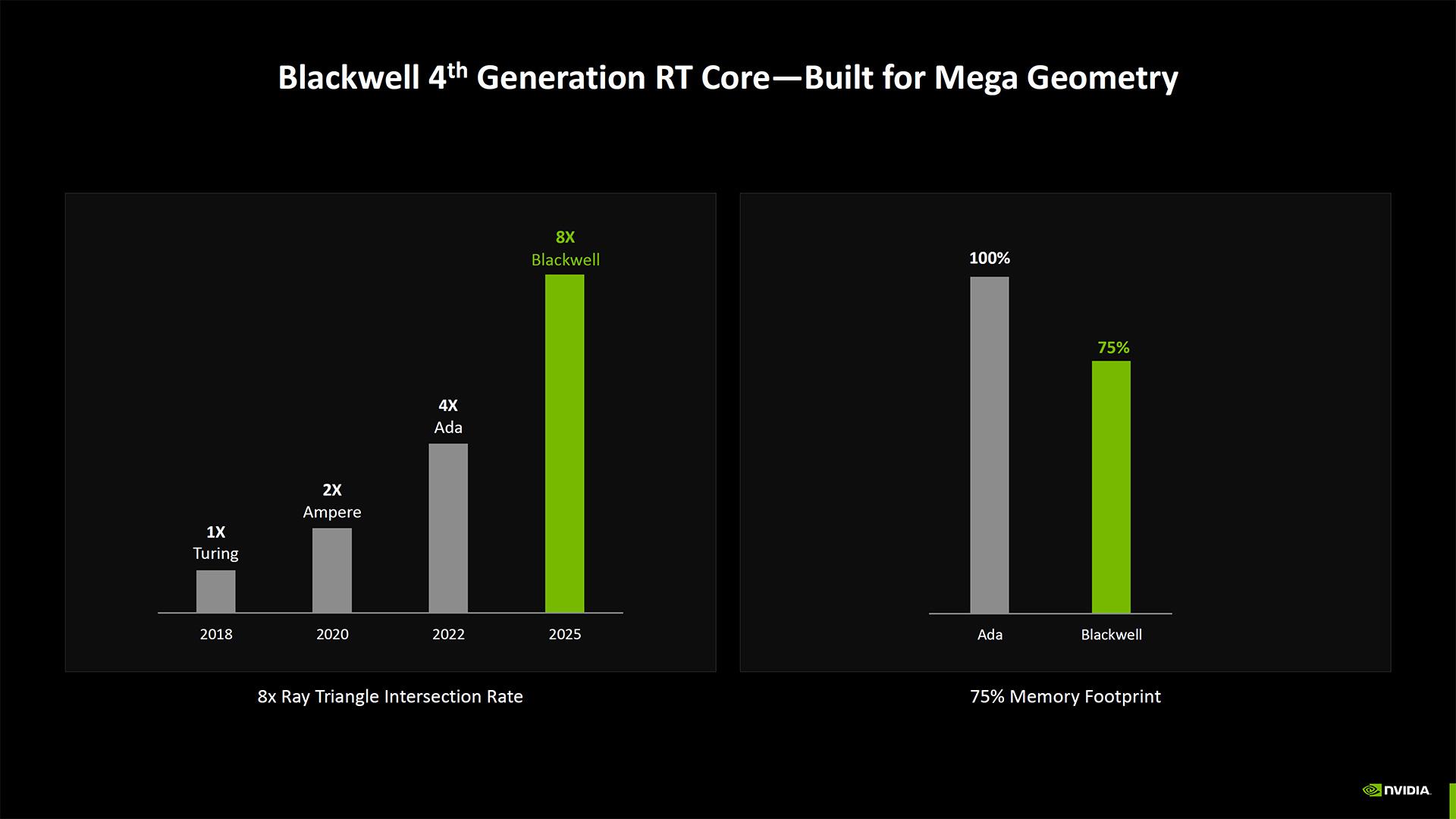
Parmi les avancées générationnelles, les cœurs RT de 4e génération sont optimisés pour la RTX Mega Geometry, un système censé accélérer la construction BVH (Bounding Volume Hierarchy) en permettant bien plus de polygones qu’actuellement. Grosso modo, le RTX Mega Geometry met à jour les polygones par lots sur le GPU. Cela doit réduire la charge de travail CPU mais aussi la quantité de VRAM nécessaire. Alan Wake 2 sera le premier titre à bénéficier de cette prise en charge.
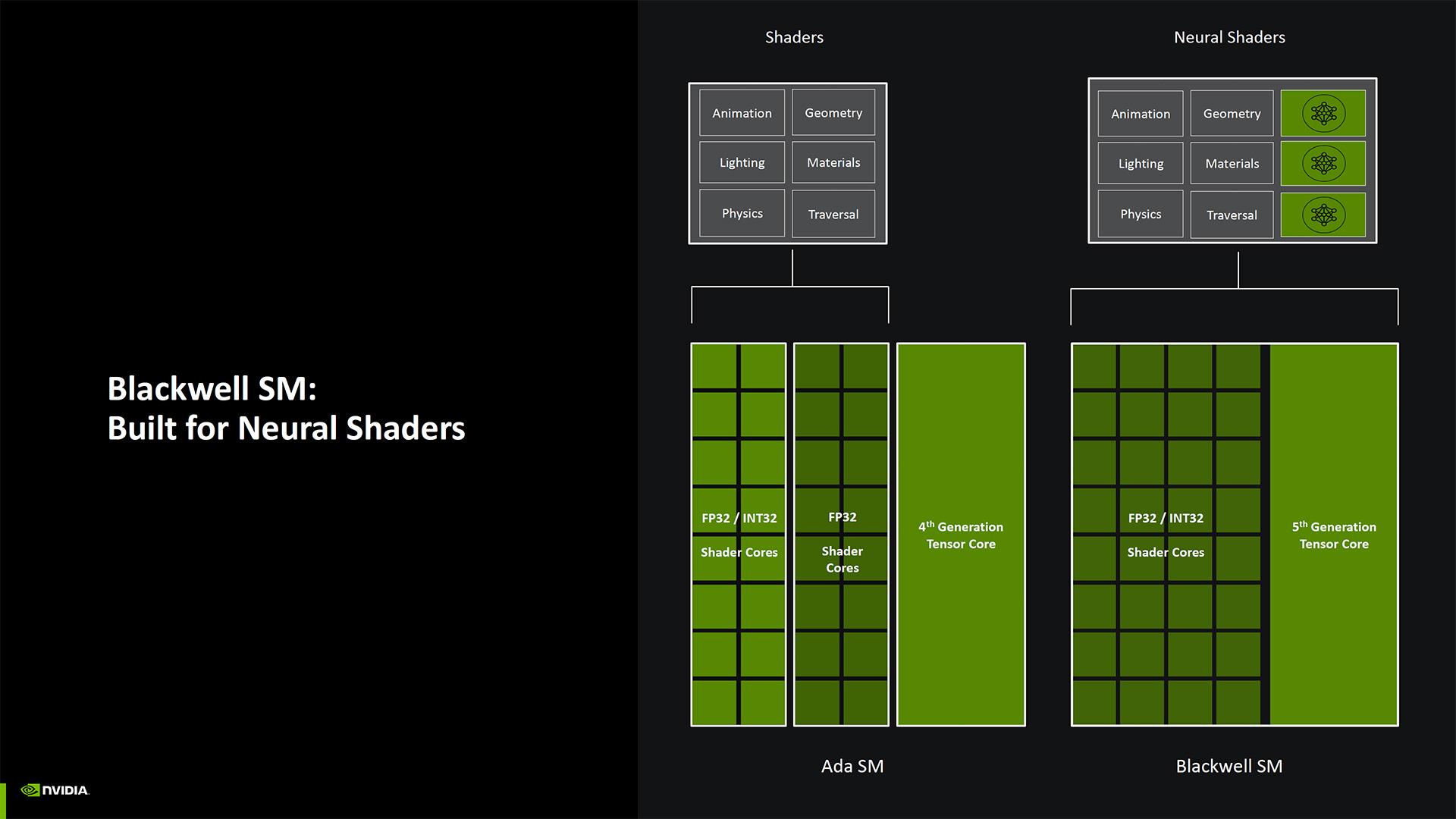
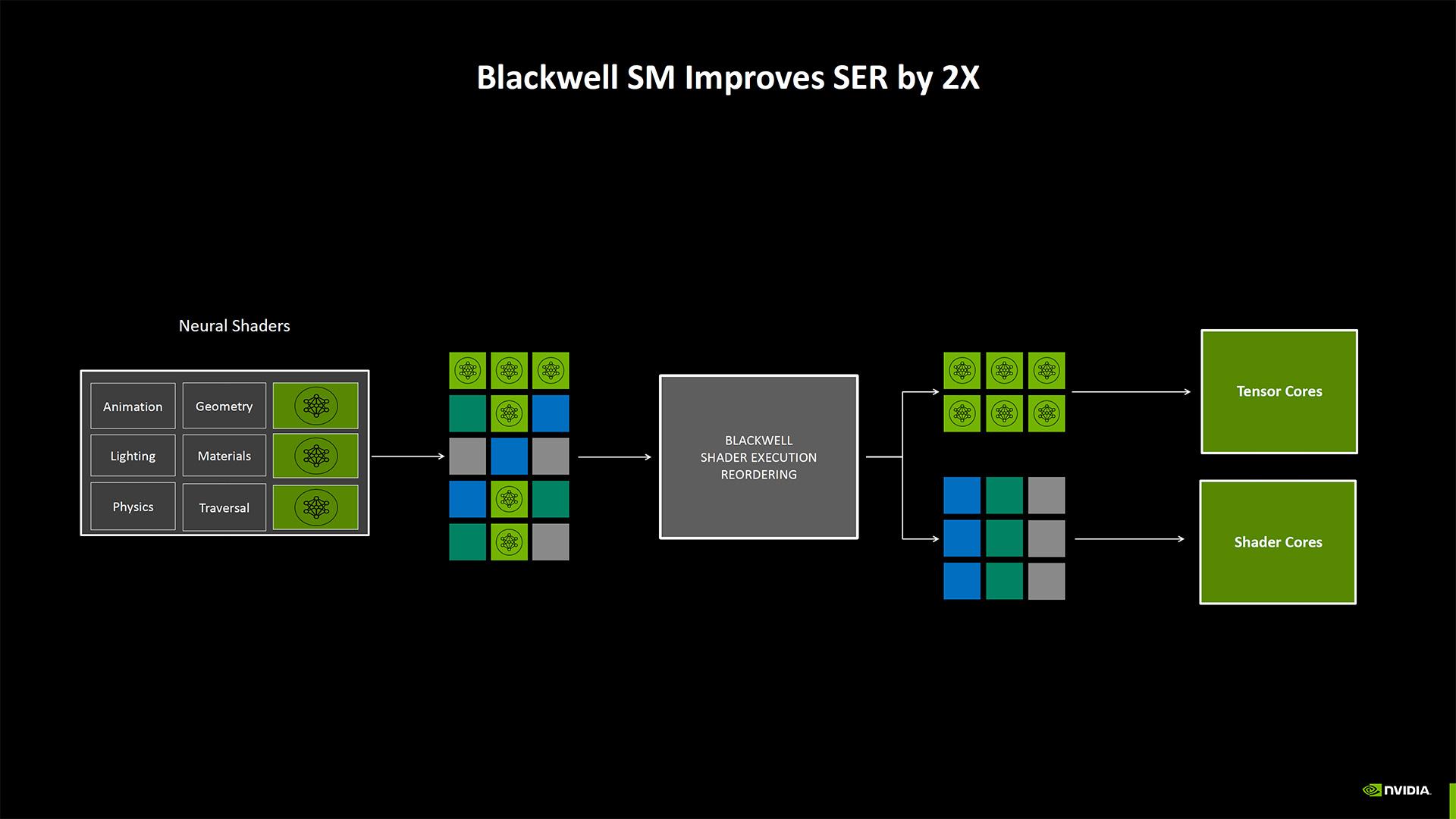
Toujours sur un plan architectural, il y a d'autres changements notables. Par exemple, NVIDIA a rendu les cœurs de shaders de Blackwell entièrement compatibles FP32 / INT32 ; la société les qualifie dorénavant de Neural Shaders. Avec Ampere puis Ada, NVIDIA avait doublé nombre de cœurs CUDA FP32 par SM, mais la moitié d'entre eux étaient uniquement destinés au FP32, tandis que l'autre moitié pouvait faire du FP32 ou de l'INT32 ; Blackwell uniformise tous les cœur, tout en conservant la quantité doublée par SM par rapport à Turing. Ajoutez à cela une prise en charge native du FP4 pour les Tensor, ainsi que des améliorations apportées au SER (Shader Execution Reordering) — présenté comme deux fois plus rapide sur Blackwell que sur Ada. NVIDIA a formé et mis à jour ses modèles d'intelligence artificielle pour exploiter ces cœurs améliorés. Nous y reviendrons un peu plus loin dans l’article.
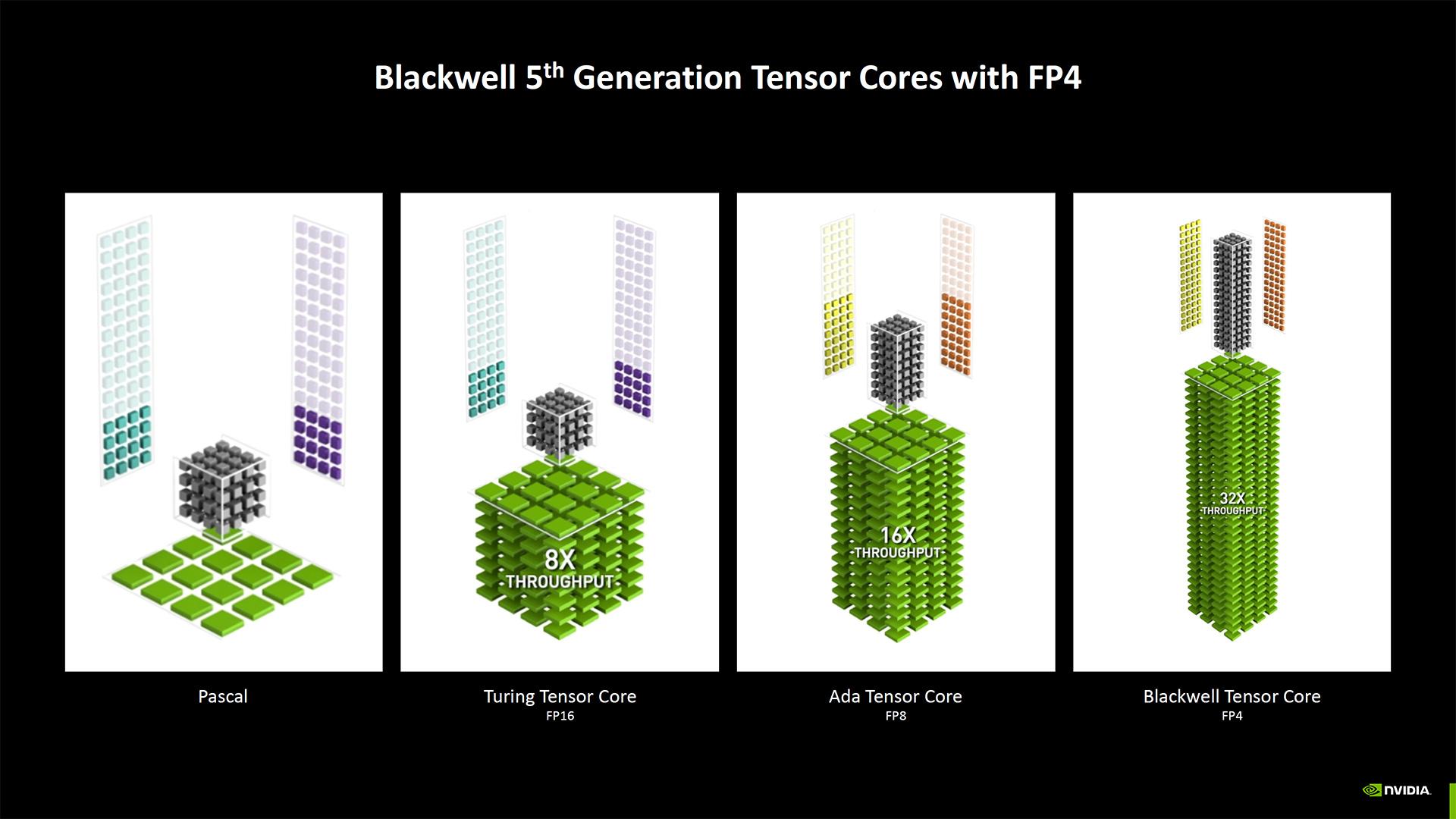
Ces changements permettent à NVIDIA de gonfler un peu artificiellement les chiffres. Par exemple, les 3352 AI TOPS revendiqués pour les cœurs Tensor sont en grande partie le fruit du support natif du FP4. Pour comparer avec la GeForce RTX 4090, qualifiée comme susceptible de fournir 1321 trillions d'opérations par seconde en FP8, il faut garder ce même format pour la RTX 5090, soit 1 676 TFLOPS. Vous avez ainsi une hausse de 27 % « seulement ». Même chose pour le FP32, avec respectivement 104,8 TFLOPS vs 82,6 TFLOPS pour la RTX 4090, soit le même écart. Entre la RTX 3090 et la RTX 4090, la différence était de 132 %.
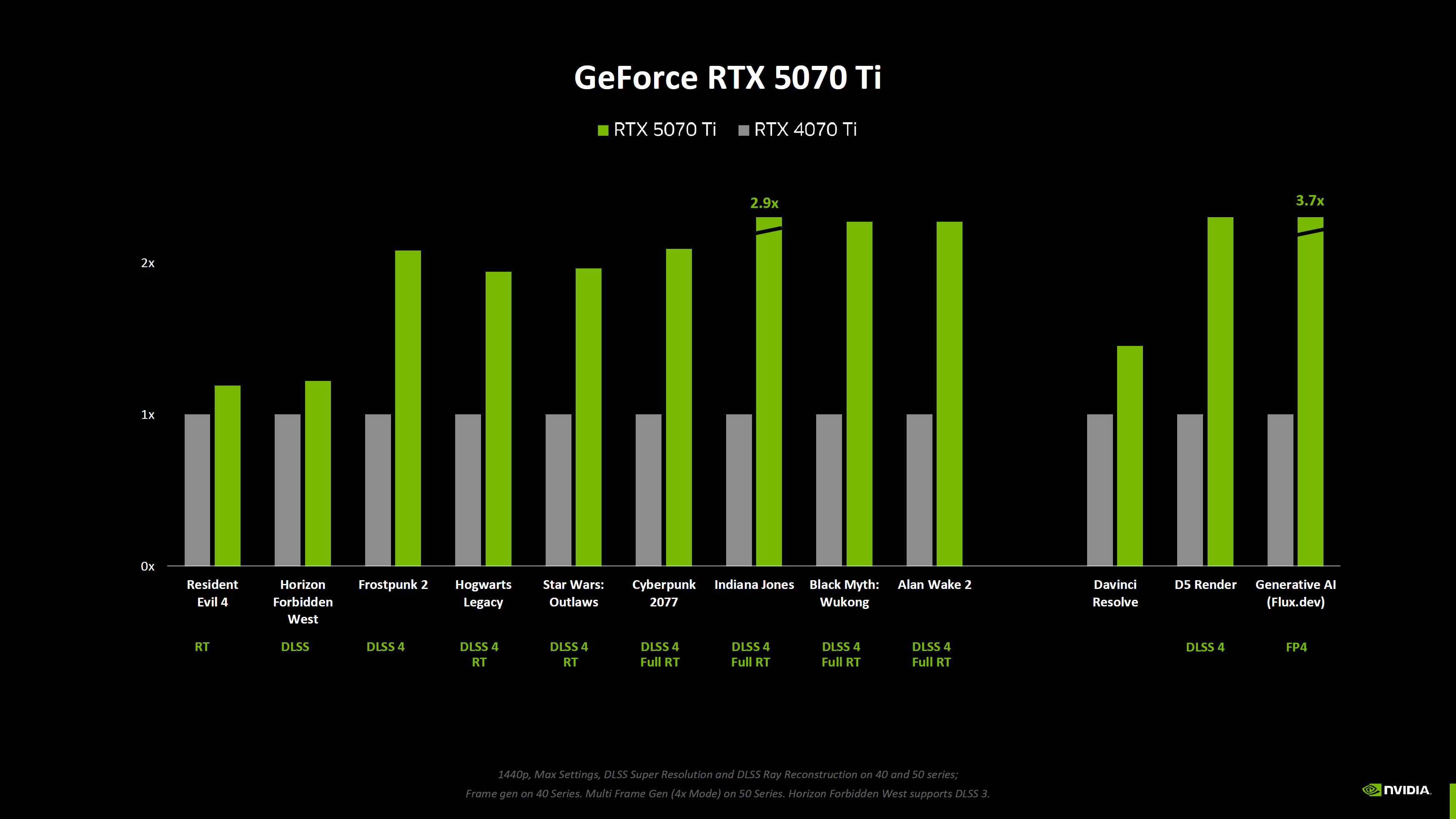
Ce flagship bénéficie toutefois d’une nette hausse du nombre du nombre de cœurs. Cette abondance permet à la RTX 5090 de creuser un bon écart avec la RTX 4090 dans les jeux, y compris lorsque les mesures de ne sont pas gonflées par la MFG du DLSS4.
| GPU | SKU | SM max | Surface die | Transistors | Densité |
|---|---|---|---|---|---|
| GB202 | RTX 5090(D) | 192 | 750 mm² | 92,2 milliards | 122,9 MTr/ mm² |
| GB203 | RTX 5080 / 5070Ti | 84 | 378 mm² | 45,6 milliards | 120,6 MTr/ mm² |
| GB205 | RTX 5070 | 50 | 263 mm² | 31 milliards | 117,9 MTr/ mm² |
| GB206 | RTX 5060 Ti ? | 36 | À déterminer | À déterminer | À déterminer |
| GB207 | RTX 5060 ? | 20 | À déterminer | À déterminer | À déterminer |
| AD102 | RTX 4090(D) | 144 | 608 mm² | 76,3 milliards | 124,9 MTr/ mm² |
| AD103 | RTX 4080(S) / 4070TiS | 80 | 379 mm² | 45,9 milliards | 121,2 MTr/ mm² |
| AD104 | RTX 4070(S) / Ti | 60 | 295 mm² | 35,8 milliards | 121,6 MTr/ mm² |
| AD106 | RTX 4060Ti | 36 | 188 mm² | 22,9 milliards | 121,8 MTr/ mm² |
| AD107 | RTX 4060 | 24 | 159 mm² | 18,9 milliards | 118,9 MTr/ mm² |
Pour le reste de la gamme par contre, sur la base de mesures partagées par NVIDIA et judicieusement exposées comme ce qui va suivre par ComputerBase, dans un rendu purement natif, le gap RTX 50 Series / RTX 40 Series n’est pas pharamineux.
| Ring | Difference de Shaders | Difference d'IPS, Resident Evil (RT) + Horizon Forbidden West (DLSS, pas de MFG) | ||||
|---|---|---|---|---|---|---|
| Référence | RTX 5000 | RTX 4000S | RTX 4000 | RTX 5000 | RTX 4000S | RTX 4000 |
| RTX XX90 | 133,00 % | – | 100,00 % | ~ 133 % | – | 100,00 % |
| RTX XX80 | 111,00 % | 105,00 % | 100,00 % | ~ 115 % | 102,00 % | 100,00 % |
| RTX XX70 Ti | 117,00 % | 110,00 % | 100,00 % | ~ 120 % | 110,00 % | 100,00 % |
| RTX XX 70 | 104,00 % | 122,00 % | 100,00 % | ~ 120 % | 116,00 % | 100,00 % |
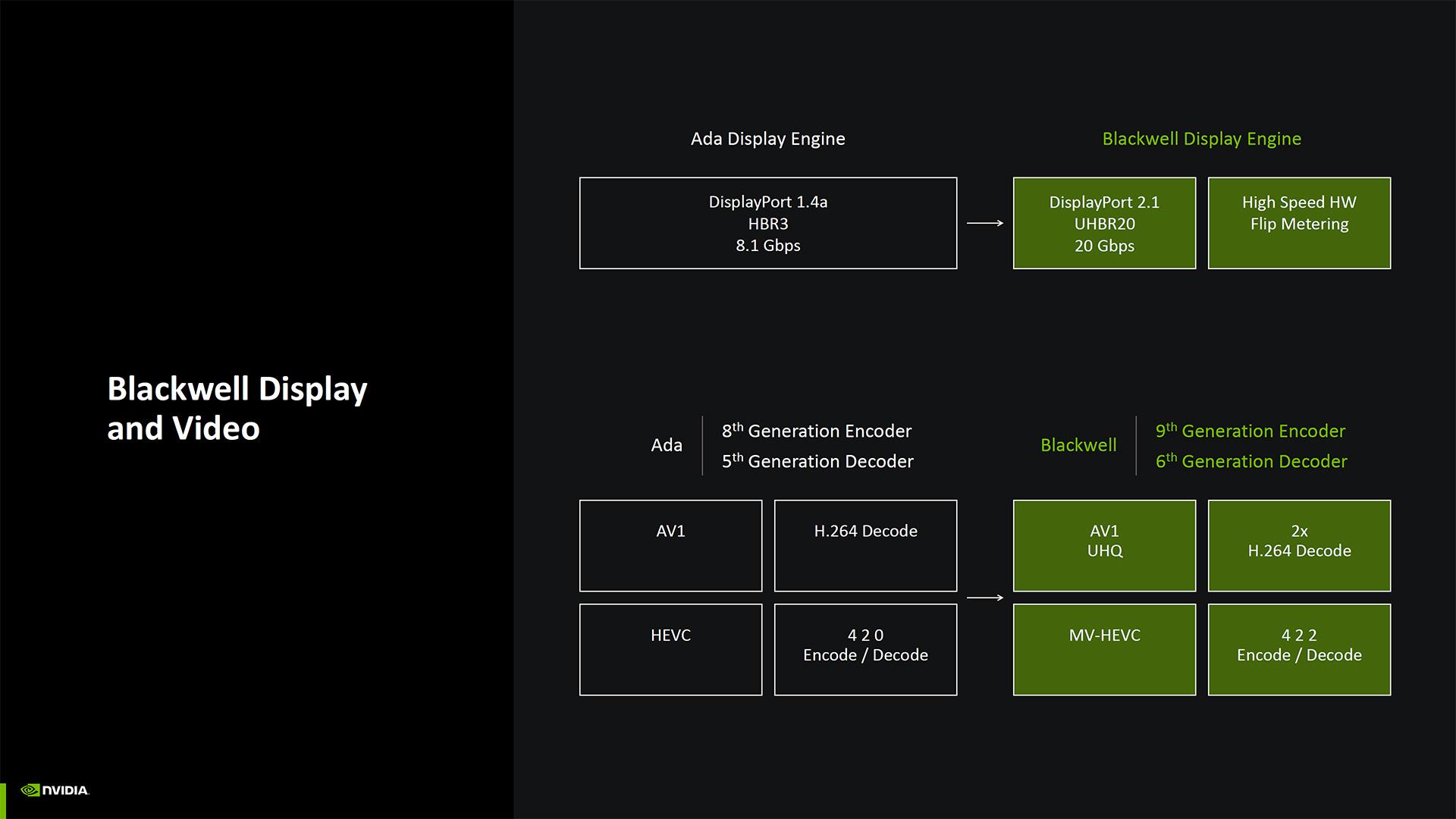
En dehors de cela, Blackwell est la première génération GPU de NVIDIA à aller au-delà du DisplayPort 1.4a ; support complet du DisplayPort 2.1 UHBR20 au programme, et moteurs d'encodage / décodage de 9e et 6e génération respectivement. Le PCIe 5.0 est également l'une des nouveautés.
L’autre grande avancée est naturellement la GDDR7. Elle est cadencée à 28 Gbit/s, sauf pour la GeForce RTX 5080, pour laquelle les puces sont à 30 Gbit/s. Logiquement, l'effet sur la bande passante mémoire se fait ressentir par rapport aux anciennes cartes équipées de puces GDDR6X.

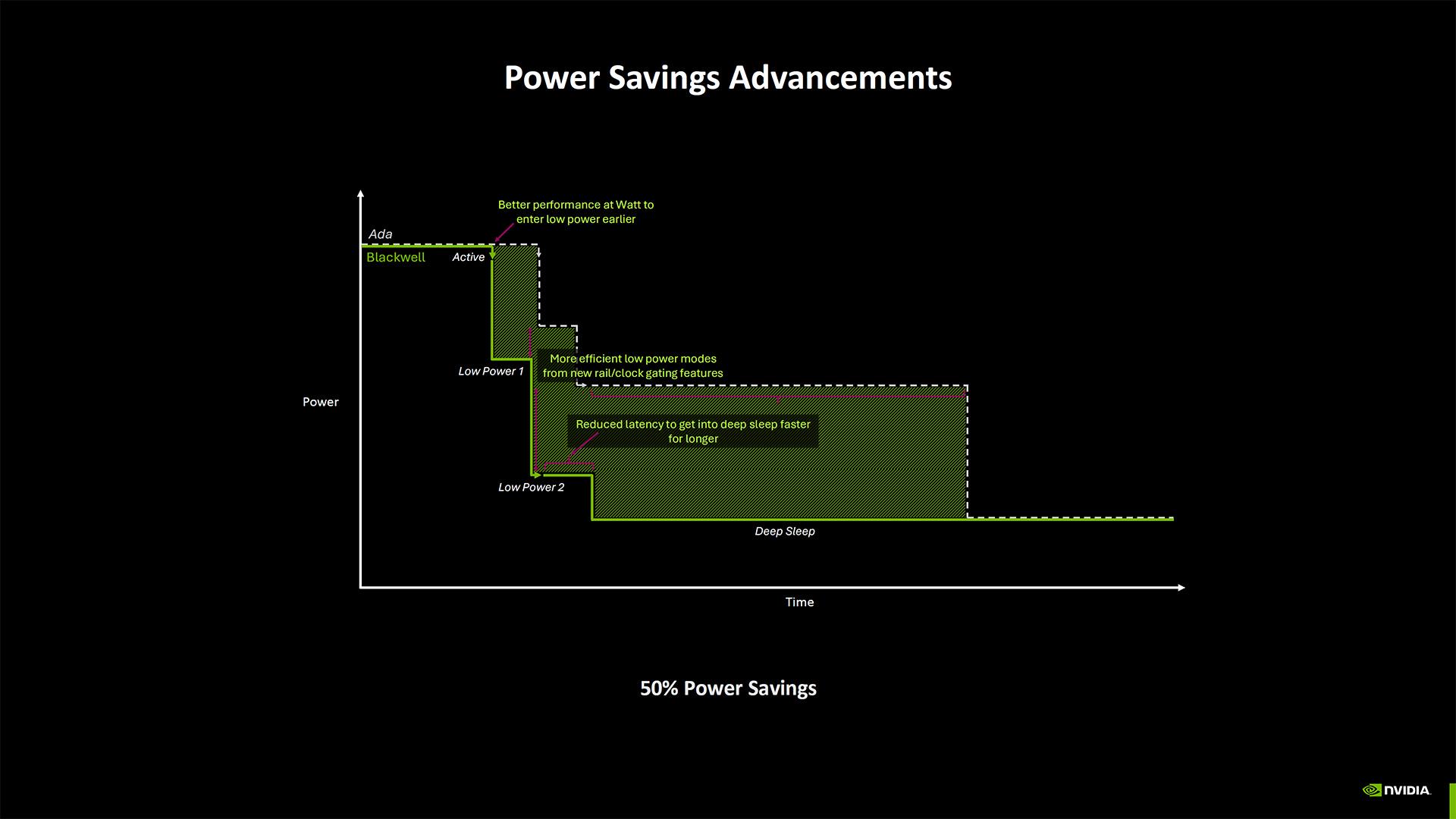
D'autre part, NVIDIA revendique aussi des gains sur le terrain de l'efficacité énergétique.
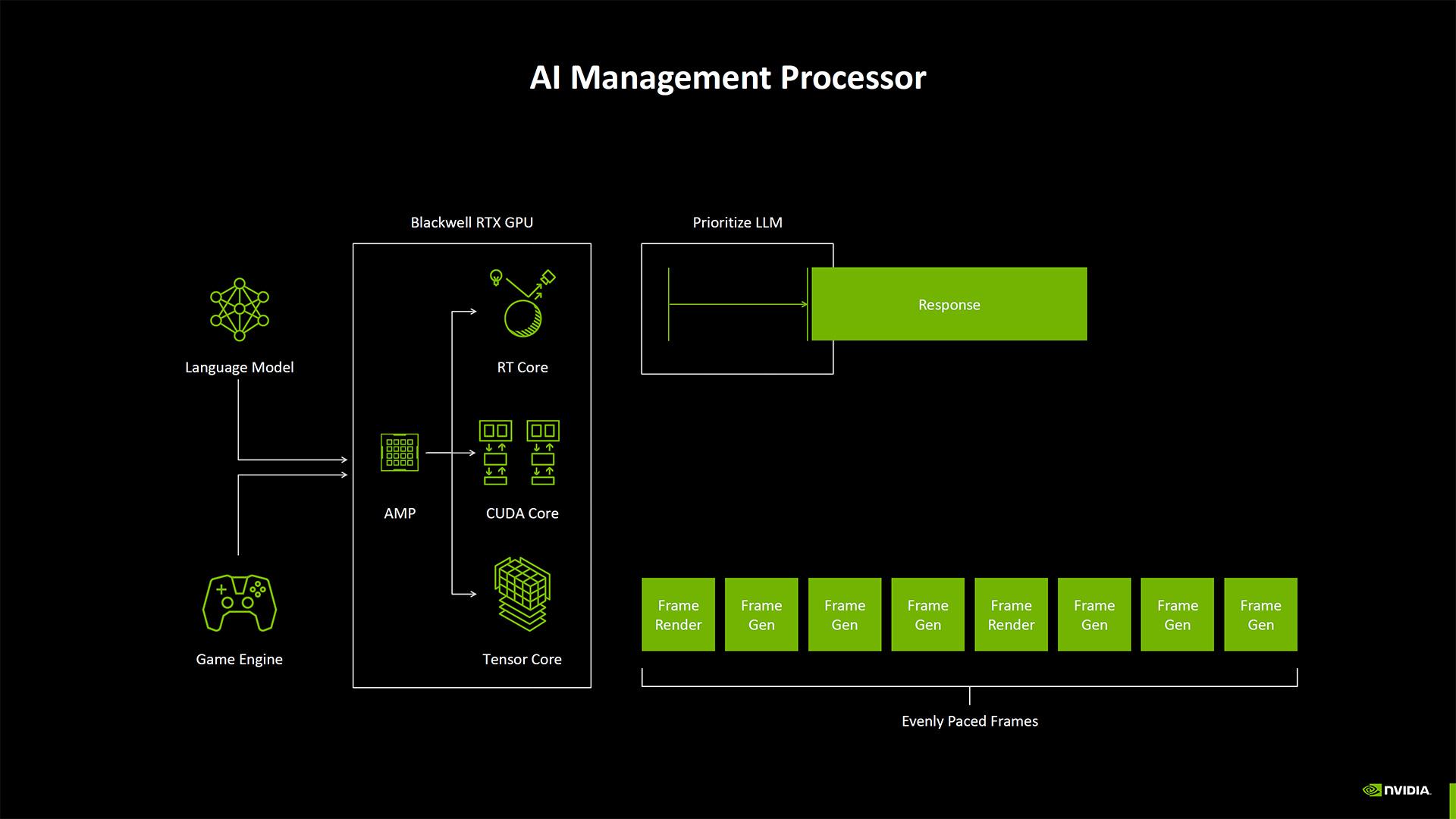
Sans surprise, Blackwell fait la part belle aux charges de travail d’IA. Cela passe notamment pas l’ajout d’un processeur de gestion de l'IA dont le rôle consiste apparemment à recevoir des indications sur le type de charges de travail en cours d'exécution afin de déterminer celles qui doivent être traitées en priorité.
Par ailleurs, les Neural Shaders bougonnent à travers cinq branches : celles des Neural Textures, Neural Materials, Neural Volumes, Neural Radiance Fields et Neural Radiance Cache.
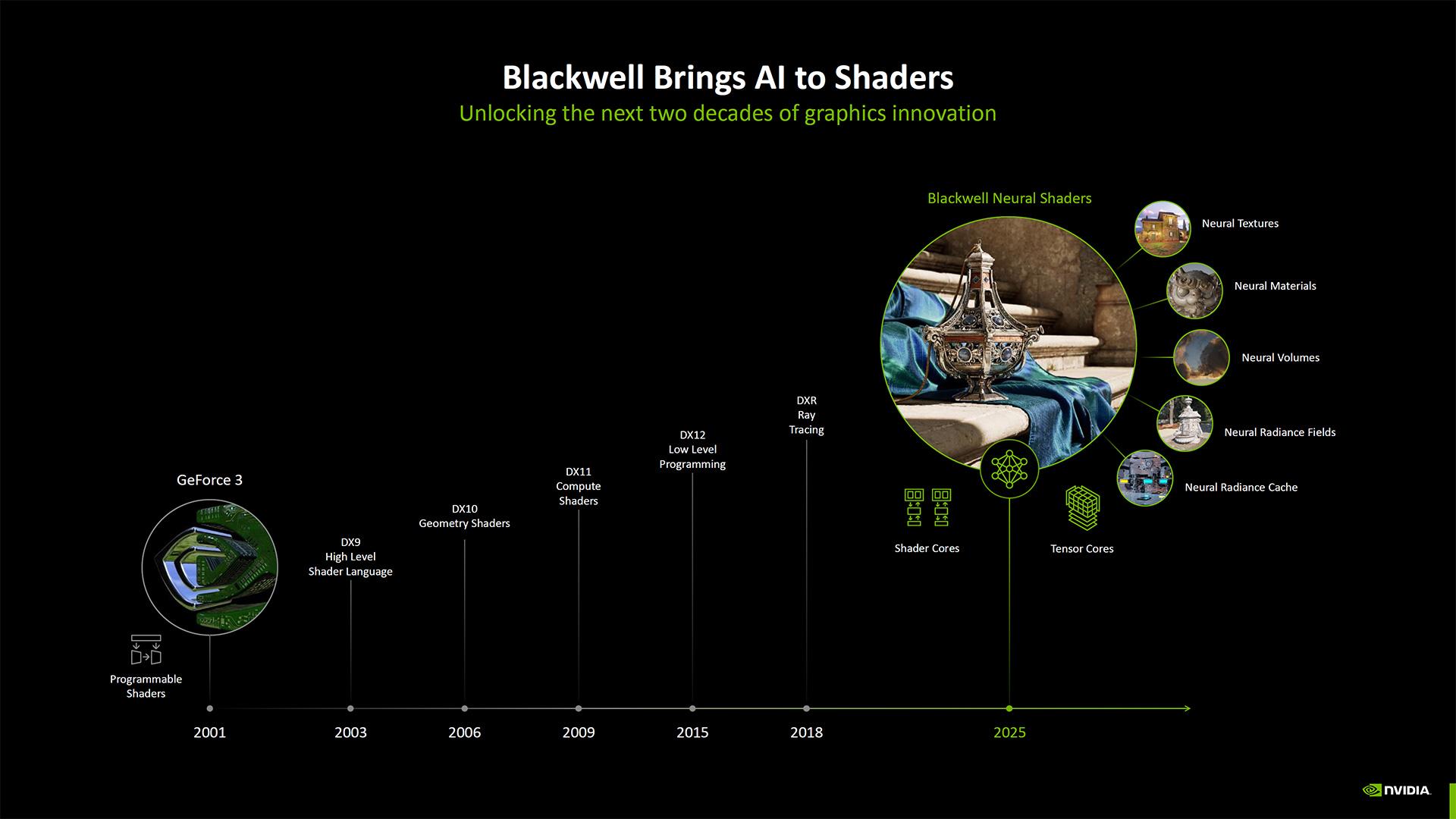
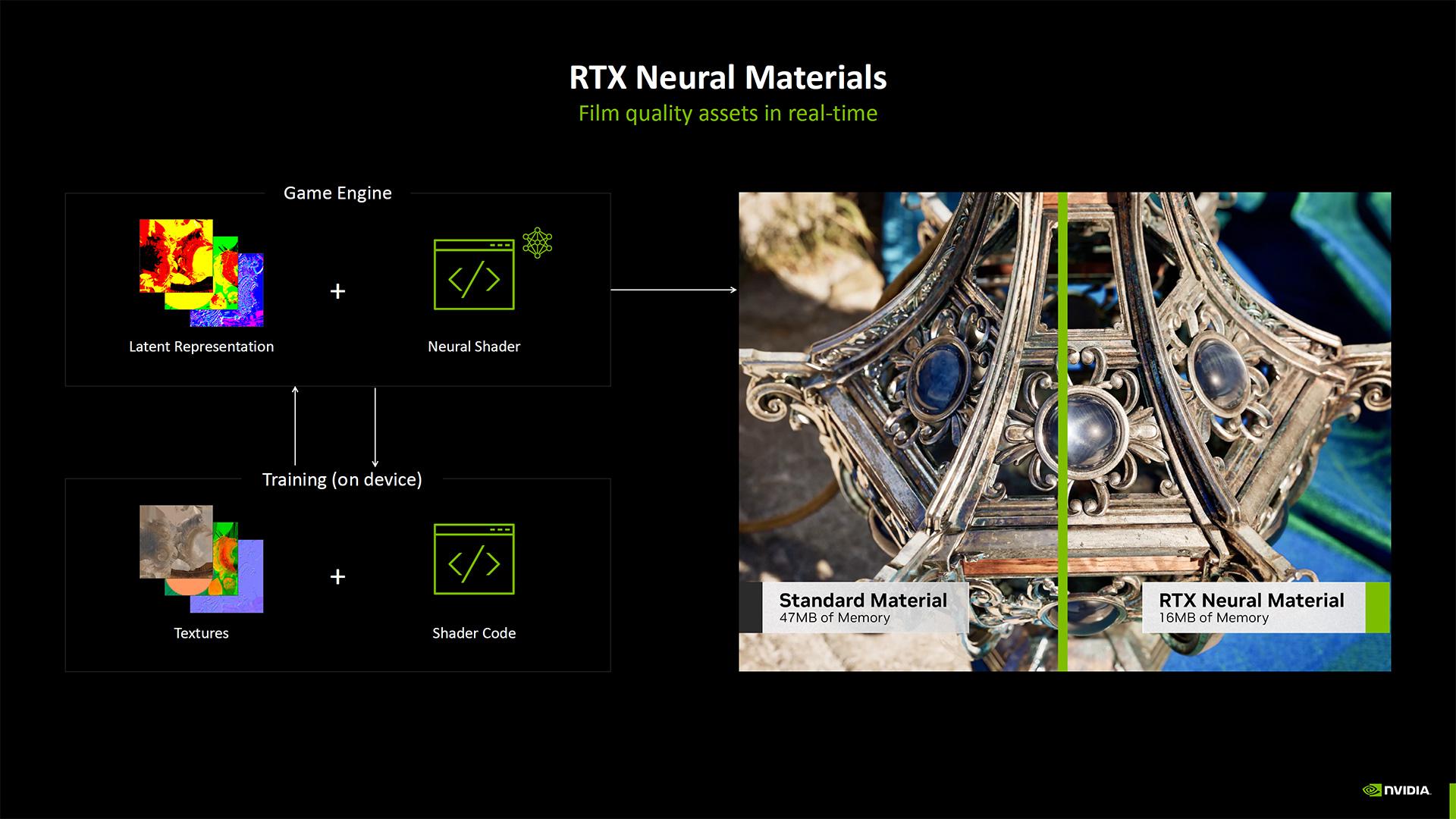
Les Neural Materials par exemple doivent contribuer à réduire l’utilisation de la VRAM pour les textures et matériaux. Sous réserve que les développeurs implémentent le support dans leurs productions. Plus globalement, Microsoft a déjà annoncé que ses équipes œuvraient à l’implémentation d’un rendu neural dans DirectX, plus particulièrement par l’entremise des « cooperative vectors ». Restera à voir la prise de tout ceci par d’autres GPU. Cela restera un standard ouvert, mais il est probable que des architectures plus anciennes ne supportent pas nativement certaines fonctionnalités matérielles nécessaires à sa mise en œuvre.
Citons aussi des dispositifs plus mineurs tels que le RTX Skin ou RTX Hair, pour lesquels les titres sont suffisamment explicites.
More details on Strand Based vs RTX Hair with Linear-Swept Spheres. https://t.co/MUpPbXKB56 pic.twitter.com/kY67vWxzTK
— Jacob Freeman (@GeForce_JacobF) January 15, 2025
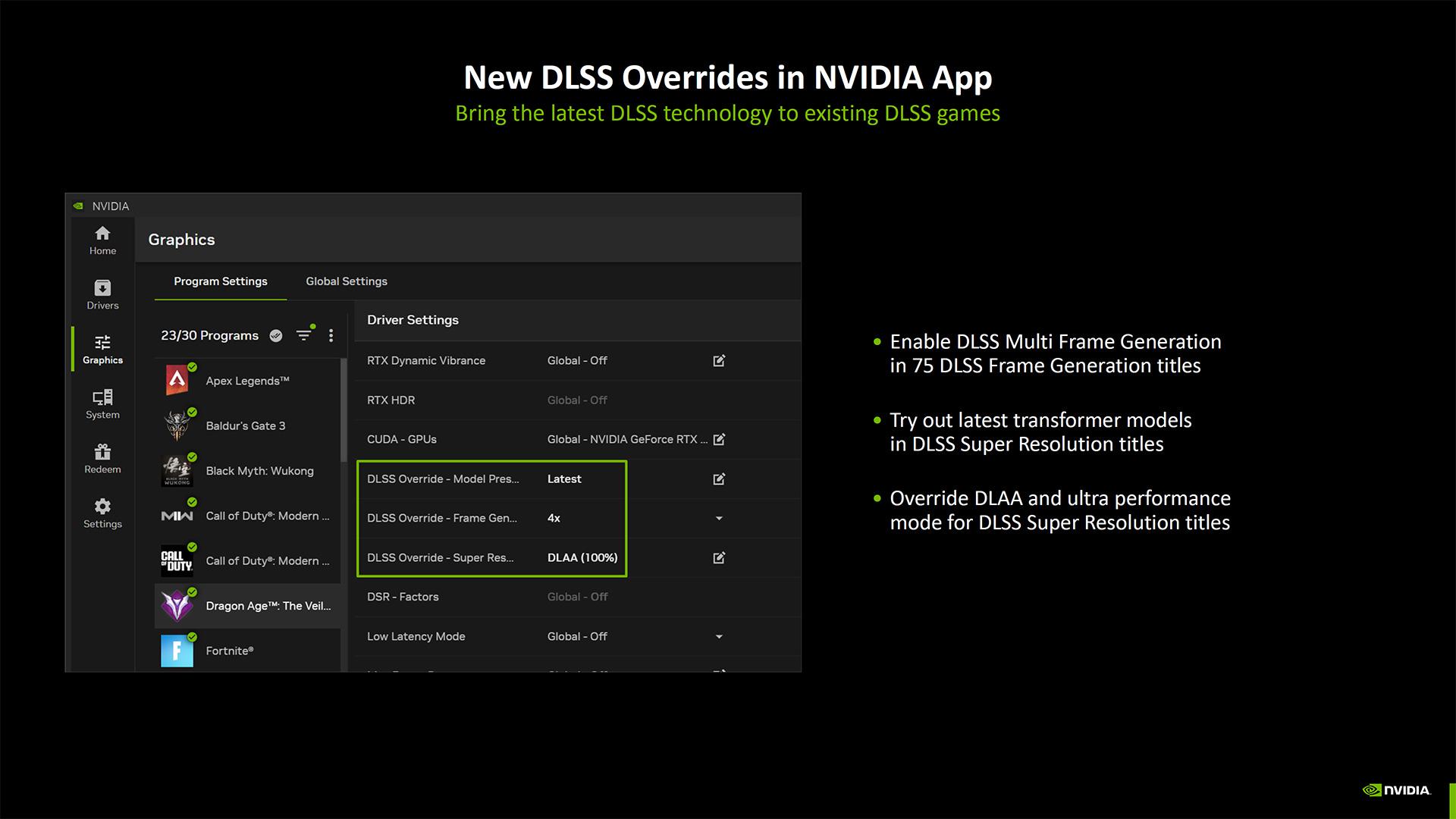
Un autre versant majeur de l’architecture Blackwell est le DLSS 4 renforcé par sa Multi-Frame Generation. Pour l’anecdote, NVIDIA allègue que plus de 80 % des détenteurs de RTX ont recours au DLSS.
Les premières versions du DLSS reposaient sur des réseaux de neurones convolutifs (CNN). Désormais, NVIDIA apporte un modèle d’apprentissage profond de type transformeur, également appelé modèle auto-attentif. Le site Picsellia nous éclaire à ce sujet en expliquant que les « CNN utilisent la convolution, une opération « locale » limitée à un petit voisinage d'une image », tandis que « les Transformers utilisent l'auto-attention, une opération "globale", puisqu'elle tire des informations de l'image entière ». La page Wikipedia de ces derniers nous apprend qu’ils reposent sur une architecture d'apprentissage profond introduite en 2017.
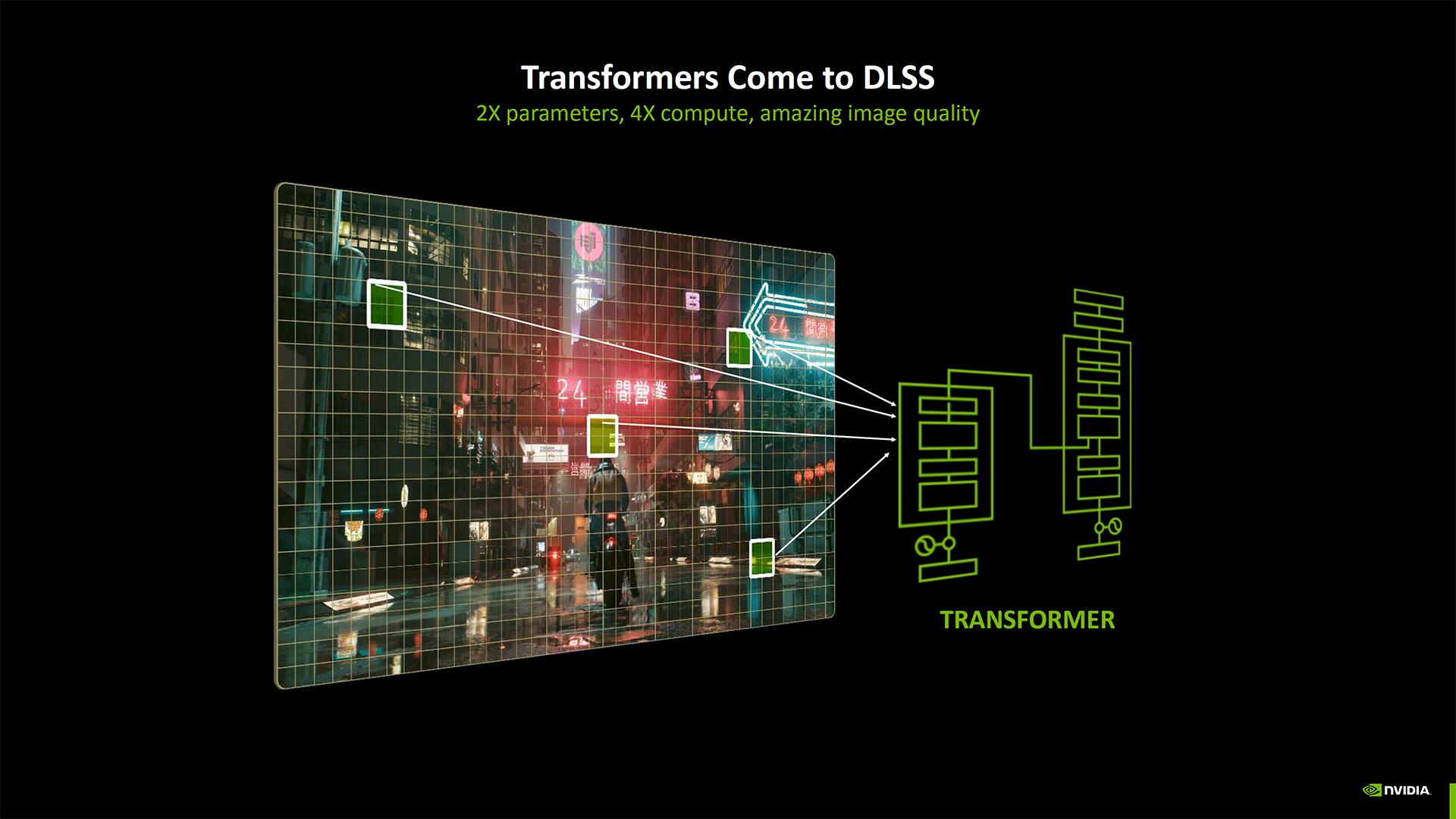
Quoi qu’il en soit, avec le nouveau modèle DLSS, NVIDIA revendique deux fois plus de paramètres et quatre fois plus de calculs, ce qui améliore considérablement la qualité de l'image. C’est valable pour la mise à l’échelle, mais aussi pour la Ray Reconstruction.


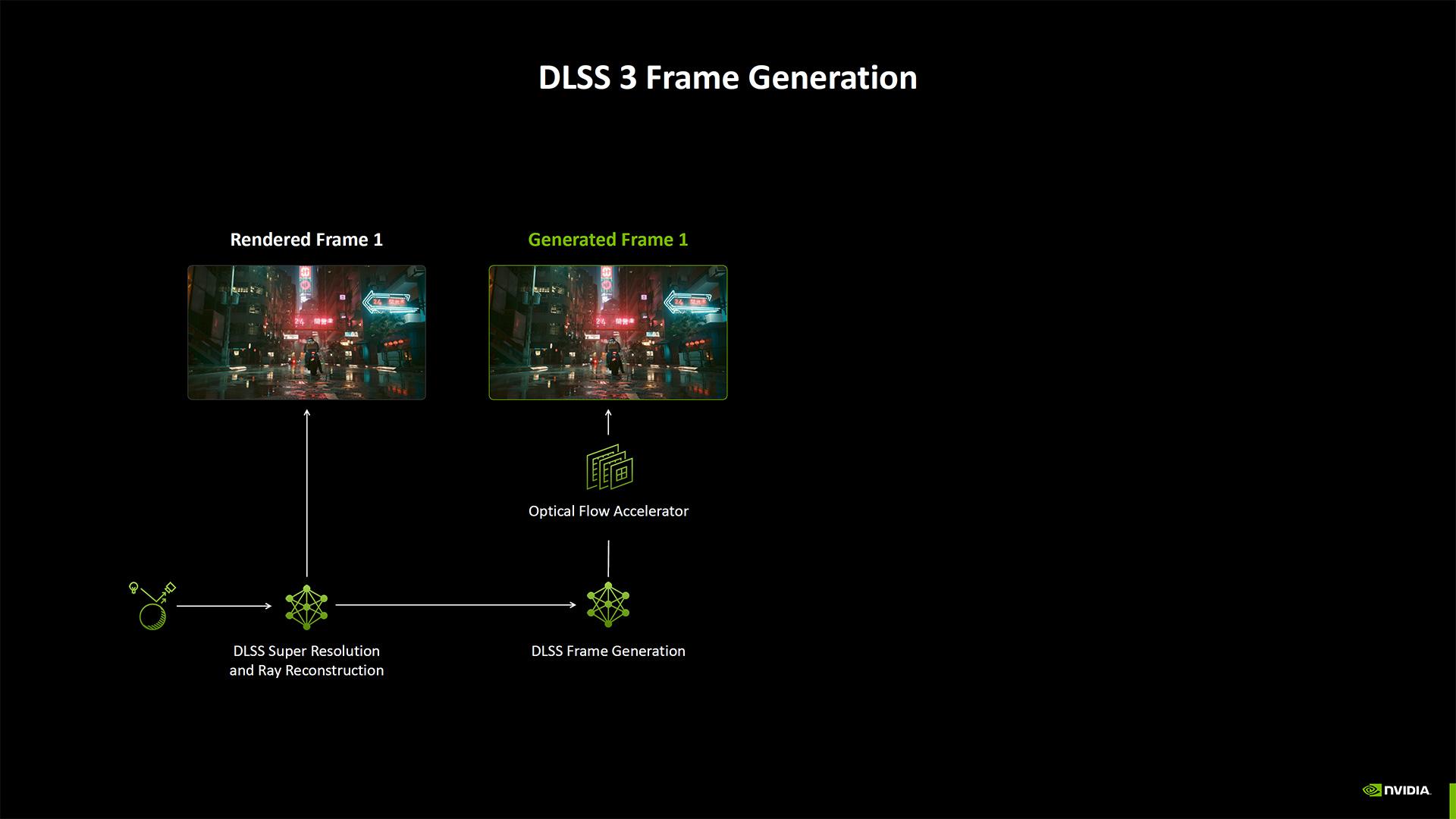
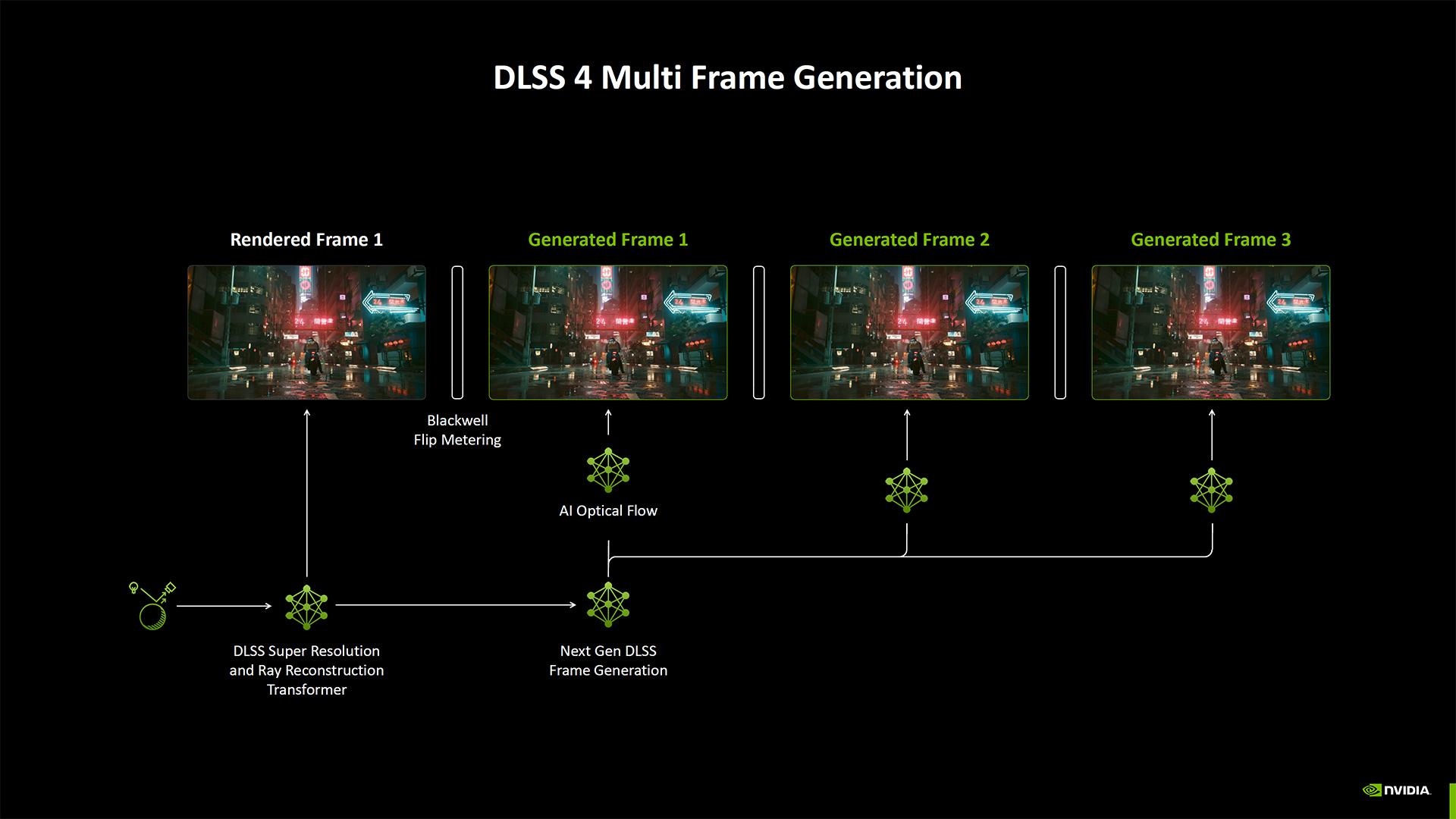
Concernant la MFG, comme nous l’avons écrit précédemment, NVIDIA n’interpole plus une image, mais carrément trois. Un bon moyen d’obtenir magiquement trois fois plus de perf dans les benchmarks !

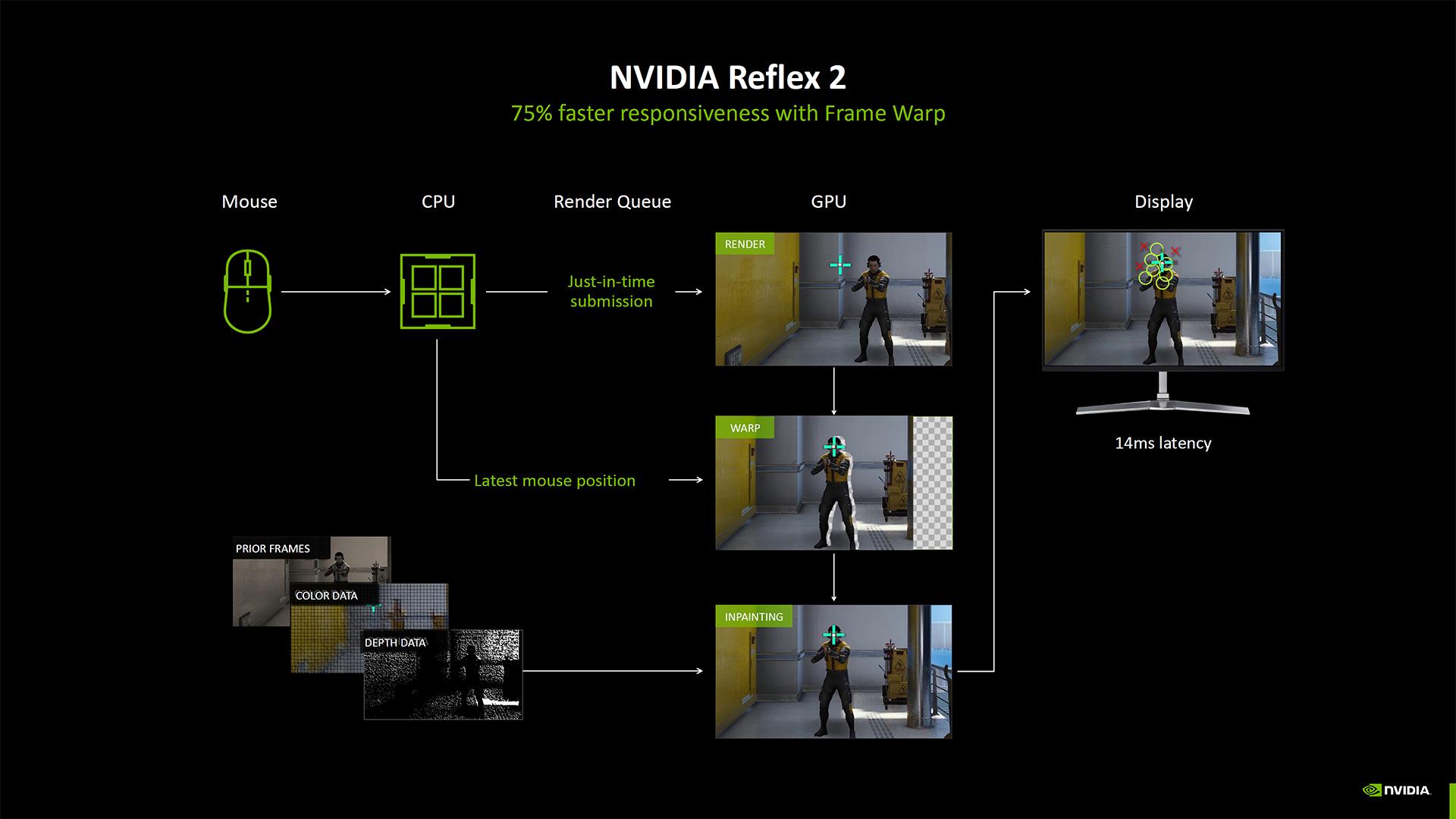
Pour contrebalancer la latence induite par son arme de destruction massive dans la guerre de la Frame Generation, NVIDIA mise sur le Reflex 2. Cette version introduit un système de prédiction et d'in-painting.

Enfin, via la NVIDA App, les joueurs pourront choisir leur Frame Generation fétiche.
Terminons par une diapositive plus générale. Elle montre la hausse exponentielle du nombre de polygones dans les jeux depuis 30 ans. Nous sommes passés, au début des années 1990, d’environ 1 000 à 10 000 polygones par scène, à entre 10 et 50 millions dans un jeu comme Cyberpunk 2077.
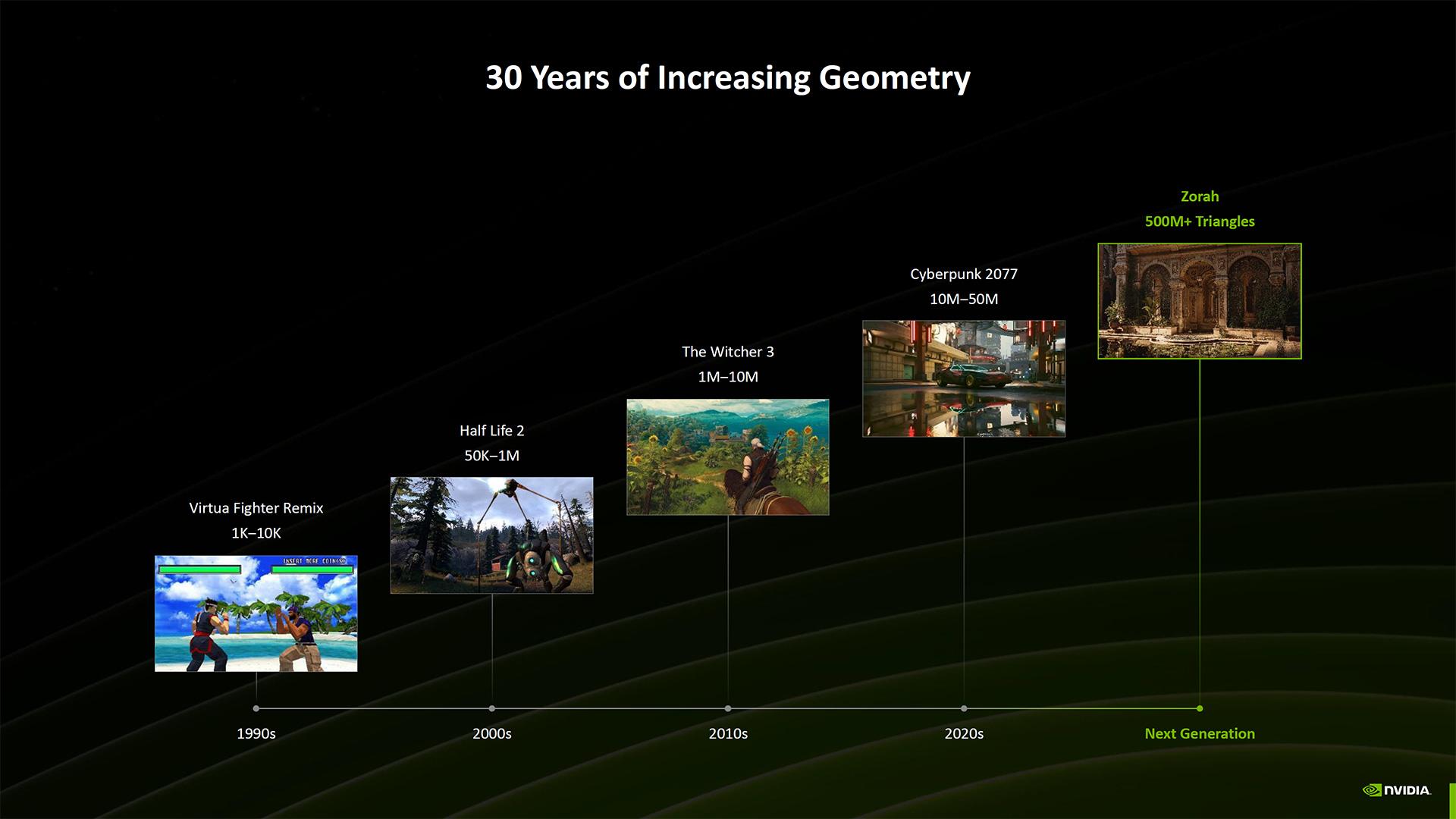
NVIDIA entrevoit déjà les 500 millions. Comme dans sa démo technique Zorah, que vous pouvez visionner ci-dessous.





















