Test • nVIDIA GeFORCE GTX 680 |
————— 22 Mars 2012



Test • nVIDIA GeFORCE GTX 680 |
————— 22 Mars 2012
Cette année 2012 est une année charnière dans le monde des GPU, car elle inaugure comme d'autres avant elle un nouveau procédé de fabrication pour les puces graphiques. Pour rappel, les 2 principaux concepteurs de GPU (destinés à des cartes graphiques et excluant donc Intel) sont dépourvus d'outils de production propres. En conséquence, cette dernière est sous-traitée à des sociétés tierces, TSMC se taillant la part du lion dans ce domaine. Depuis plus de 2 ans, les GPU utilisaient le 40 nm du fondeur, à présent la fabrication bascule vers le processus 28 nm gage de davantage de transistors par mm² permettant ainsi de réduire la consommation et augmenter la complexité des puces pour un coût de production similaire.
C'est généralement par ce biais que les plus gros gains sont observés d'une génération de GPU à une autre. L'architecture de la puce a également son mot à dire et les orientations prises par les 2 concepteurs peuvent entraîner des gains instantanés plus ou moins importants à l'exemple des HD 7900 bien plus complexes que la génération précédente par le biais du 28 nm, mais avec de nombreux arbitrages en faveur du GPU computing qui ne se retrouvent pas forcément en performance 3D. Le caméléon, adepte des puces monolithiques imposantes n'a pour ce GK104 pas battu pour autant des records de complexité. En effet, ce dernier est annoncé comme comportant "seulement" 3,5 Milliards de transistors contre 3 Milliards au GF110 de la GTX 580 et 4,3 Milliards pour Tahiti des HD 7900. En conséquence, la surface du die se limite à 294 mm² contre 365 mm² à la puce concurrente et 520 mm² au GF110.

Photo du Die d'un GK104 "Kepler" et de ses 3,5 milliards de transistors
AMD faisant des puces plus complexes que nVIDIA, voilà une situation que l'on avait plus connue depuis belle lurette, toutefois la numérotation de ce GPU GK104 indique qu'il ne s'agit pas ici de la puce la plus complexe de la lignée, puisque pour cette dernière le 0 serait de mise à la fin du code GPU (ici GK100 ou GK110) pour le haut de gamme. D'un autre côté, le "680" de la nouvelle carte ne laisse aucun doute quant à son positionnement, bref on serait tenté de croire qu'il s'agit ici d'une carte haut de gamme animée par un GPU moyen de gamme, tout du moins dans sa numérotation puisqu'au-delà de celle-ci et de la surface de die utlisée, c'est bien les performances qui dictent sa valeur commerciale ! Voyons donc ce qui a été concocté pour ce GK104.
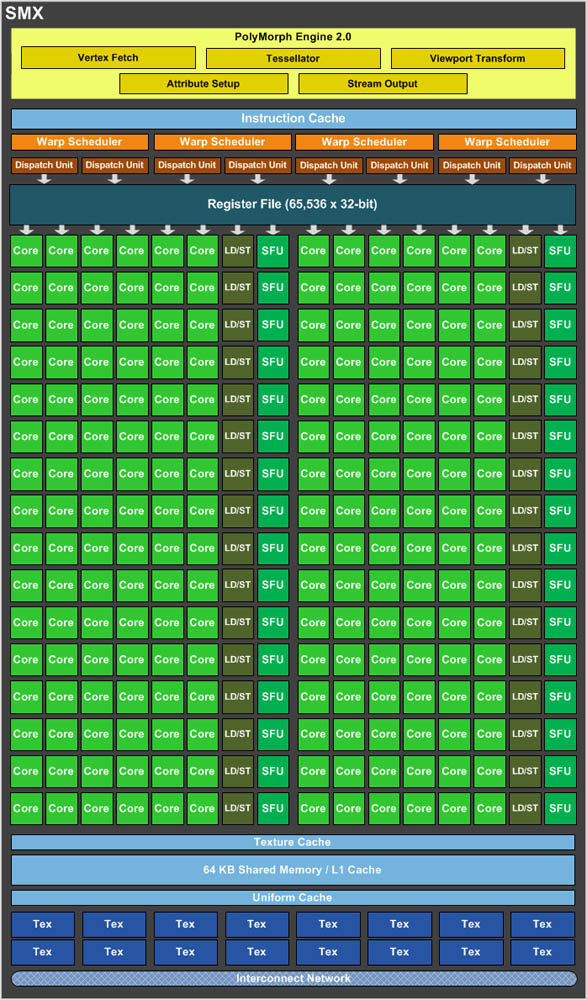
Pour rappel, nVIDIA a lancé sa première architecture compatible Direct3D 11 en mai 2010 qui portait le nom de Fermi. Elle s'articulait autour de blocs multifonctions nommés SM pour Streaming Multiprocessors, capables de réaliser les opérations sur les shaders, la géométrie et le texturing. Ces SM sont regroupés en GPC (Graphics Processing Clusters) en liaison avec les contrôleurs mémoires, cache L2 unifié et interfaces. Pour Kepler, les GPC (4) sont toujours à la base de la puce comme en témoigne le schéma de principe suivant :
![Diagramme Kepler [cliquer pour agrandir]](/images/stories/articles/gpu/gtx680/screen/diagram_gk104_t.jpg "Ultra bouzotron HD max def")
Diagramme Kepler - Cliquer pour afficher un seul SMX en gros plan
Toutefois ces derniers ne sont plus composés de SM mais de SMX, Késako ? En fait nVIDIA a orienté son approche vers une meilleure performance par Watt qui était, il faut bien le reconnaitre, le talon d'Achille de Fermi. C'est dans cette optique qu'a été décidé l'abandon du domaine de fréquence spécifique pour les shaders, qui pour mémoire étaient deux fois plus rapides que le reste du GPU (soit ~1,5 GHz pour la GTX 580). En effet, pour assurer de telles fréquences, les unités étaient jusqu'à 4 fois plus gourmandes du fait d'un pipeline deux fois plus complexe et moulinant à deux fois la fréquence ! Le passage au 28 nm permet par contre d'accroitre la densité de transistors et en compensation les SMX se voient dotés de 192 Cuda Cores (unité de calcul scalaire) contre 32 aux SM de Fermi soit un ratio de 6 !
NVIDIA a également multiplié par 8 le nombre d'unités effectuant les opérations complexes (SFU) par SMX et par 4 les unités de texturing. Ces dernières sont d'ailleurs modifiées pour s'affranchir de la limite de 128 textures par cycle, toutefois cette fonctionnalité n'est accessible que sous OpenGL pour le moment en attendant une éventuelle prise en charge dans une future version de DirectX. Un gros travail de simplification a été réalisé au niveau du scheduler qui attribue les ressources matérielles selon les besoins du code : nVIDIA a réalisé que l'information permettant d'envoyer au rendu une instruction prête pouvait être dans de nombreux cas déterminée à l'avance (latence constante) et s'affranchir ainsi des ressources matérielles précédemment utilisées pour cette tâche en la confiant au compilateur.
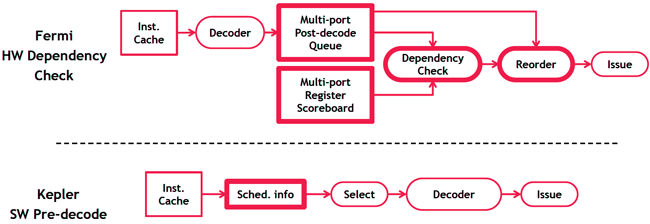
Un exemple de scheduling : Fermi vs Kepler, ou la simplification du hardware
Last but not least concernant les SMX, le Polymorph Engine qui est la pierre angulaire de la supériorité architecturale du caméléon sur la concurrence dans le domaine géométrique (unités découplées et démultipliées par SM limitant ainsi l'engorgement d'une ou deux unités pour le GPU) se voit révisée en permettant le traitement de 2 fois plus données par cycle que la version incluse dans Fermi. Chaque SMX se voit toujours doté d'un cache L1 de 64 Ko et de cache dédié aux instructions et textures.
Au final, le GK104 inclut 8 SMX (bizarre tiens, le même nombre que pour les GF104/114 ce qui en dit long sur le placement originel de cette puce) en son sein ce qui conduit à la présence de 1536 Cuda Cores, 128 TMU et 8 Polymorph Engine. Ces derniers sont donc divisés par 2 par rapport au GF110 qui comptait 16 SM, nous verrons en pratique s'ils sont réellement 2 fois plus performants. Lorsque l'on couple tous ces éléments aux différentes variations de fréquences (plus rapide pour le GPU, moins pour les shaders), le nouveau-né serait 2 fois plus performant en calcul, 2,6x en texturing et 1,3x en géométrie que le précédent flagship du caméléon. Pour le reste, on note toujours la présence d'un cache L2 unifié de 512 Ko dont la bande passante est en hausse de 73% pour s'adapter à la puissance des SMX.
Les ROP passent de 48 à 32, soit une baisse de 33% proportionnelle à la réduction du bus mémoire, qui n'est plus composé que de 4 contrôleurs 64-bit (256-bit en tout) contre 6 au GF110 (pour un bus total de 384-bit sur ce dernier). Le caméléon n'a par contre pas lésiné sur les moyens pour conserver intact la bande passante disponible en développant des contrôleurs mémoire GDDR5 capables d'atteindre 6 Gb/s pour un débit mémoire inchangé ou presque à 192 Go/s. NVIDIA indique avoir travaillé dur sur le design du circuit physique et l'intégrité du signal pour atteindre de telles fréquences.
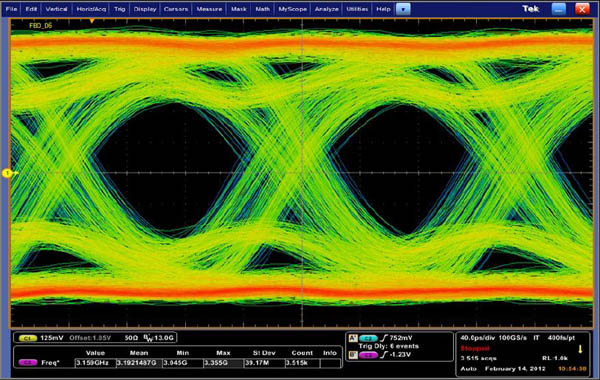
Une vue du signal à 6 Gb/s
Passons en revue les nouvelles fonctionnalités apportées par Kepler page suivante.
|
|
| Un poil avant ?Les GeForce 301.10 WHQL pour GTX 680 sont disponibles | Un peu plus tard ...GlobalFoundries fête son 250 000e wafer 32nm | |





















