Grace Hopper se dévoile en chiffres (et en lettres) sur MLPerf |
————— 12 Septembre 2023 à 12h05 —— 45080 vues



Grace Hopper se dévoile en chiffres (et en lettres) sur MLPerf |
————— 12 Septembre 2023 à 12h05 —— 45080 vues
Petite incartade du côté datacenter. Les premiers benchs du prochain supermodule CPU + GPU du camé léon, une première en termes d'intégration puisqu'elle se fait sur deux dies distincts, font surface depuis la présentation du projet en 2022. Halte au suspens, attendu pour Q2 2024 le GH200 affiche un jusqu'à + 17% face à un seul H100 sous MLPerf v3.1, en tout cas selon les chiffres donnés par NVIDIA qui sont sans nul doute obtenus dans des circonstances très « cadrées ».
Un résultat réalisé sur le modèle GPT-J, réseau autorégressif à 6 milliards de paramètres, qui comme vous pouvez vous en douter synthétise des données textuelles. Un réseau LLM néanmoins modeste si on le compare à un GPT-NeoX à 20 milliards de paramètres datant de 2022, des 175 milliards de GPT-3... ou des 1.76 trillion (1 760 000³ ... ouais ouais, c'est ça) d'un GPT-4. Des résultats à priori ne tenant pas compte des récents gains logiciels obtenus avec les librairies TensorRT-LLM.
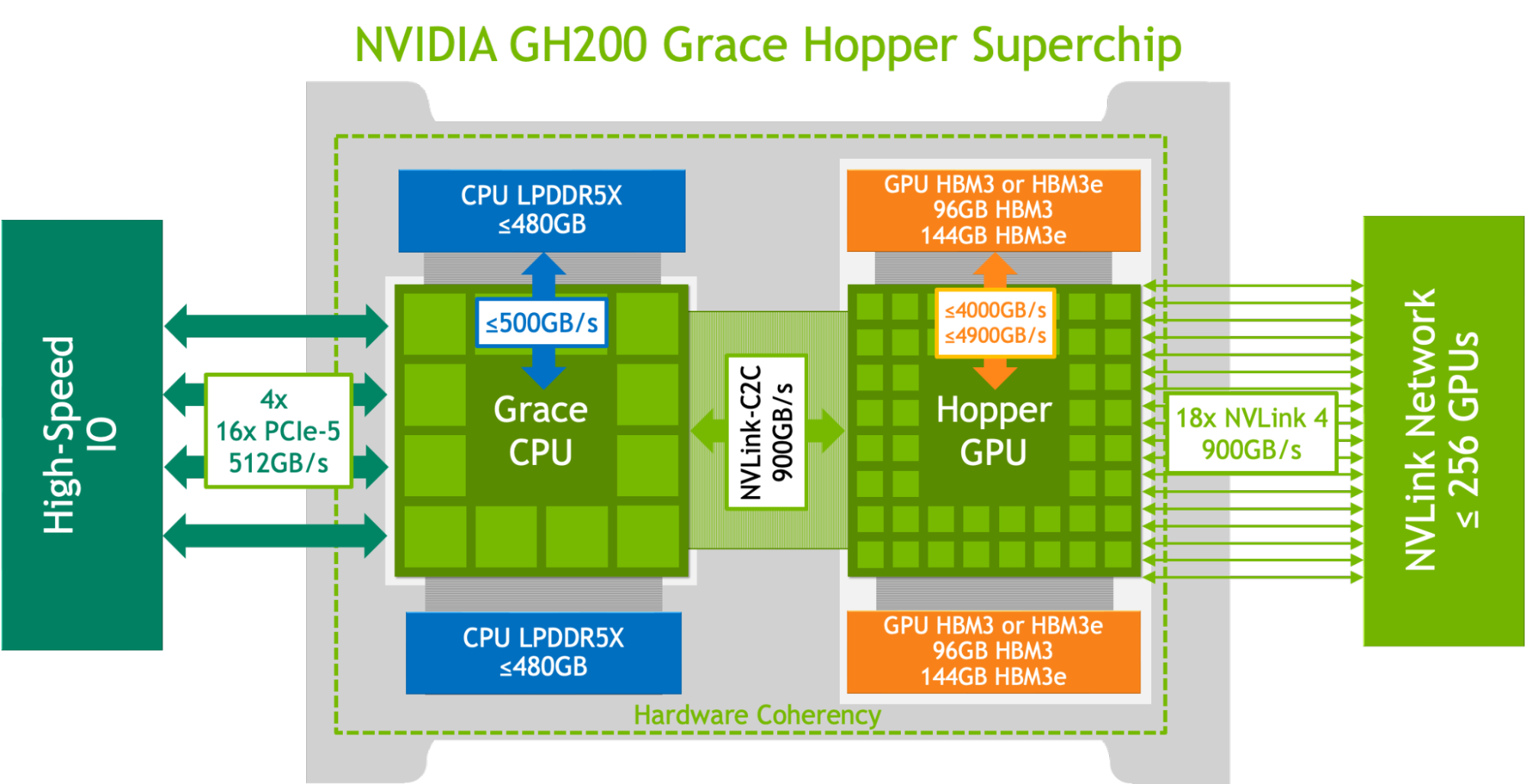
Diag logique du GH200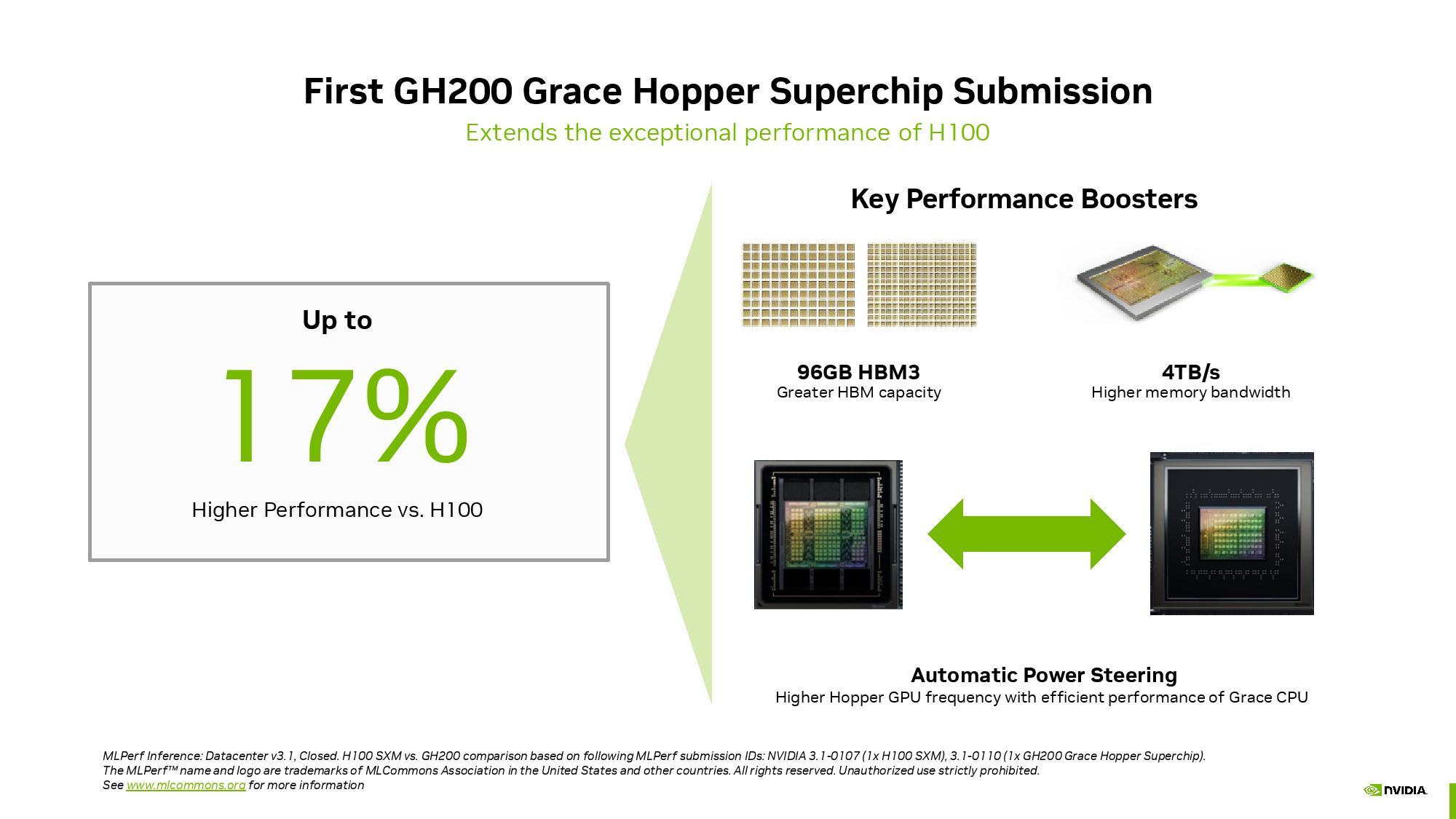
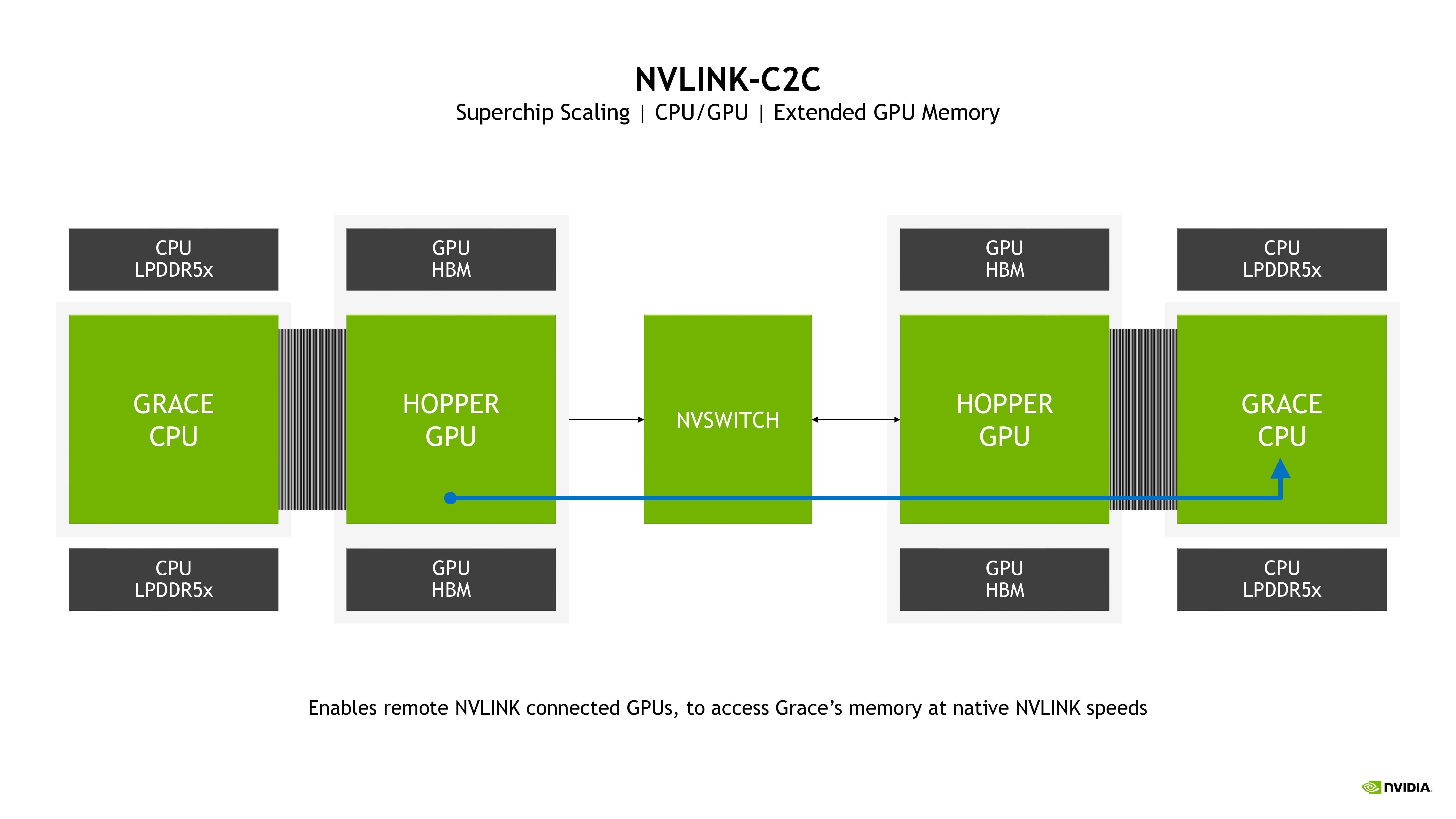
Grace Hopper est un superchip combinant un GPU Hopper et un CPU Grace à 144 cœurs ARM sur la même carte, avec un interconnect cohérent CPU↔GPU chip to chip (C2C) — permettant de transporter directement les données entre les niveaux de cache des deux SoC, sans passer par des accès mémoires — offrant la bagatelle de 900 putains de Go/s théoriques, soit 7 fois ce qui propose le PCIe 5.0 :
![NVIDIA Grace Hopper nvlink C2C [cliquer pour agrandir]](/images/stories/_cpu/arm/nvidia-grace-hopper-nvlink-c2c_t.jpg "Cliquédélique !")
L'interconnect NVLINK C2C pour les relier tous et dans les Go/s les lier
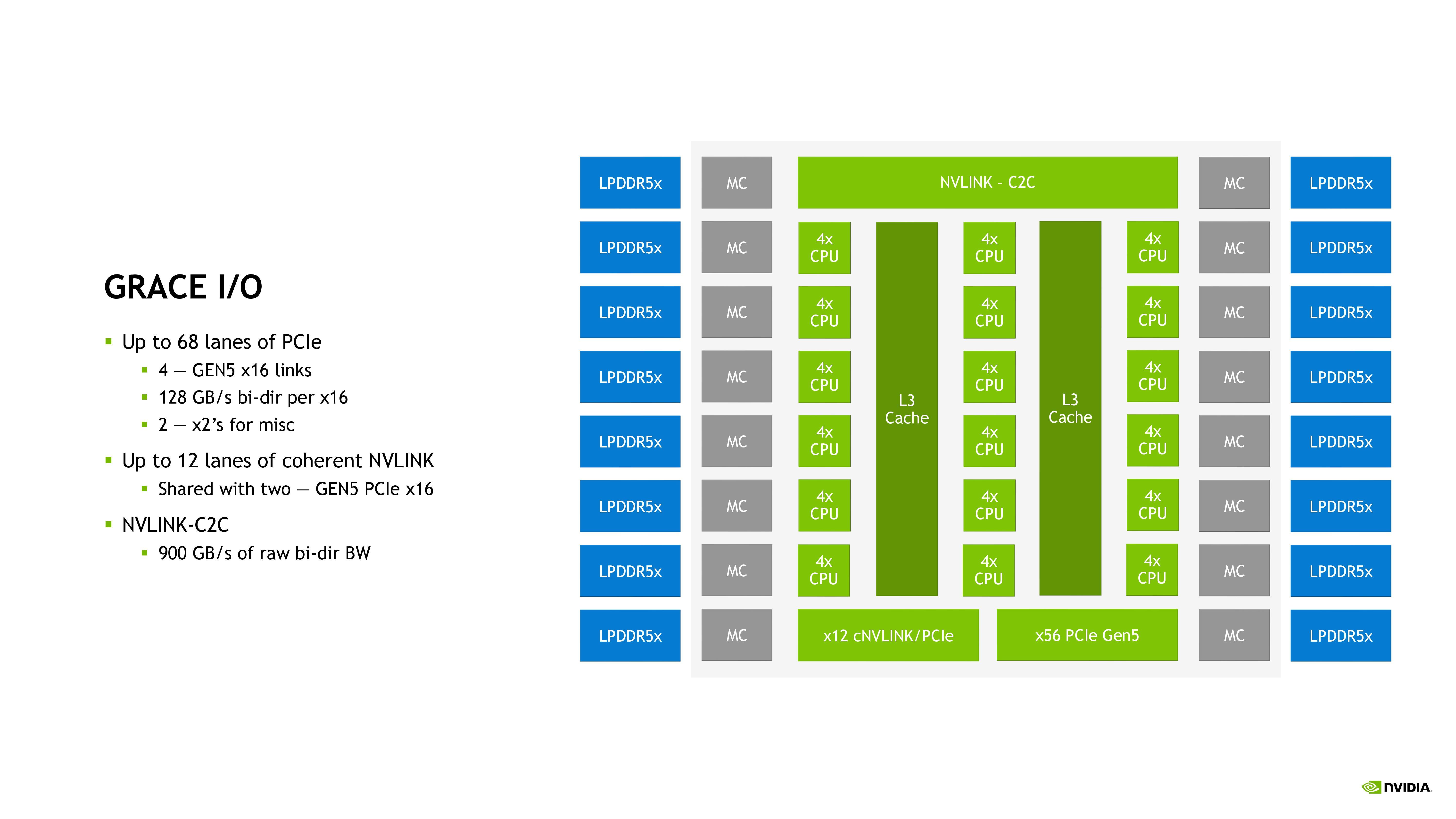
![NVIDIA Grace I/O [cliquer pour agrandir]](/images/stories/_cpu/arm/nvidia-grace-io_t.jpg "Si vous cliquez, vous cliquez.")
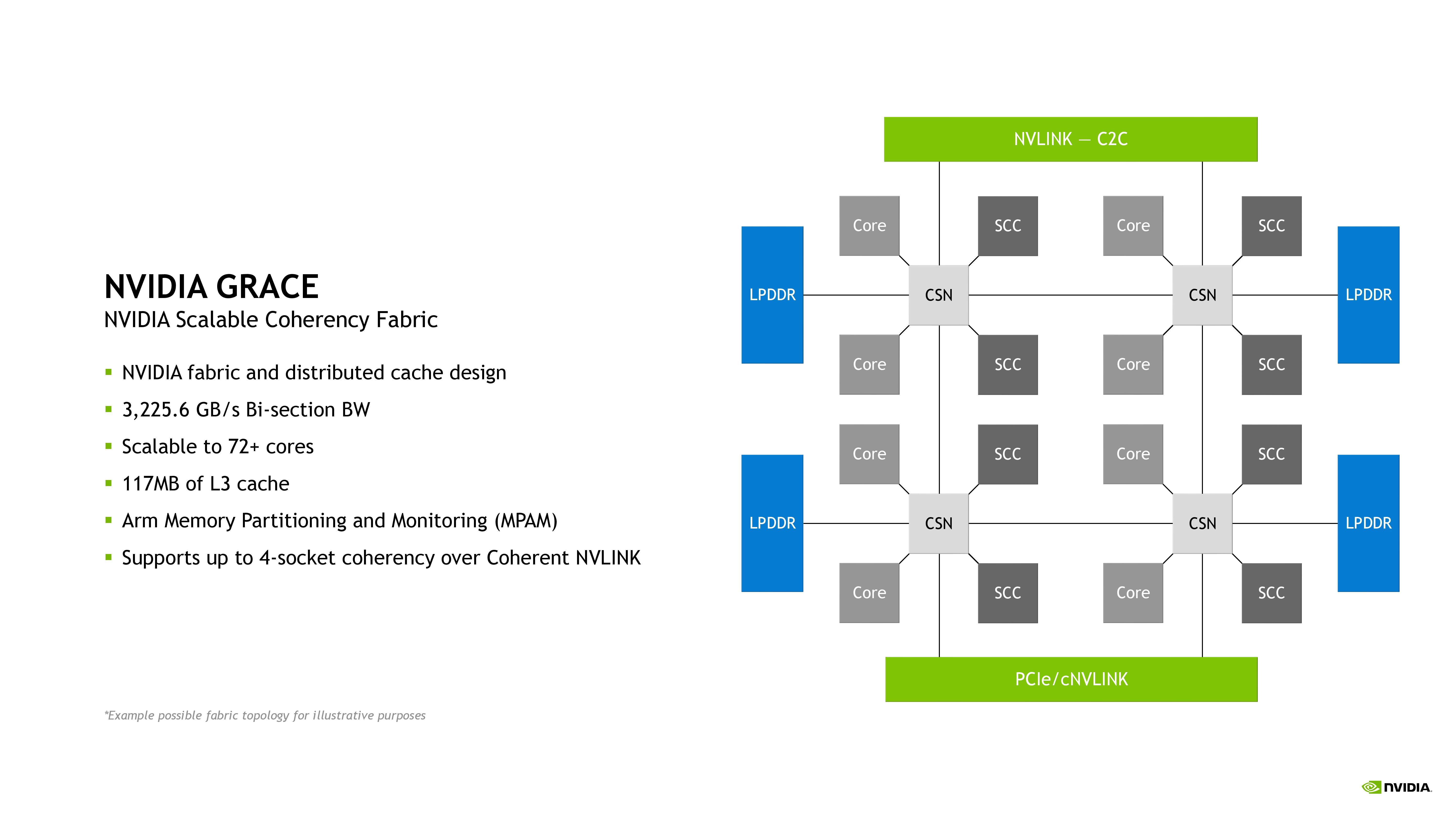
![NVIDIA Grace interconnect [cliquer pour agrandir]](/images/stories/_cpu/arm/nvidia-grace-interconnect_t.jpg "Si vous cliquez, vous cliquez.")
Rappel - L'archi mesh de Grace plus en détails, jusqu'à 68 lignes PCIe / 12 lignes NVLINK
Quant au GPU L4, mis en lumière à l'occasion et basé sur l'architecture Lovelace, c'est un GPGPU destiné à l'exécution des inférences et positionné face aux CPU habituellement dévoués à cette tâche, dont on devine que le temps est désormais compté. Celui-ci mouline sous un TDP de seulement 75 W, est donné pour 6x les performances d'un chiplet x86 Xeon 9480 (56C / 112T, Sapphire Rapids) et pour 120 fois la performance énergétique face à un couple de Xeon 8380 (32 C / 64T, Ice Lake). Cette dernière comparaison dont on essaye encore de comprendre la pertinence, tant sur la place disponible par châssis que par la génération des puces Intel... Qui sont nettement moins spécialisées. On notera l'absence d'AMD dans ces benchmarks.
Des chiffres vertigineux qui en disent long sur la course opérée aux datacenters spécialisés et de l'ampleur qu'est en train de prendre ce marché.
| Un poil avant ?Test • Lian Li PC-O11 dynamic evo XL | Un peu plus tard ...À la fin de l'épopée, c'est l'EPOS 'trophe finale | |