La synthèse haut-niveau à la rescousse de la conception hardware ? |
————— 30 Août 2019 à 14h37 —— 13387 vues



La synthèse haut-niveau à la rescousse de la conception hardware ? |
————— 30 Août 2019 à 14h37 —— 13387 vues
Nous vous parlons parfois de FPGA et autres ASIC : des puces capables d'effectuer une tâche précise (dans un cas reprogrammable, dans l'autre fixée à la conception), différant ainsi des CPU et GPU qui sont quant à eux, généralistes. Comprenez que, bien que la vitesse d'exécution soit radicalement différente selon la tâche, CPU comme GPU prennent en entrée des instructions, leur permettant ainsi de calculer n'importe quelle donnée tant que celle-ci n'est pas un fantasme mathématique.
Or, ces puces au design fixé n'ont pas d'équivalent pour une instruction. Des données sont prises en entrée et traitées selon une suite d'opérations logiques préétablie, qu'il faut donc concevoir. Or, décrire ce comportement au plus bas niveau - il est alors question de RTL, Register-Transfer Level - est une tâche ardue, bien plus complexe et demandeuse de réflexion que la programmation logicielle. C'est pourquoi de nombreuses entreprises ont développé (suite à des recherches publiques, soit dit en passant) des outils de synthèse haut niveau. Ces derniers, citons Vivado HLS chez Xilinx, ou Intel HLS chez Intel/Altera, permettent de compiler un programme C ou C++ (voire SystemC pour les plus aventureux) en un design de FPGA sans pour autant qu'aucune connaissance préalable ne soit nécessaire.
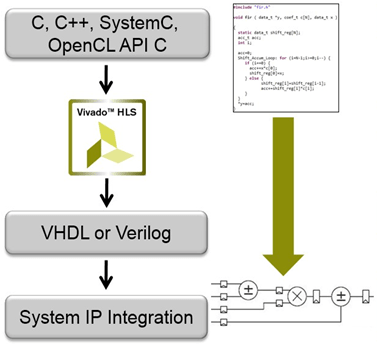
Cependant, la notion d'"aucune connaissance préalable" est quelque peu irrespectée. En effet, un code C pourra être compilé normalement, mais il faudra se contenter de performances anémiques - encore faut-il que le code en question respecte les contraintes de la HLS : toutes les fonctionnalités du C ne sont pas supportées, en particulier en ce qui concerne l'arithmétique de pointeurs et l'allocation mémoire dynamique. Il faut donc annoter voire réécrire des morceaux entiers de code source pour l'adapter au périphérique cible, ce qui demande finalement de l'expertise et du temps... si bien que le code final peut ressembler fortement au RTL - que la HLS voulait éviter ! Et cela se comprend : dans une puce où la mémoire n'est pas une RAM globale et où des contraintes fortes existent sur les tailles des caches et des pipelines, difficile de tomber magiquement sur une structure de programme tirant au maximum parti de cette organisation logique à partir d'un code arbitraire.
Néanmoins, avec le ralentissement de la conjecture de Moore, les designs sur mesure prennent de plus en plus d'importance, y compris dans la sphère privée. Il n'y a qu'a voir les RT Cores présents dans Turing qui spécialisent ce que les cœurs généralistes CUDA ne peuvent pas faire dans les contraintes de temps inhérentes au rendu temps réel des jeux vidéos. Ou encore le Mac Pro édition râpe à fromage, qui utilise une accélération par FPGA pour le traitement vidéo.
De plus, la description sémantique induite par la HLS - le programmeur code ce qu'il souhaite obtenir comme résultat, et non l'architecture qui y parvient - facilite grandement les processus de validation du design, tout comme l'élaboration de prototypes. Difficile cependant de voir à court terme une co-conception efficace entre le matériel et le logiciel, ces deux camps se vouant depuis leur création une guerre pavée d’incompréhension mutuelle et de compétences radicalement opposées - autant dire qu'il faudra encore de gros progrès avant de voir des résultats applicables au grand public. (Source : SemiEngineering)





















