NVIDIA GTC : Hopper H100, te voilà ! |
————— 23 Mars 2022 à 13h07 —— 27174 vues



NVIDIA GTC : Hopper H100, te voilà ! |
————— 23 Mars 2022 à 13h07 —— 27174 vues
Alors que les caractéristiques techniques du dernier monstre de NVIDIA semblaient avoir fuité un jour avant sa présentation officielle, voilà que notre chez Jensen Huang vient remettre les points sur les i à l’occasion de la GPU Technology Conference, également abrégée GTC. En effet, durant l’heure et demi d’énumération de frameworks divers et variés sur fond d’images de synthèse et d’IA se trouvait l’annonce de la puce la plus puissante jamais créée : Hopper et ses 16 896 cœurs CUDA (version SXM5) ou 14 592 cœurs CUDA (sauce PCIe).
Alors que certains la présageaient en 5 nm sauce N5 de chez TSMC, il n’en est rien dans les fait, puisque la belle fait en réalité usage du N4 de la firme, souvent nommé 5 nm par abus de langage ! La bagatelle de 80 milliards de transistors se trouve ainsi compressée sur un die monolithique de 814 mm² de silicium, soit un petit 50 % d’augmentation de la densité par rapport au 7 nm de la A100 précédente. Rajoutez un bon cocktail de technologies en vogue à base de PCIe 5 (elle est d’ailleurs la première à en faire usage en matière de GPU), de la HBM 3 (first également, à raison de 80 Gio, rétrogradés en HBM 2e sur la version PCIe) disposée au moyen du procédé CoWoS de la firme ainsi que 40 Tbits/sec de bande passante pour les entrées/sortie (probablement obtenus en sommant les bandes passantes du NVLink et du bus PCIe), et voilà pour la compétitrice du jour. Enfin, c’était en oubliant presque son TDP, qui pourra courir jusqu’à… 700 W. Il y aurait intérêt à sacrément ventiler les racks pour réussir à dissiper un tel bousin !

En interne, la microarchitecture évolue également : le calcul en FP8 est désormais supporté — Machine Learning en tête des usages potentiel — à raison du double de la vitesse du FP16, soit 8 PFLOPS. En ce qui concerne le FP16 et le TF32, il est respectivement question de 2 PFLOPS et 1 PFLOPS ; chiffre tombant à 60 TFLOPS en flottant simple et double précision. Rajoutez une amélioration des Tensor Cores, qui intègrent désormais un Transformer Engine : de quoi mapper automatiquement les couches des réseaux transformers développés en interne par les verts sur les unités de calcul existantes à grand coup de précision mixte FP8+FP16.
Cependant et heureusement, le ML n’a pas le monopole des améliorations architecturales : un système de chiffrement des calculs, le Confidential Computing, est également au programme, similaire au SGX de chez Intel, SME chez AMD ou encore CCA chez Arm. Au cœur du bousin, l’idée de sécuriser ses données en les chiffrant au niveau matériel afin de se protéger d’éventuelles attaques dans un scénario où l’hébergeur serait compromis — typiquement le cloud.
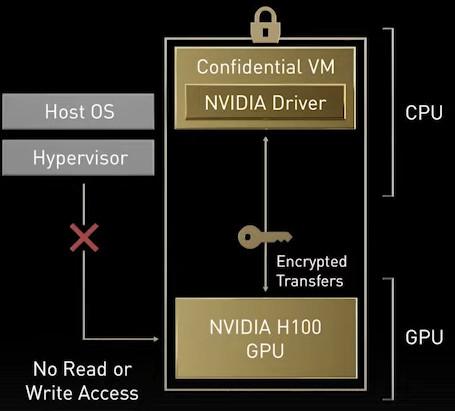
Dans le même registre, des nouvelles instructions nommées DPX permettant d’accélérer les algorithmes se basant sur le paradigme de la programmation dynamique sont au rapport. Elles permettraient des gains importants affichés jusqu’à un facteur 40, officiellement du moins. Rajoutez des fonctionnalités de virtualisation toujours plus avancées avec 7 VM maximum par carte et la possibilité de virtualiser également séparément les communications de ces 7 GPU virtuels, permettant ainsi de les faire fonctionner simultanément dans le cloud.
Si jamais vous souhaitez vous en procurer une, NVIDIA a un bon tas de plans pour vous : les H100 sont ainsi disponibles soit dans une version PCIe plus conventionnelle (mais au refroidissement passif, utilisation pour serveur obligeant), soit au format SXM5. Dans tous les cas, le protocole magique de communication intercartes, le NVLink, est également dans la fête. Cela tombe bien, il est possible de lier 8 de ces cartes ensemble : de quoi former un PCB nommé HGX, lui-même au centre des plus gros DGX-H100 (à raison d’un HGX par DGX).

Ces modules peuvent être exploités tels quels, mais, si vous n’avez pas de limite du budget, alors, la solution des PODs (assemblage de DGX) et des SuperPODs (assemblages de PODs, vous avez compris l’histoire) sera une valeur d’autant plus rentable sur le long terme.

Car NVIDIA s’est aventuré sur le segment des puces de réseau histoire de diminuer les coûts des transferts mémoires entre GPU. Ainsi, les NVIDIA NVLinks Switchs, articulés autour de 4 ports fibre optique par DGX-H100 connecté, dans la limite de 32 machines maximum, offrent 8 canaux par port supportant 100 Gbit/sec en PAM4 : de quoi roxxer du ponez en datacenter.

En ce qui concerne l'intégration de l'architecture Hopper dans le paysage des supercalculateurs existants, pas de panique : une machine du nom de NVIDIA EOS, composée de 18 superPODs, soit 275 TFLOPS en FP32/64 répartis sur les 768 DGX-H100, est en construction. Pour redonner un peu de contexte, cela correspond à une machine 1,4 fois plus performante que le supercalculateur scientifique le plus puissant actuellement disponible au pays de l’oncle Sam.
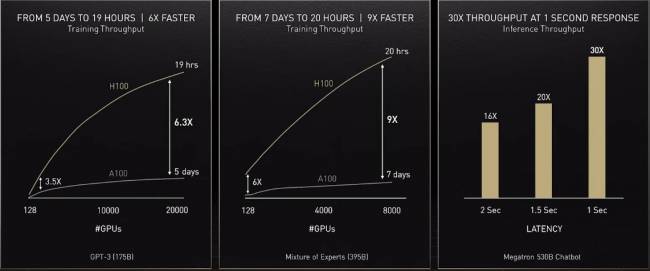
Enfin, côté performances en machine learning, NVIDIA se vante de gains faramineux comme à chaque sortie de carte : un facteur 6 par ici, un facteur 9 par là, une augmentation du débit d’un facteur 30 (rien que ça)… Reste à mettre tout cela à l’épreuve de la réalité en testant par des mains un peu plus objectives — pas vraiment celles de votre Comptoir chéri pour ce type de produit ! Néanmoins, les améliorations architecturales des gammes serveur arrivant très souvent dans les générations futures, il n’y a qu’à attendre les déclinaisons grand public pour observer un cousin d’Hopper se pavaner sous DirectX. Affaire à suivre !
| Un poil avant ?Thermaltake Versa T26 et Versa T27 TG ARGB : 1 boitier, 2 choix de façades "originales" | Un peu plus tard ...Test • ASRock Z690 Phantom Gaming-ITX/TB4 | |





















