Face à NVIDIA, la concurrence des cartes accélératrices de Machine Learning viendrait de.... Qualcomm ? |
————— 05 Octobre 2021 à 12h15 —— 14937 vues



Face à NVIDIA, la concurrence des cartes accélératrices de Machine Learning viendrait de.... Qualcomm ? |
————— 05 Octobre 2021 à 12h15 —— 14937 vues
En milieu de mois, Qualcomm annonçait une puce un peu spéciale : l’AI 100 qui, comme son nom l’indique, est destinée au machine learning. Si la firme s’aventure ainsi relativement loin des SoC mobiles Snapdragon dont nous avons l’habitude, l’écart n’est pas non plus démentiel avec « seulement » 75 W de TDP maximum pour la nouvelle venue. Beaucoup, vous dites ? Pas de soucis, la maison-mère a en fait prévue trois variantes : une carte PCIe, une version en dual M.2 et une en dual M2.e, ces deux dernières allant de 15 à 25 W — sachant que la M.2e n’a pas de radiateur, son dégagement thermique pouvant ainsi être fortement bridé. Sans grande surprise, cette gamme se place parfaitement pour s’intégrer à l’edge, c’est à dire dans des serveurs à la consommation maîtrisée que l’on installe proche des infrastructures clientes (au contraire des datacenters, localisés selon un choix économique ou politique).
![Des cartes presque haute performance chez Qualcomm ? [cliquer pour agrandir]](/images/stories/_hardw-autre/machine-learning/qualcomm-cloud-ai-100_t.png "Visionner en grand sur un magnifique pop-up")
Sous le capot, le 7 nm TSMC est aux ordres, les américains profitant ainsi de leur expertise sur mobile. Au niveau architectural, le die est décomposé en 16 « AI Core » dotés chacun de 1 Mio de L2 et 8 Mio de cache TCM (amputé de moitié sur la version mobile) servant à stocker les données immobiles lors de la mise en route d’un réseau de neurones : les poids. Côté calcul, le processeur est un VLIW à 4 voies hérité des accélérateurs de ML mobiles, épaulé par un accélérateur matriciel, le tout capable de délivrer 512 MAC INT8 par cycles, ou 256 MAC/cycle en FP16. Le tout est relié à de la LPDDR4x sur un bus 256-bit (ou 128-bit pour la version embarquée), et se lie avec le système hôte en PCIe 4.0 x8.
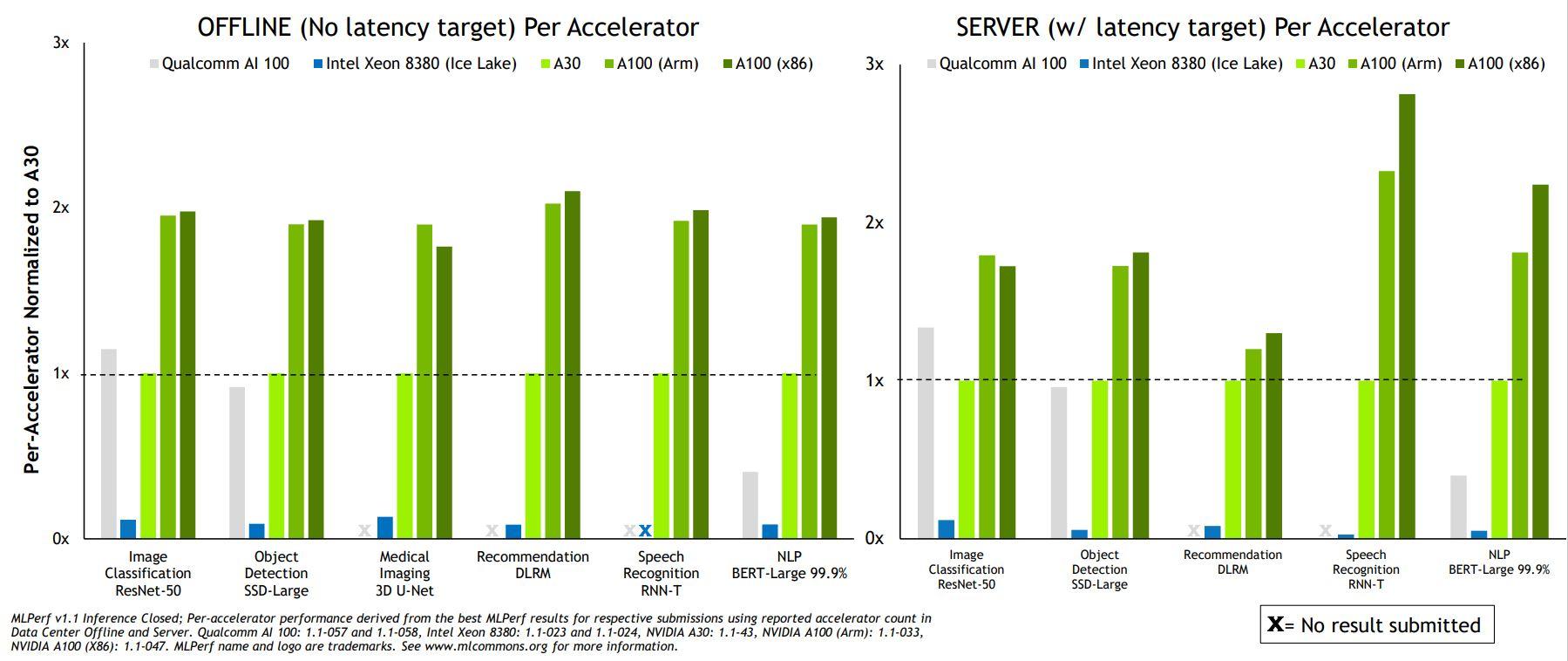
Si rien ne semble bien novateur sur la microarchitecture — mis à part l’idée de ressortir du placard un VLIW pas vraiment resté dans les annales —, Qualcomm défend cores (hohoho) et âme son bébé et a récemment soumis plusieurs de ses cartes à la suite de benchmarks MLPerf. Mis en paquet de 4 ou de 8, les AI 100 ne sont pas encore à la hauteur de la A100 de NVIDIA, reine du genre, sur les performances ; mais du côté de l’efficacité énergétique, c’est une toute autre histoire.
![Des performances encore en deça des verts [cliquer pour agrandir]](/images/stories/_divers/stats/nvidia-accelerator-performances-2021_t.jpg "Même pas cap' de cliquer")
Notez que les graphes permettent également une comparaison frontale x86 vs ARM avec — de manière peu surprenante vu que c’est au GPU de bosser — peu de différence entre les deux
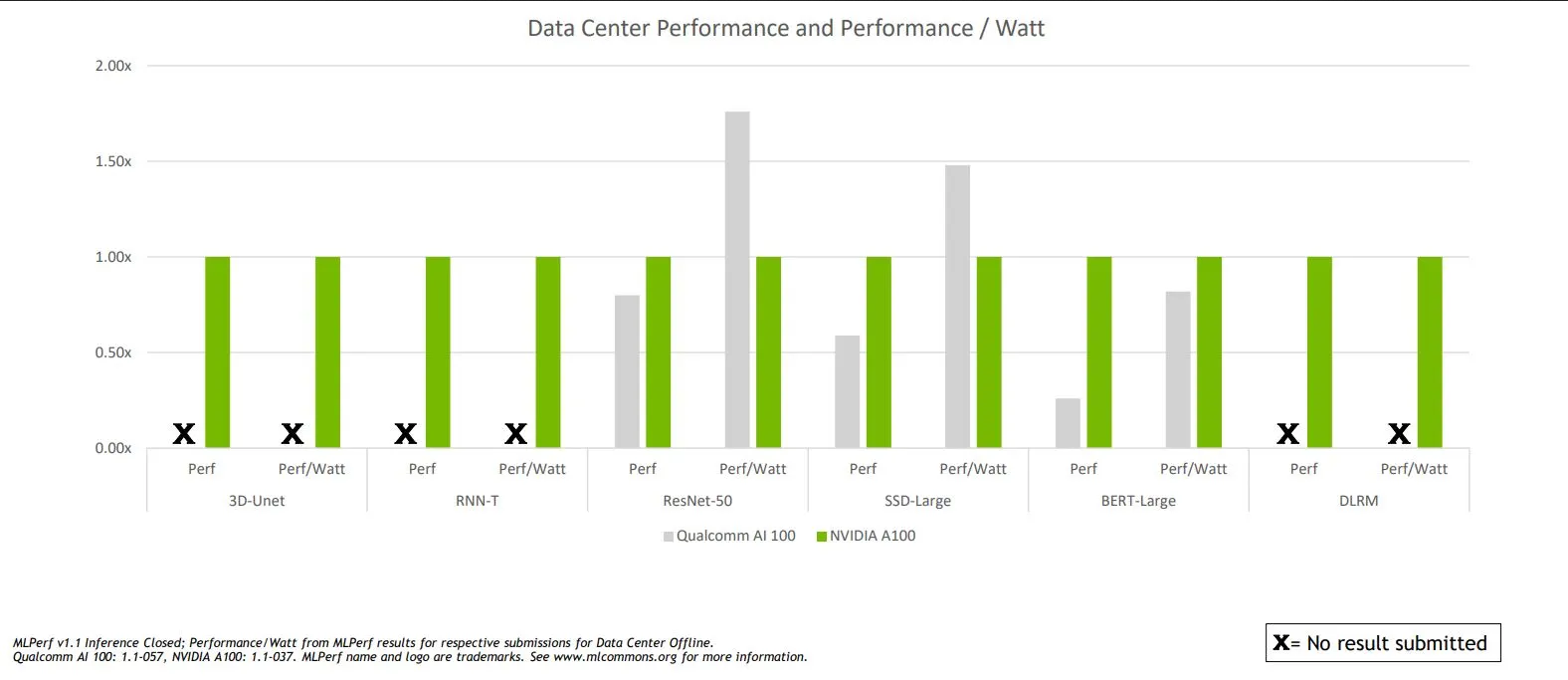
Pourtant, les deux cartes partagent le même procédé de gravure à savoir le 7 nm de chez TSMC mais grâce à l’architecture bien moins versatile de la carte, les 75 W de la nouvelle venue font fort, très fort même. Si les performances sont extrêmement variables, la moyenne est aux alentours d’une NVIDIA A30, qui pompe quant à elle... 165 W !
![Une efficacité énergétique remarquable [cliquer pour agrandir]](/images/stories/_divers/stats/nvidia-a100-vs-qualcomm-ai-100-efficiency_t.png "Même pas cap' de cliquer")
Reste que l’écosystème n’est probablement pas aussi bien poli que celui des verts, sans compter que la comparaison avec l’architecture Ampère pourrait vite se retrouver obsolète si Mr Coronavirus voulait bien se calmer. Reste que la AI 100 marque un solide premier jet dans le genre pour Qualcomm, et pourrait intéresser bien des investisseurs, voire des acteurs privés puisque cette enveloppe thermique place la carte dans le collimateur des voitures autonomes et leur « Embedded High-Performance Computing », encore faut-il avoir la matière grise suffisante pour créer un réseau tirant pleinement parti du matériel disponible. Affaire à suivre.... (Source : EETimes et WikiChip)
| Un poil avant ?AMD publie un pilote GPU important | Un peu plus tard ...Windows 11 est là, comment le choper ? | |