Test • AMD RADEON HD 7970 |
————— 10 Janvier 2012



Test • AMD RADEON HD 7970 |
————— 10 Janvier 2012
Pour rappel, AMD utilise depuis fort longtemps maintenant une architecture vectorielle à plusieurs composantes (ou VLIW). Ce modèle permet de loger un grand nombre d'unités de calcul dans le GPU et ainsi afficher des chiffres de puissance brute faramineux toujours bons pour le marketing. Le souci d'une telle approche provient du fait que les instructions doivent être fortement parallélisées pour tirer parti de toutes les composantes vectorielles par cycle d'horloge. Cette tâche est dévolue au compilateur qui optimise au mieux, mais en pratique le rendement de ces unités n'est pas très efficient a contrario des unités scalaires utilisées par nVIDIA depuis son G80. AMD a décidé avec Cayman, de simplifier un peu la tâche de ce dernier en revenant à une architecture à 4 vecteurs (Vec 4) contre 5 sur les précédentes Radeon HD et ainsi gagner en efficacité. Avec Tahiti, AMD procède à des modifications bien plus ambitieuses et annonce une nouvelle ère dans la conception des GPU succédant aux 3 précédentes que sont l'adoption du Transform & Lightning, les Shaders (avec de longues unités complexes) et la simplification/parallélisation/multiplication de ces dernières :

Les grandes ères des GPU résumées par AMD
Le terme GCN (Graphics Core Next) est censé représenter une toute nouvelle conception, quid en pratique ? Auparavant, le GPU était organisé en bloc SIMD comprenant 16 unités de calcul (de type Vec 4), 4 unités de texturing et le cache nécessaire au fonctionnement de tout ce petit monde. A présent, ces blocs existent toujours, mais s'appellent Compute Unit ou CU et leur nombre passe de 24 sur Cayman à 32 sur Tahiti ce qui conduit mécaniquement au passage de 1536 unités de calcul sur le premier à 2048 sur le second. Les unités de texturing suivent la même logique et passent donc de 96 à 128 (gain de 33%).
Gros changements toutefois, les unités ne fonctionnent plus de manière vectorielle, mais scalaire à l'instar des GeFORCE ce qui leur permettra de gagner en efficacité et allègera les travaux nécessaires sur le compilateur pour optimiser la parallélisation des instructions afin de tirer la quintessence des unités vectorielles. Espérons toutefois pour les possesseurs de RADEON plus anciennes qu'AMD n'abandonnera pas complètement ces optimisations... Pour le reste, la géométrie se contente toujours de 2 Setup Engine contre 4 au caméléon, les unités de tesselation ne sont toujours pas découplées au sein des CU (SM sur les GeFORCE), par contre AMD indique avoir amélioré l'efficacité des 2 unités via des caches plus larges et moins de pénalités lorsque ceux-ci sont saturés et que le GPU doit utiliser la mémoire vidéo pour compenser.
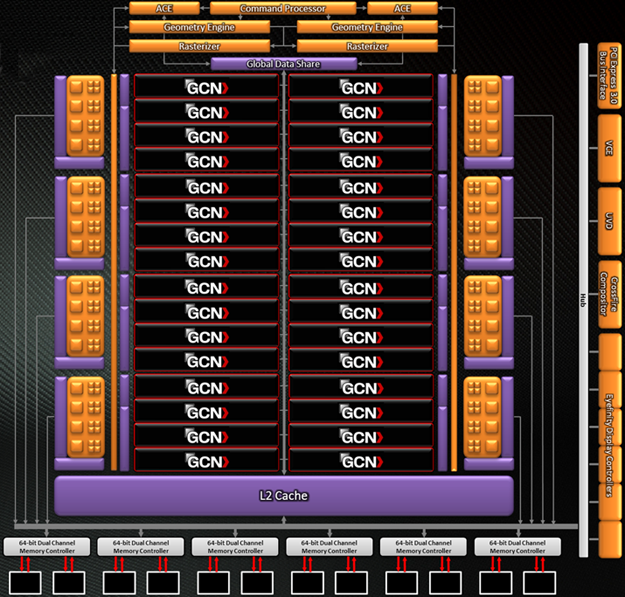
Diagramme GCN
Si les ROP (unités permettant d'écrire en mémoire et qui appliquent le filtre AA par ex.) ne changent pas et restent à 32, ils sont toutefois associés cette fois à 6 contrôleurs mémoire GDDR5 à l'instar des GF100/110 pour une largeur totale de 384 bits. Notons, pour finir sur la partie 3D, la prise en charge de DX11.1 qui est une évolution mineure principalement dévolue à faciliter la tâche des développeurs et rétrocompatible.
AMD a également revu en profondeur les caches et leur hiérarchie au sein de GCN, l'objectif étant à l'instar de Fermi de rendre ces derniers plus souples afin de pouvoir traiter aussi bien du rendu 3D que du GPU computing. Notons que le cache de type L2 est directement implémenté au niveau des contrôleurs mémoires. Enfin et toujours dans le but de favoriser l'utilisation du GPU computing, AMD a implanté 2 ACE (Asynchronous Compute Engines) pour la gestion du multitâches.
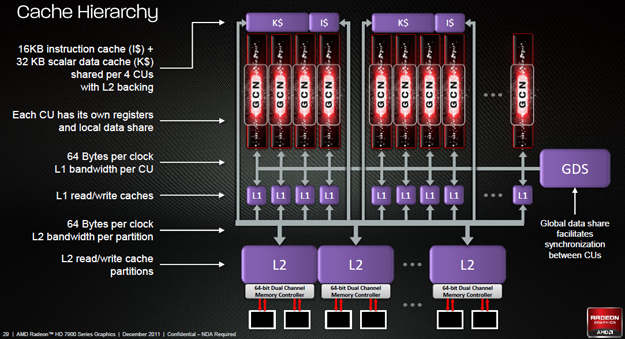
Les hiérarchies de cache GCN
Bref, GCN n'est pas une révolution en soi puisque la plupart des choix correspondent à ceux du caméléon avec Fermi, AMD opte en définitive pour la même approche ce qui devrait permettre l'essor du GPU computing à terme. Tout ceci n'est pas sans conséquence puisqu'à l'instar de l'architecture concurrente, GCN se montre diablement gourmand en transistors avec pas moins de 4,3 Milliards de ces petits bidules contre 2,64 à Cayman et 3 Milliards au GF110. Par contre AMD peut profiter du nouveau procédé de gravure 28 nm de TSMC conduisant à une superficie de die de 365 mm² sur le nouveau venu contre 389 mm² à Cayman et 520 mm² au GF110.

L'évolution de la gravure des GPU depuis 2005
Voilà pour la théorie, en pratique AMD lance pour le moment la version XT (haut de gamme) de Tahiti au travers de la RADEON HD 7970. Cette dernière embarque un GPU cadencé à 925 MHz et pas moins de 3 Go de GDDR5 cadencés à 1375 MHz. Notons également qu'Eyefinity Display dans sa version 2 et l'UVD3 se trouvent également intégrés, tout comme Powertune dans une évolution plus précise qui permet toujours de mesurer en temps réel de la consommation du GPU et limiter ce dernier à l'enveloppe thermique allouée par le fondeur via une réduction des fréquences si le besoin s'en fait sentir. Enfin friand des dernières technologies, AMD utilise la toute dernière norme PCIE 3.0 qui double les débits par rapport à la précédente révision sur Tahiti.

Récapitulatif cartes Cayman
Passons aux cartes que nous avons reçues page suivante.
|
|
| Un poil avant ?C'est officiel : la bêta publique de Windows 8 sera disponible fin février | Un peu plus tard ...ASUS et Nvidia annoncent une tablette Tegra 3 à 249$ ! | |





















