Intel IDC • Faire du machine learning sur Ice Lake, c'est comment ? |
————— 26 Juin 2019 à 18h51 —— 12692 vues



Intel IDC • Faire du machine learning sur Ice Lake, c'est comment ? |
————— 26 Juin 2019 à 18h51 —— 12692 vues
Promis, c'est la dernière news Intel de la journée ! Si la canicule vous à donné envie de vous jeter dans un Ice Lake avec votre Coffee (Lake) de début de soirée, voici un peu de lecture semi-scientifique pour laisser s'écouler les dernières chaudes heures du jour.
Vous l'avez sûrement remarqué, le machine learning (ML), c'est-à-dire les algorithmes se basant sur des méthodes statistiques pour reproduire des comportements inférés depuis des données fournies lors d'une phase d'apprentissage, est une des dynamiques majeures de la rechercher en informatique ces cinq dernières années. Il était donc impensable de voir Intel passer à côté du virage, surtout sur une architecture flambante neuve. Nous connaissions déjà l'intégration des extensions VNNI, qui fonctionne en surcouche de l'AVX (version 512 tant qu'à faire) afin d'optimiser le débit des opérations de multiplications avec accumulation en int8/16 chères aux réseaux neuronaux, utiles dans le cadre d'applications utilisant occasionnellement le ML. Également, nous nous doutions que le TFLOP de la partie graphique Gen11 serait configurable pour accélérer ces tâches lors de besoins plus poussés. En revanche, nous étions passés à côté d'un morceau de silicium, placé sur le plan logique en dehors des coeurs à la manière du L3. Il intégrait un mystérieux accélérateur ultra basse consommation répondant au nom de GNA, qui est utilisé pour les tâches duratives du traitement de signal accéléré par IA comme la réduction de bruit ambiant lors d’appels skype ou le floutage de l'arrière-plan afin de soulager le CPU et augmenter drastiquement l'autonomie. En outre, Intel assure avoir travaillé pour une compatibilité sur une intégration OpenVINO, MicrosoftML et AppleML afin de rendre l'utilisation du circuit transparente aux yeux de l'utilisateur et simplifiée pour le programmeur.

De manière étrange au premier abord, les frameworks de recherche tels Tensorflow, Pytorch ou Caffee ne figurent pas parmi les piles logicielles spécialement optimisées pour Ice Lake. Cela s'explique en fait assez simplement : ces frameworks sont en effet utilisés pour construire et entraîner des modèles, ce qui nécessite habituellement une configuration plus musclée que les futurs SoC Ice Lake de 28W.
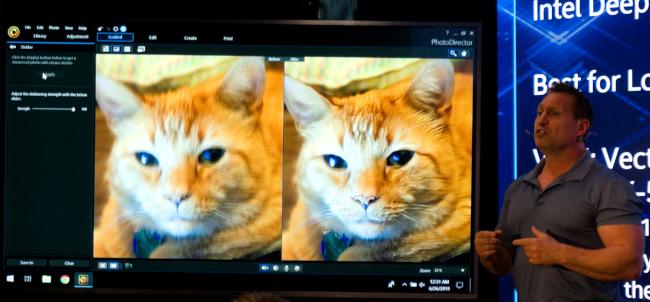
Faire du ML sur Ice Lake, c'est musclant !
Nous avons en outre profité de la rencontre avec des concepteurs d'Ice Lake pour nous pencher sur un sujet en vogue dans le monde du gaming : le DLSS. De son nom académique Image Super Resolution, le principe consiste à faire tourner un algorithme d'apprentissage automatisé sur une image de basse qualité afin de rajouter des détails et donner l'illusion d'une haute définition à l’œil humain. C'est sur cette tâche que se basait la démonstration photographiée ci-dessus, sur un chat - sic - sans surprise considérablement plus rapide (comptez un facteur 2 à 3) sur Ice Lake que Whiskey Lake. Conceptuellement, la partie graphique d'Ice Lake est en mesure d'effectuer un tel travail en temps réel, modulo la qualité d'image de sortie et la complexité du modèle ; cependant cela ne semblait clairement pas être un axe de recherche majeur de l'équipe ML de la firme : autant dire qu'un antialiasing neuroné apparaît comme très peu probable pour Xe - la future architecture de cartes graphiques dédiées d'Intel. Attendons néamoins 2020 avant de juger !
| Un poil avant ?Gros test GPU pour la surprise du chef The Sinking City | Un peu plus tard ...Soldes • Vengeance RGB 2x8Go 3000 MHz CL15 à 89,90 € | |





















