Le consortium CXL gagne la bataille de l'interconnect et annonce le CXL 3.0 ! |
————— 03 Août 2022 à 10h10 —— 23113 vues



Le consortium CXL gagne la bataille de l'interconnect et annonce le CXL 3.0 ! |
————— 03 Août 2022 à 10h10 —— 23113 vues
Un peu moins de deux ans après la version 2.0, voici qu'a déjà été officialisée la version 3.0 du standard CXL ! Bien qu'encore très récent, le CXL a su s'imposer très rapidement sur le marché des serveurs, sans aucun doute grâce à sa richesse en matière d'I/O adossé aux standards PCIe existants et naturellement grâce à une roadmap très largement supportée par l'industrie, le consortium étant constitué de la grande majorité des acteurs majeurs dans ce domaine. Par ailleurs, il a déjà effectivement poussé vers la sortie les standards rivaux Gen-Z, CCIX et depuis avant-hier, OpenCAPI !
En tant qu'interconnect standard et plus fonctionnel, le CXL a été conçu pour améliorer la communication entre CPU et accélérateurs, ainsi que pour permettre le branchement de DRAM et de mémoire non volatile sur une interface PCIe. Pour l'anecdote, le CXL a essentiellement remporté la bataille de l'interconnect depuis que l'OpenCAPI a jeté l'éponge et a opté pour rejoindre le consortium CXL. Mais il y a encore beaucoup de travail à faire, d'autant plus maintenant qu'il n'a plus de rivaux et qu'il faut donc également adresser les cas d'usage spécifiques pour lesquels ces derniers étaient conçus. En sus, les CPU x86 avec CXL sont encore largement inexistants, tandis que les constructeurs demandent également plus de bande passante et de fonctionnalités.
![]()
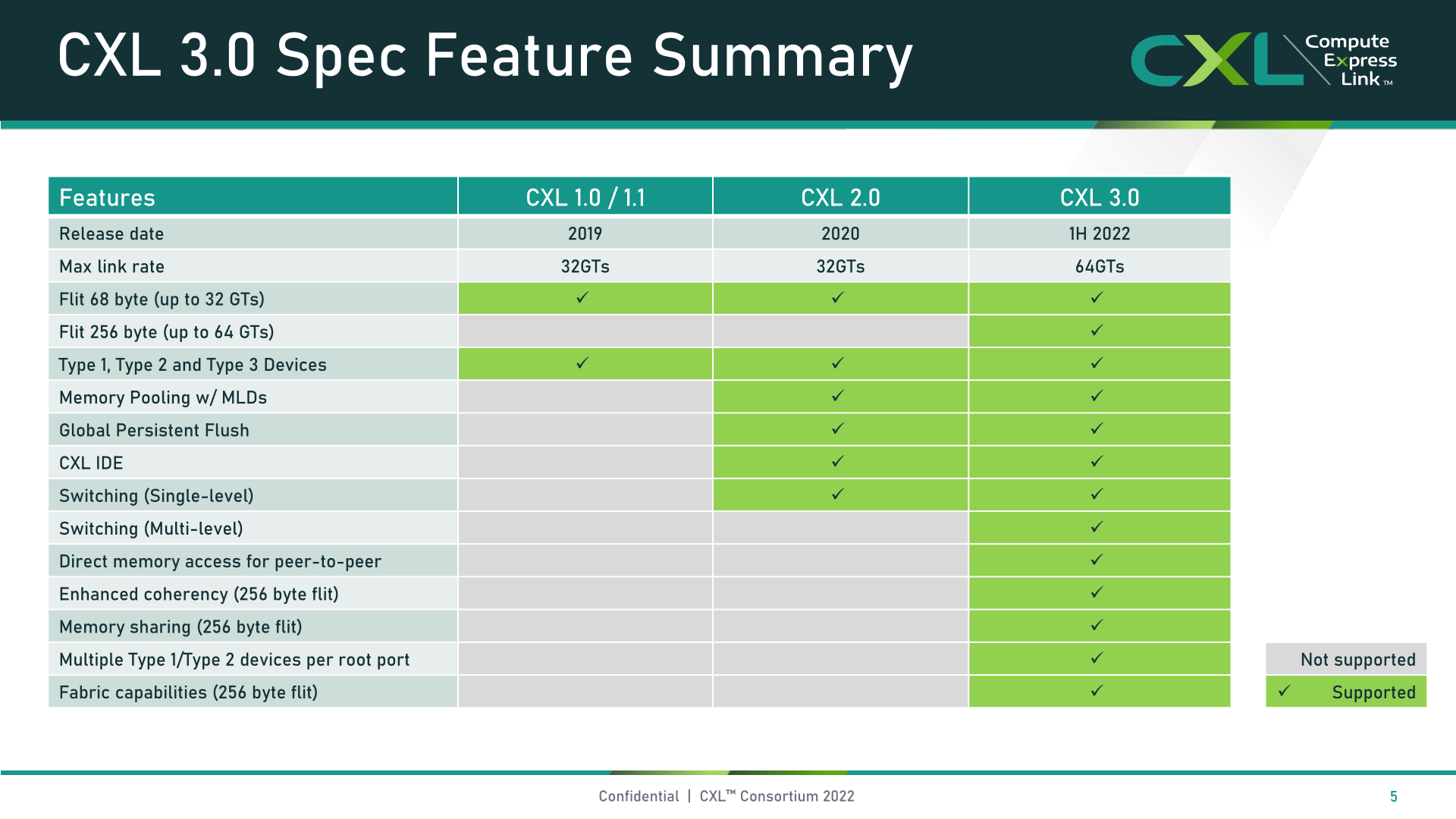
Qu'à cela ne tienne, le consortium CXL a profité du Flash Memory Summit 2022 pour annoncer la version 3.0 complète du standard CXL ! Celle-ci apporte plusieurs améliorations majeures. Tout d'abord, fini le PCIe 5.0 du CXL 1.x et 2.0, et place au PCIe 6.0 ! De ce fait, le CXL 3.0 double le débit par ligne à 64 GT/s et ce sans aucune augmentation de la latence selon le consortium ! Voici pour la partie physique. Ensuite, le CXL 3.0 améliore aussi grandement les capacités logiques du standard, autorisant des topologies et des fabrics de connexion plus complexes, ainsi que des modes de partage de mémoire et d'accès à la mémoire plus flexibles au sein d'un même ensemble d'appareils CXL. Pour compléter l'aperçu du CXL 3.0, vous retrouverez ci-dessous le résumé des nouveautés du CXL 3.0 et comment celui-ci se compare par rapport aux versions précédentes, ainsi qu'une brève vidéo explicative officielle.
Le consortium n'a pas donné de calendrier pour l'arrivée des premiers appareils CXL 3.0. De toute évidence, il ne faudra pas trop être pressé. À vrai dire, le CXL 1.1 est à peine arrivé sur le terrain et le CXL 2.0 n'y est même pas encore, mais c'est une lenteur qui n'a rien d'anormal dans ce domaine, particulièrement pour un projet aussi ambitieux que le Compute Express Link. En somme, cela dépendra avant tout des constructeurs et ça prendra certainement encore plusieurs années. (Source : CXL, Anandtech)
![cxl 3.0 [cliquer pour agrandir]](/images/stories/_hardw-autre/cxl-3-0-evolutions-presentation_t.png "Enlarge your pe...icture")
![cxl 3.0 [cliquer pour agrandir]](/images/stories/_hardw-autre/cxl-3-0-presentation-resume_t.png "3N C11QU4N7 C357 P1U5 6r4ND")
| Un poil avant ?L'ombre d'un hypothétique SSD 990 PRO se profile chez Samsung | Un peu plus tard ...AMD Ryzen 7000 : ce sera bien en septembre | |