Intel Architecture Day 2021 • Alder Lake, une architecture doublement nouvelle |
————— 20 Août 2021 à 09h30 —— 25919 vues



Intel Architecture Day 2021 • Alder Lake, une architecture doublement nouvelle |
————— 20 Août 2021 à 09h30 —— 25919 vues
Tout comme à la fin de l’année 2018 en présentiel et en 2020 en format vidéo, voilà que les bleus réitèrent leur événement destiné à envoyer la poudre aux yeux des consommateurs : l’Intel Architecture Day. Entre l’arrivée de Xe sur le segment grand public (HPG) et professionnel (HPC), Alder Lake/Sapphire Rapids pour ce qui est des processeurs et quelques rajouts spécialement conçus par la firme, le fondeur de Santa Clara a pu concocter un pot-pourri qui ne manque pas de densité et qui, pour le coup, devrait préfigurer la gamme dans un futur proche.
![]()
Commençons avec le cœur de métier de la maison : les processeurs. Avec Alder Lake, Intel poursuit la voie entamée avec Lakefield et proposera un CPU hétérogène, c’est-à-dire dont les cœurs intégrés au sein du processeur ne partagent pas tous le même design, ici soit l’Efficient Core, soit le Performance Core. Or, qui dit deux design dit deux microarchitectures différentes, et, sur ce coup, Intel a su mettre les bouchées doubles pour sortir, d’un côté, le successeur de Tremont, Gracemont ; et, de l’autre, Golden Cove descendant de Willow Cove. Désormais, ces deux familles « Mont » et « Cove », dont Intel préfère désormais les patronymes d’Efficient et Performance Core (ou E-core et P-core), évolueront ainsi en parallèle, tout du moins tant que le design hétérogène reste au goût du jour.
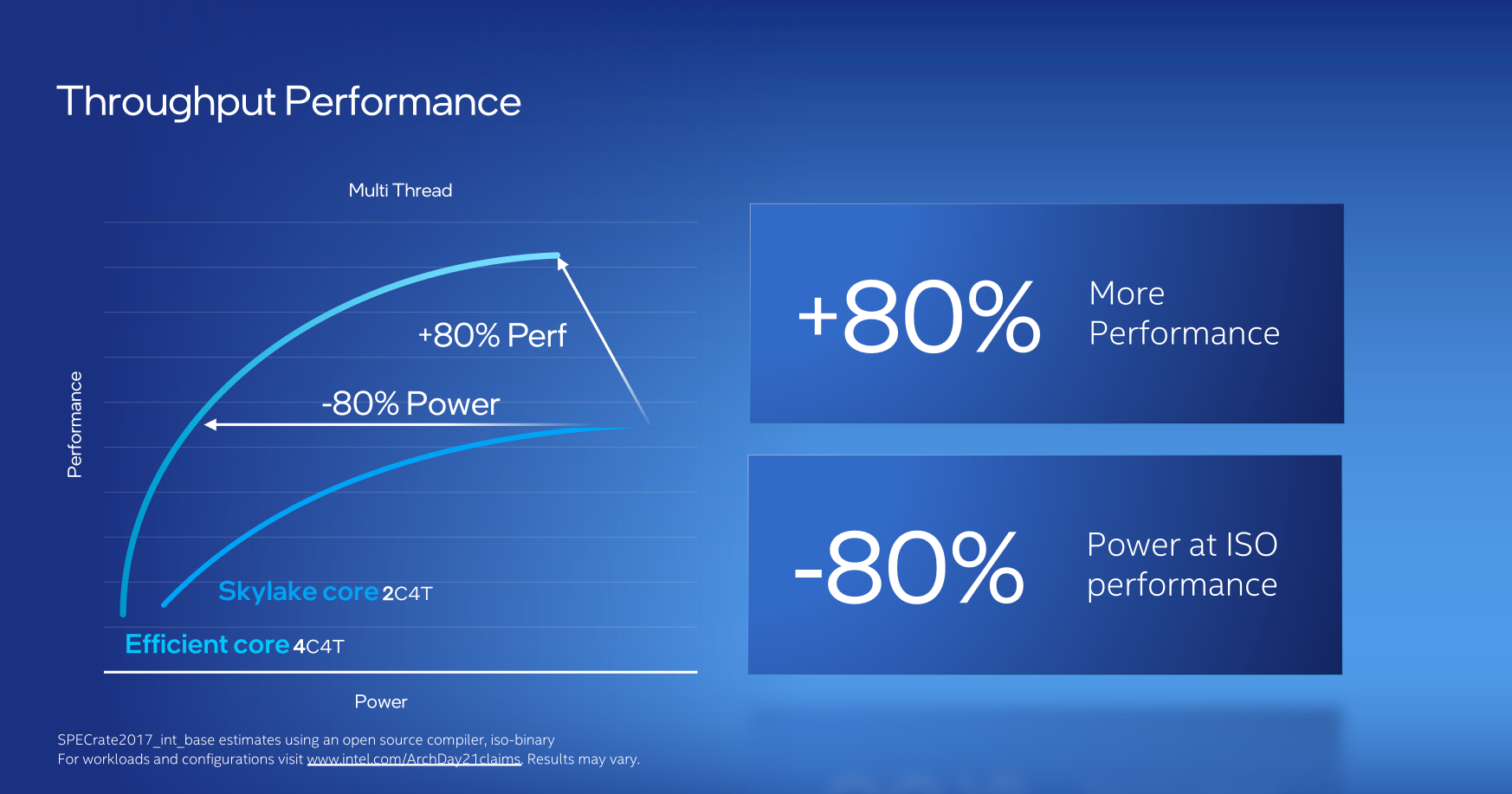
Lorsque l’annonce d’un design hétérogène a été officielle, nombreuses ont été les interrogations. En effet, proposer une configuration à 16 cœurs est alléchant sur papier, mais s’il s’agit de 8 faibles cœurs et 8 cœurs corrects, le résultat n’est pas forcément fameux (l’expérience Xeon Phi l’a très bien démontré : mettre 50 Atom ensemble ne fait pas un foudre de guerre). Cependant, Alder Lake ne devrait pas réitérer les mêmes erreurs, car Intel s’est montré plus que rassurant sur les performances des bouzins : grâce aux optimisations opérées, les cœurs se montreront plus efficients que Skylake, avec soit un gain estimé par Intel jusqu'à 40 % de performances pour la même consommation, soit une réduction de 40 % de l’énergie nécessaire, à performance égale. Une fois rassemblé en cluster, le résultat est encore plus éloquent : 4 cœurs efficients proposeraient 80 % de consommation en moins ou 80 % de performances en plus par rapport à un dual core/quad thread Skylake, l’hyperthreading n’étant par contre pas de partie sur cette microarchitecture là. Attention néanmoins à garder une certaine distance dans la lecture de ces chiffres, Intel ne précise ici ni la version de Skylake utilisée (les diverses moutures du 14 nm ayant des différences notables sur la consommation), et se contente de résultats basés sur SPEC en version int : il y a fort à parier que la FP soit davantage dans les choux.
![Un coeur efficient bien efficient tout seul [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/gracemont-latency-perf_t.png "Cliquédélique !")
![Un coeur efficient bien efficient, même à plusieurs [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/gracemont-throughput-perf_t.png "3N C11QU4N7 C357 P1U5 6r4ND")
![Un petit tour d'horizon des nouveautés du coeur efficace [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/efficient-core-recap_t.jpg "3N C11QU4N7 C357 P1U5 6r4ND")
En interne, les progrès sont nombreux : le front-end change relativement peu si ce n’est le cache des instructions, qui grandit pour passer à 64 kio, et le prédicteur de branchements qui prend également de l’embonpoint, sans plus de précision. Pour le reste, le double décodeur est toujours capable de fournir un maximum de 6 instructions par cycle, encore heureux d’ailleurs !
![Un étage de décodage qui envoie du pâté ! [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/efficient-core-front-end_t.jpg "Cliquédélique !")
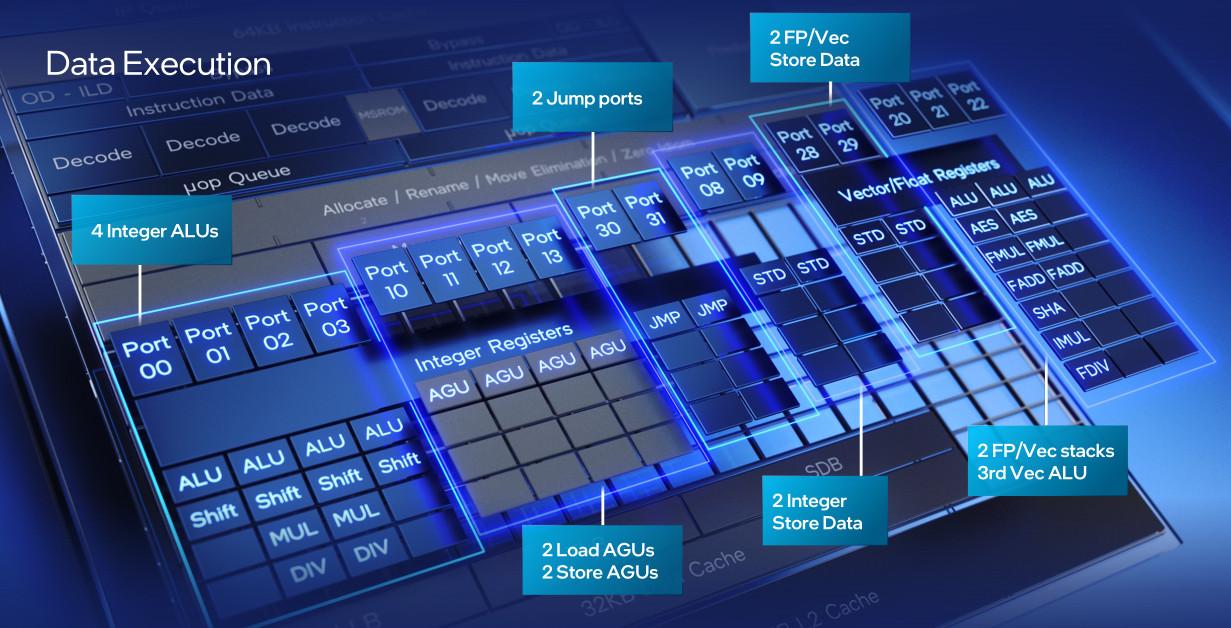
Par contre, le back-end, lui, est radicalement chamboulé : passage à une fenêtre de réordonnancement de 256 entrées, une allocation gérant 5 micro-instructions en parallèle et la terminaison de 8 micro-instructions, mais, surtout, pas moins de 17 ports de traitement, contre 8 précédemment.
![Pour être large, il est bien large ce back-end ! [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/efficient-core-back-end_t.jpg "Même pas cap' de cliquer")
Le sous-système mémoire n’est pas en reste avec 4 Mio de L2 maximum supporté pour un débit de 64 octets par cycle et une latence de 17 cycles, le tout supportant un maximum de 64 requêtes en attente. Enfin, pour ce qui est des extensions supportées, pas de panique : l’AVX2 est bien présent (comprenant les VNNI et les FMA), tout comme l’Intel CET récemment introduit.
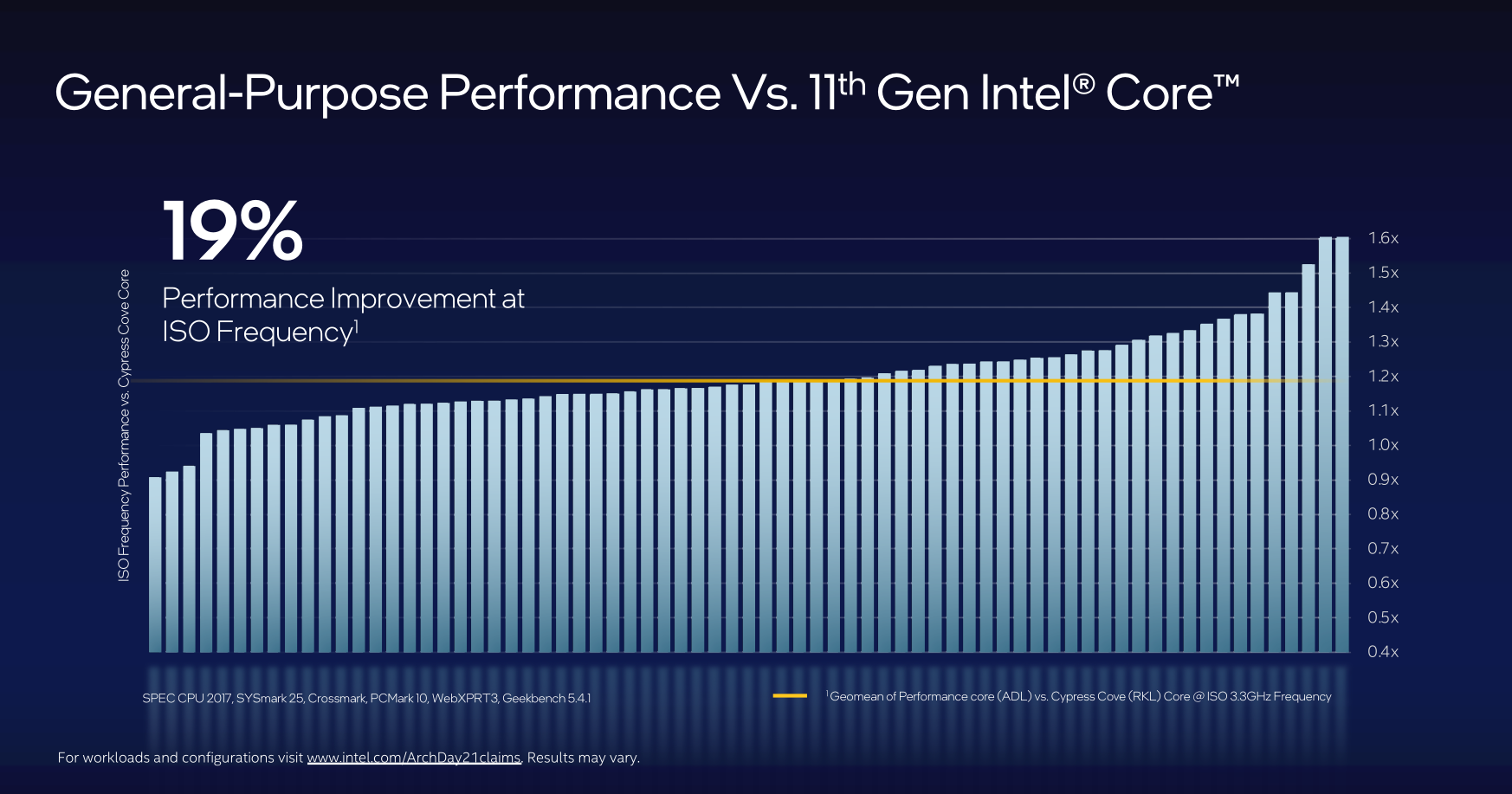
Pour ce qui est de poutrer, le cœur Performance devrait bien répondre « présent ». Boostés aux hormones avec, principalement, deux ports de calculs supplémentaires et le support de l’extension Intel AMX, les gros cœurs sont donnés pour supplanter Rocket Lake et son Cypress Cove de 19 % en moyenne à isofréquence, soit l’écart déjà réalisé entre Skylake et Ice Lake. Si les fréquences suivent, les gains en situation réelle devraient être conséquents.
![Un coeurs Performance qui envoie du lourd ! [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/performance-core-gains_t.png "La magie de la loupe, sans loupe")
Un graphique qui sent le déjà-vu !
Une fois encore, ces chiffres ne sortent pas du chapeau : le design a été passé en revu ici et là afin de grossir toujours plus les bus et fournir toujours davantage de puissance brute exploitable.
![performance core recap t [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/performance-core-recap_t.jpg "Visionner en grand sur un magnifique pop-up")
Le front-end est bien testicouillu avec des augmentations au niveau de l’iTLB, qui passe à 256 entrées pour les pages de 4 kio, et 32 entrées pour des hugepages, mais aussi du chamboulement sur le muop cache qui double quasiment en passant à 4 kilo-entrées, et qui alimente désormais une queue de 72 muops et non plus 70. Pour finir, les décodeurs évoluent (enfin !), sont au nombre de 8 et déroulent le code par tranches de 32 octets, fournissant ainsi 8 muops maximum par cycles.
![performance core recap t [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/performance-core-front-end_t.jpg "Cliquédélique !")
Côté back-end, les changements sont du même ordre : rajout d’un port de chargement des donnés et un port généraliste d’ALU ; le tout nourri par un ROB à 512 entrées et un scheduleur gérant 6 muops à la fois. De plus, les ports 0 et 1 prennent une unité supplémentaire, le Fast Add, permettant de réaliser des additions flottantes en 1 cycles.
![performance core recap t [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/performance-core-back-end_t.jpg "Si vous cliquez, vous cliquez.")
La mémoire progresse en parallèle avec 1,25 Mio de L2 pour les processeurs grand public et 2 Mio pour les pro, et le sous-système gère maintenant 48 requêtes en attentes maximums afin de gloutonner les 3 chargements 256-bit désormais possibles, ou 2 chargements 512-bits.
Du côté des extensions supportées, l’AVX-512 est au rendez-vous pour les opérations vectorielles, et l’AMX pour les opérations matricielles (offrant, par exemple, un débit 8 fois supérieur à une implémentation VNNI-256 équivalente lors d’une utilisation sur des entiers 8-bit) ainsi que le cocktail déjà présent sur les E-cores.
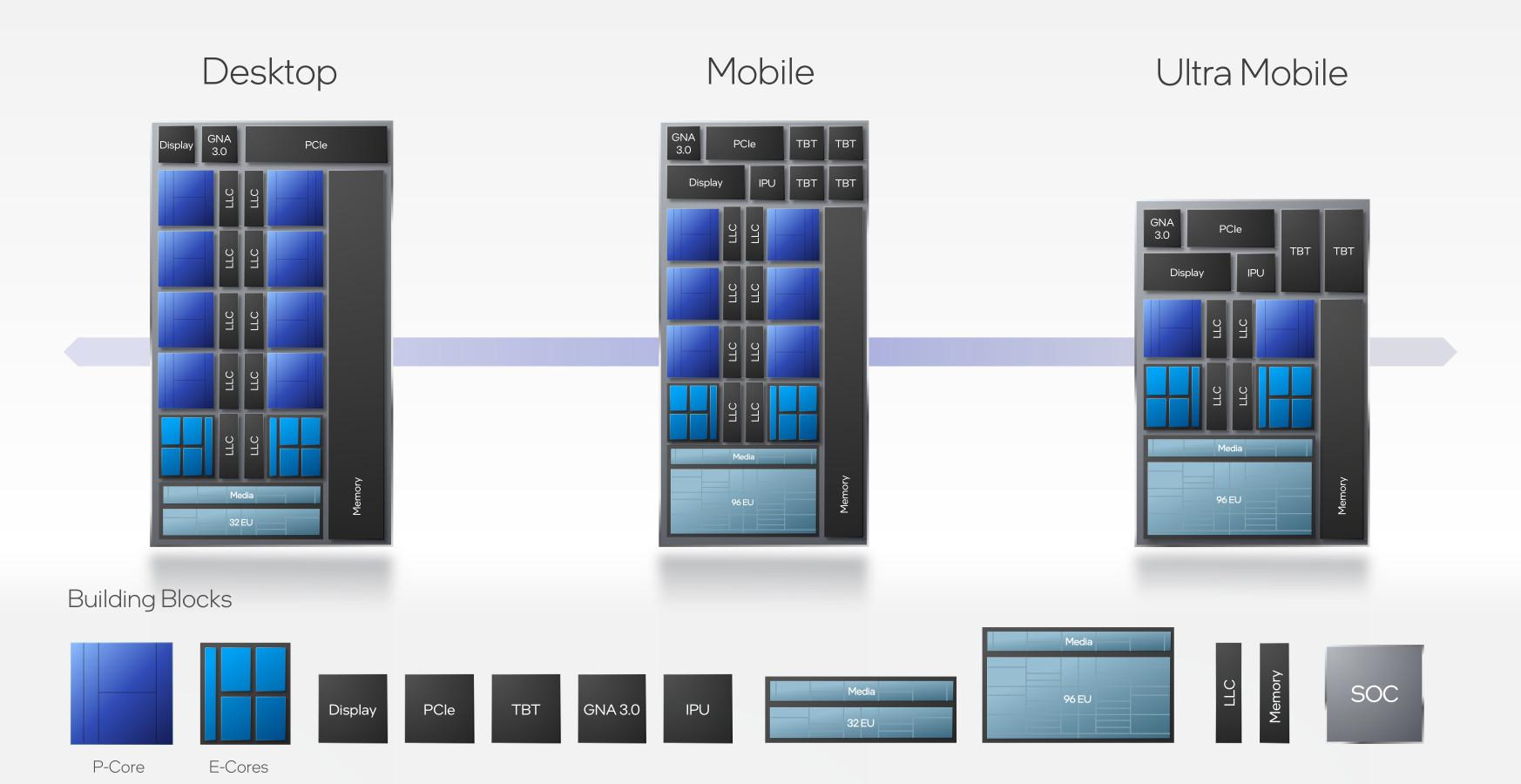
Intel l’ayant crié sur tous les toits auparavant, la surprise n’est pas bien grande... mais tout de même : Alder Lake sera la réunion de ces E-cores et P-cores sous un même die, et ce, selon trois saveurs différentes. En effet, la gamme — s’étendant, au passage, des TDP de 9 W à 125 W — sera composée de 3 dies : un pour les ordinateurs de bureau, l’autre pour les PC portables et le troisième pour les ultraportables.
![Différent facteurs de forme pour Alder Lake... [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/alder-lake-form-factor_t.jpg "Visionner en grand sur un magnifique pop-up")
Qui dit différents facteurs de forme dit différentes configurations, dont voici les spécifications maximales :
| kiki ? |
Coeurs (Efficient + performance) | Threads | Cache L3 | iGPU | Support mémoires |
|---|---|---|---|---|---|
| Le gros | 8+8 | 24 | 30 Mio | 32 EU Xe |
DDR5-4800 DDR4-3200 LPDDR5-5200 LPDDR4x-4266 |
| Le moyen | 8+6 | 20 | 24 Mio | 96 EU Xe | |
| Le petit | 8+2 | 12 | 12 Mio | 96 EU Xe |
Outre la grande nouveauté de la DDR5, le PCIe 5.0 est également présent, doublant la bande passante offerte... pour le GPU. Les quatre lignes supplémentaires offertes par le CPU, usuellement utilisées pour des SSD NMVe, demeurent en 4.0, tandit que la liaison avec le chipset est, quant à elle, inconnue. Pour ce qui est des fréquences, par contre, il va encore falloir attendre la sortie officielle des produits pour savoir de quoi il en retourne... patience !
![... pour différents die d'Alder Lake [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/alder-lake-dies_t.jpg "La magie de la loupe, sans loupe")
Détail de taille : sur Alder Lake, n’espérez pas voir ni AVX-512, ni AMX, réservé aux CPU pour datacenters. En effet, par souci d’intercompatibilité des jeux d’instructions, Intel va désactiver de manière permanente cette extension sur les CPU grand public, afin que les threads puissent être librement assignés à un P-core ou un E-core sans vérification de l’ISA. De ce fait, le VNNI, initialement lancé sur 512 bits, est ici présent dans une version 256-bit.
Petite surprise de la part des bleus, Alder Lake embarquera une aide hardware au scheduler : l’Intel Thread Director, un composant chargé de la migration des processus sur les threads disponibles. L’idée est simple : donner la priorité aux applications en cours d’exécution les plus gourmandes, là où les processus en attente où les daemons réalisant des tâches légères seront associés à des cœurs efficients. Pour autant, cette unité n’est pas capable de migrer les processus en tant que tels : cette décision demeure du ressort de l’OS... et heureusement, vu le travail que cela requiert !
![Tout dans le hard', et hop ! [cliquer pour agrandir]](/images/stories/articles/cpu/intel-architecture-day-2021/intel-thread-director_t.png "Cliquédélique !")
Pour cela, l’Intel Thread Director permet de compléter les informations possédées par le scheduler, en lui ajoutant une métrique sur le niveau de performance requis pour chaque processus basée sur une télémétrie matérielle (mesure de l’utilisation des différentes unité de calcul/extensions vectorielles), guidant ainsi la décision d’affectation d’un E-core ou d’un P-core. Notez que, dans le cas où une application serait détectée comme requérant un P-core alors que tous sont déjà pris, le CPU remontera directement au noyau un conseil sur le processus à déplacer afin de laisser une place libre pour le nouveau venu. De plus, un processus préalablement détecté comme gourmand pourra être requalifié par la suite en économe si jamais la nature de son travail venait à changer (et inversement). Une idée plutôt puissante dans la théorie, il faut tout de même espérer que l’algorithme utilisé soit suffisamment intelligent pour sélectionner la bonne application le moment venu.
Comme à chaque présentation architecturale uniquement, il nous est bien difficile de conclure. En effet, l’absence de chiffres de performances en situation réelle et de prix de vente risque de casser tout jugement préliminaire sur le produit. Néanmoins, Alder Lake présente, sur le papier, bien des avantages : en situation standard, la structure hétérogène devrait fournir d’un côté la pêche nécessaire aux applications de premier plan et, de l’autre, les cœurs économes pourront se charger de threads moins gourmands, laissant ainsi les Watts sauvés aux premiers cités. Quant au Thread Director, son principe est inséparable de la notion même d’hétérogénéité, bien que nous redoutons que son usage se limite à Windows 11 et Linux, et soit alors utilisé comme un argument de mise à jour. Rajoutons également que les progrès en matière de consommation ne sont pas tous imputables aux modifications architecturales, mais également à la finesse de gravure utilisée, l’Intel 7, qui permet par ailleurs une baisse de la tension de fonctionnement sur les E-core. Une finesse sur laquelle nous avons peu de recul sur sa capacité à monter dans les tours ; mais, puisqu’il s’agit d’un dérivé du 10 nm (merci le renommage...), nous devrions avoir relativement peu de souci de ce côté-là. À vérifier lors du test du produit fini !
| Un poil avant ?Des Raptors dans un lac, une scène leakée à voir ! | Un peu plus tard ...NVIDIA admet que l'acquisition d'Arm n'est pas encore gagnée... | |