Graphcore introduit Bow, sa nouvelle génération d'IPU au die quasi-3D |
————— 03 Mars 2022 à 13h00 —— 21312 vues



Graphcore introduit Bow, sa nouvelle génération d'IPU au die quasi-3D |
————— 03 Mars 2022 à 13h00 —— 21312 vues
Lorsque vous êtes une start-up (ou une grande entreprise en recherche de nouveaux concepts), alors surfer sur la vague machine learning est on ne peut plus tentant, d’autant plus que la technique a fait ses preuves pour accélérer certaines tâches, notamment en matière de traitement d’image, de son ou encore de vidéo. Or, qui dit ML dit aussi accélérateur spécialisé — un peu comme le minage, en fait —, un secteur dans lequel NVIDIA excelle (il suffit de voir la taille de son département de recherche et les évolutions de ses microarchitectures pour s’en convaincre). Pour autant, le caméléon est loin d’être le seul sur le segment : Intel a également quelques startups dans sa poche - coucou Movidius, hello Loihi et bonjour Habana Labs - AMD tente aussi de séduire, le segment mobile y va de ses tentatives, la Chine n’est pas en reste...
Bref, c’est un peu la foire du slip pour se découper le juteux gâteau. Or, parmi les boites ayant rencontré le succès dans ce domaine se trouve une certaine GraphCore, basée au Royaume-Uni, dont les machines nommées Pod se destinent à une utilisation dans des centres de calculs : pour de l’entraînement en masse, quoi !

Manufacturées par TSMC, leurs puces proposent une approche aux antipodes des GPGPU habituellement utilisés en apprentissage automatisée : la mémoire est totalement décentralisée, chaque tile (groupement de cœurs) contenant 256 Kio de mémoire locale utilisable comme scratchpad (soit 900 Mio au total) tout en streamant depuis une mémoire locale plus grande : ouste les caches et autres protocoles de cohérence. Et ça marche ! Comme par magie, les visages des petits malades s’illuminent performances sont au niveau de la concurrence en marchant sur les plates-bandes de la A100 de chez NVIDIA — en tout cas sur la génération précédente.
Or, il est ici question de Bow — référence à un quartier londonien —, dernière mouture en date des IPU (Intelligence Processing Units), une nouvelle génération de puces qui réplique sur le plan architectural la structure de la version précédente. Un accélérateur est ainsi découpé en 1472 tiles mentionnées ci-dessus, chacune équipée d’une unité Accumulating Matrix Product (AMP) affichant 64 opérations en précision mixte ou 16 opérations en simple précision par cycle. À titre d’information, ce parallélisme massif à un prix : 59,4 milliards de transistors, soit plus qu’un GA100 (54 milliards). Pour maximiser l’occupation de ces unités de calcul, chaque cœur est capable de gérer 6 threads via un mécanisme analogue à l’HyperThreading d’Intel/Simultaneous MultiThreading d’AMD, et l’interconnect est optimisé aux petits oignons pour ne pas perdre bêtement de cycle dans les transferts de données.
De quoi proposer 350 TFLOPS pour le calcul pour les réseaux de neurones (64 opérations/cycle x 1472 cœurs x 1, 85 GHz x 2 opérations par FMA = 348,6 TFLOPS en précision mixte, très exactement), un chiffre complémenté par la bande passante gargantuesque de 65 Tio/s - certes agrégée, mais rendue possible par l’implémentation en SRAM de la mémoire tampon interne. Notez que l’interface entre les accélérateurs et le système hôte est assuré par 16 lignes PCIe 4.0, si jamais vous vous questionniez sur la bande passante proposée.
![Un accélérateur qui fait son Bow ? [cliquer pour agrandir]](/images/stories/_hardw-autre/machine-learning/graphcore-bow-ipu-carac_t.jpg "3N C11QU4N7 C357 P1U5 6r4ND")
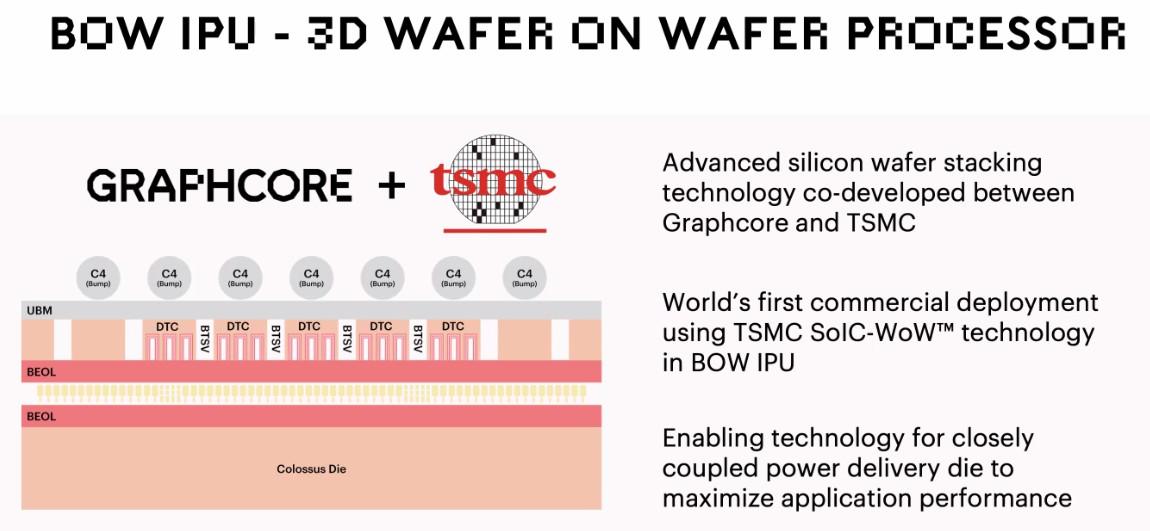
Avec une organisation logique identique, l’adaptation logicielle fut facile : rien (ou presque) n’a dû être modifié, ce qui implique la compatibilité avec les majorités des frameworks à la mode dont TensorFlow, Pytorch et Keras. Mais, dans ce cas, qu’est-ce qui permet les gains mirobolants officiellement de 40 % en performances pour 16 % d’efficacité énergétique supplémentaire ? Hé bien, Graphcore a sorti un coup de génie de son sac : un partenariat avec TSMC, pour offrir en avant-première une technologie novatrice de stacking 3D, le SoIC-WOW. Contrairement au Ryzen 5800X3D et à Milan-X, dans lequel des dies sont adjoints au-dessus des CPU afin d’augmenter la taille de cache, il est ici question d’un placement en dessous de ce dernier en vue d’améliorer l’alimentation en jus d’électron de la puce - aucune logique n’étant gravée sur ce die inférieur.
Pour cela, il a fallu travailler la méthode d’assemblage (cold weld bonding), et designer de nouveaux Back Side-TSV (les canaux traversant le silicium pour, justement, apporter ce jus d’électron), mais le résultat est à la hauteur des attentes : alors que la génération précédente d’IPU utilisait déjà le 7 nm de chez TSMC, cette nouvelle mouture permet d’améliorer la fréquence en passant de 1,1 GHz à 1,85 GHz, le tout en diminuant la tension. Chapeau ! Notez qu’une amélioration similaire, le BS-PDN, est également prévue chez les bleus et devrait arriver avec le nœud 20A : affaire à suivre pour le grand public.
![Un sacré tas d'innovation pour le Machine Learning ! [cliquer pour agrandir]](/images/stories/_hardw-autre/machine-learning/graphcore-bow-wow_t.jpg "Ne pas appuyer ici")
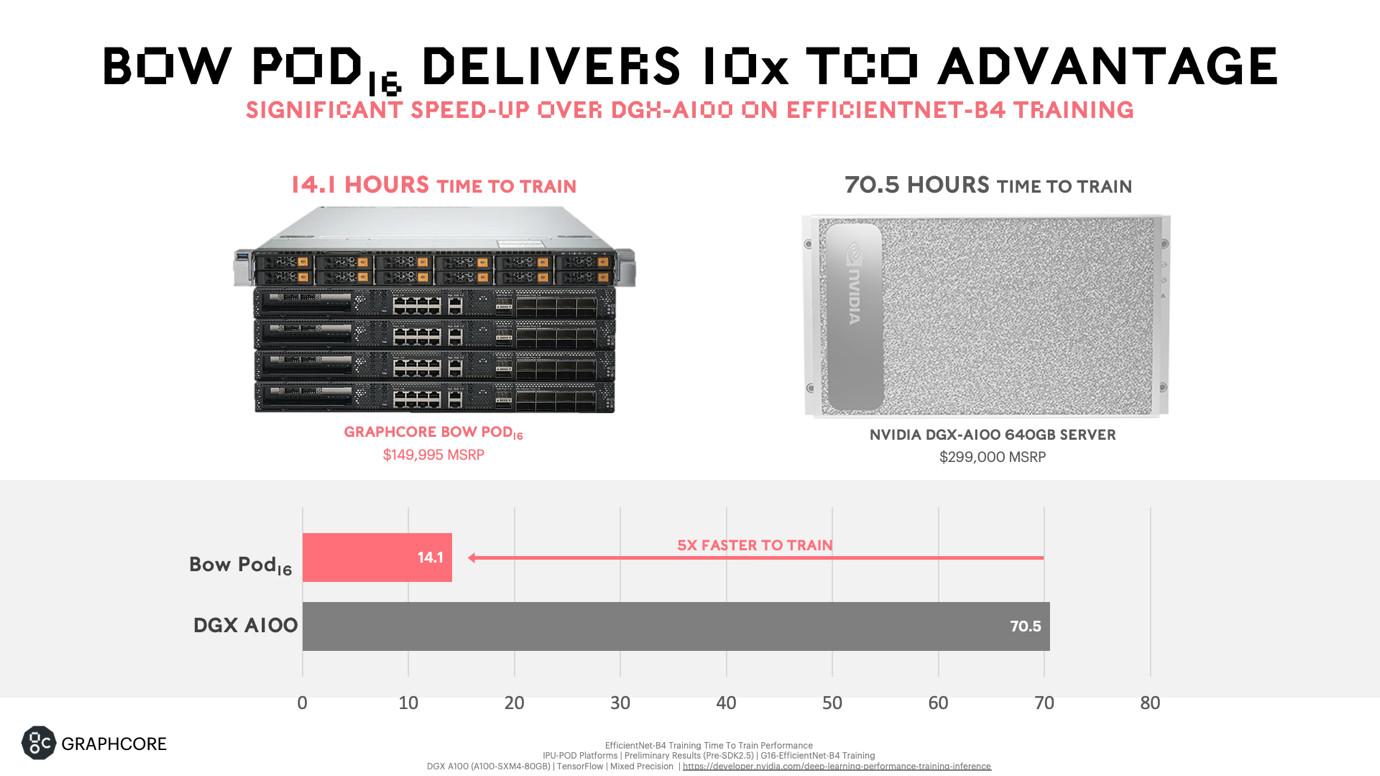
Au niveau du facteur de forme, les bousins sont distribués en plusieurs racks format 1U (refroidissement à air) pour baies serveurs à raccorder avec un système hôte (Lenovo, DELL, SuperMicro, …), intégrant un maximum de 4 IPU par machine : n’espérez donc pas en chopper un pour votre projet personnel, les Pods ne sont pas calibrés pour un usage individuel ! En outre, la firme annonce que cette troisième génération d’IPU viendra remplacer les Pod actuels sans modification de la tarification, tirant ainsi vers le bas le ticket d’entrées en ce qui concerne la génération précédente. Par rapport à NVIDIA, ces nouveaux Pod devraient offrir des performances 5x supérieur à une station DGX carburant aux A100, pour un coût total d’exploitation 10x inférieur. À voir en pratique de quoi il en retourne en fonction des réseaux — l’IPU manquant par exemple d’unités dédiées aux calculs sur des structures creuses, contrairement aux Tensor Cores des RTX Ampere.
![En voilà de belles promesses ! [cliquer pour agrandir]](/images/stories/_hardw-autre/machine-learning/graphcore-bow-vs-nvidia_t.jpg "Si vous cliquez, vous cliquez.")
En outre, si vous n’êtes toujours pas rassasiés d’autant de puissance, GraphCore a dans les cartons sa prochaine machine, nommée Good Computer. Pas encore totalement définie, il est toutefois question d’une puissance totale de 10 ExaFLOPS pour un supercalculateur complet : voilà de quoi accélérer un sacré nombre de nouvelles applications du machine learning... à venir en 2024 !
![Avis aux amateurs ? [cliquer pour agrandir]](/images/stories/_hardw-autre/machine-learning/graphcore-bow-offers_t.jpg "Même pas cap' de cliquer")
| Un poil avant ?La DDR4 marginalisée avec les futures mobales de série 700 chez Intel ? | Un peu plus tard ...ELEX 2 se paye un test GPU | |