Le Turbo Boost : une technique pratique, mais plus contraignante que ce que l'on pourrait espérer |
————— 01 Octobre 2020 à 11h28 —— 29635 vues



Le Turbo Boost : une technique pratique, mais plus contraignante que ce que l'on pourrait espérer |
————— 01 Octobre 2020 à 11h28 —— 29635 vues
Alors que les discussions concernant la course au nombre de cœurs ont engendré des débats fructueux sur notre comptoir, voilà qu’un nouveau sujet dans la même thématique se profile à l’horizon : le DVFS. Le terme, plutôt barbare, n’est pas très usité dans nos contrées francophones, car nous lui préférons le nom d’une de ses appellations commerciales, le Turbo Boost.
Pourtant, ce Dynamic Voltage-Frequency Scaling (ou Échelonnage Dynamique des Fréquences et des Tensions dans notre langue de Molière) est omniprésent dans nos ordinateurs et terminaux mobiles. En effet, bien que ce mécanisme permette de tricher allègrement sur la consommation, ce n’est clairement pas la raison originelle de son invention. L’idée de base était bien plus simple : étant donné que nos appareils alternent entre phases de sollicitation intense — par exemple, lors de calculs d’un document Excel — et phases bien plus calmes — filons l’exemple avec des moments passés à se gratter la tête sur la formule correcte à insérer dans une case —, nos besoins en matière de performances sont fortement hétérogènes. Pour économiser de l’énergie, il suffit par conséquent de calquer la puissance maximale du processeur sur la demande, qui s’effectue assez naturellement en tirant sur la fréquence, et en jouant sur la tension afin de conserver un système stable.
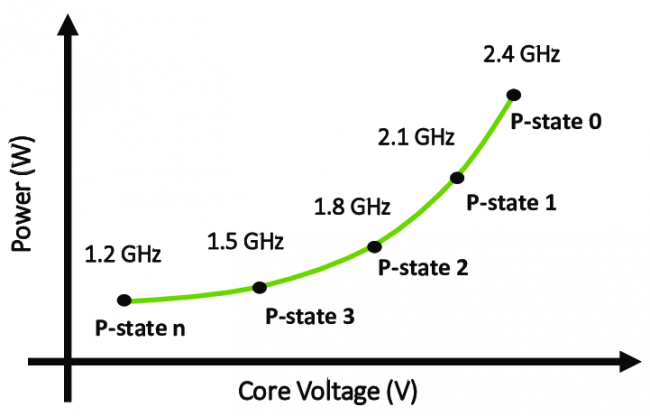
Les P-State : une première implémentation du DVFS par Intel, dans un but d’économie d’énergie. Notez la croissance quadratique de la consommation en fonction de la fréquence, décuplant l’intérêt de variations, même légères, de l’horloge (crédit : ResearchGate).
Enfantin ? Pas tant que ça : dans un premier temps, baisser la fréquence ne réduit pas toute la consommation de la puce, notamment en ce qui concerne les courants de fuite, qui restent inchangés. Inutile donc de chercher à trop ralentir la cadence du circuit : si le temps d’exécution devient trop long, la part de ces courants dans l’énergie totale dépensée devient majoritaire, et l’efficacité aux fraises.
En outre, une tâche n’est pas forcément limitée par le CPU : il est tout à fait possible que le processeur passe en fait son temps à attendre des valeurs de la RAM. Pourtant, cela qui n’empêche pas le scheduleur de demander le boost maximal (tentez par exemple sur une compression de fichiers) et ainsi de gaspiller des Watts à mauvais escient. Cela est d’autant plus risible que la mémoire vive n’est en général pas équipée de mécanismes de DVFS, du fait des rafraîchissements des données effectués à chaque cycle compliquant grandement l’aspect microélectronique du schmilblick.
La question devient d’autant plus épineuse une fois appliquée à un accélérateur, typiquement un GPU ou un NPU (pour les réseaux neuronaux), car une inconnue se rajoute : le nombre de cœurs/unités de calcul... Rajoutez à cela que certains cas d’usage (par exemple les puces d’analyse d’images dédiées à la conduite autonome) ne présentent plus les caractéristiques d’hétérogénéité qui ont donné naissance au DVFS, et vous obtenez le casse-tête classique d’un architecte devant sa feuille blanche et son cahier des charges plein.
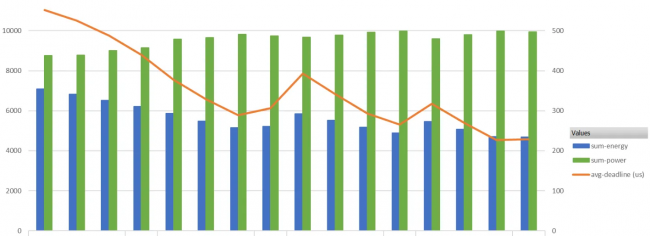
Simulations (fournies par Synopsys) présentant les résultats de différents designs d’accélérateurs de ML. En rouge, la latence maximale, en bleue, l’énergie consommée, et en vert, la puissance : les designs au meilleur rendement énergétique (baton bleu le plus bas) sont les plus rapides (courbe rouge également plus basse), mais aussi les plus gourmands en Watts (bâton vert au plus haut) !
Ainsi, certaines recherches tentent la voie de l’AFS, ou Adaptative Frequency Scaling : plutôt que de chercher à naviguer entre des paliers fixes contrôlés par logiciel, par exemple entre 0,5 V et 0,95 V — une différence énorme en microélectronique, soit dit en passant, et nécessite un surcoût du design — les circuits peuvent disposer de leur propre unité de régulation de tension, permettant d’alimenter différents composants de la puce à grain fin, et pallier les baisses de tensions parfois observées en charge. Notez que cette implémentation est alors transparente aux yeux du programmeur, une bénédiction pour les coûts de développement. Néanmoins, l’étalonnage de ces bousins ne peut pas s’effectuer correctement sans une connaissance précise du domaine d’application de la puce, ce qui rend la praticité de cette technologie quasi nulle sur un CPU. Toujours sur le terrain des accélérateurs, voir des ASIC, une implémentation du DVFS signifie également un support logiciel des changements de palier, et une vérification étendue du bon fonctionnement sémantique de la puce, quelle que soit son mode de fonctionnement.
Certes, la plupart de ces reproches sont loin de nos CPU du bureau, cependant, la diversification des firmes aidant, rien ne dit qu’un accélérateur léger de Machine Learning ne pourrait pas voir le jour dans nos PC portables, ou un quelconque autre morceau de silicium dans nos routeurs. Affaire à surveiller ! (Source : SemiEngineering)
| Un poil avant ?La Chine pourrait-elle refuser le rachat d'ARM par Nvidia ? | Un peu plus tard ...Enermax présente deux nouvelles gammes d'alimentations en bronze | |





















