Quand Intel analyse la concurence : décorticage des tensor cores de NVIDIA |
————— 22 Juillet 2019 à 11h30 —— 16905 vues



Quand Intel analyse la concurence : décorticage des tensor cores de NVIDIA |
————— 22 Juillet 2019 à 11h30 —— 16905 vues
Ah, qu'il est difficile de se faire remarquer quand la domination technologique n'est plus présente ! Après avoir raté le train de l'informatique embarquée, le géant bleu tente avec plus ou moins de réussite de s'immiscer dans le domaine de l'accélération du machine learning, pourtant trusté par NVIDIA.
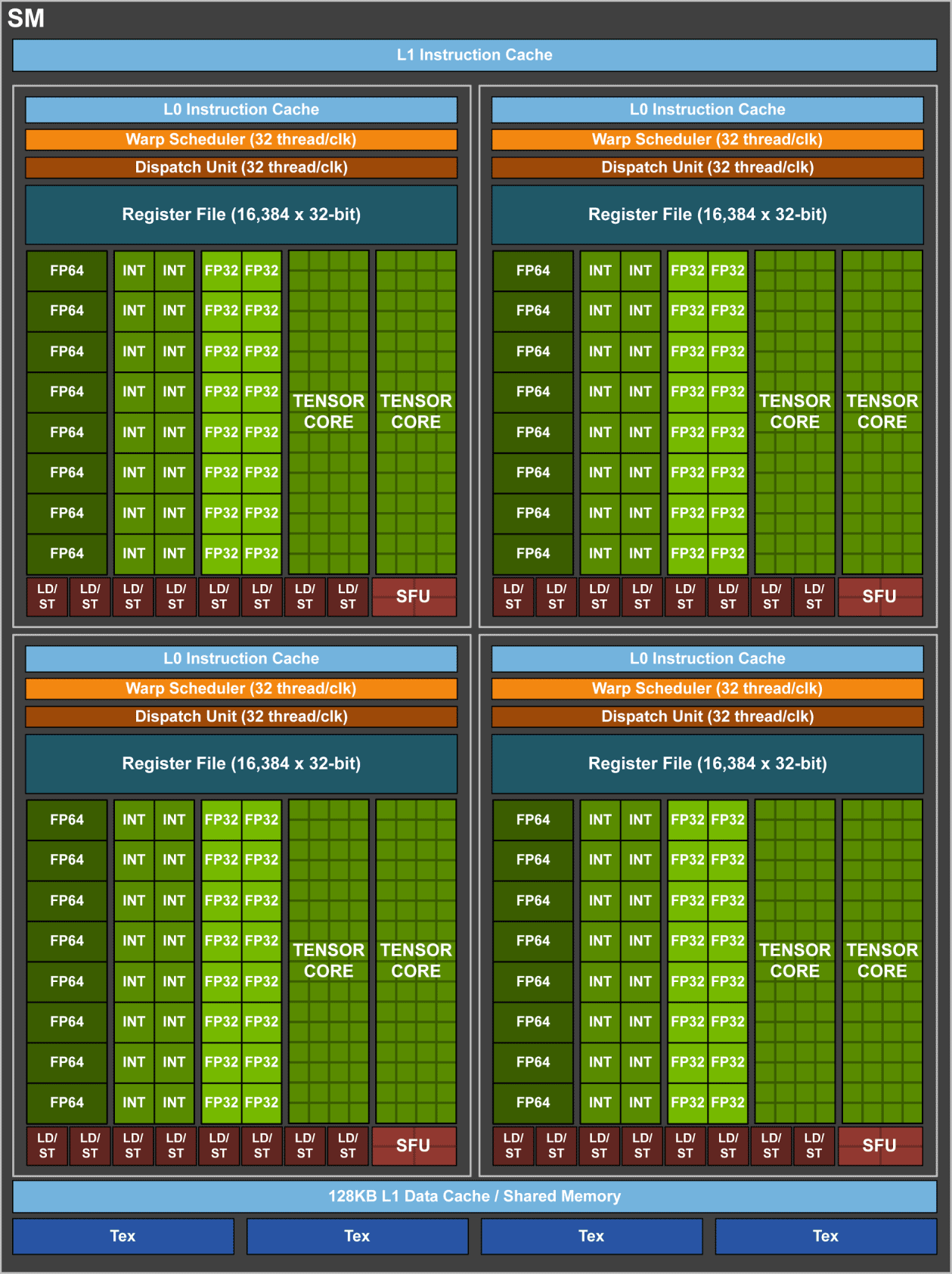
![un SM du GV100 [cliquer pour agrandir]](/images/stories/_cg/volta/volta-gv100-sm_t.png "Si vous cliquez, vous cliquez.")
Petit rappel sur les SM de Volta
Et comme dans ces cas-là, tous les coups - ou presque - sont permis, Intel a mené sa propre enquête interne sur le fonctionnement des Tensor Cores, et a pointé une erreur. Pour rappel, ces unités de calculs sont dédiées au calcul matriciel et réalisent une multiplication avec accumulation, notamment sur les nombres flottants sur 16 bits. Or, la norme IEEE 754 est très stricte sur la gestion des arrondis, ce qui permet d'en déduire la structure interne du bouzin : il ne s'agit ni d'une cascade de multiplieurs-additionneurs ni d'un arbre, mais d'une structure parallèle, coupant au passage le résultat sur 24 bits. Si dans la pratique cela n'offre pas un résultat plus faux que celui offert par un algorithme n'utilisant pas les Tensor Cores, il n'en reste pas moins différent. Du pinaillage, vous dites ? Un peu plus grave, la largeur des données employée ne permet pas de gérer efficacement les flottants 32 bits, dans lesquels un cas limite de la norme nommé nombres sous-normaux n’est pas géré et systématiquement arrondi à zéros.
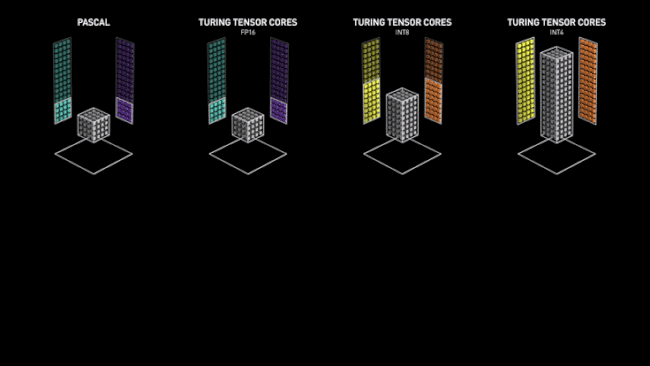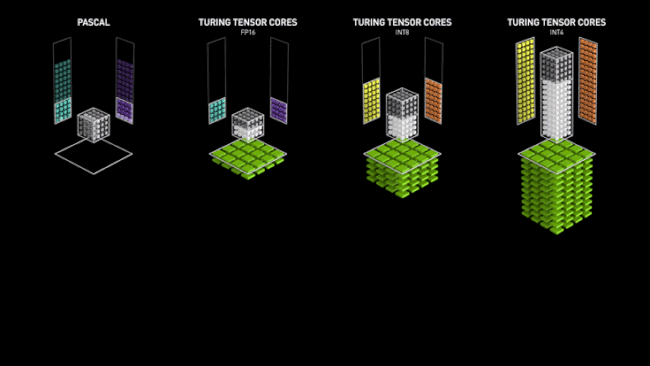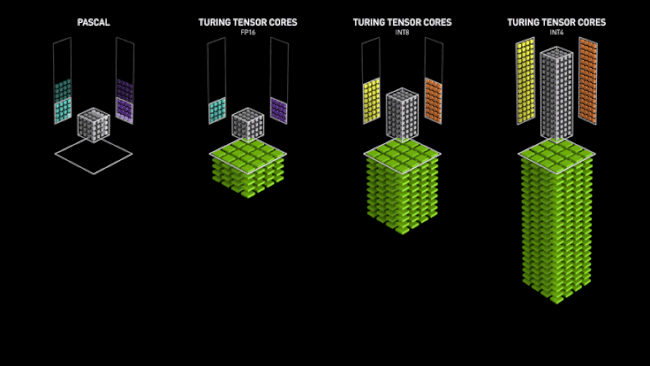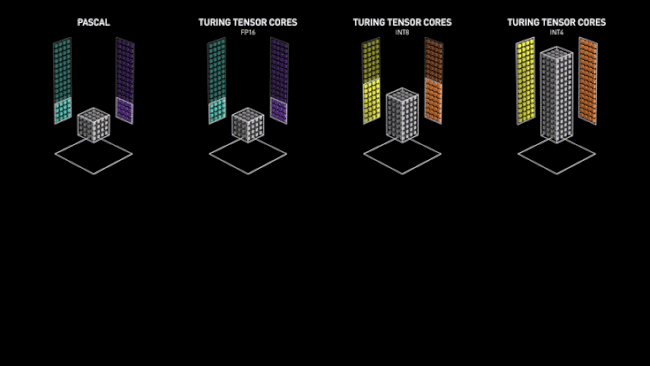
Le fonctionnement des Tensor Cores chez NVIDIA face aux architectures précédentes
Cela est d'autant plus cocasse qu'avec toutes les failles Spectre dont est victime Intel, ce dernier est bien en mauvaise posture pour pointer une mauvaise implémentation dans le but d'économiser du silicium et gagner des performances... mais tel est bien le jeu de la concurrence. À quand le papier sur une faille liée à l'exécution spéculative en provenance de NVIDIA ? (Source : Bits and Chips)
| Un poil avant ?Un projet de puces de machine learning scalables chez Intel | Un peu plus tard ...Les cours de la DRAM remontent... Pourquoi ? | |





















