Une puissance de 1400W pour l'Instinct MI355X |
————— 11 Juin 2025 à 16h19 —— 11463 vues



Une puissance de 1400W pour l'Instinct MI355X |
————— 11 Juin 2025 à 16h19 —— 11463 vues
N’en déplaise aux obséquieux qui les remercient à chaque prompt, ou aux sentimentaux qui y voient leur âme sœur après d’ardentes discussions, les grands modèles de langage — et plus largement les applications IA — n’ont rien d’entités éthérées et hors sol. Le secteur a besoin d’énergie pour alimenter ses accélérateurs GPU tels que les AMD Instinct.

Vous trouverez le tableau en fin d'article © ComputerBase
Lors d’un évènement prévu demain et intitulé Advancing AI, AMD présentera sa MI350X Series, qui comprend deux nouveaux représentants. En amont, ComputerBase a lâché quelques indiscrétions glanées à l’ISC 2025 de Hambourg. Elles concernent les GPU et modules OAM (OCP Accelerator Module) MI350X et MI355X, conçus respectivement pour des puissances maximales de 1000 W et 1500 W, soit 400 de plus que le MI350X, et presque le double du MI300X (750 W).
En dépit de leur appartenance à la série MI300, ces MI350X et MI355X diffèrent des MI300X et MI325X lancés respectivement en 2023 et 2024. En effet, ceux-là utilisent l’architecture CDNA 3 ; les nouveaux venus sont basés sur CDNA 4.

AMD avait déjà esquissé les contours des MI350/355 lors de la présentation des MI325X. Quelques-unes des diapositives partagées à cette occasion, en octobre dernier, sont affichées ci-dessous.
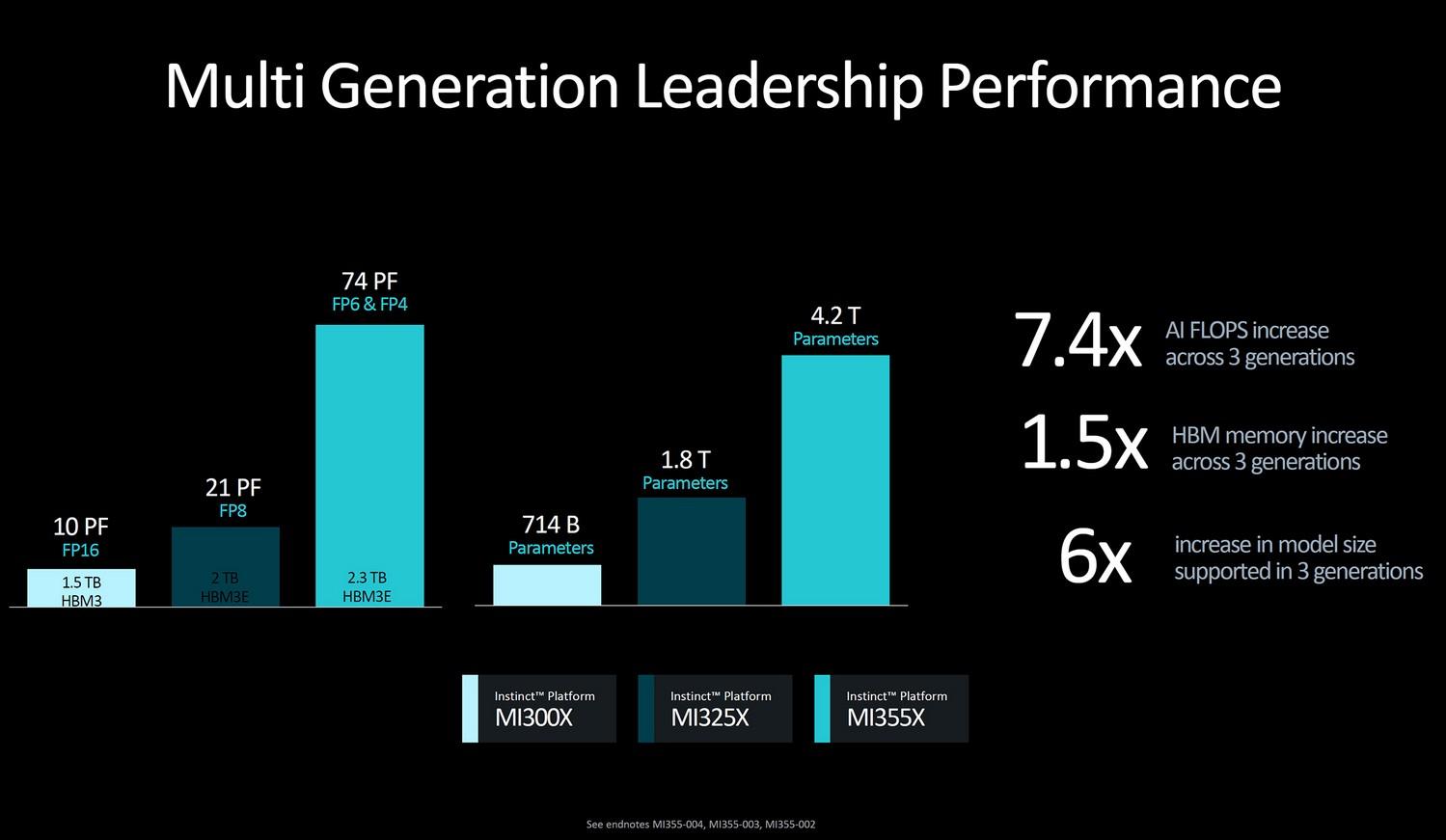


Les puces CDNA 4 s’appuient toujours sur de la HBM3E, avec une bande passante qui tutoie les 8 To/s. La photographie de ComputerBase, qui sert d'illustration, montre la bête ainsi qu’un tableau des caractéristiques. La source propose aussi une photographie plein champ de ce document, que nous avons retranscrit.
| Specifications (Peak Theoretical) | AMD Instinct MI350X GPU | AMD Instinct MI350X Platforme | AMD Instinct MI355X GPU | AMD Instinct MI355X Platforme |
|---|---|---|---|---|
| GPUs | Instinct MI350X OAM | 8x Instinct MI350X OAM | Instinct MI355X OAM | 8x Instinct MI355X OAM |
| GPU Architecture | CDNA 4 | CDNA 4 | CDNA 4 | CDNA 4 |
| Mémoire | 288 Go HBM3E | 2,3 To HBM3E | 288 Go HBM3E | 2,3 To HBM3E |
| Bande passante mémoire | 8 To/s | 8 To/s par OAM | 8 To/s | 8 To/s par OAM |
| Peak Half Precision (FP16) Performance | 4,6 PFLOPS | 36,8 PFLOPS | 5,03 PFLOPS | 40,27 PFLOPS |
| Peak Eight-bit Precision (FP8) Performance | 9,228 PFLOPS | 72 PFLOPS | 10,15 PFLOPS | 81,2 PFLOPS |
| Peak Six-bit Precision (FP6) Performance | 18,45 PFLOPS | 147,6 PFLOPS | 20,1 PFLOPS | 161 PFLOPS |
| Peak Four-bit Precision (FP4) Performance | 18,45 PFLOPS | 147,6 PFLOPS | 20.1 PFLOPS | 161,08 PFLOPS |
| Refroidissement | Air | Air | DLC / Air | DLC / Air |
| Typical Board Power (TBP) | 1000W Peak par OAM | 1000W Peak par OAM | 1400W Peak par OAM | 1400W Peak par OAM |
| Un poil avant ?RTX 5050 : la mémoire hésite entre GDDR6 et GDDR7 | Un peu plus tard ...3,5 millions en 4 jours : la Switch 2 fait mieux que toutes les autres | |
























Plus sérieusement je suis d'accord avec toi qu'on doit pouvoir faire plus avec de bon vieux int. il y a quelques papiers sur l'utilisation de LLM basés sur des int, limitant au max les multiplications (autre que par 1 ou 0), le tout afin de diminuer la consommation électrique tout en limitant les contraintes mémoires aussi. C'est surtout pour du edge aujourd'hui mais c'est assez prometteur.
Ca ajouté au doux reve d'avoir des algos deterministiques car avec la température et la seed on en est loin aujourd'hui !