Test • AMD Ryzen Threadripper 2950X / 2990WX |
————— 13 Août 2018



Test • AMD Ryzen Threadripper 2950X / 2990WX |
————— 13 Août 2018
Ces nouveaux CPU Ryzen Threadripper reprennent bien évidemment l'architecture Zen+, une optimisation de Zen original. Nous ne détaillerons donc pas à nouveau cette dernière, pour ceux intéressés, vous pouvez vous référer à ce dossier. Quelques petits rappel sur la stratégie d'AMD pour les Ryzen sont toutefois utiles. AMD s'appuie sur la création d'un nombre très réduit de die pour attaquer la totalité du marché. A l'origine, le premier conçu et fabriqué en 14 nm se nomme Zeppelin, constitué de 8 cœurs, répartis équitablement au sein de 2 modules qu'AMD nomme CPU Complex ou CCX. Au printemps, les rouges ont fait évoluer la fabrication de ce dernier en basculant vers le NODE 12 nm de Global Foundries, permettant des performances accrues pour les transistors, mais une taille identique de ces derniers, tout du moins dans l'itération retenue par AMD.
![Les gains du 12 nm [cliquer pour agrandir]](/images/stories/articles/cpu/threadripper/threadripper2/12nm_t.jpg "Enlarge your pe...icture")
Les gains apportés par le 12 nm selon AMD
Voilà pour l'état des lieux. Afin de segmenter sa gamme, AMD a pu désactiver plus ou moins de cœurs ou cache L3 afin de positionner chaque processeur au sein de celle-ci. Par contre, comment diable proposer quelque chose de plus performant qu'un die Zeppelin complet et à ses fréquences maximales ? La solution la plus élégante serait de concevoir un nouveau die comprenant non pas 2 CCX mais 4 par exemple. Problème, les masques pour graver une telle puce coûtent une fortune, tout comme la production en elle-même (moins de dies par Wafer), ce qui ne correspond pas à l'approche stratégique retenue par la société, qui a opté pour une solution plus simple : "réunir" plusieurs dies au sein d'un même packaging afin d'obtenir un CPU plus large ! AMD ajoute que les 5 meilleurs pourcents des die produits, sont destinés à devenir des Threadripper.
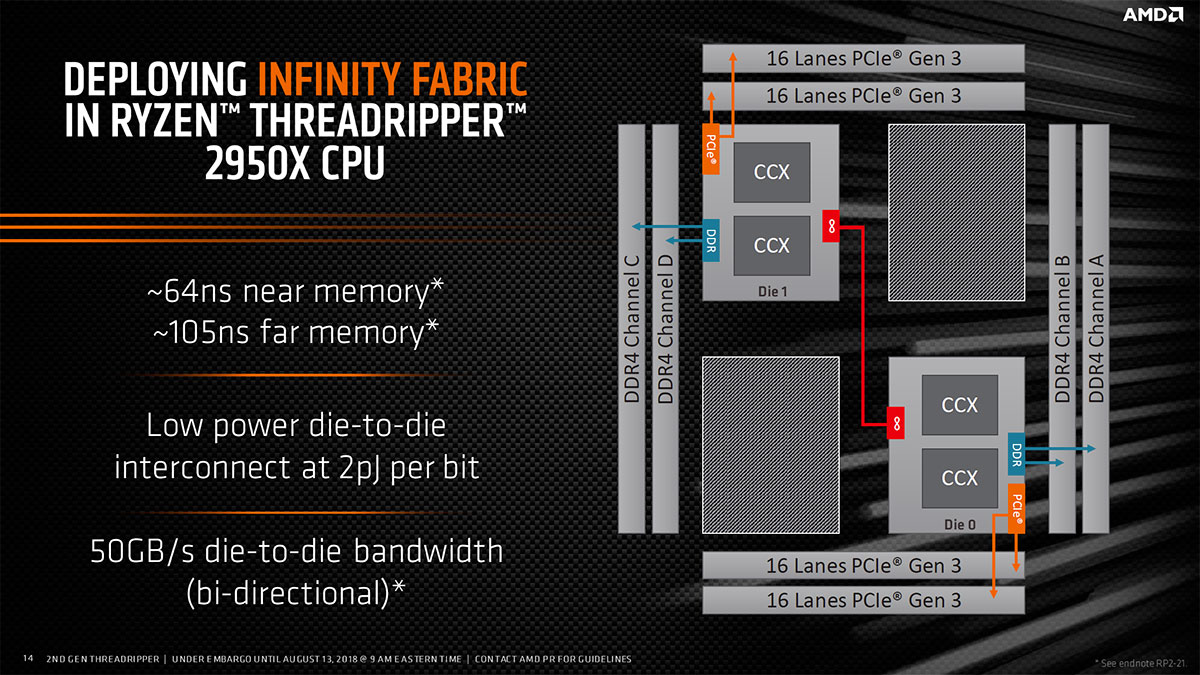
Il restait tout de même à trouver une solution pour connecter les dies entre eux. Rien de plus facile lorsque l'on dispose d'une interface à tout faire, vous vous rappelez, la fameuse Infinity Fabric. C'est par ce biais que le concepteur rouge a créé ses Epyc, utilisant pas moins de 4 dies en leur sein. De quoi proposer des CPU serveurs adaptés au traitement massivement parallèle, avec jusqu'à 32 cœurs actifs, 8 canaux mémoire et 128 lignes PCIe. Threadripper reprend cette structure de base, ce qui permet de les incorporer au sein du process pour Epyc, avec quelques ajustements selon le modèle. Ainsi, dans le cas des TR 2950X ou 2920X (mais aussi 1950X/1920X), seuls 2 die sur 4 sont activés. Ils communiquent bien-sûr entre-eux par le biais de l'Infinity Fabric, capable dans ce cas de débiter 50 Go/s, de manière bi-directionnelle.
![Interconnections die au sein du TR 2950X [cliquer pour agrandir]](/images/stories/articles/cpu/threadripper/threadripper2/infinity_2950x_t.jpg "Ne pas appuyer ici")
Liens entre die au sein du Threadripper 2950X
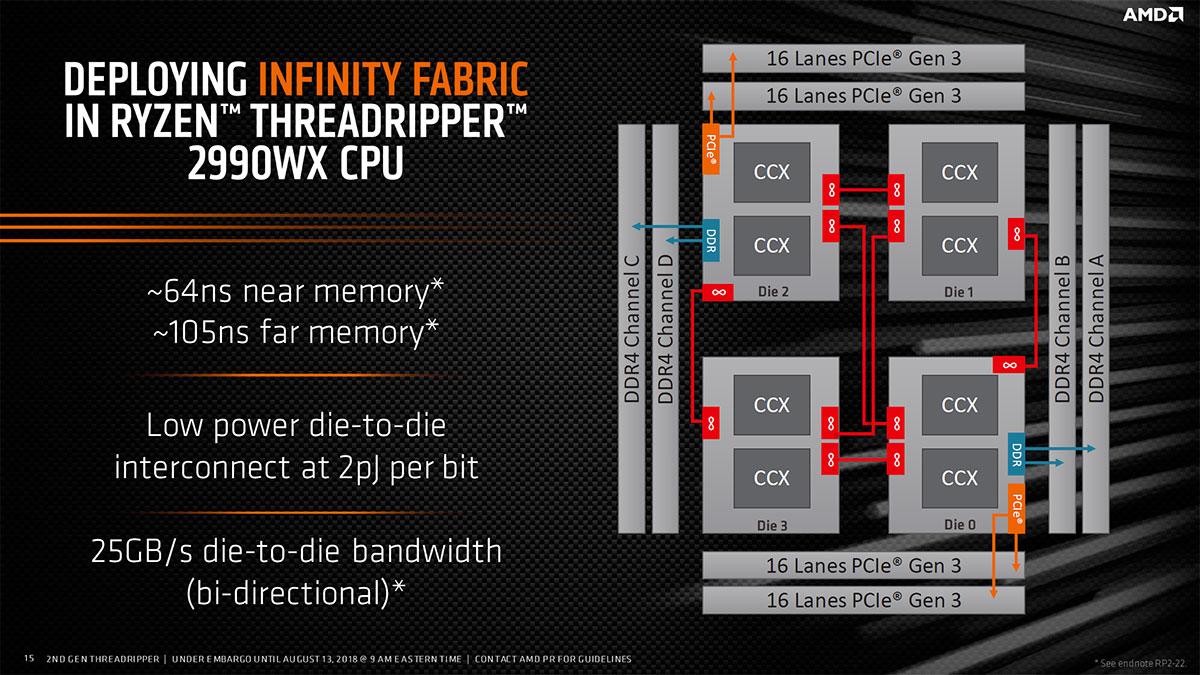
Dans le cas des TR 2990WX (et 2970WX), les 4 die sont cette fois actifs, toutefois les contrôleurs mémoire de deux d'entre-eux sont désactivés pour conserver la compatibilité avec le câblage des cartes mères TR4 existantes (et probablement laisser un avantage aux plus onéreux/rentables Epyc). Il en est de même pour les lignes PCIe de ces mêmes die. En conséquence, lorsque ces derniers ont besoin d'accéder à la mémoire ou au PCIe, ils sont contraints de le faire via l'Infinity Fabric. Nous nous retrouvons donc systématiquement dans un régime d'accès non uniforme à la mémoire (vu cette asymétrie) nommé NUMA (Non Uniform Memory Access). Ce n'est pas sans conséquence d'un point de vue performance. De plus, 4 die implique que chacun puisse communiquer individuellement avec les 3 autres, ce qui conduit à la création de 6 liens dédiés, alors qu'un seul était nécessaire avec 2 die actifs. La bande passante disponible entre-eux est donc divisée par 2 (25 Go/s bi-directionnel) d'après AMD.
![Interconnections die au sein du TR 2990X [cliquer pour agrandir]](/images/stories/articles/cpu/threadripper/threadripper2/infinity_2990wx_t.jpg "Cliquédélique !")
Liens entre die au sein du Threadripper 2990WX
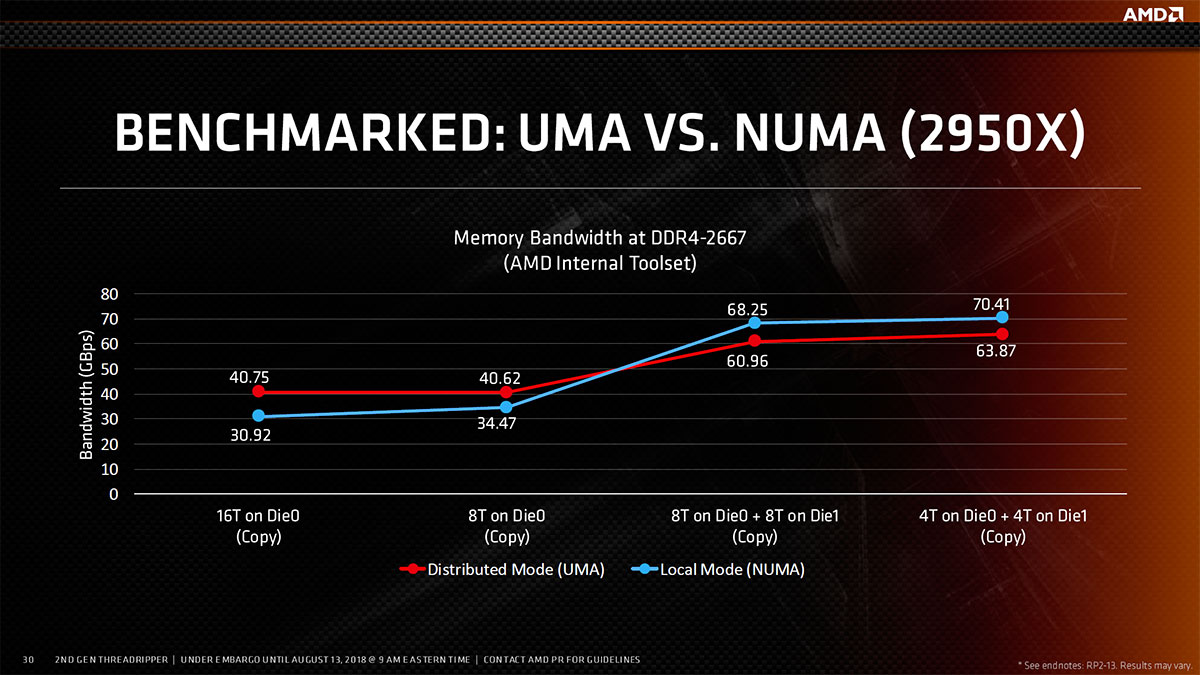
Dans un TR 2950X, chaque die actif dispose de son propre contrôleur mémoire (2 canaux), en conséquence la gestion mémoire peut cette fois adopter 2 modes différents. D'une part l'UMA (Uniform Memory Access) qu'AMD nomme Distributed et qui permet à chaque cœur d'accéder de manière uniforme à l'intégralité de l'espace mémoire, que ce dernier soit stocké sur un canal liés au die exécutant le processus comme sur l'autre, AMD évoque un ratio jusqu'à 1,6 pour la latence entre ces 2 cas. La bande passante est par contre généralement supérieure à celle obtenue en NUMA, du fait d'un accès plus large à la mémoire. C'est ce mode qui est actif par défaut.
![Fonctionnement mémoire UMA [cliquer pour agrandir]](/images/stories/articles/cpu/threadripper/threadripper2/umavsnuma_b_t.jpg "Même pas cap' de cliquer")
D'autre part, il est possible de passer également en accès non uniforme, afin de privilégier les accès mémoire locaux, différenciant ainsi la mémoire distante (raccordée au contrôleur mémoire de l'autre die) et privilégiant ainsi la latence. Ce mode de fonctionnement, en collaboration avec le système d'exploitation, a pour objectif de tenter d'agencer les données de telle manière, qu'elles soient positionnées sur le canal mémoire géré par le die en ayant besoin. Ce mode NUMA, AMD le nomme Local Mode dans ses présentations ainsi que Ryzen Master.
![Fonctionnement mémoire NUMA [cliquer pour agrandir]](/images/stories/articles/cpu/threadripper/threadripper2/umavsnuma_a_t.jpg "Ne pas appuyer ici")
Quels impacts pratiques entre ces 2 modes ? Nous avons expérimenté cela, vous trouverez les résultats dans quelques pages (n°5), toujours est-il qu'AMD fournit les mesures ci-dessous, concernant l'évolution de la bande passante suivant le protocole utilisé et la distribution des processus.
![Latence UMA vs NUMA [cliquer pour agrandir]](/images/stories/articles/cpu/threadripper/threadripper2/latence_numavsuma_t.jpg "3N C11QU4N7 C357 P1U5 6r4ND")
Côté support mémoire, AMD reste relativement conservateur puisque pour 8 Slots totalement peuplés, il faut officiellement se contenter de 2133 voire 1866 MHz, selon que les barrettes DDR4 soient Single ou Dual Ranked. C'est tout de même mieux avec 4/8, puisqu'il est possible cette fois d'utiliser de la mémoire à 2666 MHz de manière officielle, et ce quel que soit le nombre de Rank.
| occupation des slots | ranks | vitesse supportée |
|---|---|---|
| 4 sur 4 | single | 2933 MHz |
| 4 sur 4 | dual | 2933 MHz |
| 4 sur 8 | single | 2667 MHz |
| 4 sur 8 | dual | 2667 MHz |
| 8 sur 8 | single | 2133 MHz |
| 8 sur 8 | dual | 1866 MHz |
Le support mémoire officiel selon la configuration
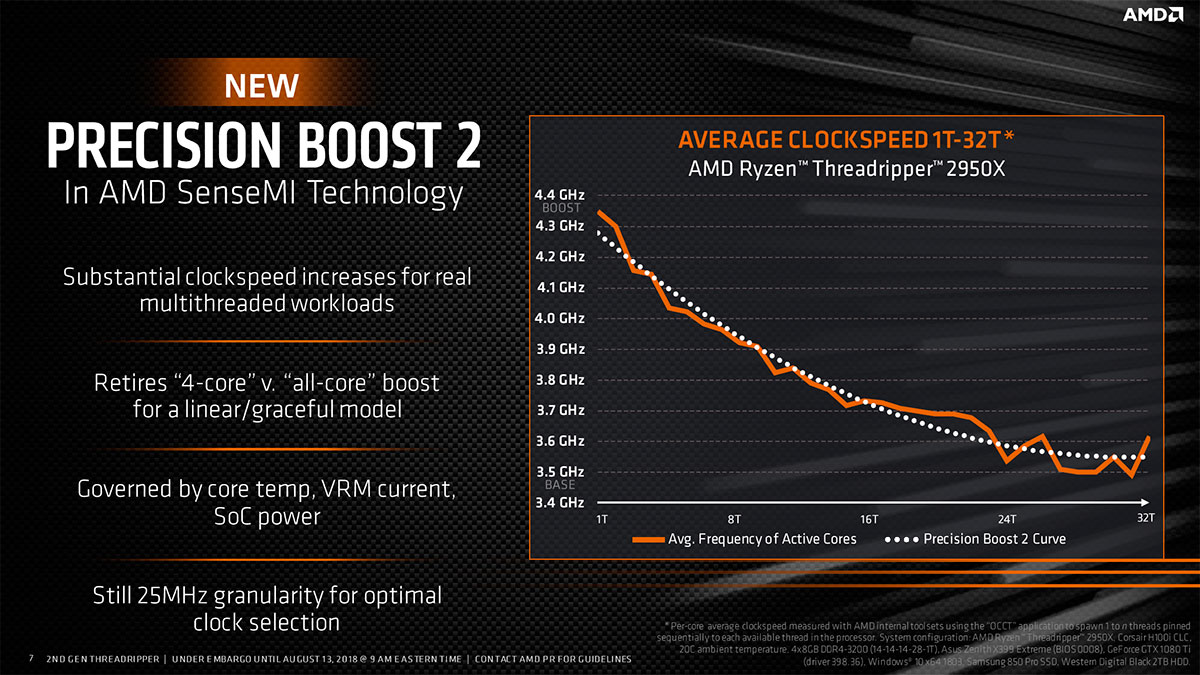
Pour tirer le meilleur parti de ses puces, AMD a utilise depuis Raven Ridge, la seconde itération de Precision Boost (la dénomination du turbo maison), qui permet de maintenir de manière opportuniste, une fréquence plus élevée que celle de référence, même au-delà de 2 cœurs sollicités si les conditions le permettent (température, intensité instantanée, etc.). De quoi proposer de fréquences élevées y compris sur des puces conséquentes, si toutefois l'enveloppe thermique allouée n'est pas trop limitante, comme c'était bien souvent le cas sur les premiers Threadripper.
![precision boost2 2950x t [cliquer pour agrandir]](/images/stories/articles/cpu/threadripper/threadripper2/precision_boost2_2950x_t.jpg "Si vous cliquez, vous cliquez.")
Un Turbo plus évolué
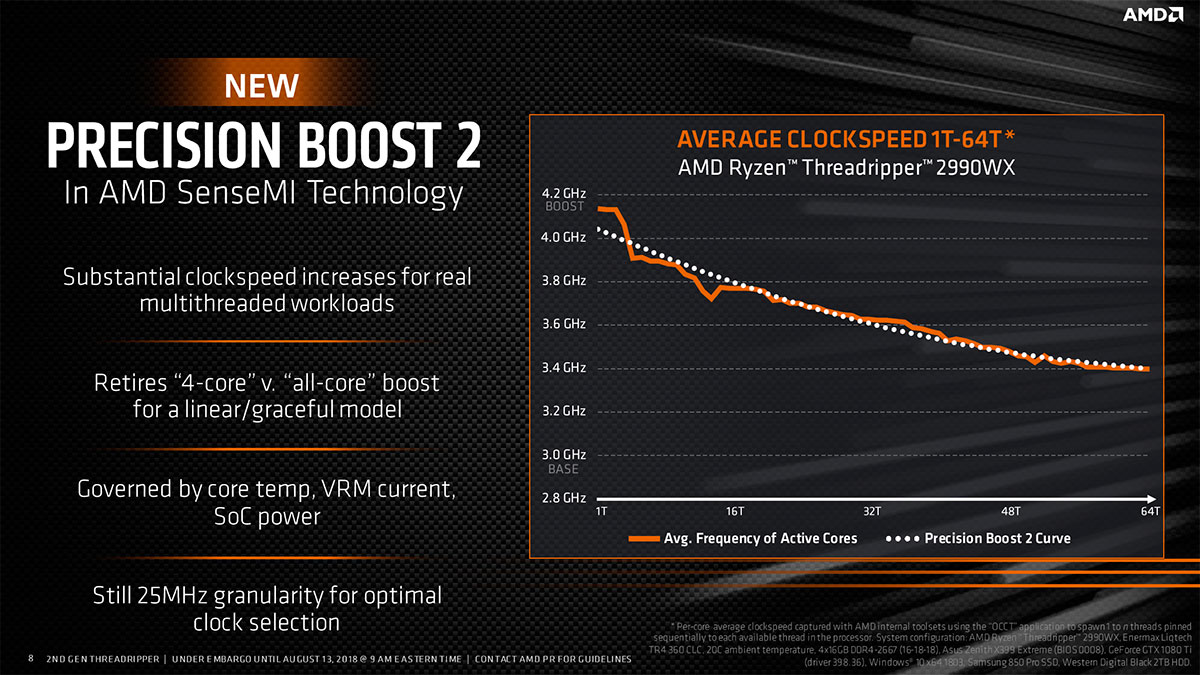
Le Threadripper 2990WX dispose lui aussi du même mécanisme. Son TDP a été poussé de 180 W (TR 2950X) à 250 W, mais dans le même temps le nombre de cœurs actifs double, ce qui a contraint AMD a baisser les fréquences, nous verrons les conséquences en pratique. A noter que XFR 2 (le Boost opportuniste/supplémentaire qui n'est gouverné que par la température) est bien de la partie pour ces 2 processeurs et apportera quelques gains avec un refroidisseur très efficace et/ou des conditions climatiques plus clémentes (fraîches).
![precision boost2 2990wx t [cliquer pour agrandir]](/images/stories/articles/cpu/threadripper/threadripper2/precision_boost2_2990wx_t.jpg "Enlarge your pe...icture")
Le même pour le grand frère (pas de jaloux comme ça !)
Finissons par la connectivité permise du fait de l'usage de plusieurs dies au sein de Threadripper. Alors que seules 16 lignes PCIe 3.0 sont disponibles sur un Ryzen pour les ports d'extension, ce chiffre passe à 48 sur Threadripper. En sus, sont disponibles 12 lignes pour les interconnexions type stockage M.2 et 4 pour le chipset X399 qui n'évolue pas avec cette nouvelle génération de processeur. Au final, ce sont pas moins de 64 lignes PCIe qui sont déployées sur un Threadripper, qu'il comporte 2 ou 4 die actifs, puisque AMD n'active pas celles de deux d'entre-eux.
![x399 t [cliquer pour agrandir]](/images/stories/articles/cpu/threadripper/threadripper2/x399_t.jpg "Si vous cliquez, vous cliquez.")
Lignes PCIe disponibles
Maintenant que nous avons rapidement décrit Threadripper de seconde génération, passons page suivante aux processeurs reçus pour illustrer le comportement de cette nouvelle gamme.
|
|
| Un poil avant ?L'IA et le hardware : et si tout était à recommencer ? | Un peu plus tard ...Hard du hard • Condensateur d’alimentation, une histoire de taille | |