Intel améliore le rendu de GTA V avec du machine learning |
————— 15 Mai 2021 à 15h40 —— 21358 vues



Intel améliore le rendu de GTA V avec du machine learning |
————— 15 Mai 2021 à 15h40 —— 21358 vues
Décidément, GTA n’en a pas fini de servir de base pour expériences de codeurs en manque de projets ! Après la scène open source qui tente de reverse-engineerer le moteur de GTA III, voilà qu’Intel s’y met à son tour, mais dans un tout autre registre : le machine learning, cette fois-ci appliqué à GTA V.
Le principe du projet n’est pas vraiment nouveau — NVIDIA s’est fait une spécialité dans ce domaine-là — : entraîner un réseau afin de reproduire le style d’un ensemble d’images prédéfinie, pour ensuite l’appliquer sur un cible, ici un jeu vidéo. Cependant, contrairement au StyleGAN des verts, le projet des bleus fait face à une contrainte supplémentaire. En effet, le bousin doit être stable temporellement, c’est-à-dire que l’algorithme ne doit pas donner des interprétations trop différentes de deux frames consécutives : un souci des travaux précédents, qui avaient tendance à « halluciner » des éléments — principalement des arbres — sur une partie des images affichées, rendant le résultat épileptique au possible. Pour autant, le programme possède plus d’entrées que le StyleGAN : il est question ici de donner à manger au réseau tout le pipeline de rendu : comprenez que l’algorithme ne possède pas que l’image originelle de sortie du jeu, mais aussi toutes celles ayant été calculées par le GPU pour arriver à ce résultat : reflets, distance à la caméra, ombres.... Autant de données permettant de donner un sens plus précis à chaque pixel, et, ainsi, mieux les intégrer dans le rendu final.
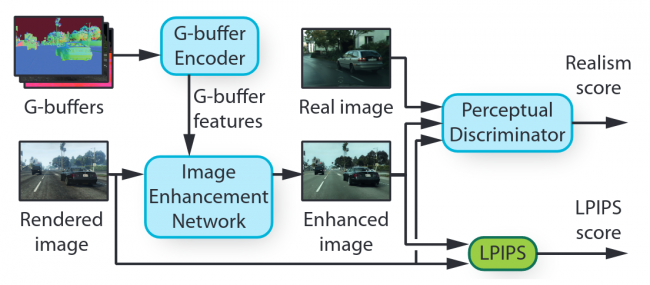
De ce fait, la structure du réseau se retrouve adaptée à ces caractéristiques des entrées : majoritairement constituées de sous-réseau convolutionnel — les plus adaptés en matière de traitement d’image —, l’algorithme se décompose en réseaux traitant séparément chaque image intermédiaire du rendu, donnant également au passage une segmentation sémantique des objets, c’est-à-dire une classification de « qui est une voiture/route/arbre/maison ? ». Tout cela est ensuite donné au réseau final, qui se charge de l’amélioration en tant que telle, pour un résultat impressionnant. Si les modifications de contraste et de luminosités sont frappantes, là ne réside pas la seule contribution du réseau : les éléments complexes, principalement la végétation, semblent plus naturels et moins réguliers... mais aussi plus flous : peut-être un artefact de la compression YouTube sur une vidéo en 720 p ?
Bien que le résultat soit impressionnant, cela ne signifie pas pour autant que ce type de technologie sera intégrée de sitôt dans les productions AAA. En effet, le processus de rendu prend environ une demi-seconde sur une GeForce RTX 3090, et, bien que le code ne soit pas optimisé pour la performance, le chemin à parcourir reste long pour obtenir une méthode adaptable sur les cartes graphiques d’entrée de gamme. Néanmoins, avec la démocratisation du DLSS (dont nous attendons toujours la version AMD, au passage...), NVIDIA a déjà prouvé que des applications du machine learning sur la scène vidéoludique pouvaient être couronnées de succès... tout comme être des échecs cuisants pour les premiers titres ayant essuyé les pots cassés. À voir si l’industrie choisit de persévérer dans cette voie !
| Un poil avant ?SK Hynix voudrait aussi aider le marché des semiconducteurs à sortir de sa pénurie | Un peu plus tard ...Gamotron • Pour les fans de gros fusils qui piquent | |





















