IA et modèles de langage : que deviennent vos données ? |
————— 17 Mai 2025 à 19h00 —— 21374 vues



IA et modèles de langage : que deviennent vos données ? |
————— 17 Mai 2025 à 19h00 —— 21374 vues
TRIBUNE — Le training traditionnel est basé sur de large data sets de données, généralement des données scrapées sur le web, pour ensuite créer de grands modèles, mais c’est loin de représenter l’unique méthode d’entraînement. Prenons par exemple les modèles distillés, ce sont des modèles plus petits en taille, et paramètres, entraînés avec des data sets qui comportent des milliers d’exemples questions/réponses valides, obtenus à partir de très grands modèles. Ça permet de pouvoir fournir des données d’exemple de milliers de situations valides, avec un contexte allant à l’essentiel, évitant le superflu. Cette méthode n’est pas infaillible, mais elle permet de gagner grandement en performance, et surtout en précision avec de plus petits modèles.

réflexion androïde
Un inconvénient de la distillation réside dans sa capacité réduite à appréhender des concepts trop complexes : si les données sont trop abstraites ou nuancées, le modèle peut échouer à en saisir le sens ou à les représenter de manière fiable. Dans ce genre de cas (toujours notre exemple du métier de développeur), le modèle se contentera de se rapprocher au mieux de la syntaxe employée généralement, y compris si elle est fausse.. D’où, si vous l’avez déjà vécu, ces interminables discussions où vous tentez de faire comprendre à votre LLM préféré, que « non, 1+1 ne font pas 11 ». Les grandes entreprises de LLM l’ont donc compris, le nerf de la guerre n’est pas seulement le web et son contenu. Le plus important est d’avoir des exemple valides, à jour, et surtout dont la confirmation est certifiée à 100 %. Mais alors, comment faire ?
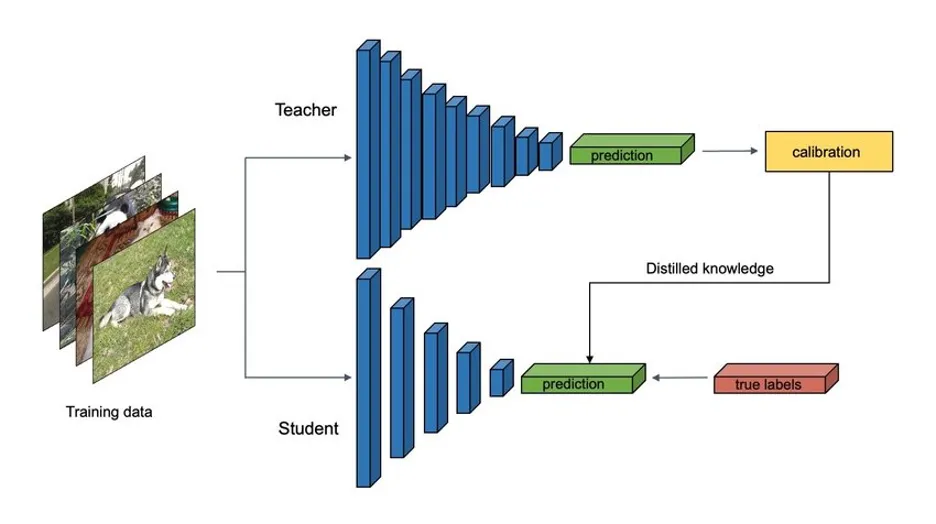
la distillation de modèles
Même si les retours humains ne sont pas indispensables pour la distillation, ils jouent un rôle clé dans l'amélioration des grands modèles dont elle dépend. En d’autres termes, mieux le « teacher » est aligné grâce à vos retours, plus le « student » a des chances d’être pertinent. Et vous l’aurez compris : le meilleur jugement se trouve toujours entre la chaise et le bureau… autrement dit, vous ! De ce côté la, vous aurez peut être constaté la myriade d’outils mis à disposition pour avoir un précieux retour de votre part : Sélection de « La meilleure réponse », pouce vers le haut/bas, signaler un problème, et même tout simplement, vos réponses pleines de joie/colère tourouj.
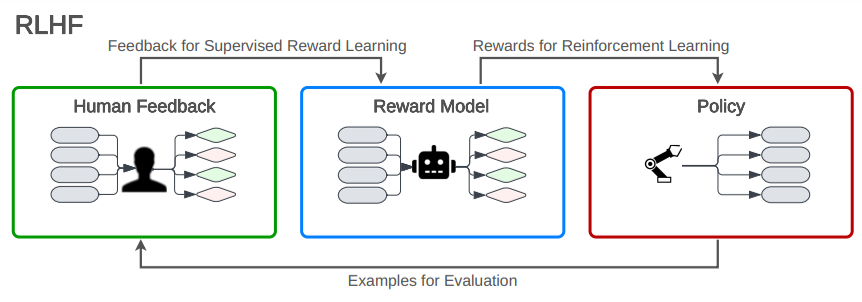
C’est le Graal de la donnée : vous fournissez un problème, un exemple, une réponse (même si elle consiste à insulter votre interlocuteur virtuel), ce qui valide la réussite, ou l’échec, de votre requête. Ce qui coche toutes les cases citées plus haut, et peut vous donner l’impression d’être à la fois le dindon de la farce, et fournir vous-même la farce avec votre abonnement, si vous n’utilisez pas ces services gratuitement.
L’Europe, souvent considérée réfractaire par les grands groupes du numérique, a mis en place dès 2018 le RGPD (Règlement général sur la protection des données), pour encadrer strictement la collecte et l’utilisation des données personnelles. Plus récemment, en 2024, elle a voté le AI Act, un règlement spécifiquement dédié à l’encadrement de l’intelligence artificielle. Ce texte impose notamment des obligations de transparence, de gestion du risque et de documentation technique selon le niveau de danger estimé du système IA concerné. Les deux règlements, bien que distincts, sont complémentaires dans la protection des citoyens européens face aux nouveaux usages technologiques.
Ce dernier prévoit entre autres des amendes jusqu’à 7 % du chiffre d’affaires ; ajoute de nouvelles réglementations imposant une transparence accrue sur l'utilisation des données, un consentement plus explicite des utilisateurs, et des droits renforcés concernant l’exploitation des informations personnelles.
 Les fondamentaux de l'IA act
Les fondamentaux de l'IA act
À première vue, ces mesures pourraient sembler être un véritable coup dur pour les fournisseurs de services. Par le passé, elles ont déjà poussé certaines entreprises, comme OpenAI, à faire preuve d’une extrême prudence avant de lancer des fonctionnalités telles que les "Custom Instructions" — un système permettant de conserver certaines préférences de l’utilisateur entre les sessions, via une mémoire persistante, afin de mieux personnaliser l’expérience.
Cependant, même si l’ européenne semble avoir réussi à faire plier les géants de l’intelligence artificielle, il convient de nuancer cette impression. Contrairement aux États-Unis, l’UE ne dispose d’aucun véritable pouvoir extraterritorial. En outre, on peut légitimement douter de sa capacité à prouver que ces fournisseurs ne continuent pas, malgré les régulations, à collecter vos données — même si celles-ci sont prétendument anonymisées.
Si vous êtes soucieux de ne pas partager la recette de tarte à la framboise de tatie Jeannine, ou pour reprendre notre exemple d’un développeur et de son code sensible, plusieurs solutions s’offrent à vous. Bien que GPT, Gemini, Claude AI, fournissent, comme mentionné plus haut, un paramètre de désactivation de prélèvement de vos données, ils peuvent vous donner l’impression d’être juste là pour vous rassurer, plutôt que pour réellement vous protéger.
 les options existent... mais sont-elles viables ?
les options existent... mais sont-elles viables ?
Une autre solution serait d’utiliser des LLM locaux, qui sont pour la plupart dénués de protocoles de connexion au net. Les seuls modèles locaux ayant la capacité a se connecter à internet sont les modèles compatibles avec le « Tool Calling », c’est un moyen relativement complexe et bancale d’avoir vos modèles locaux connectés, en plus de ne pas être facile à mettre en place. Les modèles locaux étant de plus en plus performants (prenons pas exemple Qwen 3), ils peuvent vous fournir un assistant conversationnel tout à fait compétent, pour des taches sur le virtuel, notamment le Coding, tout en utilisant du matériel domestique de moyenne gamme. Les modèles quantifiés 14B, 32B, sont très prisés de la communauté.
Cela demande toutefois du matériel raisonnablement performant. Une carte graphique Nvidia (de préférence RTX) reste aujourd’hui la solution la plus compatible et optimisée pour l’inférence locale rapide, grâce à CUDA. Il existe des alternatives avec certaines cartes AMD (via ROCm ou Zluda), mais elles nécessitent des manipulations avancées et offrent des performances variables. Les GPU Intel, longtemps absents du paysage, commencent à rattraper leur retard grâce à des bibliothèques comme IPEX-LLM. Cette solution, proposée par Intel, permet d'exécuter des modèles LLM sur les cartes Intel Arc avec de bonnes performances.
Cela dit, il est tout à fait possible d’exécuter des modèles LLM en local sans GPU, à condition de disposer d’un processeur multicœur suffisamment puissant (idéalement avec support AVX2 ou AVX512) et d’une grande quantité de RAM — 32 Go étant un bon point de départ pour des modèles quantifiés. L’inférence sera plus lente, mais reste tout à fait exploitable pour de nombreuses tâches.
En conclusion, dans un contexte économique tel que nous le connaissons, le risque zéro n’existant évidemment jamais, si vous vous servez de grands modèles de langage. En contrepartie, les chances que vos données soient vraiment novatrices comparées aux données abyssales déjà présentes dans ces modèles sont probablement très faibles également. Voilà au moins une autre chose en sus de l'humour que les IA — du moins pour l'heure — ne peuvent compiler : le libre arbitre !
| Un poil avant ?Arm réorganise sa gamme avec des noms pour chaque marché | Un peu plus tard ...La GeForce RTX 5060 se lance, sous contrôle | |
|

























Chouette tribune sinon, un rappel argumenté ça ne fait jamais de mal !